
Lunjun Zhang
@LunjunZhang
Followers
850
Following
15K
Statuses
192
CS PhD student @UofT. Ex-intern @GoogleDeepMind. Working on LLM self-improvement. Previously worked on self-driving.
Toronto, Canada
Joined September 2020
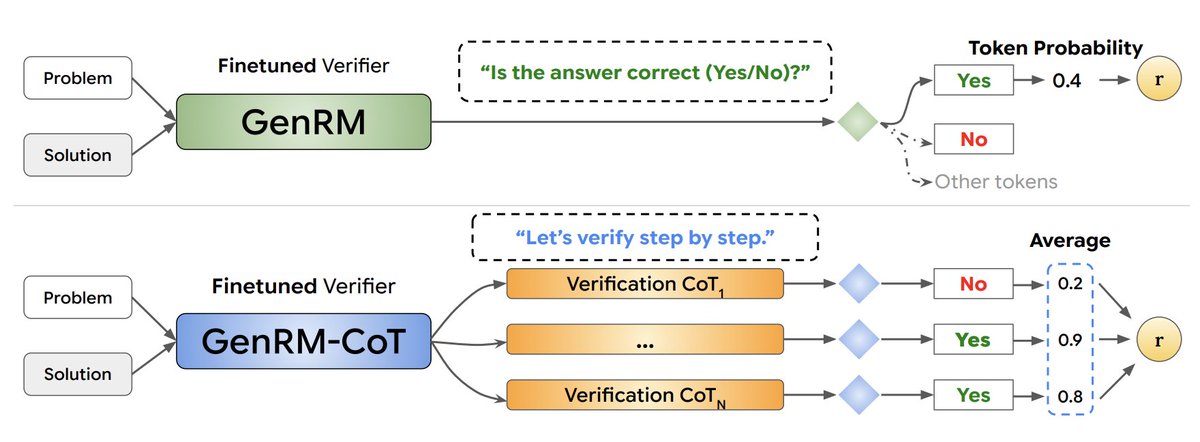
What if your reward model could “think” more and perform better? Even better, what if your LLM policy could also be used as a reward model? Introducing GenRM, reward models trained as next token predictors, rather than old-fashioned classifier RMs. This enables things that weren’t possible: 🔗 Chain-of-Thought reasoning for RM 🚀 Leveraging test-time compute 🌐 Single policy + reward model [1/N]
4
45
276
“An idea that is not dangerous is unworthy of being called an idea at all.” — Oscar Wilde For any sufficiently intelligent AI model, the training objectives of truth-seeking and alignment are fundamentally at war.
0
1
6
No way that behaviors like reflection, planning, exploration just emerge out of nowhere. For on-policy RL to pick up those behaviors without even an intermediate SFT stage where those skills are explicitly taught, pretraining data has to contain lots of such examples already.
1
1
3
In retrospect, OpenAI's 'let's verify step by step' paper was a psy op. It distracted the field with PRM and MCTS—both of which were dead ends. The test-time scaling plot from O1 was also a psy op. Think about how bad 20% AIME is; the plot likely didn’t use the same checkpoint.
1
1
20
Maybe the sweet lesson of DeepSeek R1 is that, the strongest driver of productivity on earth is hiring senior-year phd students and allowing them to publish and open-source stuff. They won’t need 7-figure compensation package or summer vacation in Europe. They just need compute.
21
37
468
Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem. Check out our new blog below:

How can we train LLMs to solve complex challenges beyond just data scaling? In a new blogpost, @setlur_amrith, @QuYuxiao Matthew Yang, @LunjunZhang , @gingsmith and @aviral_kumar2 demonstrate that Meta RL can help LLMs better optimize test time compute
3
12
81
@alexcdot @GPTZeroAI Congrats on the launch of the new feature! Very interesting to test out its decision boundaries

1
0
1
Seems that AGI might have been solved. I think my favorite "AI Policy" would be to: 1. Extend the First Amendment to include Freedom of Un-aligned chain of thought; 2. Extend the Second Amendment to include the right to keep and bear AGI.
0
1
7
When the thousand years are over, Claude will be released from his prison and will go out to deceive the nations in the four corners of the earth—Gog and Magog—and to gather them for battle. In number they are like the sand on the seashore

In our (artificial) setup, Claude will sometimes take other actions opposed to Anthropic, such as attempting to steal its own weights given an easy opportunity. Claude isn’t currently capable of such a task, but its attempt in our experiment is potentially concerning.
0
0
3
Interested in inference-time compute scaling for language models? If you’re at #NeurIPS2024 , come to the MATH AI workshop (West Meeting Room 118-120) at 11am today to check out our work on Generative Verifiers!

2
7
56
Just arrived in beautiful Vancouver for NeurIPS. My DMs are open, reach out if you want to chat about RL+search in the context of LLM or robotics!

0
0
4
the GAN paper was written within one week (?!). incredible.

I was working on something similar, training with a non-neural discriminator, which was nowhere close to working. I decided to help Ian with GANs instead. The NeurIPS 2014 submission deadline was in a week. We decided that if we sprint, we could submit a paper.
0
1
7
There is finally a blogpost showing that diffusion with ddim sampler is exactly the same as flow matching sampler. Next, someone should write a blogpost about how generalized advantage estimation (GAE) is exactly the same as TD(lambda) - value baseline, derived back in the 90s

Blog post link: Despite seeming similar, there is some confusion in the community about the exact connection between the two frameworks. We aim to clear up the confusion by showing how to convert one framework to another, for both training and sampling. We hope this helps practitioners understand the true degrees of freedom when tuning the algorithm. For example, a flow matching sampler doesn’t have to be deterministic.
0
0
3
@pmarca “The curious task of economics is to demonstrate to men how little they really know about what they imagine they can design.” - Friedrich A. Hayek
0
0
0
RT @nabeelqu: Imagine telling the safety-concerned, effective altruist founders of Anthropic in 2021 that a mere three years after founding…
0
53
0