
Alaa El-Nouby
@alaa_nouby
Followers
634
Following
737
Media
15
Statuses
181
Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬 Deprecated twitter account: @alaaelnouby
Paris, France
Joined August 2023
𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔.Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding. (🧵)
4
28
154
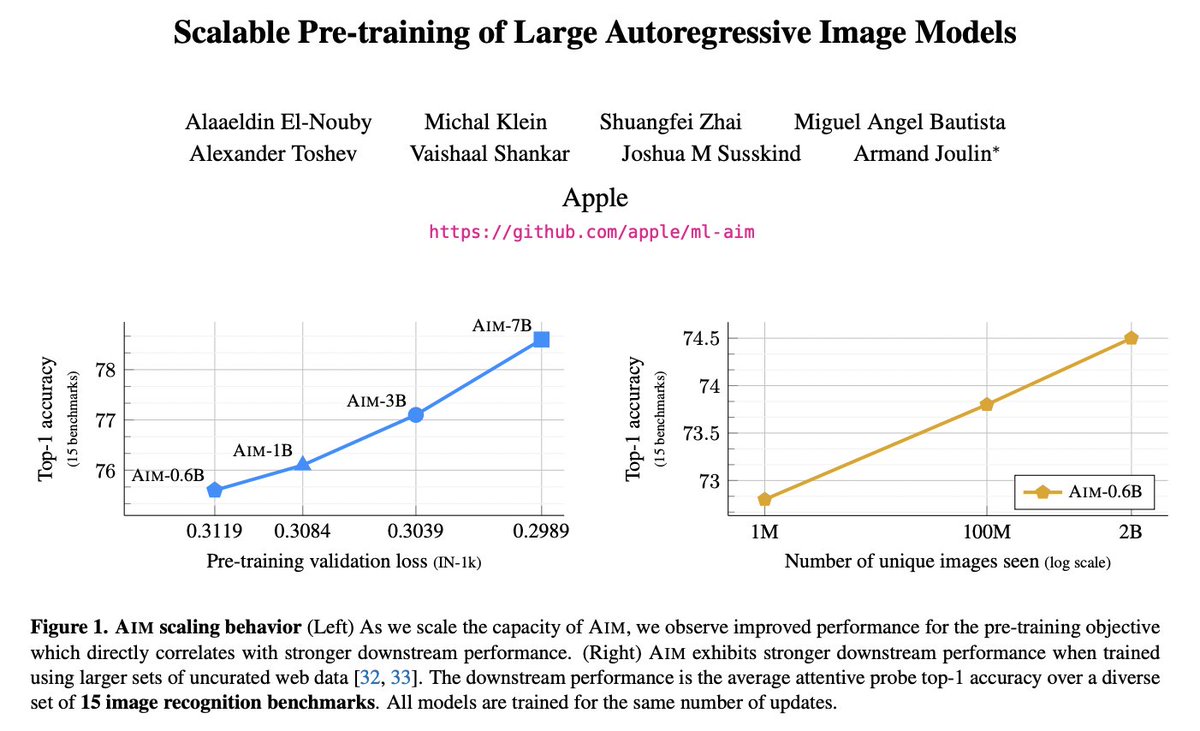
Excited to share AIM 🎯 - a set of large-scale vision models pre-trained solely using an autoregressive objective. We share the code & checkpoints of models up to 7B params, pre-trained for 1.2T patches (5B images) achieving 84% on ImageNet with a frozen trunk. (1/n) 🧵
8
56
210
📢 The @Apple MLR team in Paris is looking for a strong PhD intern. 🔎 Topics: Representation learning at scale, Vision+Language, and multi-modal learning. Please reach out if you're interested! You can apply here 👇.
3
27
88
AIM🎯 models can now be directly downloaded from HuggingFace Hub 🤗. Thanks to @NielsRogge @osanseviero @_akhaliq for their help setting this up!.
2
20
83
Don't forget to check the code and models on GitHub: With few lines of code, you can load AIM models up to 7B params, using your DL framework of choice: Pytorch, JAX, or MLX


Apple released AIM on Hugging Face. Scalable Pre-training of Large Autoregressive Image Models. model: introduce AIM a collection of vision models pre-trained with an autoregressive generative objective. We show that autoregressive pre-training of image

1
13
63
AIM stands for “Autoregressive Image Models” and it comes in Pytorch, JAX, and MLX. Getting started is as easy as the snippet below. Paper: Code+weights: HuggingFace: (2/n)

1
3
42
Very interesting work from our colleagues at Apple MLR (Building on the great work by @garridoq_) showing how you can use Linear Discriminant Analysis rank to measure the quality of the representation during training w/o downstream labels.

ICLR24 Spotlight: To train general-purpose SSL models, it's important to measure the quality of representations during training. But how can we do this w/o downstream labels? .We propose a new label-free metric to eval SSL models, called Linear Discrimination Analysis Rank(LiDAR)

0
2
13
Finally, AIM is nothing without the team behind it ❤️ . Michal Klein @zhaisf @itsbautistam @alexttoshev @Vaishaal @jsusskin @armandjoulin and all of the Machine Learning Research team at @Apple. (n/n).
1
0
11
Great job by @Vaishaal and the team at Apple! Check out DFN

Glad to see SigLIP doing well (relatively speaking) on this new benchmark! DFN by @Vaishaal also doing quite well. The rest seems pretty far behind, even with larger models. Now I wonder how well CapPa will do here, given the SugarCrepe results, I think very well :)

1
1
11
While we worked together for 3 years during our time at Meta, this was the first time to work this closely with @armandjoulin and it was a blast! .Looking forward to all the great work you are going to do next.

Our work on learning visual features with an LLM approach is finally out. All the scaling observations made on LLMs transfer to images! It was a pleasure to work under @alaaelnouby leadership on this project, and this concludes my fun (but short) time at Apple! 1/n.
0
0
9
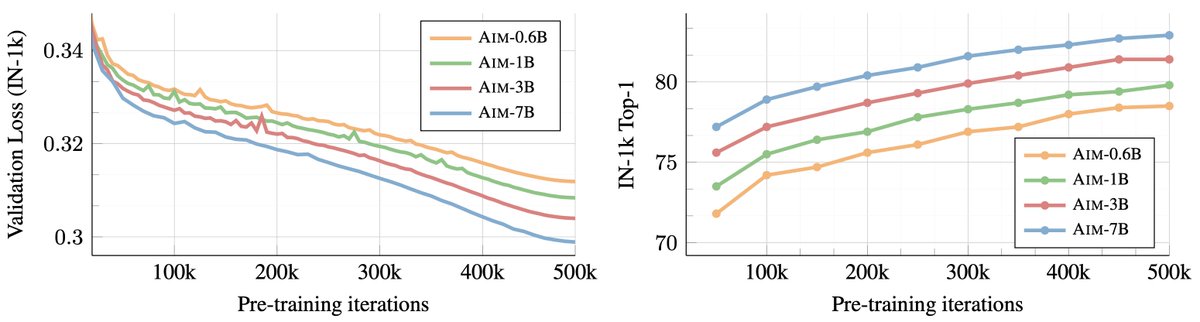
Similar to LLMs, improving the pre-training autoregressive objective of AIM directly leads to improved downstream performance (across 15 diverse recognition benchmarks). We observed no signs of saturation as we scaled AIM’s capacity. AIM-7B could be just the start . (3/n)

1
2
10
One interesting observation is that the same validation loss (roughly) can be achieved either by scaling the model capacity (e.g. 3B → 7B) or training the same model using more data (2B images → 5B images), with both cases using a similar number of FLOPs. (5/n)

1
0
10
AIM could not be simpler. We scale AIM to 7B parameters with zero tuning to the hparams across capacities and no tricks for stabilization whatsoever:. ❌ Stochastic Depth.❌ QK-Layernorm.❌ LayerScale.❌ Freezing patch embedding. (6/n).
1
0
9
I want to highlight another great concurrent work by @YutongBAI1002 et al. showing the power of autoregressive vision models for solving many pixel prediction tasks (e.g. segmentation, depth estimation). Autoregressive vision is here to stay . (9/n).

How far can we go with vision alone? .Excited to reveal our Large Vision Model! Trained with 420B tokens, effective scalability, and enabling new avenues in vision tasks! (1/N).Kudos to @younggeng @Karttikeya_m @_amirbar, @YuilleAlan Trevor Darrell @JitendraMalikCV Alyosha Efros!.
2
0
7
AIM is primarily pre-trained using a dataset of 2B web images (DFN by @AlexFang26 & @Vaishaal ). AIM breaks free from ImageNet pre-training and can be trained effectively using large-scale uncurated web images to reach a performance superior to ImageNet only pre-training. (4/n)

1
1
8
@zhaisf @itsbautistam @alexttoshev @Vaishaal @jsusskin @armandjoulin @Apple and as always thanks @_akhaliq for sharing our work!. (n+1/n).
Apple presents AIM. Scalable Pre-training of Large Autoregressive Image Models. paper page: paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e.,
0
1
6
"But causal attention does not make sense for many downstream vision tasks!". AIM has been pre-trained using prefix attention (similar to PrefixLM) such that it can seamlessly generalize to bidirectional attention for downstream tasks. (7/n)

2
0
8
As for the autoregressive patterns, we find that good old raster order still performs the best. (Raster > Spiral > CheckerBoard > Random). We observed the patterns with more uniform difficulty across patches tend to outperform those with unbalanced difficulty. (8/n)

2
1
6
We are excited about the future of large-scale vision models and cannot wait to see what the community will build on top of AIM. (10/n).
1
0
5
@MrCatid @ducha_aiki DINOv2 is a fantastic backbone (I am a co-author of DINOv2 as well). But there are a few differences:.(1) DINOv2 is evaluated with much higher-res. images. (2) It needs a high number of tricks to work. (3) Is not trained with web-images, but a curated dataset resembling IN-1k.
2
0
3
I have lost access to my Twitter/X account (@alaaelnouby) because of 2FA with an expired email account. I will be using this account instead moving forward.
0
0
1
@itsclivetime @armandjoulin @alaaelnouby Thanks for the feedback @itsclivetime! We made this choice to align both axes of improvement. Similar choice was made by figure 3 in the iGPT paper by OpenAI for example.
0
0
2
@ahatamiz1 Yes and actually it works pretty well! The drop in performance is less than one point compared to the prefix+bidirectional setup. We opted out to prefix+bidirectional as the default setup since it is more natural for most downstream tasks.

1
0
1