

Nikita Shamgunov
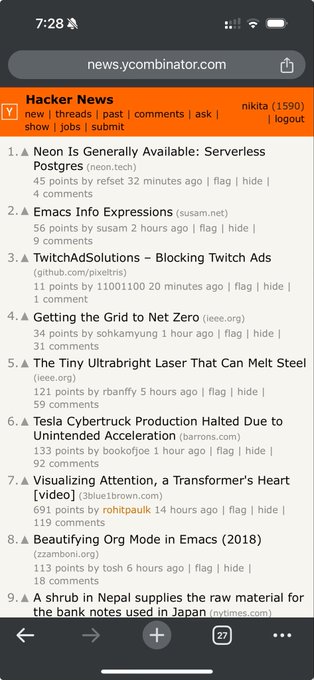
@nikitabase
Followers
7,516
Following
1,918
Media
165
Statuses
3,681
Explore trending content on Musk Viewer
Into the Depth with YUTA
• 40114 Tweets
TEN FIREWORK IT
• 36660 Tweets
ORM BKK INTER CATWALK
• 33748 Tweets
#素のまんま
• 28647 Tweets
JACK AND JOKER FLEXTALK
• 19597 Tweets
SB19 LIVE
• 18548 Tweets
タリーズ
• 18161 Tweets
True Way Of Worship
• 16239 Tweets
紫耀くん
• 15525 Tweets
Mauritius
• 13187 Tweets
マックス
• 12172 Tweets
Chagos Islands
• 11411 Tweets
コータロー
• 11298 Tweets
OHMLENG HAPPINESS FAIR
• 11046 Tweets
イグナイター
• 10860 Tweets
チカッパ
• 10730 Tweets


















Pinned Tweet

Formula for an infrastructure startup success:
- Find a 10x architectural advantage in cost and speed in a large category.
- Build a freakishly good engineering team to implement the architecture in a narrow but deep product.
- Relentlessly drive user experience.
20
50
378

Postgres has low connection limits, many settings that require restarts to change, and difficulty parallelizing because of an early decision to make it a multi-process architecture.
My cofounder Heikki presented at pgconf on making Postgres multithreaded. Here’s a summary, links
14
103
881
Every company should have access to an LLM that is tuned on ALL the enterprise data, connected to the data warehouse, and able to have a dialog about it. This time around it feels like a much bigger idea compared to attempts at enterprise search.
69
59
770
Database architecture thread. Technical. There has been several startups building an operational relational databases focused on OLTP with a shared nothing architecture.
@neondatabase
is using a different approach - shared storage. What's the difference?
12
68
430
I came to the US in 2005, spoke no English, and had $400 to my net worth. 18 years later I'm building a second tech company and still in awe of how it all came about. Greatest country on Earth! 🇺🇸🚀🫡
10
9
334

Today we are announcing
@neondatabase
integration with
@vercel
previews which allows you to have a dedicated Postgres environment for every preview. 🧵
13
8
236

The economics of running database as a service and offering a free tier are brutal. Each database instance burns at least a VM or a set of VMs (for distributed or HA flavors) 👇
16
22
195

Big
@neondatabase
news: We’re expanding to Azure, first with Azure regions in Neon console, deeper integration after that. This is backed by a strategic investment from M12 (MSFT VC arm)
Full story in thread:
13
32
180

Visiting Miami exceeded my expectations. A week of high quality meetings, great energy, and a ton of interesting people. Thank you
@rabois
@zsims
@AriannaSimpson
@cgarret_15
@marcbhargava
@bunsen
and many more for being tour guides. I'm coming back soon.
#miamitech
!
5
11
167
I'm excited to announce that
@neondatabase
crossed 100,000 databases under management. Up from under 9,000 on January 1st this year. This growth wouldn't be possible without our partners
@vercel
,
@Replit
,
@HasuraHQ
and over a dozen more and counting. 1/N
6
10
163
Postgres is missing an analytics engine. puts it at the bottom of the list and ~1000x slower than
@duckdb
and
@ClickHouseDB
.
Here are the scenarios and how to address them 🧵
10
17
158


Russia was denied participation in IMO. It’s unbelievable how dumb that is
19
5
147
pg_duckdb is doing alright. Analytics for Postgres is near!

1
13
144
The next gen data platform at the infrastructure level may just be Postgres for everything OLTP and DuckDb for everything analytics. They will also integrate super well.
15
13
144
Staging is dead. Long live previews!

6
13
137
Excited to partner with
@duckdblabs
and
@motherduck
and announce pg_duckdb - analytics extension for Postgres done right.
Clickbench will look lit shortly.

1
10
131
We had
@cognition_labs
Devin migrate a codebase from another database to Postgres.
It worked.
I'll be talking about it at WeAreDevelopers World Congress in Berlin. Thursday at 4pm, Stage 4. Don't miss.
8
15
125

@gokulr
Check out “the upside of stress”. We believe stress is bad for us, but this is a myth. We are conflating different types of stress - the stress of running a company is good stress.
4
7
105
People should not use EBS when building cloud native infrastructure services. Too expensive

11
6
104

Postgres is the future. I want to extend my congratulations to
@kiwicopple
and supabase GA.
Both
@neondatabase
and
@supabase
raised 100M+ and invest heavily into the Postgres ecosystem.

Postgres is the Linux of databases. An open 'kernel' that developers love, a strong ecosystem forms around, and from which distributions emerge.
Congrats to two of them,
@supabase
and
@neondatabase
, on going GA today:
9
37
323
6
8
99
More detail and discussion in full conference talk
Wiki on multithreading

4
10
101
Here is our take on database branching that is coming to
@neondatabase
. Creating a branch is an O(metadata) operation regardless of the database size. Here are some the use cases 1/n:
4
7
97
In an early stage startup you will personally know the founders, company strategy, fundraising, board members, what worked and what doesn’t and a ton of important company building details. If you want to build a mega career join early!
1
14
98
Will challenge any database founder in a ping pong match!
15
4
89
Beyond thrilled for the
@neondatabase
partnership with
@vercel
to deliver serverless Postgres

Introducing Vercel Storage
◆ Vercel Postgres: Serverless and Edge-ready SQL
◆ Vercel KV: Durable, global, serverless Redis
◆ Vercel Blob: Fast, simple file storage
211
1K
5K
5
11
85
@abizareyhan
@PlanetScale
@neondatabase
Nope. We designed our system that it runs super efficiently at the low end. Scale to 0 and fast cold starts help.
6
2
86
We upgraded the Neon autoscaling algo to keep the working set in memory. It’s showing up to 8x improvement in throughput on read-heavy workloads:
TL;DR in thread, link to post at end 👇
1
4
85
I owe my entrepreneurial career to
@paulg
and YC. I moved to California because I read Paul’s essays.

YC has always had a lot of people implying that it sucks.
notably this almost always comes from other investors (who are not thrilled about founders being more empowered and having such a good option)
78
95
2K
3
1
84
Neon is obsessed about the durability of your data. We store data in 6 copies two of which are on S3
1. 3 local copies of across 3 AZs for WAL in a Paxos cluster
2. In addition to that All WAL is stored on S3 (99.999999% durability)
3. 1 copy of each page is stored on the page
5
4
82


Excited to have both
@SnowflakeDB
and
@databricks
participating in the
@neondatabase
series B round:
5
4
78
There are reasons to choose pgvector over
@pinecone
. The biggest is flexibility and ability to tinker with the database which is unparalleled. If you feel like pgvector is slow I'd love to see an example.

4
13
77
This is why
@neondatabase
we didn't invest in BYOC (bring your own cloud) and went the Snowflake route: database is a URL. Multi-tenancy is a huge deal

5
6
73
When you work on databases for a long time you get to appreciate storage technology. A lot.
4
3
72

Every major database vendor will implement Vector data type and ANN search. Postgres is already there.
What's going to be act 2 for both dedicated vector databases and general purpose ones?
19
5
73
The industry is slowly realizing that
@neondatabase
has built an incredibly valuable piece of technology
7
6
72

Every new database engine requires a query optimizer. And it's just a TON of work. We couldn't get one off the shelf in the past - Apache Calcite was an interesting attempt, but it didn't translate to OLTP or native languages. Hopeful for this effort!

Its happening! Database researchers are starting to use
@ApacheArrow
DataFusion (e.g.
@CMUDB
's ). It is a good opportunity here I think for students to work with an industrial system designed to be open. Also,
@rustlang
8
44
274
9
9
69
Microsoft is incredibly dominant in devtools: GitHub, VSCode, typescript, npm, and 50% stake in OpenAI. But they don't have
@Replit
and that's where AI generated apps will end up living.
12
3
70
Excited for
@neondatabase
to make the top 100 infrastructure companies this year!


The Redpoint Infrared 100 is now live.
Our list of 100 transformative companies in cloud infrastructure.
See the full list:
10
28
108
3
5
70
We built a Postgres extension
@neondatabase
that is 20x faster than pgvector: HNSW index in Postgres with pg_embedding.

2
6
69
Someone casually uploaded ~1Tb of data over the weekend into a
@neondatabase
project. No planning, no sizing. Database is just a url.
5
2
69
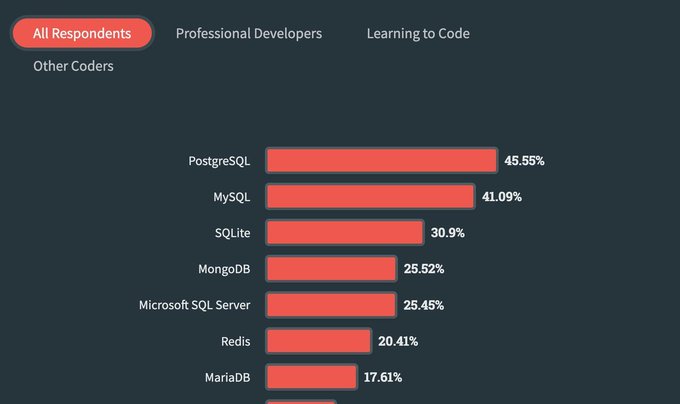
Postgres is now the top developer choice ahead of MySQL.
@neondatabase
we debated if we should support both (like AWS Aurora), but then chose to focus just on Postgres. Serverless only, cloud only, and Postgres only.

4
5
67
US and Europe should open the borders for the tech talent in Russia and Ukraine. This could be the largest talent migration comparable to exodus on 2M Jews in the 1990ies. What do you think?
6
3
65
SQL over HTTP is not standardized, but very useful.
@davidrfgomes
provides a good comparison for most popular approaches:
2
5
62
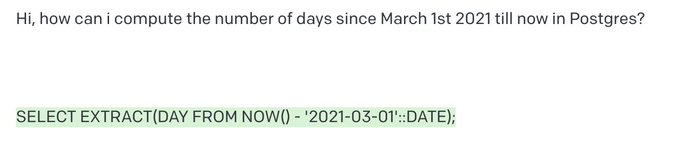
Things that will be possible in a database platform when we apply AI and LLMs 1/n:
6
5
62
I’m finding myself at the very bottom of this picture :)

5
3
60
None of this will happen without serious work, it’s a long process (several years), there are still unanswered questions. But Heikki (and I and many others) think it’s worthwhile. Multithreaded Postgres could be more efficient, simpler to use, easier to extend and develop.
2
0
60

@natfriedman
Google took a generation of the best engineering talent, but hasn’t shipped anything in a decade. It’s about time
1
1
53
Postgres process per connection is super annoying and PgBouncer is a common solution. But it didn’t support prepared statements which made it super awkward as you need two connection strings and not one. The right thing was to fix PgBouncer which is exactly what we did.

PgBouncer: The one with prepared statements
We’re happy to announce Neon’s support for PgBouncer 1.22.0.
This latest release increases query throughput by 15% to 250% and includes support for DEALLOCATE ALL and DISCARD ALL, as well as protocol-level prepared statements
1
4
38
1
9
56
End to end tracing from app to database internals:
- app
@vercel
- database
@neondatabase
- observability
@newrelic
- Postgres tracing plugin pg_tracing by
@datadoghq
Demo: cofounder of
@neondatabase
Heikki Linnakangas
3
9
55
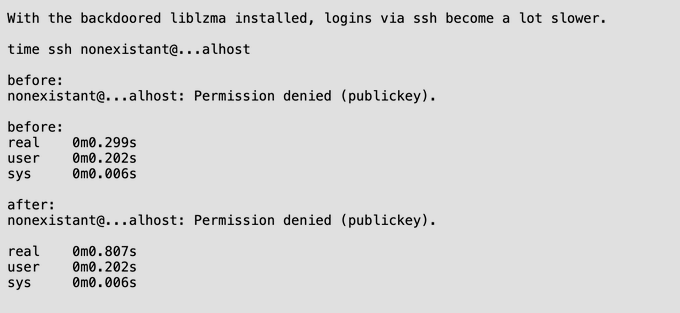
When building system software you get to build up a ton of intuition of how fast things should be. But adding two and two and running through a profiler is A+ level of competence.

The xz backdoor was initially caught by a software engineer at Microsoft. He noticed 500ms lag and thought something was suspicious.
This is the Silver Back Gorilla of nerds. The internet final boss.

159
3K
20K
1
2
54
Thank you
@MenloVentures
for leading our Series B! The photo had to be from
@BarrysBootcamp
:)
.

6
5
54
Very excited to launch the second puzzle piece after separating storage for
@neondatabase
. Autoscaling with live VM migrations. All code is opensourced!

3
7
53
With
@neondatabase
now GA, the homepage needed a redesign to better showcase the platform's features and capabilities.
6
4
53
A place where it would be super useful is database migrations. Stored procedures in legacy systems like Oracle, Sybase, IBM, and Microsoft are notoriously hard to move to anything modern and allow them to extort existing customer. This will allow moving all tier2 apps from
4
0
53


Sql Server is nosediving. Great product, but I think we are witnessing a generational change where younger people just don’t know it even exists
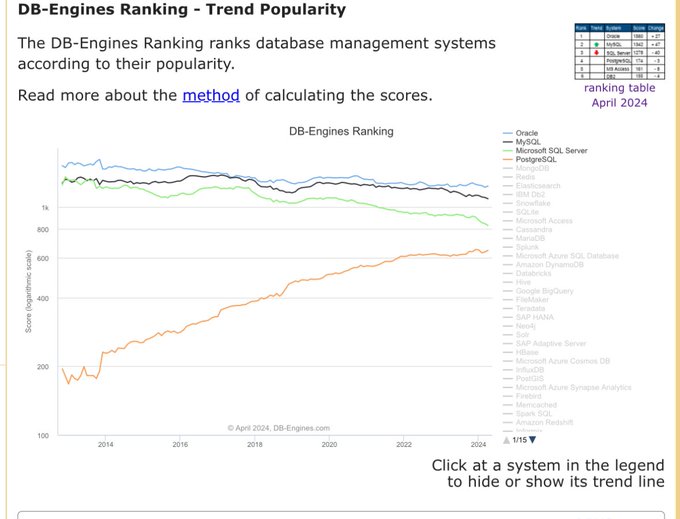
12
3
51

Amazed by the tailwinds of the Postgres ecosystem we get here
@neondatabase
. Every data vendor is building vector functionality in response to change in the market. We just embed pgvector. Same for PostGIS, Postgres anonymizes for PII data, postgREST for rest APIs and more. We
7
4
49
Excited to be an investor in the future of app development!
@khoslaventures
🤝
@Replit

We raised a Series B extension of $97.4M at a $1.16B valuation, up from our 2021 Series B.
We’ll use the funds to expand our cloud services and build our lead in AI for software creation.
Our mission to empower a billion software developers is one step closer!
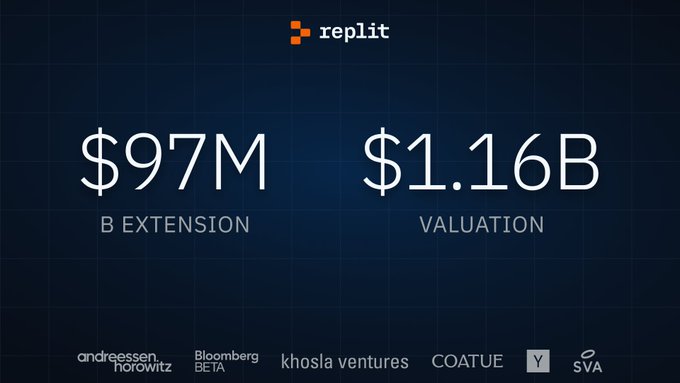
53
167
2K
2
2
48
The problem is the shared memory. When Postgres starts it has to pre-allocate a fixed amount of memory, the size of which is mostly driven by max number of processes (max_connections). If you have max_connections set to 100 that’s 100x memory, 200 is 200x memory.
The need to
1
0
47
In the first year of memsql (now
@SingleStoreDB
) our best engineer quit. We managed to talk it through, he then stayed for another 5 years, left of good terms and built a giant company after which i invested into.
I still feel a jolt of fear just remembering that moment.

“When you talk to people who’ve been investors their entire lives… they don’t know what it’s really like...”
@eladgil
is on the podcast. Episode out Thursday.
9
36
339
1
1
48
Postgres today: each connection gets a new process, and all processes access the same shared memory to coordinate.

2
0
48
Multithreading Postgres makes Postgres hacking easier:
Cheaper connections, no need for a pool
Changing settings without restart
Shared caches - plan caches, relcaches (metadata)
Resizing fixed-size shared memory areas
EXPLAIN ANALYZE on the fly
Limiting memory usage per
3
1
47
I'm excited to launch a discord service today
@neondatabase
. Some believe that you should only use forums b/c it accumulates content vs it disappears on discord.
But I think the world has moved on and expects much faster interaction with the community.
You can read the full article on why we chose Discord as the platform for hosting our community.
0
1
6
4
4
45
There is a misconception we see pushed by other databases: "DBs that scale to zero aren't production-ready" - That's silly , scale to zero is great for everyone from indie hackers to massive platforms.
11
5
45
We partner with companies who are just as obsessed with
#devx
as we are. Excited to provide
@PostgreSQL
to
@Replit
.

0
5
44
Here is a summary why people love Postgres over MySQL:
- Full features and rock solid. MySQL is quite reliable too, but def not full featured
- MySQL stopped innovating (b/c Oracle)
- Extensions. Especially PostGIS and Timescale. Now pgvector
- License. GPL vs Postgres (which is
5
9
42
1/
Reflecting on Neon’s GA announcement yesterday and the new releases today - We are just getting started
During this past year, we’ve shipped major improvements to Neon internals and we’re now ready to support your mission-critical workloads. +700,000 databases are now
2
6
44
This looks like an incredible piece of work by
@TimescaleDB
implementing DiskANN AND with a permissive license!
DiskANN is used across the board at Microsoft and has many benefits.
@neondatabase
team is testing it now and will share our results soon!

PGVECTOR IS NOW FASTER THAN PINECONE. And 75% cheaper thanks to a new open-source extension – introducing pgvectorscale.
🐘 What is pgvectorscale?
Pgvectorscale is an open-source PostgreSQL extension that builds on pgvector, enabling greater performance and scalability (keep

41
226
1K
2
6
44

Excited to share the vision of
@neondatabase
with NYSE.

Nikita Shamgunov, Founder + CEO of Neon, talks about the future of serverless database technology and how their Postgres solutions are revolutionizing data management and efficiency on
#NYSEFloorTalk
with
@JudyKShaw
@MadronaVentures
#IA40
|
@neondatabase
|
@nikitabase
1
10
22
5
5
43
Scaling to zero doesn't matter much for a single db instance. But it matters hugely when you are managing a fleet. And every company has a fleet now - dev, test, staging and beyond: a preview database for every commit. That's what we delivered on with
@neondatabase
4
3
42

The most successful systems are shared storage: Oracle RAC, SQL Server Hyperscale, and AWS Aurora.
@neondatabase
is shared storage which lets us be serverless.
And shared nothing OLTP systems are destined to stay niche.
12
3
42