

Yossi Adi
@adiyossLC
Followers
832
Following
2K
Statuses
221
Assistant Professor @ The Hebrew University of Jerusalem, CSE; Research Scientist @ Meta AI (FAIR); Drummer @ Lucille Crew 🤖🥁🎤🎧🌊
Israel
Joined June 2016
RT @hila_chefer: VideoJAM is our new framework for improved motion generation from @AIatMeta We show that video generators struggle with m…
0
191
0
🥁📷JASCO training & inference code + pre-trained model! More details 👇

Release Announcement!📢💣 🥁🎷JASCO 🎶🪇 training & inference code + model weights are out! Paper📜: Samples🔊: Code🐍: Models🤗: @lonziks @itai_gat @FelixKreuk @adiyossLC
0
1
14
Very nice work on image-to-video generation by @guy_yariv :) 🖼️➡️📽️ Paper: Project page:

[1/8] Recent work has shown impressive Image-to-Video (I2V) generation results. However, accurately articulating multiple interacting objects and complex motions remains challenging. In our new work, we take a step toward addressing this challenge.
0
0
12
RT @RobinSanroman: Excited to share that our two papers were accepted at #ICASSP2025, both focus on Audio Language Models! 🗣️🎶 1/10
0
4
0
RT @GallilMaimon: 🚨New paper on SLM evaluation🚨 We present SALMon🍣 which is a suite of benchmarks for evaluating how much Speech Language M…
0
22
0
Our paper "The Larger the Better? Improved LLM Code-Generation via Budget Reallocation" got accepted to @COLM_conf. We evaluate LLMs of different sizes on coding tasks under a fixed budget and found that larger LLMs does not necessary perform better! For more details see 👇

Which is better, running a 70B model once, or a 7B model 10 times? The answer might be surprising! Presenting our new @COLM_conf paper: "The Larger the Better? Improved LLM Code-Generation via Budget Reallocation" 1/n

0
1
20
RT @jpineau1: Open Source AI is the Path Forward Llama 3.1 release includes a new 405B model, improved 8B & 70B, 12…
0
38
0
RT @AIatMeta: Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet. Today we’re releasing a…
0
1K
0
Super nice work by @itai_gat and the team! A non-autoregressive model based on discrete flow matching, reaching impressive results on text/code generation, also for real world tasks! (i.e., HE/MBPP) More info 👇

Excited to share Discrete Flow Matching! A discrete flow framework that yields state-of-the-art non-autoregressive modeling. E.g., on code tasks (Pass@1): HumanEval 6.7/11.6, MBPP 6.7/13.1 w/ Tal Remez, @shaulneta, @FelixKreuk, @RickyTQChen, @syhw, @adiyossLC, @lipmanya
0
0
13
RT @Amit_Roth: We present our #INTERSPEECH2024 paper "A Language Modeling Approach to Diacritic-Free Hebrew TTS" 🎙️. Model is fully open so…
0
18
0
I find these results super interesting as they both improve performance on visual commonsense reasoning and even provide (minor) improvements in text-only reasoning benchmarks. Joint work with @guy_yariv @idansc, and @BenaimSagie
0
0
4
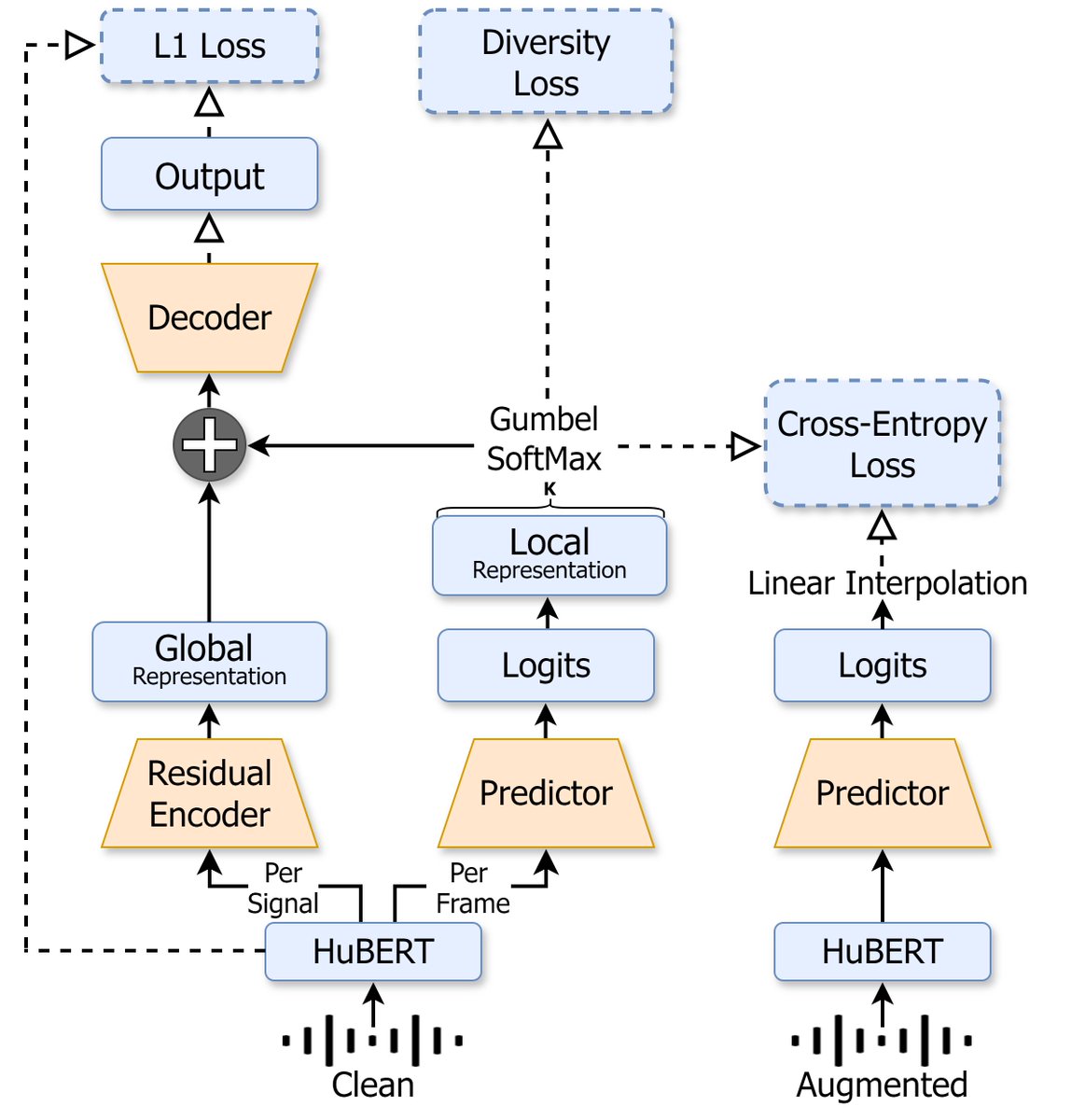
Speech tokenizers are fundamental in building speech LMs. In a recent study we show the common tokenization method (a.k.a “semantic tokens”) is not robust to different signal variations. We then present NAST! a noise aware speech tokenizer w. @ShovalMessica Code and models 👇

🚨I’m excited to share our #INTERSPEECH2024 paper "NAST: Noise Aware Speech Tokenization for Speech Language Models” 🥳 W/ @adiyossLC Paper- Code-
0
7
38
0
0
0