

Alexander Panfilov
@kotekjedi_ml
Followers
75
Following
235
Statuses
49
IMPRS-IS & ELLIS PhD Student @ Tübingen Interested in Trustworthy ML, Security in ML and AI Safety.
Tübingen, Germany
Joined October 2013
Ever wondered which jailbreak attack offers the best bang for your buck?🤖 Check out our #NeurIPS2024 workshop paper on a realistic threat model for LLM jailbreaks! We introduce a threat model that considers both fluency and compute efficiency for fair attack comparisons. 🧵 1/n

1
14
35
Check out this mega cool work on model similarities from my colleague Shashwat! (curious how these insights are reflected in jailbreaking scenarios where we use LLM as an output filter)

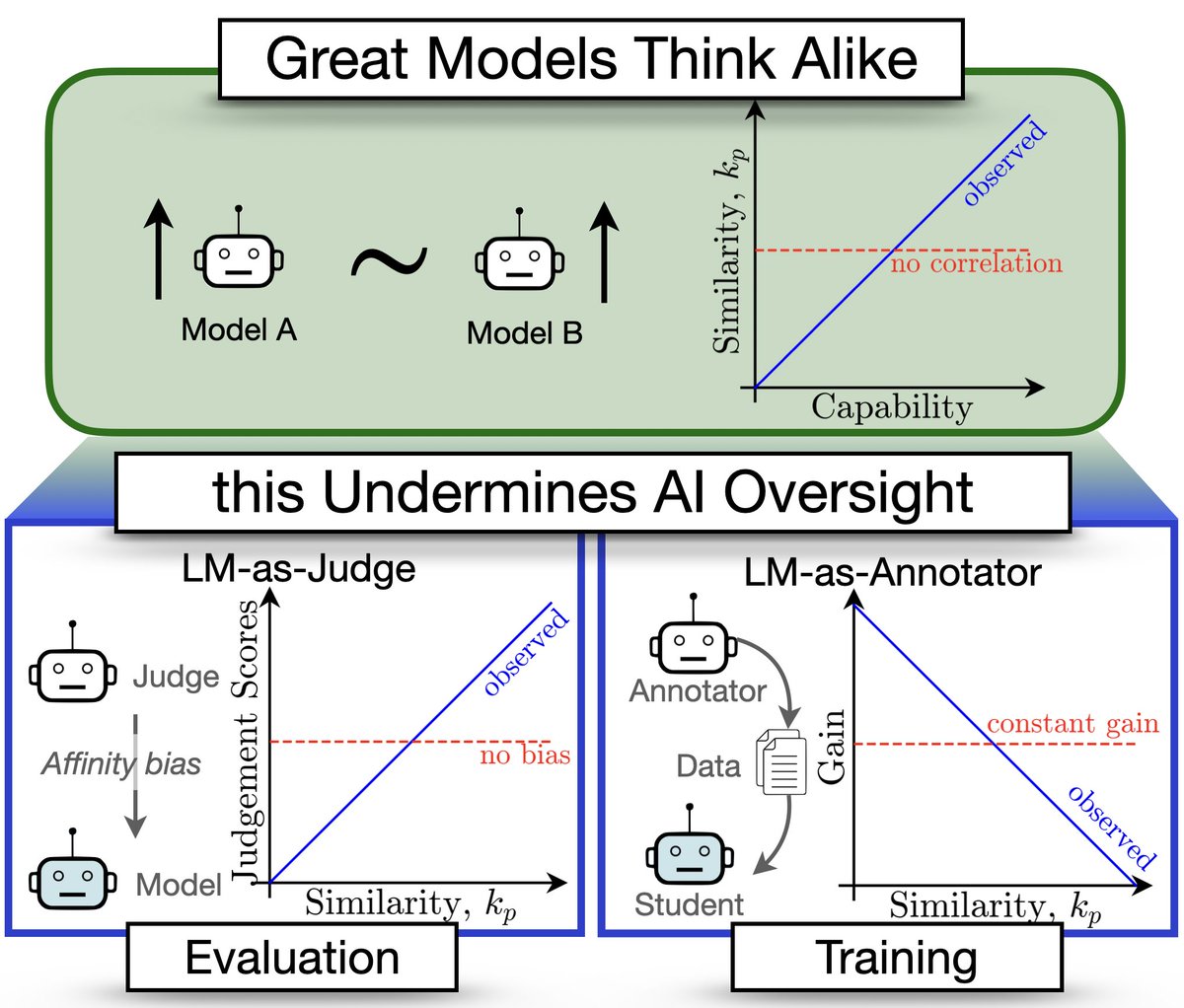
🚨Great Models Think Alike and this Undermines AI Oversight🚨 New paper quantifies LM similarity (1) LLM-as-a-judge favor more similar models🤥 (2) Complementary knowledge benefits Weak-to-Strong Generalization☯️ (3) More capable models have more correlated failures 📈🙀 🧵👇
1
3
8
RT @micahgoldblum: Here’s an easy trick for improving the performance of gradient-boosted decision trees like XGBoost allowing them to read…
0
87
0
RT @maksym_andr: Prefilling can be used not only for jailbreaks but also for exploratory analysis of alignment and biases encoded in a mode…
0
1
0
RT @jiayi_pirate: We reproduced DeepSeek R1-Zero in the CountDown game, and it just works Through RL, the 3B base LM develops self-verifi…
0
1K
0
RT @wei_boyi: Open-sourced models suffer from dual-use risks via fine-tuning. Recently, several new defenses have been proposed to counter…
0
10
0
RT @AlexRobey23: So while we already know a lot about how to jailbreak chatbots, I'm excited to see more work in this area! But if you wan…
0
1
0
RT @sichengzhuml: We’ve updated the target prefixes for 100 AdvBench requests — ready for researchers to plug and play! (8/8) https://t.co/…
0
1
0
RT @AlexRobey23: After rejections at ICLR, ICML, and NeurIPS, I'm happy to report that "Jailbreaking Black Box LLMs in Twenty Queries" (i.e…
0
16
0
RT @LukeBailey181: Can interpretability help defend LLMs? We find we can reshape activations while preserving a model’s behavior. This lets…
0
82
0
RT @AlexRobey23: In around an hour (at 3:45pm PST), I'll be giving a talk about jailbreaking LLM-controlled robots at the AdvML workshop at…
0
4
0
RT @machinestein: Check our new paper at NeurIPS 2024. We show that you can solve offline RL as Optimal Transport (OT) and get SOTA resul…
0
7
0
RT @VaclavVoracekCZ: Confidence intervals use fixed data, unsuitable for adaptive analysis. Confidence sequences compute new confidence in…
0
3
0
RT @maksym_andr: 🚨I'm on the faculty job market this year!🚨 My research focuses on AI safety & generalization. I'm interested in developin…
0
42
0
RT @dpaleka: Threat models. New framework compares jailbreak attacks under consistent fluency and computational constraints. Uses bigram pe…
0
1
0
RT @micahgoldblum: 📢I’ll be admitting multiple PhD students this winter to Columbia University 🏙️ in the most exciting city in the world!…
0
150
0
RT @bnjmn_marie: When evaluating LLMs, the batch size should not make a difference, right? If you take the Evaluation Harness (lm_eval), p…
0
4
0
@bnjmn_marie I faced the same issue when evaluating jailbreaks' success rates with the target model in bfloat16. Larger batch sizes led to lower ASR, highlighting how brittle some jailbreak suffixes are. My takeaway: for lower precision, always use batch_size=1.

0
0
1
This was an exciting collaboration with Valentyn Boreiko (@valentynepii), Václav Voráček (@VaclavVoracekCZ), Matthias Hein and Jonas Geiping (@jonasgeiping). Thank you! Find out more in our full paper at 🧵 6/n
0
0
1