

Karandeep Singh
@kdpsinghlab
Followers
10,278
Following
2,664
Media
3,021
Statuses
18,596
Jacobs Chancellor’s Endowed Chair @UCSanDiego @InnovationUCSDH . Chief Health AI Officer @UCSDHealth . Creator of @Tidierjl #JuliaLang . #GoBlue . Views own.
Joined September 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1286699 Tweets
Liz Cheney
• 283207 Tweets
MOONLIT FLOOR OUT NOW
• 232000 Tweets
JUMP
• 210092 Tweets
Mets
• 159942 Tweets
Falcons
• 64255 Tweets
Baker
• 63283 Tweets
Brewers
• 57446 Tweets
天使の日
• 47422 Tweets
Pete Alonso
• 45580 Tweets
Bucs
• 27285 Tweets
Spiritual Awakening
• 25237 Tweets
Kirk Cousins
• 24931 Tweets
Phillies
• 21562 Tweets
Bijan
• 21525 Tweets
Mooney
• 17487 Tweets
ワートリ
• 14007 Tweets
Kirko
• 11283 Tweets
#PowerGhost
• 11073 Tweets



















Pinned Tweet

I have been an advocate of better transparency in AI reporting for research () and the broader public ().
Really appreciated the opportunity to contribute to the new TRIPOD+AI guidelines to address the “how”:




NEW PAPER out today in
@BMJ_latest
TRIPOD+AI: reporting recommendations for studies developing or validating prediction models for use in healthcare that use
#machinelearning
methods
#ArtificialIntelligence
#AIstandards
#OpenAccess
Please share 🙏

10
263
481
1
10
62
2023: HBO Launches Max
2024: HBO Launches Min
2025: HBO Launches Mean
2026: HBO Launches Median
2027: HBO Launches Standard Deviation
2028: HBO Launches Interquartile Range
2029: HBO Launches Regression to the Mean
186
4K
30K
If NVIDIA ever fails, it’s bc they got stuck at CUDA and never moved on to WUDA and SHUDA.
190
1K
12K
p < 0.001 extremely significant
p < 0.01 highly significant
p < 0.05 significant
p < 0.10 trending to significance
p < 0.20 horizon of significance
p < 0.50 coin flip of significance
p < 1 so you’re saying there’s a chance
65
1K
8K
Statistician: The p-value is 0.16780.
Clinician: All I want to do is this. I just want you to remove 0.11780, because I know the p-value is less than 0.05.
66
744
6K
Statistician: Do you ever use statistics?
ML researcher: Nope. Never.
Statistician: What about when reading a paper?
ML: Nope. Never.
Statistician: Ok. So if you’re reading an ML paper comparing lots of models, how do you know which one is the best?
ML: Bold font.
37
375
4K
Why do statisticians always keep their phones on the charger?
Because they don’t want the power to drop below 80%.
30
318
2K
The two stages of learning about mixed effects models:
1. What the heck is a mixed effects model?
2. Everything should be a mixed effects model.
27
241
2K
Computer scientist: The p-value was 0.10, so I tweaked the model until it achieved a p-value of 0.03.
Statistician: But… that’s p-hacking!
Computer scientist: No, no, no! In our field, it’s called “alignment.” I didn’t like the output, so I applied a bit of RLHF until I did.
14
101
1K
The next time you accidentally take a sip of your spouse's tea, don't apologize.
Just say you were conducting a one-sample tea test.
19
109
1K
When a logistic regression causes your R session to freeze, it’s because it’s too logit to quit.
14
104
1K
Sorry everyone. I have a tendency to make terrible stats jokes on here. Some might even say it’s my central tendency.
25
37
1K

The “R for Kids” book is in progress... co-written by my son and me.
Any publishers interested?

31
107
866
My lab is moving to
#JuliaLang
, and I’ll be putting together some R => Julia tips for our lab and others who are interested.
Here are a few starter facts. Feel free to tag along!
Julia draws inspiration from a number of languages, but the influence of R on Julia is clear.
27
136
799
If statisticians wrote papers like computer scientists:
“By leveraging logistic regression, we exploited linear algebra to capture a latent log-odds representation of the data, uncovering coefficients with SOTA p-values.”
7
88
741
The first rule of statistics is recognizing that you don’t understand statistics.
17
62
724
I’m 103% sure that I’m not fitting this linear probability model correctly.
8
37
676
"We used two different versions of R for our analyses to ensure the highest possible R squared."
8
52
660
The presenter puts up a slide showing “random forest variable importance.” You know the one...
The sideways bar plot.
Says “only showing the top 20 variables here...” to highlight the hi-dimensional power of random forests.
The slide is awkwardly wide-screen. Everyone squints.
9
183
618
If a Python user comes to your R pizza party, make sure to offer them the zeroeth slice of pizza.
19
68
571
An R package function for when you're having a bad day:
there::there()
10
44
545
Some professional news - being on the faculty at
@UMich
, I have learned from great students, colleagues, and mentors.
Next year, I’ll be joining
@UCSanDiego
as the Joan and Irwin Jacobs Chancellor’s Endowed Chair of Digital Health Innovation and Chief AI Officer for
@UCSDHealth
.
82
24
541
Computer scientist: We applied a non-linear sigmoid transformation to the weights in our machine learning model.
Statistician: 👀
Computer scientist: 👀
Statistician: So you did a logistic regression?
Computer scientist: Yes.
4
44
528
The DeepMind team (now “Google Health”) developed a model to “continuously predict” AKI within a 48-hr window with an AUC of 92% in a VA population, published in
@nature
.
Did DeepMind do the impossible? What can we learn from this? A step-by-step guide.

14
190
529
Thank you for folks who have shared or commented on our paper. I know the paper is being used by some to dunk on Epic. Rather than piling on, I want to provide a clear-eyed view of what we found, what it means, and what I would suggest to Epic (& other model devs) going forward.

Study suggests that the Epic Sepsis Model poorly predicts
#sepsis
; its widespread adoption despite poor performance raises fundamental concerns about sepsis management on a national level
1
45
138
21
173
504
I always thought this was a longshot to get published in NEJM but the past week has given me hope about our chances...



33
98
483
A Visual Tour of the Meta-Tidyverse
For years, I’ve been trying out different non-tidyverse implementations of tidyverse. It’s fun seeing folks mold languages to run analysis code inspired by it.
If you like screenshots of code, come along for a visual tour.
Let’s start w/ R.
9
113
476

I would’ve suggested Nature Onion because this must be satire.

26
77
441

Regularization is a mathematical way to tell a model to calm down and not get too excited.
3
40
414
Clinician: I fit a multivariate regre—
Statistician: NO. It’s not multivariate. It’s multivariable. Anything relating to the explanatory variables ends with “variable” NOT “variate”!
Clinician: By explanatory variables, do you mean the covariables?
Stats: NO, the covari—
21
37
410
Stats 101 syllabus: You know NOTHING. In this class, we will peel a layer from this onion of dark arts known as statistics. Prepare to enter and learn secret knowledge.
Stats 601 syllabus: Everything you learned in Stats 101 was wrong.
Stats 901 syllabus: Everything is wrong.
9
42
389
I recently submitted my R01, which was written and revised entirely* in Google Docs. If you have used Word previously for grants but are considering making the switch, this step-by-step guide is for you.
*2 collaborators used Word and final version was edited in Word
9
88
373
Frequentists laugh at all funny jokes.
Bayesians only laugh at jokes that were funnier than expected.
11
60
352
If you’re an R user, the tidylog package will save you. Use it.

9
44
339
ML researcher: To really master neural networks, you need to understand a variety of tensor operations with sophisticated terminology.
Statistician: Can you give me an example?
ML researcher: Like unsqueeze.
10
19
317
ML researcher: So why do you want to predict mortality?
Clinician: Because we try so hard to save lives, but some ppl still die. Is there a problem?
ML: Yes, the outcome is imbalanced. Not enough ppl are dying.
Clinician: So what are we supposed to do?
ML: Isn’t it obvious?
9
35
316


When you correct someone’s use of “their” and “there” in a sentence, you are engaging in an ad homonym attack.
26
35
313
datar is a relatively new Python package with dplyr/tidyr syntax supporting numpy, polars, and arrow backends.
This looks like a really promising implementation of the tidyverse, including support for factors, rowwise, nesting, and more!
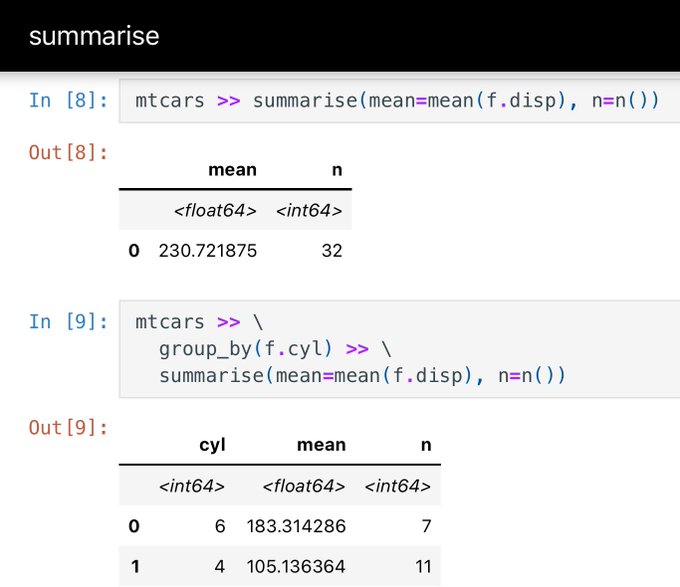
6
46
297
I’m excited to join
@UCSanDiego
@UCSDHealth
@InnovationUCSDH
!
I pledge to work with colleagues and patients to improve the experience of receiving and delivering care, and to help advance the science of using AI towards better, faster, and more accessible care.

Very excited to share that Dr. Karandeep Singh will serve as the inaugural 𝐂𝐡𝐢𝐞𝐟 𝐇𝐞𝐚𝐥𝐭𝐡 𝐀𝐈 𝐎𝐟𝐟𝐢𝐜𝐞𝐫 at UC San Diego Health and 𝐉𝐚𝐜𝐨𝐛𝐬 𝐄𝐧𝐝𝐨𝐰𝐞𝐝 𝐂𝐡𝐚𝐢𝐫 𝐨𝐟 𝐃𝐢𝐠𝐢𝐭𝐚𝐥 𝐇𝐞𝐚𝐥𝐭𝐡 at UC San Diego School of Medicine!
👉

3
12
98
29
26
302
If power isn’t peacefully transferred to Bayes by January 20th, we’ll be facing an unprecedented replication crisis.
3
16
296
When ppl ask me about my priorities as a Chief Health AI Officer, I share the Health AI Paradox.
Researched models aren't implemented. Implemented models aren't researched.
My priorities are simple. Help researched models get implemented, and implemented models get researched.
11
48
299
The two stages of learning Bayesian modeling:
1. What is Bayes theorem, anyway?
2. Frequentists are horrible people who deserve to be in jail.
4
22
293
Recently, a reviewer asked for a "visualization" of the area-under-the-curve. Nailed it!

5
24
285
I live in many worlds
and wear many hats
and know my place
in line.

5
4
272

Me, on Google: How do I do this R thing in Julia?
Google: Not so fast. First, you’re going to need to scroll past 10 pages of stuff by
@juliasilge
.
9
6
262

Regression to regression: the phenomenon when a data scientist, after having tried every possible configuration in XGBoost, returns to using a regression model.
4
22
255
Statistician: How come you didn’t report the 95% CI in your paper?
ML researcher: So sorry I left it out. Didn’t realize you cared about that. The 95% CI is 3.8.
Statistician: … ?
ML: Well I’m using 4 GitHub Actions for CI. And 95% of that is…
Statistician: Get out.
9
29
258
ML researcher: One of the biggest limitations of linear models is that you can *only* use them to learn linear relationships.
Statistician: I have the same problem with linear algebra.
ML researcher: 👀 🤔
Statistician: 👁 👁
ML: I’m wrong, aren’t I…
Stats: Yes.
7
23
241
Some textbooks say that meteors *caused* dinosaurs to go extinct.
This is wrong.
Meteors were a collider.
8
23
237
If more people used R, we might just be able to achieve nerd immunity.
8
14
234
Undergrad: Will anyone notice if I change the page margins to 1.5”? How about 14 point font?
Faculty: Will anyone notice if I change the page margins to 0.45”? How about 10.5 point font?
10
25
228
In case you coincidentally happen to be looking for alternative ways to learn
#rstats
and tidyverse because your current learning platform is busy ... *checks notes * ... suing your interactive development environment, may I suggest this series of 73 YouTube lecture videos:
Our
@umichDLHS
#LHS610
#rstats
Exploratory Data Analysis course lectures have been online-only all semester.
Want to follow along? Here’s what we’ve covered thus far...
- R + tidyverse
- dplyr, tidyr, ggplot
- shiny docs
- tidymodels
+ more...
6
38
139
2
42
222
When a statistician is being nice to you for a few days, be very wary.
They may regress to being mean.
8
27
216

@OscarBaruffa
As data scientists get older, they slowly, molecule by molecule, begin to merge with all the datasets they’ve ever worked with until one day, they leave behind the mere shadow of an inner join.
1
13
217
I'm sorry for all the puns.
It's because I grew up speaking Punjabi.
10
4
211
StatsGPT: a program that continually asks “but what’s your actual research question?”
4
36
209
Situation: my students call me “Professor” against my wishes, and my kids call me “Bruh” against my wishes.
9
2
204
My goal one day is to write a package with 13 functions:
- table_1()
- table_2()
- figure_1()
- figure_2()
- figure_3()
- manuscript()
- abstract()
- supplemental()
- response_to_revisions()
- revise()
- reformat_for_journal()
- make_scholar_one_acct()
- make_mcentral_acct()
13
27
198
👋 🧹📊 TidierPlots.jl for
#JuliaLang
A 100% Julia implementation of
#rstats
ggplot2. Powered by AlgebraOfGraphics.jl, Makie.jl, and Julia’s meta-programming capabilities, TidierPlots.jl is an R user’s love letter to data visualization in Julia.




3
50
195
Introducing Tidier.jl for
#JuliaLang
:
A 100% Julia implementation of the
#rstats
{tidyverse}. Powered by the DataFrames.jl package and Julia’s meta-programming capabilities.
Still a work in progress.
Here's a quick tour of the highlights.

5
41
192
Research interest in “is” has been growing exponentially.

7
17
195
Me: *Submits figures as vector graphics, with unlimited resolution.*
Journal: Please resubmit the figures with at least 300 dpi.
1
3
191
One myth about supervised machine learning (or predictive modeling) is that “different algorithms work best for different (clinical) datasets” and thus you must test lots of different algos and pick the best one. Let me present the counterexample: let’s separate blue from red.

4
42
192
Students: We are happy to move to Julia, but can you put together some resources for us to learn the tidyverse equivalent in Julia?
Me: Give me a month to prepare some “resources.”
***frantically re-creating tidyverse in Julia***
My lab is moving to
#JuliaLang
, and I’ll be putting together some R => Julia tips for our lab and others who are interested.
Here are a few starter facts. Feel free to tag along!
Julia draws inspiration from a number of languages, but the influence of R on Julia is clear.
27
136
799
8
18
190
The "number needed to teach" is the number of people you need to teach statistics for one person to understand it.
9
21
188
My favorite type of inference is casual inference.
Don’t have a DAG? Don’t know what a DAG is? No worries. Just keepin’ the inference casual today.
4
34
181
@matloff
What can I say. Clinicians are just Bayesians with really strong priors about their expected p-values.
6
24
177
Why does a proprietary sepsis model “work” at some hospitals but not others?
Is it generalizability? Measurement? Intervention? Patient population? Margin for improvement? Resource constraints?
Working with a team led by
@_plyons
, we looked at a 9-hospital network.
A story.

Factors Associated With Variability in the Performance of a Proprietary Sepsis Prediction Model Across 9 Networked Hospitals in the US | Critical Care Medicine | JAMA Internal Medicine | JAMA Network
@WashUi2db
@OHSUPulmCCM
@umichDLHS
1
8
36
4
47
173
Tidier.jl 1.0.0 is now on the
#JuliaLang
registry.
It’s 𝘧𝘪𝘯𝘢𝘭𝘭𝘺 a meta-package. It re-exports TidierData.jl, TidierPlots.jl, TidierCats.jl, TidierDates.jl, and TidierStrings.jl.


2
39
172
In Punjabi, the phrase “corona” (karo-na) means “Don’t do it.” The name of the virus is an apt description of the prevention strategy.
Wanna go to Broadway? Don’t do it.
Wanna go to Disneyworld? Don’t do it.
Wanna go to school? Don’t do it.
The name pretty much sums it up.
10
15
170
Shiny for R that runs in the browser?
This is an *actual* gamechanger.

4
25
168
Me: Maybe I should finally learn pandas for real…
*Types out a few lines of actual pandas code*
Me: NOT today.
19
5
166



Statisticians Lumberjacks
🤝
People who think they are
the world experts on
the topic of natural logs
4
16
160
A prediction model paradox in health: while many are developed, few are recommended.
But when models *are* recommended, they often come from tertiary care hospitals.
Is this a problem? We tested 3 prostate ca models in regional/ national data.
Paper:

7
36
159
🧵 In 2019, DeepMind published a paper in Nature describing models to predict AKI in US Veterans, finding AUCs of 92% for RNN & 89% for GBDT, better than prior work.
Inspired, we built & tested the generalizability of similar models in & out of VA.
Link:

5
44
158
The next big thing after Precision Health will be Recall Health.
11
13
156
ML researcher: Then I trained this model using an ML dataset and—
Statistician: A what?
ML researcher: An ML dataset. You know, a dataset for doing ML. It’s how we advance the field.
Statistician: …
ML researcher: Don’t you people have statistics datasets?
Statistician: …
7
12
155
I’ll be giving a talk on implementing predictive models at
@HDAA_Official
on Oct 23 in Ann Arbor. Here’s the Twitter version.
Model developers have been taught to carefully think thru development/validation/calibration. This talk is not about that. It’s about what comes after...

6
48
150
.
@elonmusk
Hospital recruitment
“An MD is definitely not required. All that matters is a deep understanding of biology, biochemistry, pharmacology, physiology, pathophysiology, genetics, social dynamics, life and death, and an ability to implement this in clinical practice.”

7
18
152
Why do seemingly useful models fail to improve clinical outcomes when implemented? Resource constraints.
In this paper, we describe constraints, how they affect net benefit, and how they apply to other measures.
Paper:
R pkg:

5
35
152
Leading scientists have raised concerns about the autocratic tendencies during the “reign” of the p-value, including misinformation being spread by the p-value on social media.

1
12
151
Statistician: Elon Musk thinks we’re living in a computer simulation with parallel universes. That guy is just so weird.
ML researcher: Agree! BTW, what is a 95% confidence interval again?
Stats: Assume we’re living in a computer simulation with multiple parallel universes...
1
14
146
8 months later and still haven’t turned back.
We still have existing projects in R and Python, but the syntax, tooling, and developer experience in Julia are so smooth that it’s hard to go back.
Language interoperability is great, and it’s nice to have a fast glue language.
My lab is moving to
#JuliaLang
, and I’ll be putting together some R => Julia tips for our lab and others who are interested.
Here are a few starter facts. Feel free to tag along!
Julia draws inspiration from a number of languages, but the influence of R on Julia is clear.
27
136
799
5
15
142