

Kirill Vishniakov
@kirill_vish
Followers
81
Following
258
Statuses
41
Joined July 2023
🧬 Genomic Foundation Models (GFMs) rely on costly pretraining just like models in NLP & vision. However, is unsupervised pretraining useful in genomics domain? Our new research says: Not Yet! In our paper we analyze 7 pretrained GFMs and find some very surprising results! 🧵

1
7
20
@ConchaEloko Our conclusions apply broadly - the core issue with pretraining isn't about the data. Prokaryote genomes are simpler so should be easier to get good performance, but learning good representation still remains a problem. Evo is not really different from say HyenaDNA in that sense.
0
0
0
RT @BrandesNadav: New preprint claims that most existing DNA language models perform just as well with random weights, suggesting that pret…
0
65
0
RT @BiologyAIDaily: Genomic Foundationless Models: Pretraining Does Not Promise Performance 1. This study challenges the paradigm of pretr…
0
15
0
Joint work by our group from @M42Health including @nickinack1, Aleksandr Medvedev, Praveenkumar Kanithi, Marco AF Pimentel, Ronnie Rajan, @skhanshadab87 Paper: Code:
0
0
1
@agarwl_ this, but to be honest any paper by @ZeyuanAllenZhu on physics of LLMs series is worth reading and thinking deeply about
0
2
6
When I spoke to @amanrsanger he said they are not only optimizing for efficiency but for the enjoyment as well which seems to be one of the main reasons behind Cursor’s success.
0
0
0
@_xjdr I think there most likely will be an exponential decrease in price, just like it happened since text-davinci-003 had been released. Especially now as we have more inference hardware providers. It may take 12-18 months or a little bit more though.

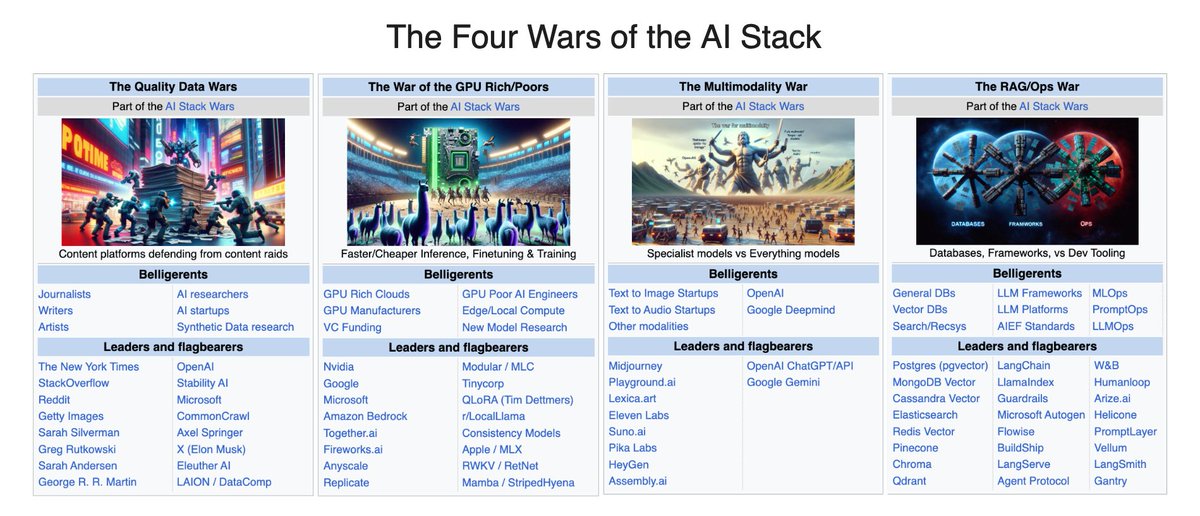
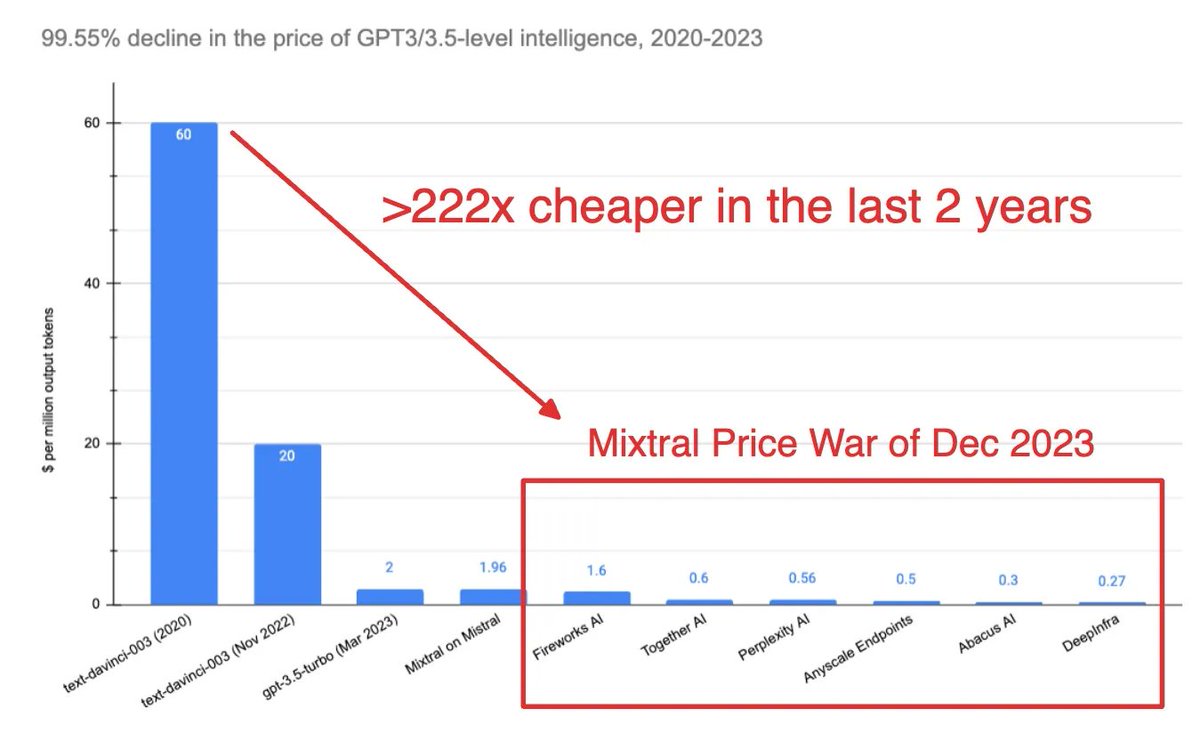
🆕 The Four Wars of the AI Stack Our Dec 2023 recap also includes a framework for looking at the key business battlegrounds of all of 2023: In Data: with OpenAI announcing a partnership with Axel Springer (see also its deal with the AP and its Data Partnerships program), the @NYT bringing a lawsuit on OpenAI demanding shutdown of all GPTs, and Apple now offering $50m for data contracts with publishers. Meanwhile there is an undeniable rise in interest in synthetic data both at NeurIPS and at Deepmind. In GPU/Inference: with the price per million Mixtral output tokens starting at ~$2 and rapidly racing down to $0.27 in a week (details below), and fresh benchmark drama between @AnyscaleCompute and other inference providers. New research into new model architectures (Mamba, RWKV), and moving compute off Nvidia (@Modular, tinycorp, Apple MLX) make more out of existing GPU resources. In Multimodality: with Midjourney soft-launching v6, a web UI, and now reported making >$200m/yr, @AssemblyAI raising a $50m Series C for “building the Stripe for AI models”, @Replicate (historically Stable Diffusion-centric) raising a $40m Series B to serve AI Engineers, and @suno_ai_ (upcoming guest!) coming out of stealth and returning to monkey - all steady point solution improvements while OpenAI and Google continue work on God Models that compete with all of them at once. In RAG/Ops: the debate on whether you need a Vector DB, vs power users adopting new vector DBs like turbopuffer; the debate between @LangChainAI (now at v0.1, with TED talk and State of AI survey) vs @llama_index (now with Step-Wise Agent Execution); and continuing LLMOps developments (@HumanLoop’s new .prompt file, Openlayer) vs framework-driven tooling like LangSmith and new approaches like @withmartian (who announced their $9m seed).


0
0
0
RT @_akhaliq: Med42-v2 A Suite of Clinical LLMs discuss: Med42-v2 introduces a suite of clinical large language…
0
29
0
@shannonzshen @SakanaAILabs while true, even if we assume fixed reasoning capabilities of the current generation models, it will most likely be improved with better rag and longer context length.
0
0
1
He is not wrong. Genuinely enjoyed this part of the discussion about current hype cycle in ML research.

0
0
1
sonnet 3.5 is a great model for coding, but it is just way too eager to reply in bullet points on basic text prompts
0
0
0