

di qi
@diqitally
Followers
1K
Following
3K
Media
36
Statuses
342
cofounder @lanterndb (yc w24). prev @ycombinator @princeton.
San Francisco, CA
Joined October 2022
we went to an @OpenAI x @ycombinator hackathon this week!. @ngalstyan4 and i built an app to iteratively build postgres extensions - it generated a median aggregate function extension successfully :)


10
12
367
I left my job at @ycombinator last year to build a startup. Today was our first in-person office hours for W24 with @gustaf!. There's so many things that are special about YC, but for me the optimism stands out the most. I'm excited to experience it from the startup side again :)

18
7
218
We just launched @lanterndb on @ycombinator! 🚀. Lantern is a Postgres vector database that is easy to use, cost-effective, and scales to billions. We support embedding generation, index compression, and external index creation.

21
22
169
The @ycombinator retreat ended a few days ago. It was super exciting although I'm just now catching up on sleep. We're a company built on Postgres, so one highlight was spending an hour talking about Lantern with one of the @citusdata founders. I'm so grateful for this


2
6
74



i don't need a big house. i don't need a fancy car. i don't need to travel the world. i just need the admiration of the two hundred regulars who comment on every hacker news post to support me in whatever i do.
1
4
38
We built external indexing for pgvector in Postgres. External indexing offloads the resource-intensive index creation process to external machines to reduce the impact on database performance. Read the blog post from @D4RK7ET below 👇.
4
7
36



thanks for the shoutout @TechCrunch :). we're building postgres for ai companies. if you're using a specialized vector db or want to improve your postgres performance, please reach out! we'd love to help.

YC’s latest Demo Day shows fascinating wagers on healthcare, chip design, AI and more
1
4
31
So excited about this partnership! 🥳. @UbicloudHQ is building an open source alternative to AWS that reduces your Cloud bill by 3-10x. It’s been wonderful to work with the Ubicloud team. They’re experts in Postgres — they're the same team that built distributed Postgres at Citus.

🚀 We’re excited to share that Lantern is now available on @UbicloudHQ !. You can access vector generation, LLMs, serverless indexing, and more. All in Postgres. All open-source. If you're building an AI app, we can help you simplify your infrastructure.
0
3
23
@annaarthoe he stole from lululemon so he could have a shirt on his back, a table from crate & barrel so he didn't have to eat off the floor.
1
0
22
ngl losing your voice during fundraising is incredibly frustrating.
3
0
22
fundraising kicked off about 2 weeks ago, and alumni demo day is tomorrow, so things have been a bit hectic. excited to be 100% back to building / writing soon, but here's an article from us in the meanwhile :).
Latest blog post - an overview of vector databases and related concepts, including vector embeddings, vector indexing, and vector search.
1
1
21



Open AI released their new embedding models last month. We worked with @JoschkaBraun to evaluate the new models on a healthcare dataset. We used @lanterndb for embedding generation / storage and @PareaAI for evaluation. Love learning form other YC cos😊.
3
6
20




Yesterday @umurc and I gave a talk at @pgconfeu about how to build a code chatbot with Postgres in 15 minutes! Here's a short version in a blog post ☺️.


We're excited to announce managed @lanterndb on Ubicloud!. With this partnership, here's what you get:. * With open source, powerful RAG (Retrieval Augmented Generation) AI apps.* Better better price / performance than proprietary solutions.* Usability
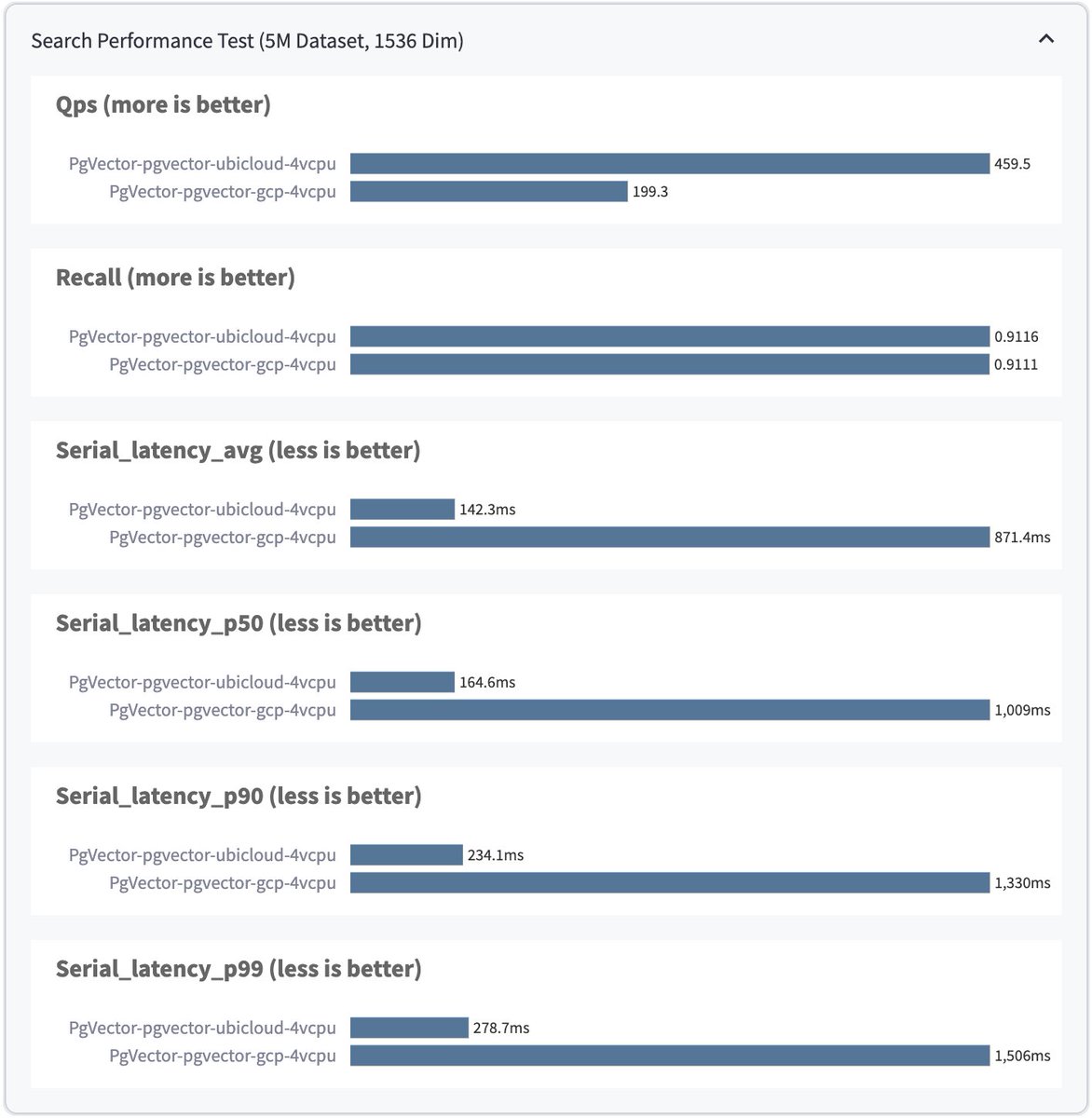
0
2
17
some of @lanterndb's engineering updates for april! including.- async tasks.- weighted vector search.- @ubicloudhq control plane.- dashboard improvements.
0
5
17
Last week we released product quantization (PQ) in Postgres with @lanterndb! 🚀. We ran benchmarks over 100M 768d image embeddings. With re-ranking, we got. ▶ 90% recall.▶ 73 ms query times.▶ Reduced memory usage from ~300GB => ~60GB.
2
3
17
meeting yc w27 founders and explaining to them that back in my day, zero companies were building for the vision pro

3
0
17
🚀 Lantern now supports LLM calls in Postgres!. Run adhoc queries:. SELECT llm_completion('Summarize code', code) FROM files LIMIT 1;. Or automate column generation:. SELECT add_completion_job('files', 'code', 'summary', 'Summarize code');.
0
2
16
tech companies getting engineers to talk to customers by calling them "forward deployed engineers" was one of the greatest tricks of my lifetime.
1
0
16
My cofounder @ngalstyan4 wrote a blog post about how different operations like indexing affect write-ahead logging (WAL) sizes in Postgres 🔍.
2
7
16
We wrote a bit on using Postgres vs. ElasticSearch vs. Algolia for search 👇.
4
2
15
great to see a major tech company that's avoided layoffs over the last 2 years:

0
0
15
we were excited to work with @nankigrewal and @andrezfu from our yc batch on this demo of automating compliance checks with lantern and ecliptor! 🚀. we used ecliptor for document processing and lantern for vector generation + storage. check it out ☺️.
1
3
13
we hit 500 stars on github today! ⭐. we have a performance upgrade and new benchmarks coming soon, stay tuned. 😊.
2
4
14
🚀 you can now use @lanterndb with @LangChainAI! 🦜. tutorial coming soon. s/o to @WHinthorn for the assist 😊.
1
4
14


We added client libraries for Knex, Sequelize, MikroORM, and Drizzle for @lanterndb! Perform vector search or embedding generation using your favorite JS ORM ☺️. Let us know what you think!.
2
3
13

Do you stream vector embeddings into a Postgres instance? This might be relevant to you. TLDR: a small schema change may make your pipeline 30-50% more efficient. How? - Generate less WAL, use fewer CPU cycles on WAL and applying table / index changes.
0
4
12
Tell me you’re a systems programmer without telling me you’re a system programmer (my cofounder). PL I dislike: Makefile.PL I begrudgingly respect: C++.PL I think is overrated: JS/Python.PL I think is underrated: OCaml.PL I like: C.PL I love: Rust .PL I dream of mastering: C++.
2
0
11
when my dog is sick: home cooked pumpkin rice and fish porridge. when i am sick: mucinex and pizza rolls

1
0
11
kinda funny to see someone scrolling robinhood while bored on a first date.
2
0
11




my experience with every trump nomination:.- see on pop crave.- think "is this real".- confirm real.

Donald Trump chooses Dr. Oz as the Centers for Medicare and Medicaid Services (CMS) Administrator.


0
0
10
We built a Pinecone => Postgres export tool!. With a few lines of code, you can export your Pinecone data to Postgres, and build an index using Lantern.
0
2
8
I built a site to browse the Postgres mailing list archives. It supports search using FTS from Postgres + vector search with the Lantern extension. I've been using it for testing but cleaned it up a bit to share 🙂.

0
3
10

halloween in two cities.nyc: costume parties, halloween parade, cool pop-ups.sf: networking event with light halloween decorations.
1
0
8
rereading books after a few years with a different perspective is nice.
1
0
8

hacker after remotely accessing my computer and seeing how i organize my desktop:

0
0
8
fun talk at @pgconfnyc : “elections are weird” featuring many, many more table schemas for elections than you would expect 😅

0
0
7

This week we worked on docs for using @lanterndb with @llama_index !. We added an overview of how to get started:. We also added a guide to auto-retrieval:. Would love to learn more about the tutorials people like with LlamaIndex :).
0
3
7
born too early to explore space.born too late to explore the earth.born just in time to compete with GPT4 for my own job.
1
1
7


The @GetOnboardAI team set up a Learn This Repo for Lantern! It's a free tool to ask questions about our source code. Our source code is available at. Give it a try! ☺️.

Introducing a free tool from Onboard AI. LTR let's you chat with 300+ of our most popular open source repos for free. From Redis, to Postgres, to NextJS, to LangChain. Why did we build this?. 1. The best way to become a better programmer other than.
1
2
6
Thank you to our partners, @gustaf @bradflora @dflieb @garrytan @daltonc, as well as others at YC I've gotten to know over the last few years. When I did YC S20, it was fully remote. I'm grateful I got the chance to experience it in-person this time 🧡.
0
0
6

today's schedule:. 8:00am - 2:00pm: try to fix this bug. 2:01 - 2:03pm: fix the bug. 2:04 - 7:00pm: complain to the people around me about how ridiculous finding that bug was.
0
0
5
@snowmaker cofounder matching is such a great product :) i'm always recommending it and work at a startup to people.
0
1
5

To use it, just call CREATE INDEX with external=true. Concurrent indexing is supported, and subsequent reindexes also use external indexing. Our pgvector fork to enable external indexing: Our CLI to run the external indexing server:
0
0
4
@eshear I don’t think this is a proof for that? Both are invalid. - a plank of wood is not a boat.- adding a plank of wood to something that isn’t a blank of wood doesn’t make it a boat. And yet a boat can be comprised of wood planks. Something can exist only in the aggregate.
0
0
5
customers in 2003: pdfs are bad. customers in 2013: pdfs are bad. customers in 2023: pdfs are bad. founders in 2024: we fixed it!! you can now chat with pdfs… using ai. customers: what.
3
0
5
investors: do you have a plan for monetization?.founders: i have concepts of a plan.
0
0
4
🚀@lanterndb is now available on @llama_index ! 🦙. s/o to @disiok for the assist, you guys are so fast :) excited to ship tutorials next week.
1
1
3

@chefjeffsf @andrew__rea I have some conflict about this -- I agree but at the same time for myself these were often fundamentally bad experiences that I don't want to feel "thankful" for.
1
0
3
This week we released product quantization (PQ) in Postgres. For 35M 768 dimension vectors with (m=16), PQ can reduce the index size from ~105GB to ~10GB. If you’re self-hosting, this can take your monthly cost from ~$1000 to ~$100.
1
1
3
I would like to experience Papa John's as an 8 year old again, the purest form of joy.
1
0
3
@ShaanVP I think they're a lens to understand people better - not just the subject but also yourself, your friends, people with similar or dissimilar traits.
0
0
3
@nooriefyi @D4RK7ET We'll be releasing some additional Postgres extensions next week!. For external indexing, we'd love to support other more expensive indexing processes, such as GIN and GIST.
0
0
3
@mralanagon @ycombinator @lanterndb Hey! I'm not aware of Firebase supporting vector search. AI / Vector support is our core focus. Unlike the others, we built features like PQ quantization, external indexing, inline embedding generation in Postgres, etc. that specifically target AI application needs.
1
0
1
@karinanguyen_ i'm excited about this! i use chatgpt a lot to help with writing. i always drop the entire article to provide context, but repeatedly copy and paste individual paragraphs to iterate. how can i try it out? :).
0
0
6
Our managed service is currently in beta at – reach out for access!. Or self-host! Our source code is available at It's been incredible to work with @ngalstyan4 and @D4RK7ET on this. I can’t believe the number of 4am nights 😅.
1
0
3

I feel like southern Thanksgiving recipes don't actually need all this butter, they just add it in because they saw it and thought why not.
1
0
3
0
0
3
Using only a restaurant, tell us where you went to college



0
0
2
@skeptrune @paradedb imo time will show how important bm25 is, we are just sharing what can be done with vector search + full text search, both of which have been shown to add value to production postgres use cases.
1
0
2