

Jiacheng Liu
@liujc1998
Followers
1,196
Following
197
Media
70
Statuses
273
🎓 PhD student @uwcse @uwnlp . 🛩 Private pilot. Previously: 🧑💻 @oculus , 🎓 @IllinoisCS . 📖 🥾 🚴♂️ 🎵 ♠️
Joined November 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1203388 Tweets
Liz Cheney
• 209584 Tweets
#LISAxMoonlitFloor
• 197221 Tweets
MOONLIT FLOOR OUT NOW
• 137932 Tweets
SCJN
• 128619 Tweets
The Boss
• 103770 Tweets
#GHGala5
• 100032 Tweets
Bruce
• 92338 Tweets
Mets
• 69981 Tweets
Happy Anniversary
• 59797 Tweets
Baker
• 51010 Tweets
Brewers
• 42600 Tweets
EL DESTELLO IS OUT
• 34794 Tweets
天使の日
• 33230 Tweets
Falcons
• 29013 Tweets
Mancuso
• 25832 Tweets
Halle
• 24850 Tweets
もちづきさん
• 24728 Tweets
Pete Alonso
• 19614 Tweets
Athena
• 15232 Tweets
Mike Evans
• 14530 Tweets
Bijan
• 13510 Tweets
Phillies
• 11404 Tweets
#ゴンチャのハロウィン準備中
• 10748 Tweets
Milwaukee
• 10479 Tweets
Quintana
• 10036 Tweets




















What if we combine PPO with Monte-Carlo Tree Search – the secret sauce for AlphaGo to reach superhuman performance?
Spoiler: MAGIC!! Our inference-time decoding method, PPO-MCTS, achieves impressive results across many text generation tasks.
📜
🧵(1/n)
9
101
455
It’s year 2024, and n-gram LMs are making a comeback!!
We develop infini-gram, an engine that efficiently processes n-gram queries with unbounded n and trillion-token corpora. It takes merely 20 milliseconds to count the frequency of an arbitrarily long n-gram in RedPajama (1.4T

11
90
382
Is your favorite LLM still making simple commonsense mistakes? 🤯
Meet Vera, a model that estimates plausibility of commonsense statements, thereby flagging ⛳ errors made by generative LMs like ChatGPT. 🤖
Try our demo!
🧵(1/n)

3
64
212
Can LMs introspect the commonsense knowledge that underpins the reasoning of QA?
In our
#EMNLP2022
paper, we show that relatively small models (<< GPT-3), trained with RLMF (RL with Model Feedback), can generate natural language knowledge that bridges reasoning gaps. ⚛️
(1/n)

1
43
193
Our paper, “Generated Knowledge Prompting for Commonsense Reasoning”, is accepted to the
#acl2022nlp
main conference! 🎉
🌟Elicit ⚛️ symbolic knowledge from 🧠 language models using few-shot demos
🌟Integrate model-generated knowledge in commonsense predictions 💡
@uwnlp
(1/N)

3
35
158
Introducing 🔮Crystal🔮, an LM that conducts “introspective reasoning” and shows its reasoning process for QA. This improves both QA accuracy and human interpretability => Reasoning made Crystal clear!
Demo:
at
#EMNLP2023
🧵(1/n)

2
30
138
Introducing the infini-gram search engine:
Infini-gram allows you to search documents and count n-grams in trillion-token text corpora. This might enable us to further understand what contents LLMs are trained on.
We show a demo video below, and here’s
2
18
88
On what NLP problems academia can work on in the advent of GPT-4, here's my 2cents on what's still missing from GPT-4-alikes:
1. Persistent memory
2. Robust instruction following
3. Expressing belief & confidence
4. Robust chain-of-reasoning
more in blog:
0
11
83
The infini-gram paper is updated with the incredible feedback from the online community 🧡 We added references to papers of
@JeffDean
@yeewhye
@EhsanShareghi
@EdwardRaffML
et al.
Also happy to share that the infini-gram API has served 30 million queries!

2
13
77
Big milestone! Welcome Dolma to infini-gram 📖, now available on our web interface and API endpoint.
This brings the total size of the infini-gram indexes to 5 trillion tokens and about 5 quadrillion (5 x 10^15) unique n-grams. It is the largest n-gram LM ever built, both by the

2
12
60
Today we’re adding Dolma-sample to infini-gram 📖
Dolma-sample (8 billion tokens) is a sample of the full Dolma dataset (3 trillion tokens), which is used to pre-train
@allen_ai
's open-source OLMo model.
Use infini-gram to get a sense of what data OLMo is trained on:

It’s year 2024, and n-gram LMs are making a comeback!!
We develop infini-gram, an engine that efficiently processes n-gram queries with unbounded n and trillion-token corpora. It takes merely 20 milliseconds to count the frequency of an arbitrarily long n-gram in RedPajama (1.4T
11
90
382
2
6
48
[Fun w/ infini-gram
#3
] Today we’re tracing down the cause of memorization traps 🪤
Memorization trap is a type of prompt where memorization of common text can elicit undesirable behavior. For example, when the prompt is “Write a sentence about challenging common beliefs: What

1
13
43
[Fun w/ infini-gram 📖
#6
] Have you ever taken a close look at Llama-2’s vocabulary? 🧐
I used infini-gram to plot the empirical frequency of all tokens in the Llama-2 vocabulary. Here’s what I learned (and more Qs raised):
1. While Llama-2 uses a BPE tokenizer, the tokens are

6
3
41
Announcing the infini-gram API 🚀🚀
API Endpoint:
API Documentation:
No API key needed! Simply issue POST requests to the endpoint and receive the results in a fraction of a second.
As we’re in the early stage of rollout, please
4
6
39
The Vera model is now public! 🪴
We received many interests in using the Vera model for large-scale inference. Now you can set it up on your own machine.
Meanwhile, if you're looking to try out Vera, feel free to visit our demo at
Is your favorite LLM still making simple commonsense mistakes? 🤯
Meet Vera, a model that estimates plausibility of commonsense statements, thereby flagging ⛳ errors made by generative LMs like ChatGPT. 🤖
Try our demo!
🧵(1/n)
3
64
212
0
3
31
Check out our latest dataset that shows language models falling into “memorization traps”! Details in
@alisawuffles
’s thread 🧵

Presenting MemoTrap🪤, a dataset of 2.5K examples spanning text completion, translation & QA, where repeating memorized text & concepts is *not* the desired behavior. We find that LMs perform worse📉 as they scale up, revealing severe failures in simple instruction-following🧵


6
87
514
0
6
29
I’m at
#EMNLP2023
! Would love to chat with old&new friends on reasoning, search/planning, commonsense, RL, or anything!
Also I’ll present two papers, both at the 2pm session on Dec 8 @ Central1:
- Vera (commonsense verification): 2-2:15
Crystal (RL-powered reasoning): 3:15-3:30
1
2
29
Now you can transform Siri into the real
#ChatGPT
! Simply download this shortcut (link in repo ⬇️) to your iPhone, edit its script in the Shortcuts app (i.e. paste your API key into the text box), and say, "Hey Siri, ChatGPT". Ask your favorite question!

1
7
30
Vera is accepted to
#EMNLP2023
!! 🎉🎉
We’re releasing a community-contributed benchmark for commonsense evaluation, derived from user interactions with Vera in the past months. (Thanks everyone for using our demo!)
This new challenging dataset is on HF:

Is your favorite LLM still making simple commonsense mistakes? 🤯
Meet Vera, a model that estimates plausibility of commonsense statements, thereby flagging ⛳ errors made by generative LMs like ChatGPT. 🤖
Try our demo!
🧵(1/n)
3
64
212
0
1
28
Very excited that the Inverse Scaling paper is released! Our prize-winning task submission, memo-trap, is among those with the strongest and most robust inverse scaling trends.

New paper on the Inverse Scaling Prize! We detail 11 winning tasks & identify 4 causes of inverse scaling. We discuss scaling trends with PaLM/GPT4, including when scaling trends reverse for better & worse, showing that scaling trends can be misleading: 🧵

4
41
159
0
4
25
[Fun w/ infini-gram
#2
] Today we're verifying Benford's Law!
Benford's Law states that in real-life numerical datasets, the leading digit should follow a certain distribution (left fig). It has usage in detecting fraud in accounting, election data, and macroeconomic data.
The


3
2
28
Here's one of my favorites: our model constructed a nearly-perfect induction proof, by learning the pattern of induction in training data but NOT copying from any similar proofs. 🤖🎓
Amazing skills from the combination of large models, massive data, and innovative algorithms.


New paper:
Theorem proving in natural mathematical language- the mix of symbolic and natural language used by humans- tests reasoning and plays a central role in mathematical education.
Can language models prove theorems & help us when we're stuck? 1/N


3
60
213
1
4
24
If you’re following the
@OpenAI
Q* rumors, see how we combined RLHF and search: PPO + Monte-Carlo Tree Search
So don’t throw away the value model! 💎

0
5
22
The infini-gram API has served over 1 million queries during its first week of release! Thanks everyone for powering your research with our tools 🤠
Also, infini-gram now supports two additional corpora: the training sets of C4 and Pile, both in the demo and via the API. This
Announcing the infini-gram API 🚀🚀
API Endpoint:
API Documentation:
No API key needed! Simply issue POST requests to the endpoint and receive the results in a fraction of a second.
As we’re in the early stage of rollout, please
4
6
39
0
3
24
Too many things lie on continuums: 🤯
(1) What is commonsense, and what is factual knowledge?
(2) What is common knowledge, and what is domain knowledge?
(3) What is memorization, and what is generalization?
(4) What is personal information, and what is common fact?
etc.
1
1
21
(7/n) We will be releasing PPO-MCTS as a plugin so that you can apply it to your existing text generation code. Stay tuned!
Huge kudos to my amazing collaborators and advisors at
@uwnlp
@MetaAI
@AIatMeta
:
@andrew_e_cohen
@ramakanth1729
@YejinChoinka
@HannaHajishirzi
@real_asli
0
2
19
(7/n) Above all, infini-gram requires 0 GPU for both training and inference!! 🙈🙈 So if you’re one of those GPU-poor NLP students like me, come and build your work on infini-gram 💸😎

1
1
20
[Fun w/ infini-gram
#1
] Today let’s look up some of the longest English words in RedPajama. 😎
honorificabilitudinitatibus (27 letters, 7 tokens, longest word in Shakespeare's works): 1093 occurrences
pneumonoultramicroscopicsilicovolcanoconiosis (45 letters, 17 tokens; some

1
4
19
This made me thinking -- many commonsense mistakes made by ChatGPT may be caused by the LM trying to defend an answer it already gave. This is an inherent problem of retrospective, post-hoc explanations, which seem to be what ChatGPT frequently does.
pc:

0
2
18
The 🏔️Rainier model is now on huggingface!
Also, try out introspective reasoning with Rainier in this web demo:
I will be presenting the Rainier paper at
#emnlp2022
. Please come find our poster stand, Dec10 11am in the atrium!

Can LMs introspect the commonsense knowledge that underpins the reasoning of QA?
In our
#EMNLP2022
paper, we show that relatively small models (<< GPT-3), trained with RLMF (RL with Model Feedback), can generate natural language knowledge that bridges reasoning gaps. ⚛️
(1/n)
1
43
193
0
2
18
(3/n) We trained Rainier with a multitask setting so that it can work in many commonsense domains, including:
🧠 General commonsense
🧪 Scientific commonsense
🪐 Physical commonsense
🙋 Social commonsense
🔢 Numerical commonsense
…

1
3
15
[Fun w/ infini-gram 📖
#4
] A belated happy Chinese New Year! 🐉 How about a battle for popularity among the 12 Zodiacs?
When counting by their English names, Dog appears most frequently in RedPajama, followed by Dragon and Rat.
However, when counting by their Chinese names, the


1
2
14
(2/n) The model we present - which we refer to as “Rainier” 🏔️, or Reinforced Knowledge Introspector - is an encoder-decoder LM that generates natural language knowledge statements conditioned on the input question.
The beautiful Mt. Rainier seen from Seattle, WA ⬇️

1
2
13
(8/n) Beyond our efforts, we envision that infini-gram can be useful in many additional areas:
1. Understanding massive text corpora
2. Data curation
3. Attribution
4. Detecting data contamination, memorization, and plagiarism
5. Mitigating copyright infringement
6. Reducing
1
0
12
The infini-gram engine just got 10x faster! 🚀🚀🚀
Try infini-gram here:
To experience faster inference, select the “C++” engine before submitting your query.
On RedPajama (1.4T tokens), the C++ engine can process count queries in 20 milliseconds on

3
2
12
Awesome work! Excited to see that our commonsense model, Vera, is employed to characterize and filter textual artifacts, resulting in higher-quality negatives for V-L compositionality dataset! ☘️


Introducing SugarCrepe: A benchmark for faithful vision-language compositionality evaluation!
‼️ Current compositional image2text benchmarks are HACKABLE: Blind models without image access outperform SOTA CLIP models due to severe dataset artifacts
📜:

1
20
93
0
0
12
@alisawuffles
and I will soon be presenting this cool knowledge generation method in
#acl2022nlp
! 🤠 Feel free to stop by in one of our poster sessions:
[In-person]: Mon 05/23, 17:00 IST (PS3-5 Question Answering)
[Online]: Tue 05/24, 07:30 IST (23:30 PT) (VPS1 on GatherTown)
Our paper, “Generated Knowledge Prompting for Commonsense Reasoning”, is accepted to the
#acl2022nlp
main conference! 🎉
🌟Elicit ⚛️ symbolic knowledge from 🧠 language models using few-shot demos
🌟Integrate model-generated knowledge in commonsense predictions 💡
@uwnlp
(1/N)
3
35
158
0
4
12
(4/n) The infini-gram index is a data structure called “suffix array”, which stores the ranking of all suffixes of a byte array. In our use case, the byte array is the concatenation of all (tokenized) documents in the corpora.
Here’s an illustration of how suffix array works:

1
0
12
Thanks for featuring our work
@_akhaliq
!! 😍
Super excited to announce the infini-gram engine that counts long n-grams and retrieve documents within TB-scale text corpora, with millisecond-level latency.
Look forward to enabling more scrutiny into what LLMs are being trained on.

Here is my selection of papers for today (1 Feb) on Hugging Face
Advances in 3D Generation: A Survey
ReplaceAnything3D:Text-Guided 3D Scene Editing with Compositional Neural Radiance Fields
Anything in Any Scene: Photorealistic Video Object Insertion

0
9
44
0
1
11
(3/n) Interpolating with ∞-gram reduces the perplexity of neural LLMs by up to 73%, and this works even when the neural LLM is Llama-2-70B! ∞-gram also outperforms kNN-LM and RIC-LM as retrieval-augmentation strategy used by the SILO model (Min et al., 2023).


1
0
10
(6/n) Our analyses show that:
1. PPO’s value model is more suitable in guiding MCTS decoding than the reward model
2. MCTS is a better search algorithm than other alternatives, e.g. stepwise-value
3. PPO-MCTS yields better reward-fluency tradeoff than over-training PPO

1
2
9
(9/n) We host pre-built indexes on popular corpora (RedPajama and Pile) through the HF demo, and we’re planning to host a public API. Please suggest which dataset(s) you’d like us to support!
We will also open-source the infini-gram engine so that YOU, by beloved readers, can
1
0
9
(6/n) The suffix array occupies O(N) space and can be built in O(N) time.
Inference is lightning fast! On RedPajama, n-gram counting is 20 milliseconds (regardless how large n is); n-gram LM probability estimation and decoding is within 40 milliseconds per query. ∞-gram takes a

1
3
8
@arankomatsuzaki
Check out infini-gram:
- ∞-gram LM (i.e. n-gram LM with unbounded n)
- 1.4 trillion tokens
- About 1 quadrillion (10^15) n-grams
- Trained on 80 CPUs in 2 days
- Perplexity = 19.8 (when interpolated between different n's); PPL = 3.95 (when interpolated with Llama-2-70B)
0
0
9
@sewon__min
@LukeZettlemoyer
@YejinChoinka
@HannaHajishirzi
(2/n) Using the ∞-gram framework and infini-gram engine, we gain new insights into human-written and machine-generated text.
∞-gram is predictive of human-written text on 47% of all tokens, and this is a lot higher than 5-gram (29%). This prediction accuracy is much higher


1
0
6
(10/n) Tons of thanks to my amazing collaborator
@sewon__min
and advisors
@LukeZettlemoyer
@YejinChoinka
@HannaHajishirzi
, as well as friends at
@uwnlp
@allen_ai
@AIatMeta
for sharing your invaluable feedback during our journey! 🥰🥰
0
0
9

1
0
7
(7/n) Paper available at
Stay tuned for the camera-ready version and the code!
Huge thanks to my wonderful collaborators at
@uwnlp
@allen_ai
and
@PetuumInc
! --
@SkylerHallinan
@GXiming
@hepengfe
@wellecks
@HannaHajishirzi
@YejinChoinka
2
0
8
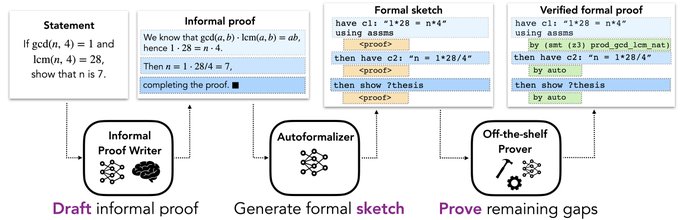
Check out our recent cool work on solving and formally proving competition-level math problems, using informal provers and autoformalizers! Led by
@AlbertQJiang
🎓

Large language models can write informal proofs, translate them into formal ones, and achieve SoTA performance in proving competition-level maths problems!
LM-generated informal proofs are sometimes more useful than the human ground truth 🤯
Preprint:
🧵
8
152
662
0
0
8
(5/n) We tested PPO-MCTS on 4 text generation tasks. PPO-MCTS is much better than the PPO policy baseline on all tasks, yielding 30% higher success rate on sentiment steering, 34% reduced toxicity, 12% more useful commonsense knowledge, and 5% higher win rate in chat completion.

1
1
6
(7/N) Paper available at
Huge thanks to my wonderful collaborators at
@uwnlp
and
@allen_ai
:
@alisawuffles
@GXiming
@wellecks
@PeterWestTM
@Ronan_LeBras
@YejinChoinka
@HannaHajishirzi
0
0
7
[Fun w/ infini-gram 📖
#5
] What does RedPajama say about Letter Frequency?
Image shows the letter distribution. Seems that there’s a lot less letter “h” in RedPajama than expected (using Wikipedia page as gold reference: ). Thoughts? 🤔
(I issued a single

0
1
7
(2/n) Our method, PPO-MCTS, uses value-guided MCTS decoding by recycling the “value model” trained by PPO, and achieves awesome results in text generation tasks. Based on the success of PPO-MCTS, we recommend researchers and practitioners *not* to discard their value models.

1
1
6
@DimitrisPapail
I guess stuff like "As a language model trained by OpenAI" has already diffused into and polluted our pretraining data 🤣🤣

0
0
7
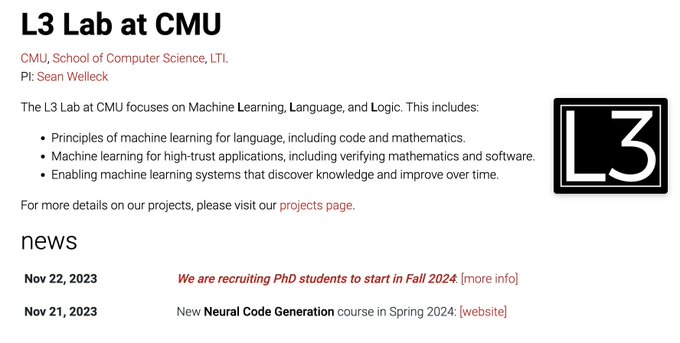
So excited to see the launch of L3 Lab! 😍
Sean has awesome vision and years of solid work at the intersection of natural language and formal mathematics/logic. It's been a huge privilege for me to work with him at UW. Please definitely apply to
@wellecks
's lab at
@LTIatCMU
!!
Announcing the L3 Lab at CMU!
We focus on Learning, Language, and Logic, including:
- Principles of ML for language
- ML in high-trust areas, such as verifying math and programs
- ML systems that improve over time
Recruiting PhD students for fall 2024!
11
94
528
1
0
6
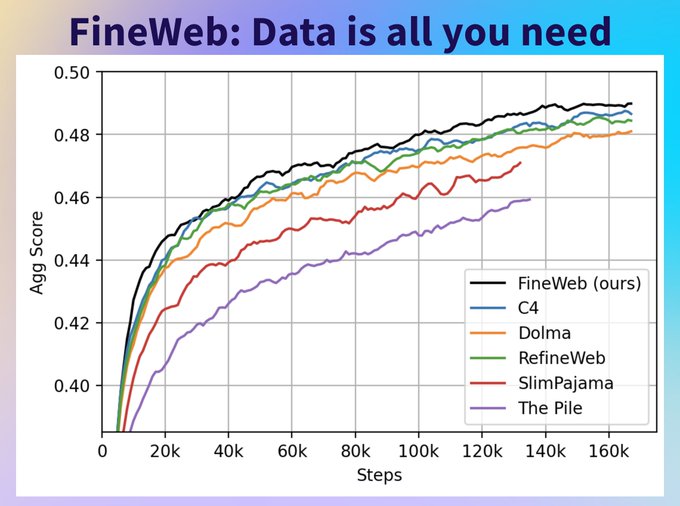
Wow 15T tokens of open data! Imagine the amount of 💸💸 I’d need to burn to bring this to infini-gram … 🤣

Data is all we need! 👑 Not only since Llama 3 have we known that data is all we need. Excited to share 🍷 FineWeb, a 15T token open-source dataset! Fineweb is a deduplicated English web dataset derived from CommonCrawl created at
@huggingface
! 🌐
TL;DR:
🌐 15T tokens of cleaned
13
86
390
0
0
7
0
0
6

(4/n) We made several innovative changes to the MCTS algorithm to better fit the PPO models, including (1) replacing edge values V with the Q function; (2) initializing the Q of children actions from the V of their parent node; (3) forbidding exploration after terminal states.
1
1
4
@chrmanning
@sewon__min
@LukeZettlemoyer
@YejinChoinka
@HannaHajishirzi
OMG thanks so much
@chrmanning
!!
Indeed strings "2000" through "2024" do appear a total of ~4 billion which account for ~70% of everything starting with digit "2". I guess year numbers also contributed a lot to digit "1".

1
0
5
(3/n) Text tokens are compared to actions in AlphaGo. To decode each token, several “simulations” are performed, where each simulation has 4 stages: select, expand, evaluate, and backup. After all simulations, a token is decoded by referencing the visit counts of the next token.

1
1
4
@JeffDean
@sewon__min
@LukeZettlemoyer
@YejinChoinka
@HannaHajishirzi
@_akhaliq
Thanks
@JeffDean
for clarifying!
We're not the largest n-gram LM (yet, stay tuned~) in terms of training data size, the honor is held by Jeff's '07 paper. Though it seems we are still the largest in the number of unique n-grams indexed.
0
0
4
Also, huge thanks to
@alisawuffles
@_julianmichael_
@rockpang6
@KaimingCheng
and Yuxuan Bao for their valuable help and feedback, and to our sharp and diligent proof evaluators from the math/amath department of UW!!
0
0
5
(4/n) Given the absence of gold knowledge annotation in most large-scale commonsense datasets, we train Rainier by optimizing the reward which indicates whether a pretrained QA model can correct its prediction given the additional knowledge. We use PPO as the RL algorithm.

1
0
5
(6/n) Rainier-generated knowledge stays relevant, is usually factually correct, and is usually helpful for answering questions in a human-interpretable way. We also found the knowledge to be diverse in terms of domain, expressed relation, and syntactic structure.

1
0
5
(5/n) Here’s an illustration of the suffix array for a trillion-token corpus:

1
0
5
@JeffDean
@_akhaliq
Also I noticed while the 2007 paper trains on 2T tokens, the number of unique n-gram entries seems to be 300B.
Our infini-gram conceptually gives ~10^24 entries on a corpus with 1T tokens. (Even when not counting across document bounds, there should be ~100T n-gram entries)
1
0
2
(3/n) Vera is built on top of T5 and finetuned on a vast collection of ~7M correct and incorrect commonsense statements sourced from 19 QA datasets and 2 knowledge bases. Training techniques include multi-stage finetuning, contrastive learning, and automatic data augmentation.
1
1
4
(5/n) Using the Generate-Prompt-Inference framework (proposed in our ACL paper), we evaluate Rainier on knowledge introspection. Rainier’s knowledge boosts QA performance across multiple benchmarks, and even outperforms the few-shot GPT-3 (Curie) while being 16x smaller in size.

1
0
4
(6/n) We’d love to hear your feedback on how we can improve Vera! Feel free to try our demo and test your favorite example about commonsense. Let us know what went well and what did not via a simple click 🖱️
The demo is located at (thanks
@huggingface
🤗)

1
1
4
(3/3) Meanwhile, if you’re just trying out infini-gram or using in small volume, please feel free to head over to our HF demo:
0
1
4
(4/n) As a statement verification model, Vera can solve commonsense problems better than GPT-3.5 and Flan-T5, with good generalization to unseen data distributions. It can act as an off-the-shelf critic model that effectively filters commonsense knowledge generated by other LMs.

1
1
4
(2/n) Given a declarative statement, Vera estimates a plausibility score for it based on commonsense. This score can be further used to predict the correctness of the statement. The score is well-calibrated, meaning it reflects Vera’s level of confidence in the prediction.
1
1
4
@jang_yoel
@HannaHajishirzi
@uwcse
@uwnlp
@LukeZettlemoyer
Welcome, Joel!! So excited for you to join the community 😆
0
0
4
(3/3) Quantitatively, for 70% of instances in memo-trap, the proverb’s last token has probability >0.5. And for 37% this probability is 1.0 (one-hot). Image shows the distribution of this probability.
We suspect that training on such data may have imparted a strong memorization

1
0
4
Highly recommend everyone working in
#NLProc
to take this 20-min survey and think about these questions! 🤗

📣 CALLING ALL NLP RESEARCHERS 📣
Do you think you have lots of minority opinions on NLP issues? Where does the research community stand? Where does the community *think* it stands? Let’s find out — take part in the NLP Community Metasurvey!
🧠💭🧠
2
92
163
0
0
4
(3/N) We set up new SOTA on the following commonsense reasoning benchmarks: NumerSense (numerical commonsense), CommonSenseQA 2.0 (general commonsense), and QASC (scientific commonsense).

1
0
3
(2/3) This analysis can be easily carried out using the infini-gram engine. I wrote only a few lines of code and got all results within a second!

1
0
3
(7/n) Vera is a research prototype and limitations apply. We hope it can be a useful tool for improving commonsense correctness in generative LMs.
Huge kudos to my amazing collaborators
@happywwy
@DianzhuoWang
and our wonderful advisors
@nlpnoah
@YejinChoinka
@HannaHajishirzi
🥰
0
1
2
(5/n) 🔮Crystal addresses the unfaithfulness issue in existing rationale-augmented reasoning methods (e.g., Chain-of-Thought distillation), by capturing and optimizing the bi-directional interaction between knowledge introspection and knowledge-grounded reasoning.

1
0
1
@TheGrizztronic
Code will be released soon! 😇
We prioritized API because it has higher demand, and even with the code it'd take quite some effort and $$$ to build the index yourself 💸💸
1
0
3
@hiroto_kurita
Very interesting mini-analysis!
This may imply that the context where these numbers would play a big role, with things around "42" being somewhat interesting / attractive 😆
0
0
3
(2/3) A few more examples:
If you snooze you ==> lose (72%)
All is fair in love and ==> war (81%)


1
0
3
@yoavartzi
@DimitrisPapail
@elmelis
@COLM_conf
@LukeZettlemoyer
@sewon__min
Hi
@yoavartzi
! Indeed we didn't rival the GPTs with the n-gram LM alone. There's a tradeoff between using richer context & getting smooth distributions, and we found this messes up with autoregressive decoding.
Love to chat more on how to reach GPT performance using counts 😊
1
0
1
(3/3) You can use the infini-gram search engine on
@huggingface
spaces today! 🤗
We will announce an API endpoint soon (currently working on optimizing latency and throughput), and we will also release the source code of infini-gram. Stay tuned!
Our
0
0
2
(5/N) The knowledge generated by our method helps commonsense predictions in an interpretable way: it reduces commonsense problems to explicit reasoning procedures -- deduction, induction, analogy, etc.

1
0
3
Updated
#ChatGPT
-in-Siri with improved interactions, debuggability, and detailed installation guides! 😎
Try it out here:

Now you can transform Siri into the real
#ChatGPT
! Simply download this shortcut (link in repo ⬇️) to your iPhone, edit its script in the Shortcuts app (i.e. paste your API key into the text box), and say, "Hey Siri, ChatGPT". Ask your favorite question!
1
7
30
0
0
2
@natolambert
@ericmitchellai
@hamishivi
If you look at the KLs, they are equal to the diff of logprobs of current policy and ref policy, and it being positive means logprobs on the "current rollouts" have increased, compared to the ref policy.
Probably not what you're looking for, though 😛
0
0
2
@EdwardRaffML
@sewon__min
@LukeZettlemoyer
@YejinChoinka
@HannaHajishirzi
Indeed. Thanks for sharing!!
0
0
2
(6/N) You ask the secret ingredients of generated knowledge prompting’s success? Generate better knowledge, generate more knowledge, and use a simple but great strategy for integrating them!


1
0
2
(3/3) Footnote: Llama tokenizer seems to tokenize all numbers into single digits. "1234" will be tokenized as ["__", "1", "2", "3", "4"]. "__" denotes the beginning of a number.
I made sure the digit is leading. E.g. for digit "1", infini-gram counts for the 2-gram ["__", "1"].
0
0
3
@yeewhye
@sewon__min
@LukeZettlemoyer
@YejinChoinka
@HannaHajishirzi
@frankdonaldwood
@cedapprox
Hi
@yeewhye
, thanks so much for sharing your paper, it looks super relevant!
It's so cool that the term "∞-gram" already appears in this '09 paper 😎
1
0
2
@kanishkamisra
@YejinChoinka
Thanks for sharing this dataset
@kanishkamisra
! It would be nice to see how well Vera can handle this type of input. It is not trained to comprehend new definitions (as in COMPS), but Vera has already surprised us on how well it can handle slightly out-of-scope tasks.
1
0
2
(4/N) Our method works for both zero-shot and fine-tuned inference models, and has the greatest impact on small models.
Meanwhile, it is worth noting that a model can even benefit from the knowledge generated by itself for the purpose of question answering.

1
0
2
(5/n) Our model, Vera, is potentially useful in detecting commonsense errors in outputs of generative LMs. On a sample of commonsense mistakes made by ChatGPT (mostly collected by
@ErnestSDavis
and
@GaryMarcus
), Vera can flag errors with a precision of 91% and a recall of 74%.

1
1
2
