

Shawn Presser
@theshawwn
Followers
8K
Following
15K
Media
3K
Statuses
14K
Looking for AI work. DMs open. ML discord: https://t.co/2J63isabrY projects: https://t.co/6XsuoK4lu0
Lake St Louis, MO
Joined January 2009
Last night, someone asked me what I've been up to since 2010. My reply turned into a short autobiography. I considered deleting it, but people encouraged me to post it instead: If you're unhappy with your life, it's important to believe you can fix it.
21
9
260
Suppose you wanted to train a world-class GPT model, just like OpenAI. How? You have no data. Now you do. Now everyone does. Presenting "books3", aka "all of bibliotik". - 196,640 books.- in plain .txt.- reliable, direct download, for years: thread 👇

25
323
2K
I'm pleased to release `llama-dl`, a high-speed download script for Facebook's 65B GPT model. It downloads at around 200MB/s, so it finishes ~18x faster than the torrent. Be sure to read the disclaimers in the README. Enjoy.
29
112
901
One of the strangest mysteries in AI is that you can average two models and get a result superior to either model alone. The weights, not the outputs. As gwern said, it’s like putting a beetle and a rabbit in a blender and getting a rabbit that can fly.
33
79
662
An anonymous donor named L has pledged $200k for llama-dl’s legal defense against Meta. I intend to initiate a DMCA counterclaim on the basis that neural network weights are not copyrightable. It may seem obvious that NN weights should be subject to copyright. It’s anything but:.
40
93
624
Recently, many people have asked me how I make so many breakthroughs in ML and AI. I've highlighted a few of my key approaches:
5
65
507
Fixed the llama sampler. After turning off top_p, adding top_k 40, setting temp to 0.7, and adding a repetition penalty of 1/0.85, llama 7B is looking nice. I'll post 65B next, along with (hopefully) some big text files with lots of outputs.


21
44
510
Most underrated ML hack of this century:. Loss getting too low?. loss = abs(loss - x) + x. where x is a value like 0.2. Presto, your loss is no longer <0.2. Set it to whatever you want. It completely stabilized our biggan runs. This is "flood loss"
12
77
469
Facebook is aggressively going after LLaMA repos with DMCA's. llama-dl was taken down, but that was just the beginning. They've knocked offline a few alpaca repos, and maintainers are making their huggingface mirrors private "so at least I can use it as a peresonal backup.".
20
85
422
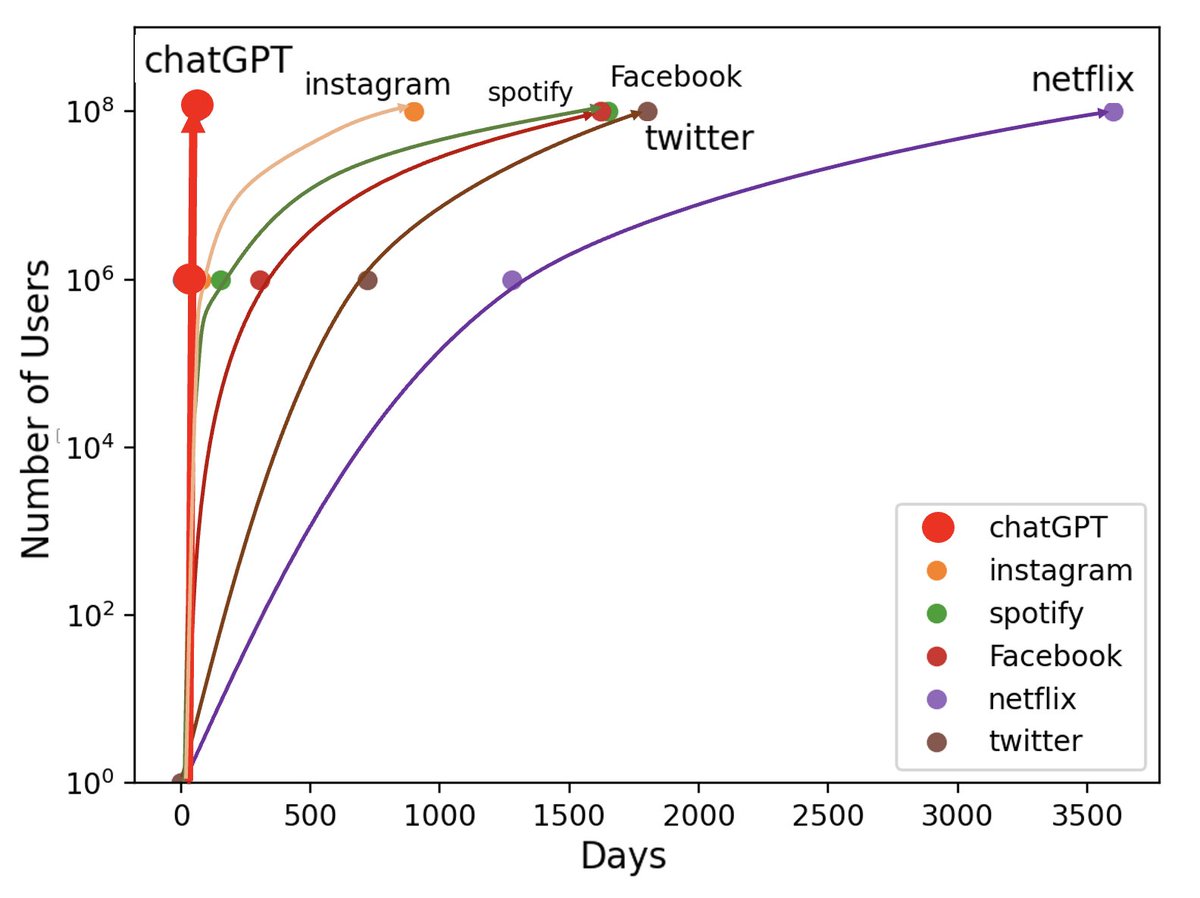
I’ve been staring at this chart for three minutes and can’t wrap my head around it. How did openai scale chatgpt so well? The fact that they pulled it off should terrify google. Log10 scales break my brain. I grew up watching Netflix go from 0 to 100m. OpenAI did it in 3 months.

chatGPT : something different is happening. Number of days to 1M and 100M users : .vs.* instagram.* spotify.* facebook.* netflix.* twitter. #chatgpt #ai #openai #google @openai
44
39
415
I was served with papers a few minutes ago. Is this e/acc?. More seriously, I can’t figure out what (if anything) they’re asking me to do. It seems to be a notice. What data do I have that could possibly matter for an OpenAI lawsuit? Anyone else get one?. This is cyberpunk af


79
33
384
Yet again, someone with 8 followers (@jonbtow) randomly shows up and points out something awesome (a badass way to plot neural networks). I'm amazed and fortunate that people share stuff like this!


@theshawwn Pretty similar.
5
42
315
Prediction: five years from now, there will be no signs of AGI being anywhere close to the horizon. The technology will get sufficiently more and more advanced, but will remain a tool for humans, rather than a species that are recognizably alive, or achieving superintelligence.

I don't really like talking about AGI timelines. The term "AGI" is vague and varies depending on the speaker. According to my best understanding of the term, I think we'll probably get AGI within 5 years, but I suspect the econ impacts will come later. This confuses people.
26
36
288
I created "colab-tricks", a github repo with some advanced Colaboratory tips and walkthroughs. - SSH into Colab.- View tensorboard while you're training.- Use rsync to copy files to/from Colab.- Interact with Colab's TPU from your local machine.
5
68
281
@kathrinepandell @angelt18 @redditships I like the phrasing here. It implies that the therapist is claiming personal responsibility for every boner in the world.
1
0
252
This feels prescient. All I could think while watching it is “Someone will probably train a GPT robot to behave this way with RLHF.” I kind of want to.
9
24
261
Trained a GPT-2 1.5B on 50MB of videogame walkthroughs. The results are *very* interesting. Someone could parse this and generate game levels, or mechanics. Thanks to @me_irl for the dataset, and for giving permission to release everything publicly. I'll post instructions soon.




10
55
253
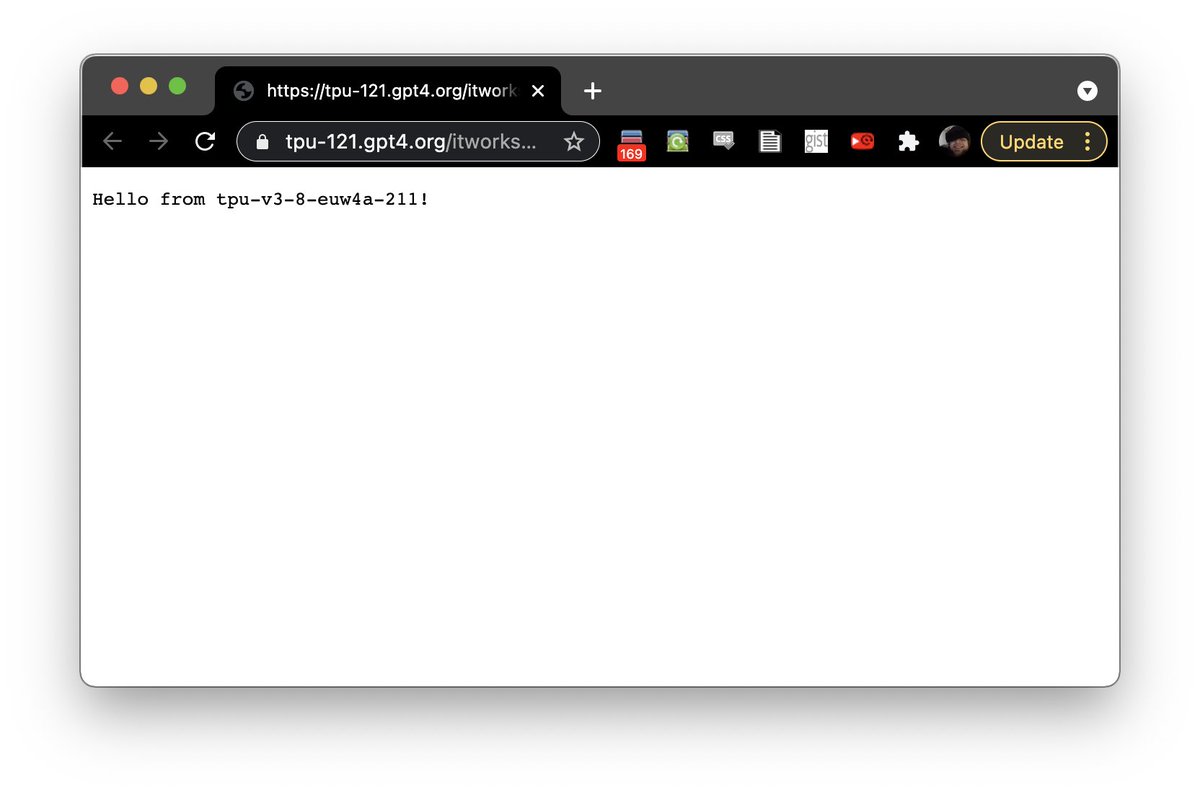
Wow. I'm SSH'd into a TPU v3-8. It has 96 CPUs and 335GB of RAM. Incredible. I installed npm:. snap install npm.npm i -g http-server.sudo http-server -p 80. Then I added Cloudflare DNS. Presto: a 96-core NodeJS website (for the next 3h): It was so easy!

5
21
255
After watching Chernobyl, I thought I’d go learn about nuclear physics. I ended up discovering my favorite lecturer of all time, perhaps second only to Feynman. Meet Michael Short, a thoughtful and unassuming MIT professor.
3
22
254
I was trying to understand the 1-bit adam paper ( and was like, "I wish I could paste a screenshot and have ChatGPT tell me what this math is saying." Then I realized I could paste TeX. And. it worked? I'm legitimately amazed.

9
25
246
Anyone who feels happy that 70TB of Parler user data was leaked: you’re cheering a criminal committing a crime because you happen to dislike the target. It’s breathtaking seeing how many people are legitimately two-faced and unprincipled.
12
7
235
Ported pytorch to tensorflow. I like how it looks. Calling it This code might look like pytorch, but it's actually tensorflow. I'm almost literally copying pytorch codebases verbatim. biggan 256x256 discriminator / generator / GBlock / batchnorm:




7
37
238
I am preparing to release a notebook where you can play chess vs GPT-2. If anyone wants to help beta test it:. 1. visit 2. open in playground mode.3. click Runtime -> Run All.4. Scroll to the bottommost cell and wait 6 minutes. If you get stuck, tell me.
7
41
239
An explanation of DALL-E's encoder/decoder:. The encoder takes in an image, and spits out a shape [8192, 40, 40] of logits. What does that mean? It means the image is broken up into 40x40 blocks. (The upper-left corner = block 0,0.) At each block, there are 8192 numbers.
2
30
232
Dear ML Twitter: what’s the smallest ML model that you can “do something cool” with?. GPT-2 117M has always been my baseline, but it happens to be too big for my current domain. I was hoping someone knew of a tiny ML model that you like playing with (for any value of “like”).
42
16
221
Well, damn. Apparently I experienced a "winning lottery ticket" ( and squandered the opportunity to study it by not saving the weights. Yesterday I woke up to a loss of 0.000235. Today I woke up to a loss of 0.0018, around 8x higher. Same params.
11
17
209
I discovered long ago that gwern ruthlessly purges bad ML ideas. He’s rarely wrong. If an idea has the slightest flaw, it won’t make it past him. Here’s one he didn’t reject. If you’re looking for a promising idea about GPTs, consider snagging this one before someone else does.

@YebHavinga @JagersbergKnut @robertghilduta I was thinking, the model could output a token and a confidence. The confidence levels are stored, just like the tokens are. When you reach the max context size, go back to the first uncertain token and regenerate, but this time it can see the rest of the tokens. Repeat to taste.
17
12
197
This collection is 40 times larger than books3. No one seems to care at all about copyright. It’s tempting to leave the English speaking world behind and focus on someplace that supports academic work. Will people call this theft? No one has so far. It’s a nice challenge too.
9
15
186
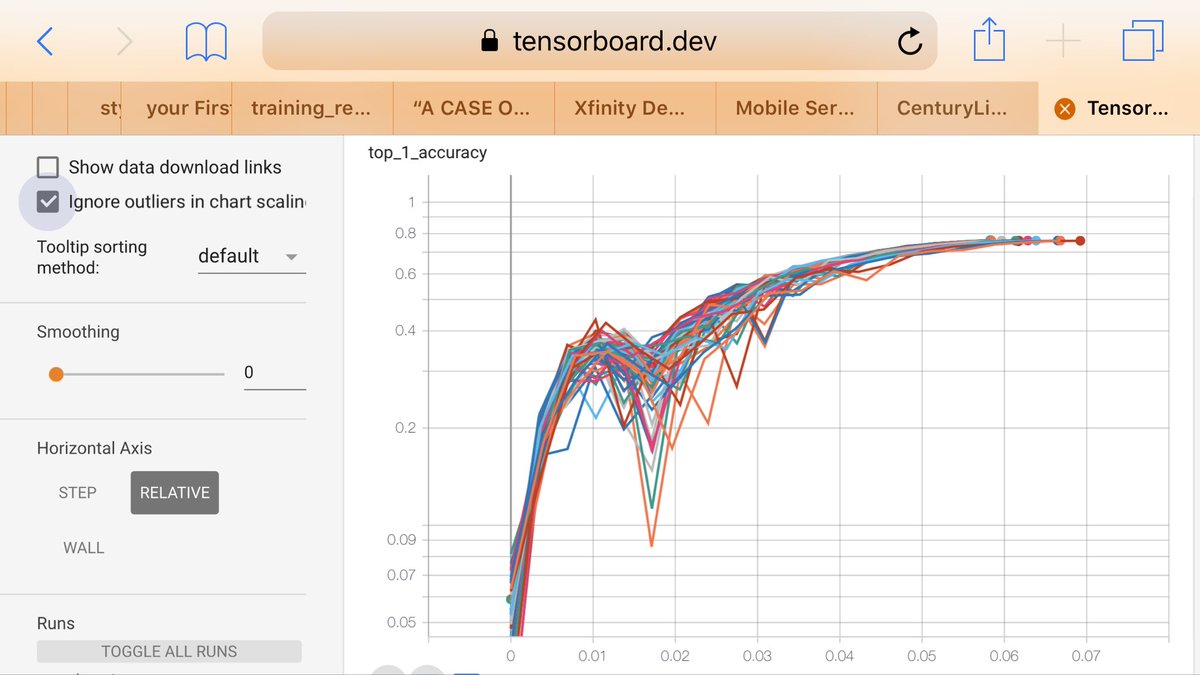
Success: I trained ResNet-50 on imagenet to 75.9% top-1 accuracy in 3.51 minutes using a 512-core TPUv3. (480,000 images per second. 224x224 res JPG.). Before you think highly of me, all I did was run Google’s code. It was hard though. Logs:
3
34
183
We've been building the largest corpus of freely available training text ever released, called The Pile. @nabla_theta has been doing an incredible amount of work on it. Mainly I like how fun it is. You can join and contribute!


11
35
173
“Hey I invented fire”. “Are you serious right now? Fire burns you, and it’s a threat to everyone’s livelihood”. Cue fire getting canceled and legally restricted to governments and approved researchers.
12
24
167
Trained a GPT model using 8 tpu v2-8’s. Each layer is on a different tpu (pipeline parallelism). And I didn’t do a damn thing. Remember GPT-J? Turns out, Kindiana (the fella that wrote most of GPT-J’s code) quietly made this 5 months ago. “swarm-jax”:




6
20
176
Stephen King on books3: “Would I forbid the teaching (if that is the word) of my stories to computers? Not even if I could. I might as well be King Canute, forbidding the tide to come in. Or a Luddite trying to stop industrial progress by hammering a steam loom to pieces.”.
6
19
158
EleutherAI’s new paper is out! “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”. pdf: dataset: If you want to train your own GPT-3, this removes one of the main hurdles: collecting high quality training data.
1
27
153
To invent AGI, we'll either need to use evolution, or bypass evolution. Right now, everyone is convinced -- totally convinced -- that it's possible to bypass evolution. Nope. No chance. That's why I think AGI won't happen within our lifetimes. No one is focusing on evolution.
51
16
147
@LilliVaroux @forte_bass I noticed that too. He calculated $0.01 per install when Unity charges $0.20. He also got the floor wrong by saying no charge till $1M rev; Unity charges at $200k rev.
4
1
144
I figured out how to convert the entire Bee Movie into a gif suitable for discord profile pictures:
4
11
145
Holy crap. This is the first time that I've seen one of my discoveries in print, almost word for word. (Independent discovery.). Side by side: Lion vs mine, from ~days ago. I almost posted a big twitter thread about it, but wanted to do more tests.



Symbolic Discovery of Optimization Algorithms. Discovers a simple and effective optimization algorithm, Lion, which is more memory-efficient than Adam.

5
8
145
@YTSunnys @GilvaSunner In fairness, it's Nintendo's music. From it seems like he just uploads their music without transforming it. That's clear-cut infringement of business IP. Some of them don't mind. Others do.
28
1
137
Success: My first published paper! 🎉 I wrote zero words of it, but I made one of the core datasets so my name is on it. Also apparently I'm notorious enough to be mentioned explicitly here: "by Leo Gao et al. including @theshawwn", ha.

The Pile: An 800GB Dataset of Diverse Text for Language Modeling.by Leo Gao et al. including @theshawwn.#Computation #Language.
13
7
143
Reversible networks seem like one of the most important developments in ML, yet nobody seems to be talking about them. Backprop memory cost becomes O(1), with a 25% increase in computation cost. This is almost always the right trade for large models; mem bw is the bottleneck.
6
19
140
Working on a StyleGAN face editor. It's like faceapp, but you use sliders to mix together as many effects as you want. (Faceapp only lets you pick one at a time.) You can also blend between multiple faces. You can control age/gender/glasses/smile/yaw/roll/moustache/emotion/etc.
7
20
130
I rewrote Adam optimizer's code to get an intuitive sense of what it's doing. Here's "Adam, explained in terms of Newtonian physics":
1
14
134
JAX released a compilation cache for TPU VMs. It cut our startup time by over 50%! If you experiment with large models on TPU VMs with JAX, be sure to try this out. Instructions here:
3
17
131
Feeling sad today. Worried that no one wants to release models anymore. It was the whole reason I got into ML. It’s like “no one wants to work anymore,” but unironic. But GPT-J proves that you don’t need to wait for OpenAI, DeepMind, or anyone else. We can do it ourselves.
7
3
125
At long last, I finally fulfilled my dream of manually controlling learning rates during a run. It's basically a knob you can turn. The LR changes all get logged to tensorboard. It uses shared TPU variables, so I have direct access to the TPU vars from my laptop. (LR is a var.)




9
5
128
The US copyright office recently upheld a decision that ML outputs cannot be copyrighted. There are several reasons for this, and as far as I can tell, all of them apply to NN weights as well:
4
16
116
Picked out the most interesting books from storage. Ended up with these . No bullshit guide to math. A retargettable c compiler. Practical signal processing




3
4
117
GPT-2 chess is promising. After an hour of training, 1.5B is pretty good at opening theory. Longer sequences tend to fail due to invalid moves, but this shows it's possible in principle to make a GPT-2 chess engine. And maybe after more training it'll make fewer invalid moves.

8
24
117
Ahem. ATTENTION ML TWITTER: *grabs megaphone*. The Russians trained their own DALL-E (ruDALL-E 1.3B), and it looks amazing. Googling "ruDALL-E" brings up nothing whatsoever. Apparently @l4rz is the only one who noticed it was released a few hours ago!.


5
17
113

3
1
110
I made a library for visualizing tensors in a plain python repl:. pip3 install -U sparkvis.from sparkvis import sparkvis as vis.vis(foo). "foo" can be a torch tensor, tf tensor, numpy array, etc. vis(a, b) will put 'a' and 'b' side by side. I like it. Here's the FFT of MNIST:

This is the stupidest hack I've ever come up with, and it works great. My local pytorch isn't working (thanks, M1 laptop) so I had to do my REPL work on a server. I didn't want to install jupyter, because lazy. But I needed to visualize a tensor. Solution: sparklines!

4
12
111
I did an interview with The Verge about LLaMA. It turned out pretty interesting. I spent awhile talking about the impact on society of having your own personal ChatGPT, since it's a matter of time till someone fine tunes LLaMA into one.
9
8
109
I wanted to set up a non-profit to make AI research more accessible (Tensorfork Labs). Most of my research goals have been "help people get started with AI research," so a non-profit felt naturally aligned. But how?. Surprisingly, getting an EIN was free:


3
8
109
I rarely unfollow people, but AI art is quickly becoming annoying. You’re not an artist in the sense of someone who spent years honing their craft. Pretending you are is just boring.
28
3
103
It doesn’t cost OpenAI $3M a day to run chatgpt. The source for this based these calculations on AWS, when OpenAI uses azure. They also have the benefit of scale. Amusingly, tiktok called out all of that in the comment section, whereas everyone on Twitter seems credulous.

4
7
110

This is the stupidest hack I've ever come up with, and it works great. My local pytorch isn't working (thanks, M1 laptop) so I had to do my REPL work on a server. I didn't want to install jupyter, because lazy. But I needed to visualize a tensor. Solution: sparklines!
5
11
108
Discovery: the phase of an image’s FFT is far more important than its magnitude. You can even reconstruct the image solely from the phase of the FFT. This is in contrast to audio, where magnitude matters way more than phase. Idea: train a GAN to predict phase, not magnitude.



7
10
107
Gonna train a GPT on swear words and release it as an autoaggressive language model.
10
4
104
Interesting hypothesis: most changes to transformers don’t matter at all; performance is more or less identical.


5
6
101
I used GPT-4 to draft a DMCA counterclaim for Does anyone know any lawyers that could weigh in on whether this looks reasonable to submit?. (Happy to pay for counsel, too; we're funded. But I'm not sure who to contact.)

An anonymous donor named L has pledged $200k for llama-dl’s legal defense against Meta. I intend to initiate a DMCA counterclaim on the basis that neural network weights are not copyrightable. It may seem obvious that NN weights should be subject to copyright. It’s anything but:.
13
10
96
Daily dose of BigGAN-Deep. Training step 8.6M, 78 days of training.




7
4
99
Here's a detailed breakdown of how JAX allocates a tensor on a TPU: It shows the C++ stack trace you normally can't see. It's interactive, too -- you can click each frame to jump to the code. There's also a (bad) video of me editing Tensorflow in CLion.
1
14
99
I believe that businesses should have the right to control their own intellectual property. But it’s not obvious that NN weights are property. They’re created from society’s data, just as phone books were, and phone books aren’t subject to copyright.
5
9
94
We suspect OpenAI's books2 dataset might be "all of libgen", but no one knows. It's all pure conjecture. Nonetheless, books3, released above, is "all of bibliotik", which I imagine will be of interest to anyone doing NLP work. Or anyone who wants to read 196,640 books. :).
2
9
94
BookCorpus is a popular large dataset of books (~6GB of text, 18k books). It was hard to replicate the dataset, so here it is as a direct download: it contains 18k plain text files suitable for e.g. GPT training or text analysis.
5
8
100
I got GPT-2 working on TPU pods a couple days ago. A TPUv3-512 gets about 160k tokens/sec training 1.5B, aka 2.5k tokens/sec per TPU. It trained a GPT-2 1.5B poetry model in 2 hours. My previous technique took two weeks. Feels nice finding the optimized code path.
3
9
97
That moment when Twitter criticizes you for retweeting an ML paper you haven't read.

2
2
93
TIL one of the most interesting astronomical phenomenons I've seen:. Basically, two moons can "bounce" off each other halfway through their orbit. Except they don't bounce; they fly by each other, which *flips their orbit*.
4
11
94
If you watch one video about ML this year, make it this one. It’s probably the best ML video I’ve ever seen. It ties together so much. I’ve waited years for this. How to make an anime without an animation studio:.
4
16
93
@EGirlMonetarism How do you make videos like this? I'd like to present some AI arguments in similar form.
6
1
77
It's convention on Twitter to post a sanitized version of yourself; to pretend that you're in public, and that you're being judged for every word. I've decided to reject this and simply not care anymore: I'm lonely and sad. But as I've wondered why, I've realized a few things.
9
0
90
This stable link is thanks to a community of data enthusiasts: They gather and make available data "for the benefit of humankind". They have an interesting DMCA policy. I urge you to read it:
2
9
89
How do you visualize an 8D object? A mathematical physicist was posting a TikTok venting that it was hard to think in more than 3 dimensions, and that higher dimensional equations pop up all over the place. I explained the trick I use; maybe you’ll find it useful too.

9
7
88
DeepMind trained a Transformer in a 3D environment to recognize and manipulate specific objects it learns about on the fly. It has an external memory, meaning it can remember new objects with no training. "Grounded Language Learning Fast and Slow". arxiv:

2
12
87
You don’t need interconnected A100s. Just average the parameters periodically. Think of it this way. Gradients are small. That means if a model is trained without interconnect, the copies can’t drift very far. So average them periodically and everything works out fine.

LLaMA was trained on 2,048 80gb A100s. Currently the most you can get interconnected is about. 20. This is unlikely to change soon as demand ramps hard. Only a few entities have capacity to train these models let alone compute for R&D.
10
6
86
I really don’t want to be twitter famous. Hundreds of people have followed me in the last day, and all I can feel is a sense of impending doom. My audience was the whole reason I loved twitter. New followers: welcome. Please just be nice. That’s all I actually want.
8
3
84
This data was so striking that I made a graph. JAX accounts for 30% of all models uploaded to @huggingface hub. PyTorch: 63.2%.JAX: 29.6%.Tensorflow: 7.3%


@Sopcaja @tunguz This is not necessarily representative data, but it is interesting to note that among the models in @huggingface hub, 1,186 were written in TF, where JAX was used in 4,830 models. PyTorch had 10,322 models, btw.
7
7
81
GPT-J-6B can generate very convincing Python code. I imported BeautifulSoup and it knew how to use it. Everything till the first `def` was the prompt: . People seem to love GPT-J in general. See the HN discussion for more examples:

4
8
85
When I noticed the FedEx courier was standing at the front door and wasn’t going away, I answered it like this. I was like, “just got home last night with a newborn, so this is what you get!”. Managed to hold back our dog Pip and sign for it with only one hand to spare.

8
0
83
I wrote up some details here: In OpenAI's papers on GPT-2 and 3, you'll notice references to datasets named "books1" and "books2". books1 appears to be bookcorpus, or similar. But OpenAI will not release information about books2; a crucial mystery.
2
6
80
Hot take: AI is pretty boring now. It was more interesting in 2020 before massive scaling was the norm. It’s more powerful now but less fun. I guess hindsight is 2020. (I hope a bunch of people say I’m wrong, it’s fun, they’re having a great time, etc.).
29
3
80

NSFW. Our hypothesis was that people will tag your datasets for free, if there’s an incentive to do so. What kind of incentive can we offer? The most straightforward was porn. This hypothesis turned out to be true. Not only that, but the tags are breathtakingly high quality.

6
12
77
This is one of the stablest BigGAN runs I’ve seen. @gwern’s idea of “stop the generator if the discriminator is too confused” seems to work beautifully. It’s a cooperative GAN rather than competitive. - D stops if D < 0.2.- G stops if G < 0.05 or D > 1.5

6
13
78
Why optimizing ML is harder than it seems: I've been fortunate to learn a lot from @jekbradbury, and I wanted to pass along some of the lessons. notes:.- simplicity wins.- the XLA optimizer wins.- don't worry (much) about reshapes.- sharding is key.
2
20
78
Hi @ID_AA_Carmack! I once emailed you as a freshly-minted 18yo programmer who had just landed his first gamedev internship, asking you for advice on how to be impactful. Your reply was, essentially, that it matters very much how you use your time. Thank you for that. It was true.

1
1
79
One reason I never seriously pursued any full time ML job is that I’m a high school dropout. I don’t regret becoming a full time software professional at 17. It wasn’t a flaw. The reason I work to make ML popular is, partly, to get rid of this elitism. You can do ML. Today.

Research recruiter: We *love* your background. Tell us about your recent work. Me: Explains years of published projects. Recruiter: Sounds amazing. But when did you get your PhD?. Me: Don't have one. Recruiter: lmfao smh nevermind want to work on product? How's your leetcode?.
2
5
78
It’s remarkable how little research there is on letting models use other models. We think of models as a finished product: once you train it, that’s it. That’s the model. But why not train models to use other models, the way humans do?.
17
3
76
The worst case for me personally is that I might go bankrupt. If Meta wants to bankrupt a fellow researcher with a child on the way for fostering an open source ecosystem around the model that they advertise as open science, then that’s their choice.
2
1
75
Our BigGAN-Deep 256x256 evonorm-s run is up to step 2.9M (as in million). No collapse so far. Trained on a v3-8. I'm excited about this because it opens the door for "BigGAN for the masses." You could train it yourself on Colab. On the other hand, it's been training for ~1mo.

4
7
77
Today I resigned from Basecamp. I never worked there to begin with, but I’m hoping no one notices so I get 6 months of salary like everybody else that left. For real though, who wouldn’t accept $75k minus tax to leave your job? You’d have to really love your job.
4
1
74
One reason OpenAI might be hesitant to release the image capability of GPT-4 is that it makes captchas obsolete. I won’t be surprised if they refuse to process anything that looks like a captcha.
15
2
73