

Edward Kennedy
@edwardhkennedy
Followers
4,768
Following
593
Media
288
Statuses
1,986
assoc prof of statistics & data science @CMU_Stats @CarnegieMellon . interested in causality, machine learning, nonparametrics, criminal justice, public policy
Pittsburgh, PA
Joined June 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Adalet
• 229495 Tweets
#4MINUTES_EP7
• 110778 Tweets
Chester
• 109053 Tweets
ベイマックス
• 108916 Tweets
Merchan
• 87219 Tweets
Jean Carroll
• 67100 Tweets
Eagles
• 66452 Tweets
#2KDay
• 65265 Tweets
HAPPY BIRTHDAY TANNIE
• 54862 Tweets
#dilanpolat
• 42720 Tweets
Franco Escamilla
• 36228 Tweets
Ayşenur Ezgi Eygi
• 33350 Tweets
Packers
• 29860 Tweets
#CristinaMostraElTitulo
• 22644 Tweets
Ganesh Chaturthi
• 14787 Tweets
Bafana Bafana
• 14541 Tweets
Tesehki
• 13943 Tweets
Barcola
• 13148 Tweets
Chaine
• 12323 Tweets
Alina Habba
• 10927 Tweets
Go Birds
• 10887 Tweets
Skylar
• 10060 Tweets




















Pinned Tweet

Very excited about this new paper!
We study if one can improve popular semiparametric / doubly robust / DML causal effect estimators -- without adding structural assumptions...
Short answer: nope!
Turns out these methods are minimax optimal here
Lots of Qs left to explore...




4
46
216
Florence Nightingale made this plot... by hand... a mere ~50 years after the word statistics was first used, ever... Insane. She is such a hero.

18
338
984
"Behind every great theorem lies a great inequality"
This inequalities cheat sheet has been really helpful to keep on hand while working - passing it along in case others find it useful

4
173
673
Siva & Larry & I have a new paper on counterfactual density estimation:
Means are everywhere in causal inference, but *densities* can be much more informative & useful
We give efficiency bounds, optimal estimators, & easy-to-use code - hope it's useful!



10
90
483
I wrote a review & tutorial illustrating how I think about semiparametric / doubly robust / TMLE / DML methods:
It builds on workshops I've given in the past using these slides:
(next one's at ACIC in May: )


Here are some slides from a short course where I try to explain why doubly robust estimators (and influence function-based estimators more generally) have these nice bias correction properties, allowing valid use of flexible ML tools:

2
16
57
7
106
398
"Statistics, contrary to popular perception, isn't really about facts; it's about how we know or suspect or believe that something is a fact. It has more in common w/philosophy (eg epistemology) than accounting. Statisticians are applied philosophers."
-
@stephensenn
#statsquotes
5
123
391
My PhD advisor Dylan Small taught me to take the long view, and think about publications more like newspaper articles than books - they reflect your current understanding at the time, and only when taken together make up your body of work. No single publication defines you.
2
63
296
It's always bugged me that in R the lm/glm defaults all require assuming the fitted model is exactly correct.
Here's what looks like a very useful tool for providing more honest inference that formally treats the fitted models as mere approximations:

5
47
232
Such a fun paper & collaboration:
In an instrumental var setting, we show how to accurately predict who compliers are, & give tight bds on generalizable effects in identifiable subgroups.
Surprisingly, these properties are orthogonal to IV strength!




6
59
228
"There are two types of statisticians: those who do causal inference and those who lie about it." - Larry Wasserman
#statsquotes

2
70
218
A prediction: in the next 5 years, someone will rediscover marginal structural models + structural nested models & come up with a more marketable name (sequential adaptive double machine learning? SAD ML?) & they will become the next big thing in causal econometrics w/ panel data
6
16
220
New paper!
How do trt effects vary across people? Such heterogeneity is crucial for optimal allocation, generalizability, etc
Many methods out there... but optimality's been unsolved. What is "best"?
We derive minimax rates & give new optimal estimator




4
30
192
A short thread:
It amazes me how many crucial ideas underlying now-popular semiparametrics (aka doubly robust parameter/functional estimation / TMLE / double/debiased/orthogonal ML etc etc) were first proposed many decades ago.
I think this is widely under-appreciated!
1
36
189
STOP talking crap about different subfields of statistics
Causal inference is ENLIGHTENING
Bayesian is BEAUTIFUL
Nonparametrics is FASCINATING
Bioinformatics is EXCITING
Time series
High-dimensional is INSPIRING
2
19
181
A very nice and readable review of what you can miss with averages and why/how to consider modes instead:

1
50
166
Some good advice from my PhD advisor Dylan Small:
Take the long view, & think about publications more like newspaper articles than books - they reflect your current understanding at the time, & only when taken together make up your body of work. No single publication defines you
1
19
165
New paper alert!
"Sensitivity analysis via % of unmeasured confounding"
SA is absolutely crucial for causality: holy grail is finding one that's interpretable *&* flexible
@bonv3
& I propose contamination model approach, w/effect bds across % confounded


4
45
159

“It’s funny: lots of people who aren’t statisticians do statistics. We don’t do chem/bio; we don’t go to a lab & start filling test tubes. Stats is something you can do if you have a PC. Lots of people think they can do it well, but don’t.”
-
@robtibshirani
#statsquotes
19
45
138
Causal effects aren't identified from observational data w/o nonidentified assumptions. If you don't wish to join Fisher & say causality from obs data is illegitimate (incl cigarettes -> lung cancer) then you must recognize need for untestable assumptions
- J Robins
#statsquotes
1
17
138
I like this rule of thirds:
“When you’re chasing a big goal, you’re supposed to feel good 1/3 of the time, OK 1/3 of the time, & crummy 1/3 of the time.”
Sometimes we feel down when we get stuck on something, but that’s a crucial part of doing interesting & challenging research

The longer I'm in academia, the more I see a resemblance between our field and professional sports. But I think folks in pro sports understand and embrace the competitive aspect and difficult parts of training in a more honest and healthier way. This advice resonated:

26
242
1K
5
29
136
Eric TT is one of my all-time favorite statisticians & people
He’s that person you meet & instantly think “wow I want to be like them...”
A true Renaissance man making incredibly creative advances in theory, w/deep connects to science, & unbelievably encouraging & kind to all

We are excited to honor alumnus and
@Wharton
professor Dr. Eric Tchetgen Tchetgen as the recipient of the 2020 Myrto Lefkopoulou Distinguished Lectureship! He will deliver a virtual lecture on Sept 17, 1-2pm. More info here:

5
23
173
2
19
130
Identification of average causal effects, when all confounders are measured:
E(Y1)
= E{ E(Y1 | X) }
= E{ E(Y1 | X, A=1) }
= E{ E(Y | X, A=1) }
Step 1 by iterated expectation, step 2 by no unmeasured confounding & positivity, step 3 by consistency.
Simple but very powerful

Can you think of a more important/useful theorem that can be proven in a tweet?
Proof:
P(A⋂B)=P(A|B)P(B)
P(B⋂A)=P(B|A)P(A)
P(A⋂B) = P(B⋂A) ==> P(A|B)P(B)=P(B|A)P(A).
==> P(A|B)=[P(B|A) P(A)]/P(B) QED
i.e. (proof by division)
25
74
305
6
12
130
a favorite aspect of research:
that select group of people whose work you really really admire &, when they come out with a new paper, you get super excited to read through & see what they've been working through lately
similar to when your favorite band puts out a new album
3
8
126
Oh boy. Stats with purely *observed* data is difficult enough in small samples...
Causal inference using only “a few data points” is necessarily going to require some heroic assumptions.

11
10
120
If you’re worried about what happens when 1% of your sample disappears, wait till you hear what happens when 1% is subject to unmeasured confounding! :)
@bonv3



Hello! Tamara Broderick, Ryan Giordano and I have a new working paper out!! It's called "An Automatic Finite-Sample Robustness Metric: Can Dropping a Little Data Change Conclusions?"

34
229
1K
3
12
118
Really looking forward to this next Tuesday!
I’m presenting brand new work on flexible estimation of heterogenous causal effects, which I’m very excited about (paper on arxiv next week 🤞🏻)
Also honored to have one of my heroes Jamie Robins as discussant

3
26
115
So excited about this paper exploring "Counterfactual Risk Assessments, Evaluation, and Fairness" led by star PhD student
@AmandaCoston
, & w/
@achould
:
Turns out that causal inference ideas are extremely useful when assessing fairness in risk prediction


1
31
109
Favorite intro prob game:
You & I both pick length-3 sequences of H/T. Then we flip a coin and whoever’s seq comes first wins.
All seqs are equally likely so we both have 50% chance to win, right?
NOPE. If you pick first, I can pick seqs ensuring I’m 2x-7x more likely to win!
6
23
104
Very excited to share new work on flexible estimation of heterogeneous effects:
1st part is more practical & gives flexible error bds. 2nd part is more theoretical & tries to find best possible error.
Might’ve learned more in this than any other paper




3
20
103



This paper was really fun!
We give new methods for estimating bounds on the avg treatment effect -- here trt is confounded, but you have an instrumental variable. Super common setting in practice
The bounds are non-smooth, so std nonparametric efficiency theory isn't applicable



2
15
97
Charles Stein is one of my all-time favorite statisticians. And this paper from 1956 (!!) is one of my all-time favorites - it sets the foundation for modern nonparametric efficiency theory & was so so far ahead of its time:

3
10
93
I recently lost my sister Kels. They were one of the best people I've ever known, & were loved so so much. I will always regret not telling them more.

25
1
87
One of the most interesting & surprising things in stats is that adding noise/randomness can often help rather than hurt:
Experiments, permutation tests, bootstrap, cross-validation, MCMC

3
14
90
There’s no way you can just sit down and do a ‘big thing,’ or at least I can’t... Statistics is a wonderfully forgiving field: you don’t have to be the brightest person in the world or work day & night; all you have to do is get an idea and keep at it.
- Brad Efron
#statsquotes
0
11
84
my favorite part of the paper is where I share tricks I use to derive influence functions
e.g. this *3-line derivation* for the average treatment effect
with these tricks (& some practice), you can often see what the influence function will be without even writing anything down


3
12
85
.
@manjarips
& I have a new paper on nonparametric estimation of population size:
This is a classic problem w/ a long history & lots of important applications - our paper focuses on how to flexibly & efficiently incorporate complex covariate information




1
18
83
Some of my favorite Stat Sci conversations:
Bickel
Blackwell
Efron
Fienberg
Stein
Wahba
Wellner




This is why I *love* Stat Sci's "Conversations with..." series:
but unfortunately they never did one with Stone.
1
1
11
5
12
81
Related: be suspicious if you see someone reducing statistics to simplistic "do this, never that" rules
(eg: never dichotomize! no propensity scores! condition on everything!)
In my experience it's rarely that black & white - if you start questioning you uncover lots of gray
"Statistics, contrary to popular perception, isn't really about facts; it's about how we know or suspect or believe that something is a fact. It has more in common w/philosophy (eg epistemology) than accounting. Statisticians are applied philosophers."
-
@stephensenn
#statsquotes
5
123
391
7
18
78
This is great! I have found that defining target parameters nonparametrically - outside of any possibly wrong model assumptions - one of the most freeing & important things you can do in stats

We can think about defining our parameters more flexibly outside the context of a parametric model!
Can write the average treatment effect as the contrast: E_X[E(Y|T=1,X)-E(Y|T=0,X)].

1
3
53
2
7
78
Great news! Betsy is a hero of mine -- if you ever want an example of work that is creative, exceptionally well-written, and deep (both substantively & theoretically), you won't go wrong picking one of her papers at random.

Congratulations to Dr. Betsy Ogburn on her promotion to Associate Professor! It’s an awesome achievement, and we could not be more proud!

4
15
146
1
5
73
Woah. What a first sentence for an abstract:
"The premise of the deconfounder method proposed in "Blessings of Multiple Causes"... is incorrect."

4
0
72
“The point of rigour is not to destroy intuition; it should destroy bad intuition while clarifying & elevating good intuition. Only w/ a combo of rigorous formalism & good intuition can one tackle complex math problems; the former for fine details, the latter for the big picture”
A nice article by Terry Tao: There's More to Mathematics and Rigor and Proofs.
7
85
313
1
7
69

I learned a beautiful result recently from
@BetsyOgburn
@oleg_sofrygin
@ildiazm
@mark_vdlaan
's amazing paper on causality in networks:
A CLT still holds for non-iid network data, as long as everyone has << sqrt(n) friends!
(pic: )

3
8
71
Double robustness is often explained as: you get 2 chances at picking correct parametric model. But the chances of this are slim.
The really cool thing abt DR estimators is their errors are products: & so smaller than either error alone. Thus you can get fast rates/CIs even w/ML

Interesting paper! And a conceptual question: Double robustness is often motivated by assuming lack of knowledge of the treatment or exposure models. If we knew either we could rely on single robustness. How often do we know one of the two models is correct, just not which one?
3
3
18
4
6
66
Very excited about this new paper by Tiger Zeng ()
We study causal inference w/ high-dimensional discrete confounders
We give new bias/variance results & minimax lower bounds, which characterize fundamental limits of causal inference in high dimensions




3
21
78
I’m so excited about this work - the capture-recapture problem is super interesting with lots of applications across diverse fields (epi, human rights, ecology, etc), & also has some subtle ties to causal inference. Our paper will be out soon!

Congratulations to Manjari Das on her wonderful thesis proposal on “Non-parametric doubly robust estimation of population size with conditional capture-recapture designs”! Advised by Edward Kennedy
@edwardhkennedy

1
1
22
1
5
67


"There are dangerous myths in mathematics. One is that there exist "math people" to whom it all comes easily & is obvious."
Great idea for a book - & I love that it's free.
Living Proof: Stories of Resilience Along the Mathematical Journey

1
24
64
Can you fix the boss's mistake if you're only given the sorted data?
ie is regression even possible if we only see uncoupled Xs and Ys?
This nice paper says yes (!), if the regression fn is non-decreasing (but it's hard & error decreases slowly with n)

4
13
63
Here’s an amusing story told by Lucien LeCam, which features typical pomposity from RA Fisher, but ends with him getting some just deserts:

1
5
63
Jamie Robins:
- was 58 when first groundbreaking work on higher order influence functions came out ()
- was 67 when recent HOIF advances appeared in Ann Stat ()


Examples of major math advances past 50
• Kolmogorov solved Hilbert's 13th problem at 54
• Y.Zhang proved there are infinitely many pairs of primes that differ by ≤70M at 58
• Apery proved the irrationality of 𝜁(3) at 62
• Weierstrass proved the approximation theorem at 70
39
452
2K
4
6
61
“Observational methods are used everyday to answer pressing causal questions that can't be studied w/RCTs (eg drugs, sex, smoking, alcohol)... It's important to develop obs methods to estimate these effects to prevent further needless suffering & death.”
- J Robins
#statsquotes
0
21
60


Here are some slides from a short course where I try to explain why doubly robust estimators (and influence function-based estimators more generally) have these nice bias correction properties, allowing valid use of flexible ML tools:
2
16
57
great interview with a truly great person. can't think of anyone more deserving of the copss award

3
12
56
Cool new paper by
@leqi_liu
!
Mean optimal trt rules aren't robust: sensitive to small % w/ extreme outcomes
Marginal median opt rules are unfair in different way: my treatment depends on *your* outcomes
We study fair+robust median optimal trt rules:




2
8
57
This terminology is one of my pet peeves.
For consistent estimation of the target parameter, doubly robust estimators require 1/2 nuisance estimators to be consistent.
“Triply/quadruply robust” makes it sound like you only need 1/3, or 1/4. Would be neat! But it’s not true.


5
8
57
Cool example where probabilistic ideas help prove results in number theory, despite everything there being deterministic:
Another classic is using the WLLN to prove Weierstrass’ approximation theorem. Any other fun examples like this?

4
3
54
Peers consider Hairer a genius, but he admits maths can be infuriating. “Most of the time it doesn’t work out. As every graduate student can attest, during your PhD you probably spend 2/3 of your time getting stuck & banging your head against a wall.”
3
4
55
Huge congrats to
@AmandaCoston
on her
@Meta
PhD research fellowship!
Amanda's a joint student
@mldcmu
&
@HeinzCollege
@CarnegieMellon
doing amazing work on fairness in ML, causal inference & more
Check out her papers & more here:


1
4
54
I like how the formatting of this brand new paper feels a bit like stepping back in time... is there a latex template that replicates 80s typesetting?

10
2
54
I'm not a fan of how these Lalonde-style papers are framed
When you add observational controls to an experimental treatment arm, **you are changing the target parameter** (even w/ATT)
We shouldn't necessarily expect the "observational" estimates to match the "experimental" ones

Facebook did a LaLonde for ads and the results don’t look great for observational designs.
3
9
60
3
3
54
"Most scientists study some aspect of nature; we study scientists, or at least scientific data. Statistics is an information science, the first and most fully developed information science."
- Brad Efron
#statsquotes
2
11
54
So excited to share new work w/star
@CMU_Stats
PhD student Alan Mishler ():
We show how to post-process arbitrary risk predictors so they satisfy more meaningful *counterfactual* fairness constraints, & study statistical properties



0
6
54
And now there's an easy-to-use R package! (on github & cran)


.
@manjarips
& I have a new paper on nonparametric estimation of population size:
This is a classic problem w/ a long history & lots of important applications - our paper focuses on how to flexibly & efficiently incorporate complex covariate information
1
18
83
1
12
51
"Statistics is intertwined with science and mathematics but is a subset of neither."
- Jamie Robins
#statsquotes

1
10
51
this is why i celebrate a little when i post to arxiv, and then try to forget whatever happens afterwards.
publication outcomes are noisy & not great signals of quality. lots of bad papers get into good journals, and lots of good papers get rejected.

Please tell me your most infuriating academic publishing stories. I need this right now.
25
3
43
2
0
51
Causal effects via modified treatment policies are so useful for flexible & robust causal inference
Now
@ildiazm
has extended them to the longitudinal setting!
Yet another novel & thoughtful but also super clearly written paper by Iván

3
12
51
"Statisticians are engaged in an exhausting but exhilarating struggle with the biggest challenge that philosophy makes to science: how do we translate information into knowledge?" -
@stephensenn
#statsquotes
2
14
51
This work by
@CMU_Stats
PhD student
@iwaudbysmith
is *extremely* cool
Surprisingly, you can do safe, anytime-valid causal inference - even in complex observational studies, where asymptotics usually dominate! Has important implications for modern online data collection & beyond

Super excited to share this work with
@edwardhkennedy
,
@darbour26
, Aaditya Ramdas, and Ritwik Sinha on confidence sequences for causal effects!
arxiv:
code:


4
27
112
1
5
49
“Individual men are insoluble puzzles, but in aggregate they become a mathematical certainty. You can't foretell what 1 man will do, but you can say what an avg # will be up to. Individuals vary but %s remain constant. So says the statistician.”
- Sherlock Holmes
#statsquotes
1
9
49
In this paper I propose simple "incremental intervention" effects for causal problems with complex longitudinal confounding and/or positivity violations:
arxiv:

2
15
49
I actually find the opposite to be true — it seems like too many people in stats & other fields prioritize low variance over low bias — mostly by incorporating unrealistic model assumptions, evidently just to obtain precise answers to the wrong question.
6
5
49
"I guess I’d like to be remembered as somebody who produced really good students and who helped change the image of statistics in the sense that lots of people now work on serious applied problems and help solve them." - Steve Fienberg
#statsquotes
1
2
49
very excited for this
@SAMSI_Info
workshop on causal inference in december:
So many amazing speakers! including
@deaneckles
@AviFeller
@laura_tastic
@ljk50
@Lizstuartdc
and lots of others


2
10
48
New review of incremental effects, with
@bonv3
, Alec McClean, & Zach Branson!
Usual effects compare all vs none exposed - but this doesn't make sense if some are destined to be exposed. Can instead ask "what'd happen if trt were slightly more likely?"

In this paper I propose simple "incremental intervention" effects for causal problems with complex longitudinal confounding and/or positivity violations:
arxiv:
2
15
49
0
10
48
Wow I just accidentally made the most beautiful “i” I’ve ever written. I had to stop and take a pic
Also I’m now noticing how different the 3 “i”s are in this. Weird


8
0
47
Updated version of our CATE minimax rates paper is out!
We settle the minimax story *regardless* of propensity vs regression complexity (eg, PS can be less smooth)
We also show how minimax rates change, depending on which regression fn is parametrized
New paper!
How do trt effects vary across people? Such heterogeneity is crucial for optimal allocation, generalizability, etc
Many methods out there... but optimality's been unsolved. What is "best"?
We derive minimax rates & give new optimal estimator
4
30
192
1
9
46
What are the best reviews of statistical theory for neural nets? Some I know:
Gyorfi et al Ch 16:
Just saw this clear & short & sweet one by CMU phd YJ Choe:
Bartlett et al (2021) also seems essential:



1
8
47
Sometimes authors' notational choices can be like nails on chalkboard for me.
Was just looking at a paper where dimension is "n" and sample size is "k"...
4
1
47
Super exciting work by Matteo
@bonv3
!
Really advances the state-of-the-art for causal inference w/continuous treatments
- new methods *and* guarantees for effect estimation *and* sensitivity analysis
(cts trts are everywhere in practice but much more difficult than discrete)





My advisor
@edwardhkennedy
and I have posted an article on continuous trt effects estimation:
We study nonparam models where the dose-response curve has its own smoothness, which may differ from that of the outcome regression or cond dens of trt given X.
4
18
112
0
8
46
1
3
41
Hopefully this isn't because earlier iterations were just poorly explained...
Slides have been updated, still available at same link:
And here is corresponding review paper:

3rd? time in 5 years I've seen
@edwardhkennedy
do his np causal inference workshop but still manage to learn something new every time.
0
2
30
1
4
44
A very weird but cool result:
Extreme overfitting to training data isn’t necessarily a bad thing - and in fact can lead to provably optimal prediction on test data!
(even under standard nonparametric conditions)

3
7
42
PSA: Missing data & censoring/dropout are causal inference problems. They’re mathematically equivalent.
If you’ve done complete case analysis or multiple imputation or Kaplan-Meier or Cox modeling, you’ve made untestable assumptions to draw conclusions from observational data.
6
9
40
Check it out! Fun paper with
@dscharf3
@raziehnabi
@bonv3
& others on flexible methods for sensitivity analysis to common "no unmeasured confounding" assumptions



Semiparametric Sensitivity Analysis: Unmeasured Confounding In Observational Studies. . Learned so much from my co-authors:
@raziehnabi
,
@edwardhkennedy
Ming-Yueh Huang,
@bonv3
, and Marcela Smid.
1
7
46
0
7
41
A small sampling from a very memorable review I received, on a submission to JASA:
Corollary 1: this is not a mathematics journal. Please explain what "inf" , "lim inf" and "sup" mean
page 13: What is RKHS regression? nerver heard about this
page 14: what does "debiased" mean?

"What is the definition of twice differentiable? Is the term related to differential privacy?" is from now on my favourite paper review quote. It will be hard to beat this one!
11
36
311
4
0
42
This is why I love combining bds *with* sensitivity analysis. You get the whole picture: pt identification @ one extreme, agnostic bounds at the other
Best of both worlds & middle ground in between!
Nice example in
@bonv3
% unmeasured confounding paper:
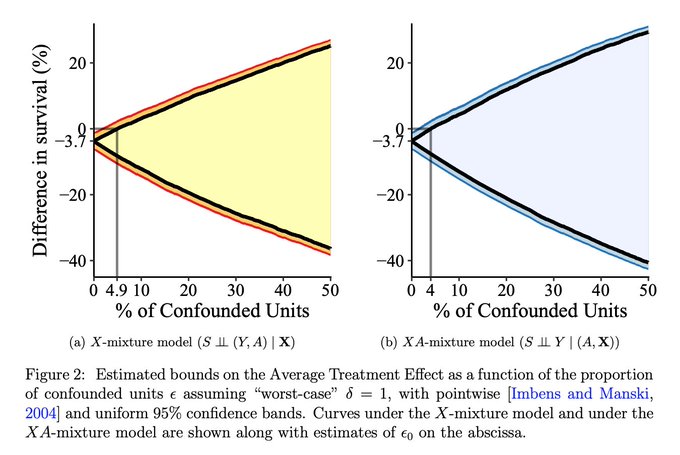

@JeffDenning
@paulgp
@PaulaAureo
@VC31415
@elie_tamer
But is this the fault of econometricians? Or do applied referees not like bounds because they are wide and would rather believe more precise estimates based on potentially untenable assumptions?
1
0
8
2
1
41
Looks like an interesting paper! Since po-calculus complements do-calculus, it will be hard not to pronounce it as “poo-calculus”.

A Potential Outcomes Calculus for Identifying Conditional Path-Specific Effects.
0
2
25
2
6
42
@CandiceMajewski
How can stats help tell us "what if" and not "what is"?
What tools work best when stats is hard? What does "best" mean & what does it look like?
1
0
41
Come work with us at
@CMU_Stats
!
CMU is a really special place & I've learned so much from the amazing community here.
We're hiring on both tenure track (all ranks) & teaching track (asst profs):
Tenure track:
Teaching track:

1
13
39
Very nice paper - and super clear thread on why doubly robust estimators & sample-splitting/cross-fitting is important!
1
7
39
Very related:
I loved working on this paper w/
@leqi_liu
exploring median optimal treatment regimes:
It seems hard to motivate the mean over the median here - when they align, you can pick either, and when they don't, the median is often much more useful



why is causal inference apparently always about the average treatment effect rather than, say, the median? is that just tradition or what is computationally easier, or is there something fundamentally more causal about the mean?
24
10
128
3
7
38
Really excited about this paper, w/ amazing postdoc Alex Levis
We propose conditional potential benefit (CPB) measure, ie the improvement under optimal trt vs status quo
We describe id assumptions & propose nonparametric, robust, & efficient estimators



2
8
43
Really looking forward to this visit!
Here's a tweet-sized version of my talk:

May 3rd see Edward Kennedy of Carnegie Mellon University on the subject of Nonparametric Causal Effects Based on Incremental Propensity Score Interventions.
Friday May 3 from 12 PM - 1 PM
HCP Conference Room 224E
@HMSHCP

1
3
19
1
4
38