
Juan Pino
@juanmiguelpino
Followers
1K
Following
1K
Statuses
505
RT @jpineau1: As part of our work towards Advanced Machine Intelligence I’m excited to share a few new open source releases and milestones…
0
22
0
RT @honualx: We just released Hibiki, a 🎙️-to-🔊 simultaneous translation model 🇫🇷🇬🇧 We leverage a large synthetic corpus synthesized from…
0
7
0
RT @jaseweston: 💀 Introducing RIP: Rejecting Instruction Preferences💀 A method to *curate* high quality data, or *create* high quality syn…
0
79
0
RT @jaseweston: 💭🔎 Introducing EvalPlanner – a method to train a Thinking-LLM-as-a-Judge that learns to generate planning & reasoning CoTs…
0
80
0
Excited to see our previous work on multimodal translation featured in Nature, congrats to the Team!

Today we’re excited to share that our work on SeamlessM4T from Meta FAIR was published in the latest issue of @Nature ➡️

0
0
21
New research from FAIR just released 👇
Wrapping up the year and coinciding with #NeurIPS2024, today at Meta FAIR we’re releasing a collection of nine new open source AI research artifacts across our work in developing agents, robustness & safety and new architectures. More in the video from @jpineau1. All of this work is part of FAIR’s continued work towards the goal of achieving advanced machine intelligence A few highlights from what we’re releasing today: • Meta Motivo: A first-of-its-kind behavioral foundation model that controls the movements of a virtual embodied humanoid agent to perform complex tasks. • Meta Video Seal: a state-of-the art comprehensive framework for neural video watermarking. • Meta Explore Theory-of-Mind: A program-guided adversarial data generation for theory of mind reasoning. • Meta Large Concept Models: A fundamentally different training paradigm for language modeling that decouples reasoning from language representation. And much more! We’re excited to share this work with the research community and look forward to seeing how it inspires new innovation across the field. Details and access to everything released by FAIR today ➡️
0
1
20
RT @IAugenstein: 📢 📅 After a long process of soliciting & vetting bids, I'm excited that we've finally been able to reveal the location for…
0
14
0
RT @kotoba_tech: NVIDIA CEO Jensen Huang氏と孫正義氏の対談にて、KotobaのSpeech AIが英日同時通訳ライブ書き起こしを行いました!まもなく音声から音声への同時翻訳モデルもリリース予定です。Kotobaは、最先端の音声テクノロジー…
0
29
0
RT @emnlpmeeting: We're also excited to announce our #EMNLP2024 panel on Wed., Nov. 13! Title: The Importance of NLP in the LLM Era featu…
0
13
0
Looking forward to #EMNLP2024 and discussing ideas for improvements (plz suggest topics of discussion for the business meeting!)

We’re forward to seeing you at #EMNLP2024 in Miami! If you have suggestions for improvement and topics of discussions for the business meeting, please fill out this form:
0
1
25
RT @emnlpmeeting: 🚨 We’re thrilled to announce our exciting keynotes for #EMNLP2024 1⃣ 11/12: Percy Liang: open-s…
0
29
0
RT @AIatMeta: Today we released Meta Spirit LM — our first open source multimodal language model that freely mixes text and speech. Many e…
0
503
0
We just released new models and data, in particular Spirit LM, a new speech/text language model. Blog: Paper:
Open science is how we continue to push technology forward and today at Meta FAIR we’re sharing eight new AI research artifacts including new models, datasets and code to inspire innovation in the community. More in the video from @jpineau1. This work is another important step towards our goal of achieving Advanced Machine Intelligence (AMI). What we’re releasing: • Meta Spirit LM: An open source language model for seamless speech and text integration. • Meta Segment Anything Model 2.1: An updated checkpoint with improved results on visually similar objects, small objects and occlusion handling. Plus a new developer suite to make it easier for developers to build with SAM 2. • Layer Skip: Inference code and fine-tuned checkpoints demonstrating a new method for enhancing LLM performance. • SALSA: New code to enable researchers to benchmark AI-based attacks in support of validating security for post-quantum cryptography. • Meta Lingua: A lightweight and self-contained codebase designed to train language models at scale. • Meta Open Materials: New open source models and the largest dataset of its kind to accelerate AI-driven discovery of new inorganic materials. • MEXMA: A new research paper and code for our novel pre-trained cross-lingual sentence encoder with coverage across 80 languages. • Self-Taught Evaluator: a new method for generating synthetic preference data to train reward models without relying on human annotations. Access to state-of-the-art AI creates opportunities for everyone. We’re excited to share this work and look forward to seeing the community innovation that results from it. Details and access to everything released by FAIR today ➡️
4
16
103
RT @jffwng: Announcing Meta Movie Gen: new foundational media generation models We introduce 4 new capabilities: (1) text-to-video (2) vid…
0
5
0
RT @gh_marjan: We are hiring interns for summer 2025 at FAIR. Get involved in cutting-edge projects related to LLM alignment, reasoning, a…
0
56
0
RT @pascalefung: Looking for interns for Meta-FAIR in Paris in 2025 on multimodal reasoning, reasoning benchmarking, NLP, and AI safety. Ye…
0
37
0
RT @kotoba_tech: kotoba-whisper-bilingual-v1.0(超高速日英Speech-to-Text Translation)を公開しました。OpenAI Whisperではできない、End-to-End日英双方向の音声翻訳が可能となりました。…
0
100
0
RT @jaseweston: Today we are releasing code, models & data from the Self-Taught Evaluator paper, a method to train LLM judges with syntheti…
0
100
0
Great feature, all integrated no need for 3p app, congrats to the team on bringing SeamlessExpressive, a great research prototype to a production ready system in a few months! @Pipibjc @minjaeHwang2 @jiangyurong609 @MavlyutovRuslan @yilin_yang721 Bokai Yu and many others!

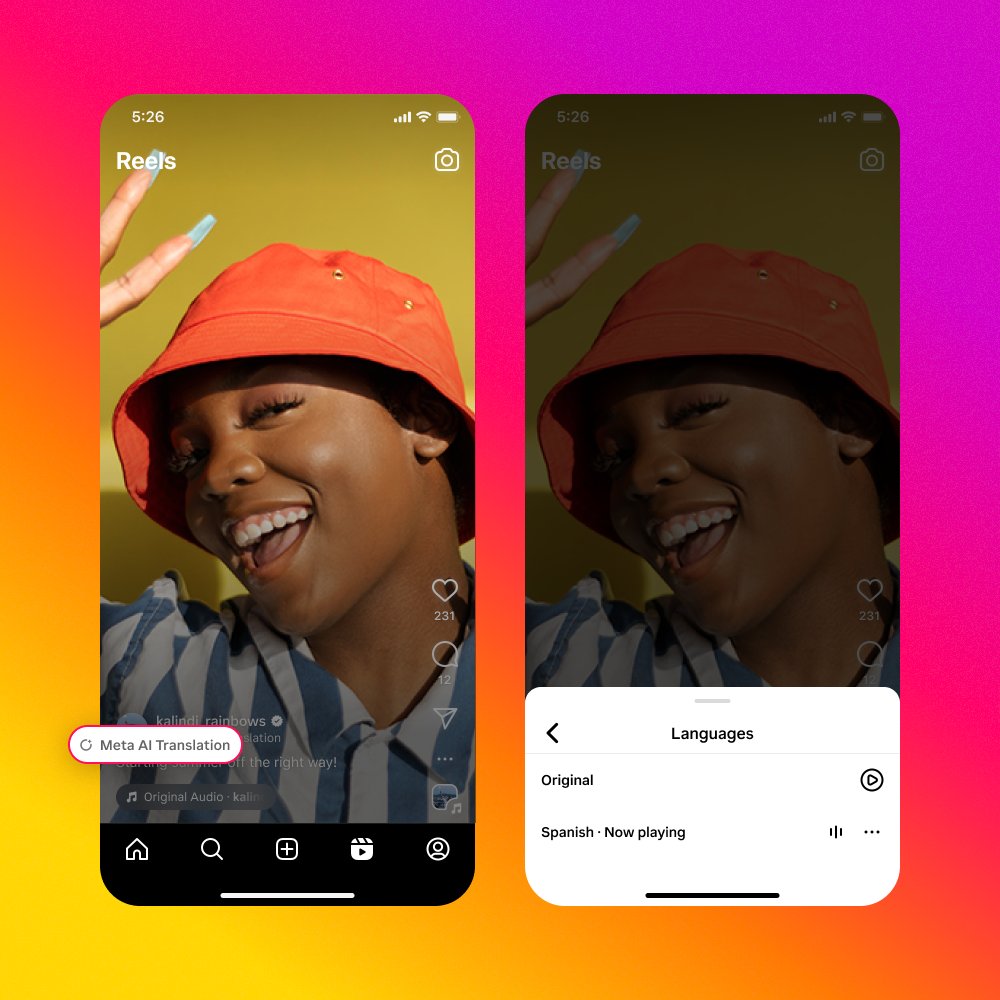
4. Let more people enjoy your content in different languages. With automatic dubbing and lip-syncing, Meta AI translates your voice in Reels 🗣️✨ (limited testing in English and Spanish)
0
4
13