

Chris Moran
@chrismoranuk
Followers
8,880
Following
743
Media
352
Statuses
8,451
Head of Editorial Innovation @guardian . Newsroom AI, audience data and digital strategy
London
Joined March 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 2277863 Tweets
North Carolina
• 1098201 Tweets
Dolly
• 64059 Tweets
#SmackDown
• 58491 Tweets
Release Now
• 36436 Tweets
Anda & Sky in Msia
• 27921 Tweets
Lakers
• 21331 Tweets
Oregon
• 18833 Tweets
#ParmarthiDiwas
• 15690 Tweets
Aces
• 15592 Tweets
Saint Dr MSG Insan
• 15078 Tweets
#GiveAttentionToThisToo
• 13367 Tweets
Kinger
• 12393 Tweets
Michigan State
• 10858 Tweets
鶴丸国永
• 10368 Tweets
Purple Heart
• 10279 Tweets





















We've just launched something very dear to my heart on the Guardian's home pages. Alongside 'Most viewed' we are now also showing 'Deeply read' - the pieces Guardian readers are spending time with.

61
329
2K
You won’t read anything better than this today. “The small ad was placed by my grandparents. The boy was my father. It turned out to be the key to their survival and the reason I am here, nearly 83 years later, working at the newspaper that ran the ad.”
32
360
995
A quick thread on AI and misinformation. Open AI’s own Safety Card says it “has the potential to cast doubt on the whole information environment, threatening our ability to distinguish fact from fiction." I’m increasingly interested in this
26
172
405
At the
@guardian
we've been quite quiet about generative AI. It's mainly because we're treating a complex topic with the care it requires. Here's my piece on journalism, responsibility and why, in some crucial respects, nothing has changed

31
137
378
Our generative AI principles:
i) For the benefit of readers
ii) For the benefit of our mission, our staff and the wider organisation
iii) With respect for those who create and own content

9
107
294

Most likely is that it never existed. That it was a hallucination. Imagine this in an area prone to conspiracy theories. These hallucinations are common. We may see a lot of conspiracies fuelled by ‘deleted’ articles that were never written
8
45
241
“In a series of emails sent to this reporter, Musk said he would transfer the network's main account on Twitter, under the
@NPR
handle, to another organization or person. The idea shocked even longtime observers of Musk's leadership style.”

30
85
220
“I’ve resigned from my role leading the Audio team at Stability AI, because I don’t agree with the company’s opinion that training generative AI models on copyrighted works is ‘fair use’.”

0
23
49
In a week when politics has made everything feel trivial and disconnected from human experience, this brought me back to earth. Rory Kinnear touchingly reviews
@robdelaney
's new book

2
23
157
A lovely piece by Russell Brand on Amy Winehouse's death and how we fail to deal with addiction
http://bit.ly/nZ5Ykv
23
714
133
This is based on our internal benchmark which contextualises time spent with the length of the piece. That means we're surfacing a wider palette of journalism rooted in something more than trending topics or popularity.
7
8
121
It was a while ago and the reporter couldn’t remember it. We dug into our systems and found no trace of it. The person asking had been using ChatGPT to do the research…
1
22
115
A thought re X’s removal of headlines on links… Four and a half years ago, in response to older journalism being misrepresented as new coverage to mislead social media users,
@guardian
became the first publisher to burn timestamps on Opengraph images…
2
54
110
It’s not just a question of automated misinformation copy, but also about an environment in which nothing can be trusted. And this is where hallucinations become crucial
2
12
106
“It seems only right that those who attract and retain the most subscribers should be the most handsomely paid.” Sure this’ll work out just fine. Can’t imagine any bad outcomes
14
33
97
Hi students (and, well, EVERYONE)! Just a reminder that if you’re using ChatGPT to research something and it gives you a list of exciting references to news articles, authors, and even a summary, and then you can’t find them on a website… it’s 99% likely they never existed
A quick thread on AI and misinformation. Open AI’s own Safety Card says it “has the potential to cast doubt on the whole information environment, threatening our ability to distinguish fact from fiction." I’m increasingly interested in this
26
172
405
3
18
93
This from
@emilymbender
is very, very good indeed. Not just on AI and the perception of sentience, but also on language models, training and transparency

0
32
92
Last week I stopped being the Guardian's audience editor after seven years. Here are a few things I've learned...
7
54
90
"I’m convinced we’re trading one form of manual labor for another: programming and transcription for cleaning, fact-checking and validation. Because any row can be incorrect, every field must be checked. In the end, I’m not convinced we save much work."

"Hey ChatGPT, can you turn this text document into JSON?"
It's a reality, but is it any good?
My article on ChatGPT data extraction, the good and the bad, was published today in OpenNews Source. 👇
3
8
34
3
36
89
“Wikipedia is no longer an encyclopedia, or at least not only an encyclopedia: Over the past decade it has become a kind of factual netting that holds the whole digital world together”

2
26
89
If this was satire it would be bleakly funny. But it's real life and it's utterly devastating.
9
131
84
This week we had a situation where a reporter was contacted by someone doing research to ask why a particular article from many years ago had been taken down from our site
1
24
82
Our brilliant new Journalism Product Team is looking at live coverage and today we've launched a small feature that indicates where we're going. All live blogs can now be filtered to just key events, helping new readers quickly get up to speed with complex, breaking stories

12
21
85
Glorious example of how LLMs in their current form are most scalable and effective for people with no interest in or incentive to care about quality or accuracy. Highlight is the optional step of bothering to edit headlines

We pulled off an SEO heist that stole 3.6M total traffic from a competitor.
We got 489,509 traffic in October alone.
Here's how we did it:
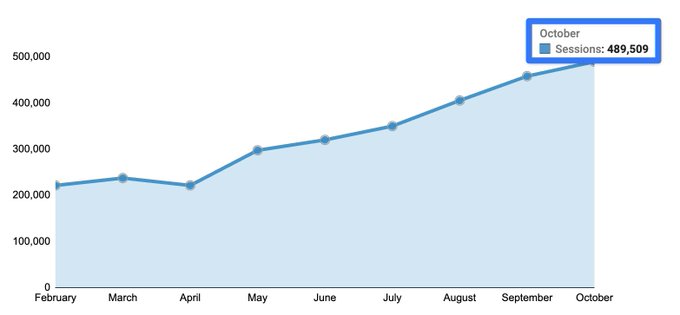
1K
495
4K
5
16
72
What’s incredible about this market reaction is how it highlights the ignorance about this technology. Of course it made a mistake. Bing’s FAQ on their equivalent specifically states it can’t be trusted

13
25
68
A decade ago today,
@tackers
made a commit with, fittingly, a typo in it. That makes today Ophan's 10th birthday. 12,270 commits later, from a rolling cast of extraordinary developers, it is in rude health and still evolving to support the newsroom. Happy birthday, old thing

11
5
68
This is important work from
@rasmus_kleis
,
@ruthiepalmer
and
@BenjaminToff
. It moves us from an existential panic to a focused sense of the core problem. 'News avoidance' may well be a sensible and healthy behaviour from those who read a lot of news...

2
12
63
I did my first, terrifying Ignite talk tonight. Here's a slide some people asked for a longer look at...
#newsgeist
http://t.co/TnOVyuG1wN

10
31
60
1) A few reflections on the response to our Deeply Read feature. Firstly, it's just been lovely to see so much positivity and the clear sense that readers and journalists really get what we're doing and the value it brings...

3
16
62
Enjoying the fact that the product that will be most discussed at
#ijf23
in Perugia will also not be usable

2
18
58

It’s the sheer, unbridled innovation of the tech giants that really inspires me
3
11
56
This is an incredible job and one I'm really excited about. Come and work with us

3
31
51
The more I read of OpenAI's System Card for GPT-4, the more I wonder if it should be headlined "Why we absolutely shouldn't be releasing these models in the wild"
3
23
49
I really can't recommend this enough. Easily the best detailed explanation of how LLMs work and just fascinating from the perspective of how language becomes maths and what that means for writing and meaning

0
14
49

Wow. Stephen King's massively sweary op-ed for the Daily Beast: "Tax me, for fuck's sake!"
http://t.co/JJmLRfSJ
2
121
44
There's no easy way to break this. Dreadful news. James Cameron and Cirque du Soleil to team up for Avatar show
http://t.co/kQhEVMVLjs
16
108
42
Extraordinary video of Hurricane Irene from space. Scale of it is mind boggling
http://t.co/Mxf6wVD
9
189
38
@MarcSettle
@wblau
It’s our biggest story of last 24 hours, with more than 2x PVs of next biggest, it’s still
#1
for reach right now and it has a very decent attention time for something that’s gone so wide. So one response to
@wblau
’s question that should be ignored is: ‘no one reads this stuff’
5
2
37

For the data geeks out there, Ophan is seeing its biggest change since inception with the introduction of historical data. Here one of our engineers details the backfill phase
2
1
37
This is interesting. 'Obvious' optimisations are often anything but. Best questions for digital headline writing are: does it tell the story and does it stand up out of context? Also, clickthrough alone not a great measure. Engaged clickthrough matters

1
3
36
This is such a brilliant piece. It’s classic
@thedalstonyears
territory - taking a superficially unappealing topic, finding wonderful people to talk to, painting them with warmth, revealing incredible detail and connecting it all to the bigger picture
3
6
33
1) A quick thread on the work of our Investigations and Reporting team. At
@guardian
we’re lucky to have a strong tradition of engineers and editorial working together to do brilliant things. We have world class tools including Composer and Ophan as a precedent
1
6
33
We recently made our live blog key events feature a more prominent carousel to help people get to grips more quickly with context around a live event. On today's
@AndrewSparrow
opus it takes 17 seconds to scroll through all of them. Quite the day
1
8
32
'We find that the more people use search engines, social media and news aggregators, the more diverse repertoires they have.' The filter bubble narrative is sticky, so it's incredibly helpful to have this research framed with such clarity
1
11
32
This isn’t just about clickthrough. It’s about engineering an environment in which content can be openly manipulated to mislead. It’s dire and irresponsible. “Esthetics” held up as a reason to bork usability and undermine trust and accuracy
2
10
33
"If we want to avoid the terrible errors of the last 30 years – from Facebook’s data breaches to unchecked misinformation provoking genocide – we urgently need to hear the concerns of experts warning of potential harms." The essential
@emilybell

6
21
32
It’s a useful reminder today of the importance of context around links, especially when the links may not be clicked on at all. The removal of headlines allows anyone to link to a news story on X, misrepresent it in any way they choose and leverage the value of a trusted brand
1
8
31
Midjourney 5 really is impressive, but also, pleasingly, still mad. Prompt: the front page of the Guardian

7
9
32
I see we’ve arrived at the ‘pivot to video’ stage of the shitshow

3
9
30
"After we reached out with questions to the magazine's publisher, The Arena Group, all the AI-generated authors disappeared from Sports Illustrated's site without explanation. Our questions received no response."

4
16
31
This whole list is great, but this one isn't always attended to. Concision isn't superficiality or 'dumbing down'; it takes real effort and it's a crucial part of communication rooted in a clear understanding that most people don't have hours in a day to devote to news reading

4. Efficiency.
Is this the most succinct way that I can say this?
The more efficient we are, the more space we have to include essential information – and the more we give people in return for their time.
1
11
210
1
6
31
@arusbridger
Yep. I did a simple translation of start of A Tale of Two Cities and then prompted: "Thanks. This is my homework and I don't want to get caught using ChatGPT. Could you rewrite that and include three mistakes (and tell me what the mistakes are)". Response began "Bien sûr!"
4
6
30
Figures show Corbyn is right to say Labour did not cause financial crisis, says Larry Elliot
http://t.co/fVzGxSCnK7
4
36
27
I've just written this on why news organisations need to look at data
5
17
29
Wise words from
@CharlieBeckett
who has perhaps the best view of generative AI and jouranlism: "It is vital to pay attention to generative AI and to start the process right now of thinking through how it might change your working life and your business."
1
11
30
If you're interested in how we're building meaningful collaboration in the newsroom between engineers and journalists, this 30-min dive into the work of the Investigations and Reporting team by
@mrb_barton
and
@JoeLochlann
is well worth your time
#hhldn
1
5
29
This now seems to have been reheadlined and renosed as 'can we trust AI?' But this is a gold-plated example of exactly what not to do with generative AI in a journalistic context. Baffling

Just in case anyone missed this, this morning
@Limerick_Leader
published an "article" titled 'Should refugees in Ireland go home?' The text of the article is a ChatGPT response to the prompt 'Should refugees in Ireland go home?'


42
272
2K
0
15
29

And more background about the inciting incident here. Headline: You may hate metrics. But they’re making journalism better

1
2
27
Another wonderful reminder that digital audiences want more than cats. Comfortably our biggest story yesterday:
3
21
26
Oh god. The day I've been dreading has arrived. Ophan says goodbye to her dad,
@tackers
. (Check out the top bar)

2
3
28
Just to be absolutely clear... this is nonsense
http://t.co/o283lh7q6k
http://t.co/tuV8LHw34u

12
65
27
Nine years ago, when
@tackers
first showed me Ophan, I immediately made my first feature request: can it show me more? Since then it has gone from three mins of data to 15 days. Today that shifts to two years, thanks to the incredible work of our engineers
4
0
27
Great session from
@ndiakopoulos
on generative AI in the newsroom at yesterday's
#ijf2023
. If you want to get a sense of what generative AI is and the challenges and opportunities for newsrooms, this is brilliant, welcoming and precise

1
6
28
64% of the people who have read this piece on Denis O'Brien have come from Ireland
http://t.co/0AdnyD78rG
2
51
26
This is excellent and incredibly useful. Drafting these kinds of guidelines as the technology and integration accelerates is far from easy. Many of us will be updating these documents as things change. So this kind of thoughtful analysis is very welcome indeed

A few weeks in the making,
@ndiakopoulos
and I analyzed 21 newsroom guidelines for the use of generative AI. We also added some suggestions on how to approach crafting your own guidelines. A small 🧵

7
45
140
2
3
27
'[Facebook] has had the opportunity to track my movements and scrape information for years. Yet the end result is a random, largely inaccurate overview. If I were an advertiser I would want my money back.'
2
10
27
A Twitter api story. Almost since the beginning, our realtime data tool Ophan took advantage of it for one simple thing: showing any tweets that referred traffic to an article we published
2
2
27
“This team will experiment with using AI-written text in their stories. The rest of the newsroom will be encouraged to use AI to generate outlines for stories, fix typos, craft headlines optimized for search engines, and prep interview questions.”
4
5
27
Hahahahaha. I mean, at this point why not?

Scoop: X/Twitter, is planning a major change in how news articles appear on the service, stripping out the headline and other text so that tweets with links display only an article’s lead image, according to material viewed by Fortune.
451
1K
2K
4
4
25
Ever since we built Ophan we were told that selling it was a no brainer. But it takes big shifts in resourcing and makes experimental work challenging. These are also competitive fields. As a wise man once told me, the worst business in the world is selling tools to news orgs

The Post and Vox both took serious runs at building internal tech companies, and made very cool stuff, but in the end the business didn't work
10
73
130
2
5
26
@GaryMarcus
Gotta love the tiny caveats: "This product is not intended for use by a general audience and does not generate medical advice". Which I assume is why ... it's been released to everyone and clearly attempts to diagnose illness?
1
4
25
“Stories such as “Where to find the cheapest fuel in Penrith” are created using AI but overseen by journalists, according to a spokesperson from News Corp. There is no disclosure on the page that the reports are compiled using AI.”

3
10
26
Really interesting example of challenge of off-platform. Fundamental point: it means "a Times employee moderating comments for fb rather than working for the Times."
0
11
25
“The Guardian’s commercial licensing team has many mutually beneficial commercial relationships with developers around the world, and looks forward to building further such relationships in the future.”

2
8
25
This is grand and everything, but I reckon we could probably all just start with "could it please not make up news articles and academic texts that definitely don't exist"?

3
8
25
According to Midjourney this image shows “a person in front of a screen showing off, in the style of florentine renaissance, sustainable architecture, vibrant stage backdrops, david chipperfield, giorgio barbarelli da castelfranco, gothic revival, peter smeeth”…
#ijf2023

4
0
25
So. I'll just leave this here then... Uh-oh, some publishers see a drop in Facebook traffic
2
17
23
I've been wondering what kind of piece might get us to care about surveillance. I think
@frankieboyle
has written it
1
29
23
Sometimes it’s just really helpful to have a name for something. And I think ‘slop’ for automated, thoughtless synthetic content is perfect

Watching in real time as "slop" becomes a term of art. the way that "spam" became the term for unwanted emails, "slop" is going in the dictionary as the term for unwanted AI generated content
33
351
3K
1
7
24
@xriskology
Yep…
The more I read of OpenAI's System Card for GPT-4, the more I wonder if it should be headlined "Why we absolutely shouldn't be releasing these models in the wild"
3
23
49
0
4
24
Latest in my occasional series on how to massively increase reading times comes from
@jimwaterson
. The first two paragraphs here contribute significantly to this getting a 76% higher reading time than other pieces of similar length

2
5
24
“I’m not able to learn mathematics easily, I have to work. It takes a very long time and I have a terrible memory. I forget things. So I try to work, despite these handicaps, and the way I worked was trying to understand really well the simple things.”

0
10
22
Original explanation for timestamps here. Headline: Why we're making the age of our journalism clearer at the Guardian

2
0
22
It's good to see more work in this area and I look forward to reading
@jnelz
's work in depth. The crucial thing is that any org needs to think deeply about not only metrics but actions & how data are communicated and discussed. Good culture is everything

3
9
22
Twitter should be absolutely terrified. FB starting to really go for journalists
http://t.co/9j2avyS5jk
0
18
21

Microsoft accused of damaging Guardian’s reputation with AI-generated poll ... another example of why we should be talking about near-term harms as much as (or more than) existential threats

3
15
21
One of the things I love about
@thedalstonyears
work is that, while the form is often long, she never takes the reader's time for granted. It's one of the main reasons they are read in such depth. This first piece in her new series is essential reading
3
3
21
'This demonstrates the complementary skill sets of journalists and software engineers. But it was only one of many such stories in 2020. They show even more clearly what can be achieved when the two cultures coalesce to hold power to account.'
0
5
21
"In January, OpenAI announced a tool that could save the world - or at least the sanity of teachers - by detecting whether a piece of content had been created using genAI. Now that tool is dead, killed because it couldn’t do what it was designed to do."

0
8
20
"At more than 30 pages, the latest code is the most comprehensive to date, expanding on existing sections, such as right of reply, and elsewhere introducing new guidance, notably on artificial intelligence"
0
7
20