

Tabular (now part of Databricks)
@tabulario
Followers
1,130
Following
94
Media
141
Statuses
371
Tabular is an independent storage platform from the creators of Apache Iceberg, including ingestion, performance optimization, central RBAC and SaaS simplicity.
United States
Joined April 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Maharaj
• 317307 Tweets
#INDvsSAFinal
• 85486 Tweets
SEND 21 BACK TO THE NOVEL
• 80055 Tweets
スタフォニ
• 77371 Tweets
Kohli
• 72758 Tweets
ウマチュン
• 65999 Tweets
#BABA抜き最弱王決定戦
• 64343 Tweets
#ดุจอัปสรEP4
• 56231 Tweets
Team India
• 45642 Tweets
#T20WorldCup2024
• 40152 Tweets
Let's Join NuNew1stCon
• 35647 Tweets
Verstappen
• 35514 Tweets
PABLO ON ICSYV
• 35042 Tweets
Knights
• 29124 Tweets
WANDEE TOGETHER
• 28803 Tweets
#SixTONESANN
• 26036 Tweets
ソロライブ
• 25765 Tweets
#Venue101
• 23862 Tweets
Surya
• 23363 Tweets
最高のライブ
• 19925 Tweets
Pant
• 19181 Tweets
ドラえもんズ
• 19127 Tweets
うぇいびー
• 18871 Tweets
ババ抜き
• 14216 Tweets
山田涼介
• 14056 Tweets
山田くん
• 11078 Tweets




















Pinned Tweet

Big news!
@databricks
has completed their acquisition of Tabular, bringing together the original creators of
#ApacheIceberg
and those of Linux Foundation
#DeltaLake
, the two leading open source table formats.

1
4
24
We are thrilled to announce that
@databricks
and Tabular are joining forces to solve lakehouse interoperability. We intend to work closely across the
#ApacheIceberg
and
#DeltaLake
communities to bring open table format compatibility to the
#lakehouse
.

3
24
88
Exciting news! We closed a $26M round of funding from Altimeter,
@a16z
and Zetta Venture Partners to build our independent data platform based on
#Apacheiceberg
.
We've also have added
#GoogleCloud
and Amazon Athena support.
Read more here:
3
11
70
Rui Li has written a blog on how Bilibili built an OLAP
#DataLakehouse
with
#ApacheIceberg
. With over 1,000
#Iceberg
tables that comprise over 10PB of data and a daily increment of 75TB.
#Trino
is serving over 200k queries daily
0
7
52
Akshay Jain has written a very nice blog on
#ApacheIceberg
with tips on optimizing streaming and batch updates for enhanced performance results. It's worth a read.
#dataengineering
#datalake
#datalakehouse
.

0
5
36
Recently,
#polars
-- the Rust-based DataFrames library -- added the ability to ingest data from
#apacheiceberg
tables using
#pyiceberg
.
Read the blog below from PyIceberg committer
@FDriesprong
to see how to start using them together.

0
6
25
Fokko Driesprong has written a great blog to highlight some of the great new features in the recently released
#PyIceberg
0.4.0.
#Python
and
#ApacheIceberg
are a powerful combination.
#dataengineering
#datalake
#datalakehouse
0
6
23
#ApacheIceberg
1.4 is now live. Apache Iceberg PMC chair and Tabular CEO
@TabularBlue
provides a rundown of what's new, including updates to the default file format version & compression codec, and support for
#ApacheSpark
3.5.
1
5
23
Jason Hughes has a compelling new blog on how
#ApacheIceberg
is really opening up the data space, by empowering a large selection of compute engines on the same data, without vendor lock-in. See what you think of his points.
#dataengineering

0
7
22
We're thrilled to announce the inaugural Iceberg Summit, May 14 - 15. It's a free online event.
Many thanks to our colleagues
@dremio
and
@apachesoftware
for helping us get this off the ground.
To register or submit a talk, visit:
1
3
20
The time has come to announce that Tabular is now open to the public and describe precisely what we’re about and what we do for Apache Iceberg. You can read the details here:
#ApacheIceberg
#Iceberg
#datalake
#datalakehouse
#dataengineering
1
7
19
Ryan Blue is back with part 3 in his blog series covering CDC and
#ApacheIceberg
. He covers CDC merge patterns and the trade-offs introduced by batch updates.
#dataengineering
#datalake
0
4
19
#PyIceberg
has crossed a new milestone today, with over 1,000 downloads. The
#ApacheIceberg
community keeps growing.
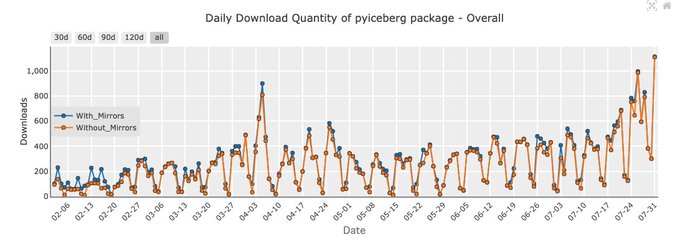
0
4
19
There are exciting developments in the
#python
and
#apacheiceberg
worlds as PyIceberg is demonstrated in this video by Fokko Driesprong. Learn how to connect to
#Iceberg
from Python in this short, four minute tutorial.
#datalake
#dataengineering
#minio

0
6
16
Our new blog, "Securing the data lake - Part 1," is now available. This first in a series of posts will explore the challenges and best practices around securing data in next-generation data warehouse architectures. Stay tuned for more to come!
#datalake
0
3
18
Bryan Keller did the work and
@bitsondatadev
wrote the blog. Learn more about the new
#ApacheIceberg
#Kafka
-connect Sink. This is a very important evolution in the
#DataLake
and streaming data. It includes exactly-once processing and commit coordination.
0
5
17
With
#PyIceberg
0.2.1 now available, we thought a video that illustrates using it with
#PyArrow
and
@duckdblabs
would be in order.
#iceberg
#apacheiceberg
#duckdb
#voltrondata
#datalake
#datalakehouse

1
3
17
Kostas Pappas has written a nice blog "Migrating to Iceberg for a more efficient Data Lake" that you will enjoy.
@ApacheIceberg
#hive
#apacheiceberg
#datalake
#datalakehouse
#dataengineering
.

0
2
17
Go deep on how modern table formats
#apacheicberg
and
#hudi
handle commits and the implications this has for ACID guarantees.

1
2
17
Ryan Blue has a new blog available that touches on some of the major
#ApacheIceberg
announcements in recent weeks. He also covers some quick
#Iceberg
basics and why you would add it to a
#DataWarehouse
.
#dataengineering
#datalakehouse
0
4
16
Jason Reid has finished Part 2 in his series on securing the data lake. Give it a read.
#datalake
#datalakehouse
#dataengineering
0
2
16
Amazon has published a very informative blog on improving the operational efficiencies of
#ApacheIceberg
tables built on AWS S3.
#datalake
#datalakehouse
#dataengineering
0
5
16
PyIceberg 0.2.0 released
This release includes a few major features, such as
* Read support using PyArrow and DuckDB
* Support for AWS Glue
for the details.
This release can be downloaded from:
#iceberg
#python
#pyiceberg
0
4
15
We are happy to introduce our new video series, "Tabular Solutions". We illustrate using various products and projects to access Tabular managed
@ApacheIceberg
tables. Our first episode is with
@AlexMercedCoder
of
@dremio
.
#iceberg
#datalake
#datalakehouse

2
3
14
Have you wondered what
#ApachePuffin
is and what it has to do with
@ApacheIceberg
? Wonder no more; co-creator
@TabularBlue
joins "Ask the Iceberg Experts" to make things clear.
#datalake
#apacheiceberg
#datalakehouse
#dataengineering

0
3
14
Hot off the press! Ryan Blue will be a featured speaker at next week's
#DataandAISummit
in San Francisco. We'd love you to come by.

0
2
13

0
4
14
The fine folks at
@berlinbuzzwords
already have the talk from Fokko Driesprong on
@ApacheIceberg
available on YouTube. Fokko gives a great presentation that is very informative for the techies.

0
1
14
People are doing some cool stuff with
@duckdb
and
@IcebergDevs
#datalake
#datalakehouse
#duckdb
#iceberg
0
2
14
#PyIceberg
0.3.0 is now available with lots of great new features. Grab a copy and discover the power of
#Python
with
#ApacheIceberg
.
#datalake
#iceberg
This Python release can be downloaded from:

0
3
13
Let there be WRITES! ✍️✍️✍️
Write support is now live in
#PyIceberg
0.6.0. Read the blog with a short step through demo from
#apacheiceberg
committer Fokko Driesprong.

0
0
13
In case you missed the presentation by Ryan Blue on CDC patterns in
#ApacheIceberg
at
#TrinoFest
this week, the video is now available on YouTube. His talk details patterns and best practices for writing CDC streams into
#Iceberg
tables.

0
6
13
We recently created an
@ApacheIceberg
cheat sheet illustrating
#Spark
SQL and made it available for download. No signups or registration is required, just a straight download link for the PDF. We hope you find this helpful.
@IcebergDevs
#iceberg
3
2
13

0
5
13
It's the last day of February, so it's time for the February 2023 edition of the Iceberg Community News. Lots of great updates to
#ApacheIceberg
and
#PyIceberg
as well as adoption from
@streamsets
@ClickHouseDB
and
@DatabendLabs

0
3
12
Did you miss Ryan Blue and the Starburst team’s presentation at Data Council? You can still run through the tutorials at : Set up Galaxy and Tabular and Using Trino and Iceberg for data warehousing.
0
1
11
The
#IcebergSummit
lineup is set! 30+ sessions from Netflix, Apple, ByteDance, NVIDIA, Bloomberg, +++ . From
#apacheiceberg
case studies to deep developer talks & technical panels - there's something for everyone.
Sign up now - it's free and 100% online!

0
5
11
The latest "Ask the Iceberg Experts" sees
@SnowflakeDB
Principal Software Engineer, Dennis Huo, talk about Snowflake's support of
@ApacheIceberg
,what it was like working with the
#Iceberg
community and the Snowflake Catalog.
#datalake

1
2
11
Ryan Blue discussing
#ApacheIceberg
and
#s3
at
#AWSreInvent
.
"Apache Iceberg is designed and optimized for S3"
If you missed this one, you can catch Ryan in the data theatre on the Expo Hall floor tomorrow at 10:30 am. Or come by Booth 1632.

0
1
11
Multiple Engines, Single Catalog — The Impact of Adopting an Open Table Format in a Data-Driven Organization
#iceberg
#datalake
#datalakehouse

0
2
11
This is the first in a series by Ryan Blue, about mirroring transactional database tables into a
#datalake
. This is part of the broader topic of Change Data Capture (CDC). Other CDC patterns in data lakes will be covered in later blogs.
#dataengineering
0
5
11
A new blog by
@etudenhoefner
illustrates using
@AirbyteHQ
with Tabular managed
#ApacheIceberg
tables. This is an exciting evolution in the
#Iceberg
ecosystem.
#datalake
#dataengineering
0
3
11
Have you read this tutorial from
@TabularBlue
yet that shows you how to use
@trinodb
with
@ApacheIceberg
for data warehousing?
#trino
#datalake
#datawarehouse
#dataengineering
.
0
3
11
@dremio
@VoltronData
and
@tabulario
hanging out and brainstorming some
@ApacheIceberg
ideas at
@DataCouncilAI

0
3
11
Getting excited for
@SnowflakeDB
Summit starting on June 27. Our CEO and co-founder Ryan Blue will be speaking about
#ApacheIceberg
at the summit on Wednesday, June 28 at noon. Make sure to save your spot!
#snowflakesummit2023

0
1
11
We're very excited about this partnership with Starburst going to GA and how it will help build the modern open data lake. Both products are now tightly coupled to provide seamless integration, making it very simple to manage and query
@ApacheIceberg
tables.

Starburst 🤝
@tabulario
That's why we're so excited to announce that the Tabular connector in Starburst Galaxy is now GA! Check it out 👉
#BigData
#Analytics
#StarburstGalaxy
#Tabular
#datalake
#trinodb

0
1
5
0
2
11
We brought our
#ApacheIceberg
committers, developers, and solutions architects together to write 34 useful recipes in our first edition of the
#ApacheIcebergCookbook
-- to give you a head start on your Iceberg journey.
🍳 👨🍳 👩🍳 🍽
Let's get cooking!

0
4
10
Our own
@fdriesprong
will be giving a talk next month on
#PyIceberg
at the
#PyData
conference. You don't want to miss it.
#dataengineering
#apacheiceberg
0
2
10
Check out our new YouTube channel with our first Fireside Chat with founders and creators of
@ApacheIceberg
Ryan Blue, Dan Weeks and Jason Reid.
#apacheiceberg
#datalake

0
2
10
There's still time (barely)⌚ ⏱ ⏰ to register for next week's 1st
#IcebergSummit
. Click below for the agenda featuring 30+ practitioner and developer talks about
#ApacheIceberg
. Many thanks to co-organizers
@dremio
and
@TheASF
who sanctioned the event.

1
5
8
Check out this
#timetravel
recipe, one of 34 in our
#ApacheIcebergCookbook
.
It shows you how to rewind time to a historical table snapshot, which helps with debugging, auditing, and historical analysis.
And it comes built into
#ApacheIceberg
.

0
1
10
In this episode of "Ask the Iceberg Experts", we discuss the topic of "Copy on Write" vs. "Merge on Read" with Iceberg co-creator, co-founder, and Head of Engineering at Tabular, Daniel Weeks.
#iceberg
#datalake
#tableformat

0
4
10
Our co-founder Ryan Blue, also co-creator of Apache Iceberg, will join
@starburstdata
at
@DataCouncilAI
to present a tutorial about
@trinodb
and
@ApacheIceberg
for data warehousing. Check it out to learn how to use MERGE to build an idempotent data import process with Trino.
0
1
10
Make sure to tune in and see
#ApacheIceberg
co-creator speak at
#Subsurface
tomorrow March 1st, and his panel on March 2nd. Registration is free.
@dremio
0
3
10
If you liked our first 3 CDC posts, you'll love "Zen and the Art of CDC Performance" by
@ApacheIceberg
creator and Tabular CEO Ryan Blue.
Enjoy!

0
2
9
Our new blog starts the dive into the Tabular security model by explaining our credential system and how it secures your data without relying on your compute to do it.
#dataengineering
#datalake
#datalakehouse
#cloudsecurity
0
4
9
Did you know that you can now use
#AWS
#redshift
to query Tabular-managed
#ApacheIceberg
tables? This new episode of Tabular Solutions with Tabular co-founder Jason Reid shows you how quick and easy it is to do.
#dataengineering
#datalake
#datalakeshouse
0
3
9
Deniz Parmaksiz from Insider is giving a great
#Iceberg
talk at
#subsurface
right now. He recently was on an episode of Ask the Iceberg Experts talking about this experience.

0
1
9
A new blog from Mike Shakhomirov has a great introduction to
@ApacheIceberg
tables.
#datalake
#datalakehouse
#dataengineering
0
1
9
In the excitement over our blog post announcing the general availability of Tabular yesterday, we didn’t point out the brand new website. Most important is the pricing page and the new resources that illustrate the product.
#apacheiceberg
#dataengineering
1
1
9
0
3
9
Very pleased to report that
#ApacheIceberg
#PyIceberg
0.4.0 is now available. Details and downloads available at

0
3
9
So happy to be part of the new
@starburstdata
Galaxy partner connect experience. Sign up for the virtual workshop with our CEO Ryan Blue and Starburst's Monica Miller on June 22nd from 1 pm to 2 pm ET. Sign up at the following link:

0
3
9
Our new interactive demo illustrates how to work with our new
#AWSAthena
compute engine integration. This feature will be live in the Tabular product in a couple of days. Come give it a try!
#dataengineering
#datalake
#datalakehouse
0
4
8
Only 7️⃣ days until the 1st
#IcebergSummit
. Join the
#thousands
who have already registered! Sign up for technical talks from Apple, Netflix, Uber, ByteDance, LinkedIn, Bloomberg and other prominent
#apacheiceberg
users.

0
4
8
After an exciting week of
#ApacheIceberg
news from Snowflake and Databricks, we wrap up all the technical and community information in our end-of-month
#Iceberg
community news. Read here for the latest.
0
3
8
We're super excited to have you join our growing team!

Starting a new journey at as the first Solutions Architect helping customers adopt Tabular’s platform and Apache Iceberg. Super excited for another 🚀 adventure.
@tabulario
1
2
11
0
1
8
The latest episode of "Ask the Iceberg Experts" sees Amazon Senior Software Engineer, Jack Ye, back, to talk about what he sees as underused
@ApacheIceberg
features that are available in
#AWS
S3
#datalake
#apacheiceberg
#datalakehouse
0
3
8
Great talk from SK Telecom from the recent
@trinodb
summit, and their journey to
#iceberg
from
#hive
.
@IcebergDevs

0
2
8
@ProgRockRec
of Tabular with
@zeroshade
of
@VoltronData
managed to meet up for the keynote at
#SnowflakeSummit

0
2
8
Here is the surprise. Tabular is directly available in the
@starburstdata
Galaxy catalog as of today. It doesn't get much easier. Check out our latest Tabular Bits on YouTube to see it in action.

0
2
8
Want to learn more about how Snowflake can work with your Tabular managed
#ApacheIceberg
tables? Find out more on our website.
#dataengineering
#snowflakesummit2023
#datalakehouse
#datawarehouse
0
2
8
The
@ApacheIceberg
newsletter for March is here. Lots of big news with version 1.2,
#ApacheSpark
,
#ApacheFlink
and vendor support.

0
3
8

ICYMI: Here is the recording 🎞 🎬 of last week's webinar
"7 best practices for a successful Apache Iceberg implementation"
Good advice to help you on your journey from
#ApacheIceberg
PMC member and Tabular CTO Dan Weeks.

0
1
8
In the first episode of "Ask the Iceberg Experts" for 2023, we talk about the very exciting REST catalog for Iceberg, with Iceberg co-creator, co-founder, and Head of Engineering at Tabular, Daniel Weeks.
#apacheiceberg
#datalake
#datalakehouse
#tabular
0
3
8

0
1
8
Want an
#apacheiceberg
video snack 🍕 🥜 🍪 ... or 6? We just excerpted the best practices from our recent webinar into some bite-sized content for your convenience. Here's the YouTube playlist. Enjoy!

0
3
8
0
2
8
This talk from
@FDriesprong
is excellent. He is doing amazing work with
#PyIceberg
and
#ApacheIceberg
in general.

Last week our very own
@MatthijsBrs
shared one of the
#PDAmsterdam2023
talks he thinks you shouldn't miss;
@FDriesprong
's talk on PyIceberg, which is the
#python
implementation of
#apacheiceberg
▶ 💯 Check out your favourite(s) in our program:
0
1
6
0
1
8
As April comes to a close, it's time to look at all the great things that happened with
@ApacheIceberg
this month.
#DataEngineering
0
3
8
Mehul Batra has a very informative new blog on utilizing
#ApacheFlink
with AWS Glue Catalog and
#ApacheIceberg
to build a robust real-time
#datalakehouse
architecture. Check it out!
#dataengineering

0
0
8
For devs and data engineers.
@daveklein
reboots his "random pizza business" to demonstrate how to stream events from
#apachekafka
to
#apacheiceberg
using the Iceberg Kafka Connect sink. Includes code and a github repo. Enjoy! 🍕 🍕 🍕

0
2
7
We now have integrated Athena/
#PySpark
support in Tabular. This interactive demo will show you how simple it all is.
#apacheiceberg
#aws
#datalake
#DataEngineering
0
4
8
Amazon Web Services (AWS) announced the preview release of
#ApacheIceberg
query support from
#Redshift
. This is great news for the rapidly expanding support of
#Iceberg
from the industry.

0
2
7
0
1
7
#apacheiceberg
was a big deal at
#kafkasummit
London. You can read a synopsis from our Kafka-maven
@daveklein
in our latest blog post.
0
1
6
Part 2 of the CDC blog series from
@TabularBlue
is now available. Transactional consistency is the topic.
#cdc
#datalake
#dataengineering
2
1
7
Our co-founder and Head of Product, Jason Reid will be joining a fireside chat and AMA with
@hugobowne
of
@OuterboundsHQ
on June 7 at 4:30pm PT. They'll cover the Open-Source Modern Data Stack. Sign up for this free event at this link:
#dataengineering
0
3
7
Dave Klein, the human within which all things streaming meets Tabular, spent some time at last week's
#Current_conference
and had these observations about
#Kafka
,
#Flink
and never ending streaming v. batch debate.
Give it a read:
0
2
7

Just in case you didn't pick up the big announcement in the
#ApacheIceberg
Community News yesterday. Version 1.3 of
#Iceberg
is now available. It includes performance improvements, more vendor integrations, and much more. Check out the details:
0
2
7
Our next
#webinar
Nov 15 will cover methods for implementing change data capture
#cdc
from
#mysql
and other databases into
#ApacheIceberg
, also showing off the slick way Tabular mirrors your databases.
Sign up here:

0
2
7
If you're in NYC 🍎 right after the eclipse 🕶, head over to Javitz to hear
#apacheiceberg
co-creator Ryan Blue talk about how open table formats are revolutionizing data architecture.

1
3
6
We will be at the
@dremio
organized
#Subsurface
conference in San Francisco on March 1 if you'd like to meet up. Our CEO and
#apacheiceberg
co-creator, Ryan Blue will be speaking and on an
#iceberg
panel. Come say hi :)
1
3
7
This time on "Ask the Iceberg Experts", we talk to Thomas Cardenas, a senior software engineer at
@Ancestry
about how he implemented and optimized a 100 billion row table in
#ApacheIceberg
#datalake
#datalakehouse
#dataengineering
0
2
7