

Haihao Shen
@HaihaoShen
Followers
2,944
Following
2,710
Media
40
Statuses
436
Creator of Intel Neural Compressor/Speed/Coder, Intel Ext. for Transformers, AutoRound; HF Optimum-Intel Maintainer; Founding member of OPEA; Opinions my own
Shanghai
Joined September 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#T20WorldCup
• 198057 Tweets
Bardella
• 171448 Tweets
#INDvENG
• 135225 Tweets
Speed
• 125112 Tweets
#loveIsland
• 121256 Tweets
Lakers
• 116395 Tweets
Grace
• 112305 Tweets
Tony
• 111380 Tweets
Kohli
• 107437 Tweets
EFCC
• 75102 Tweets
Bapu
• 70550 Tweets
Raul
• 67823 Tweets
Bronny
• 67524 Tweets
Sharon
• 66470 Tweets
#TemptationIsland
• 51072 Tweets
Pete
• 49800 Tweets
Joey
• 48577 Tweets
Jess
• 42905 Tweets
Jenny
• 31499 Tweets
Oklahoma
• 31211 Tweets
Dube
• 30945 Tweets
Olga
• 30451 Tweets
Aida
• 27321 Tweets
Bumrah
• 23098 Tweets
Kuldeep
• 21658 Tweets
Faure
• 21441 Tweets
Harriet
• 19000 Tweets
Polônia
• 16779 Tweets
ESCUELA DE COCINA FURIOSA
• 16096 Tweets
Tractor Supply
• 15769 Tweets
Jadeja
• 13810 Tweets
Adara
• 13746 Tweets
#SVAllStarsGala2
• 13138 Tweets
Buttler
• 12661 Tweets
Martina
• 10574 Tweets




















Pinned Tweet

🔥Great to share with you that
@HabanaLabs
Gaudi accelerator has been supported in AutoGPTQ.
🎯PR: Congrats Danny and Habana team! Thanks to fxmarty!
⏰Intel Neural Compressor will be fully supporting the model compression for Gaudi soon. Stay tuned!

0
10
41
🧩No GPU but wanna create your own LLM on laptop?
🎁Here is a gift for you: QLoRA on CPU, making LLM fine-tuning on client CPU possible! Just give a try.
📔Blog: Kudos to ITREX team!
🎯Code:
#IAmIntel
#intelai
@intel
@huggingface

6
161
675
🔥Excited to share our NeurIPS'23 paper on Efficient LLM inference on CPUs! Compatible with GGML yet better performance up to 1.5x over llama.cpp!
📢Paper:
📕Code:
#oneapi
@intel
@huggingface
@_akhaliq
@MosheWasserblat

7
108
659
🚀Up to 3x LLM inference speedup using speculative decoding from
@huggingface
with Intel optimizations!
📘Guide:
🎯Project:
#oneapi
#iamintel
#intelai
@intel
@huggingface
3
56
340
📢Just change the model name, you can run LLMs blazingly fast on your PC using Intel Extension for Transformers powered by SOTA low-bit quantization!
🎯Code: , supporting Mistral, Llama2, Mixtral-MOE, Phi2, Solar, most recent LLMs.
🤗
4
58
321
🎯We released GPT-J-6B INT8 ONNX models (first time for INT8 ONNX LLM❓) with ~4x model size reduction while preserving ~99.9% accuracy of FP32 baseline.
🔥GPT-J-6B INT8 models are now publicly available at Hugging Face model hub!

6
47
280
🚀Accelerate LLM inference on your laptop, again CPU! Up to 4x on Intel i7-12900 over llama.cpp!
🎯Code:
📢Chatbot demo on PC: ; Hugging Face space demo locally:
#oneapi
@intel
@huggingface
@_akhaliq
@Gradio
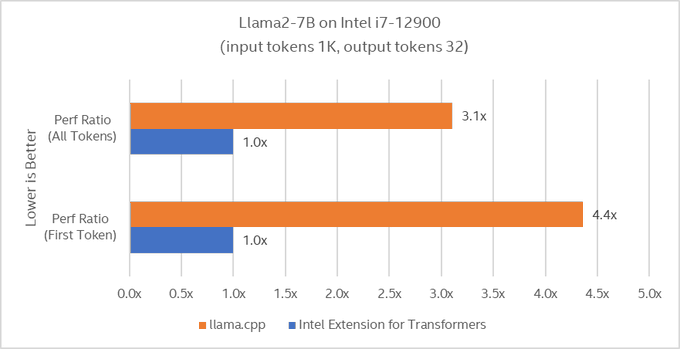
9
56
274
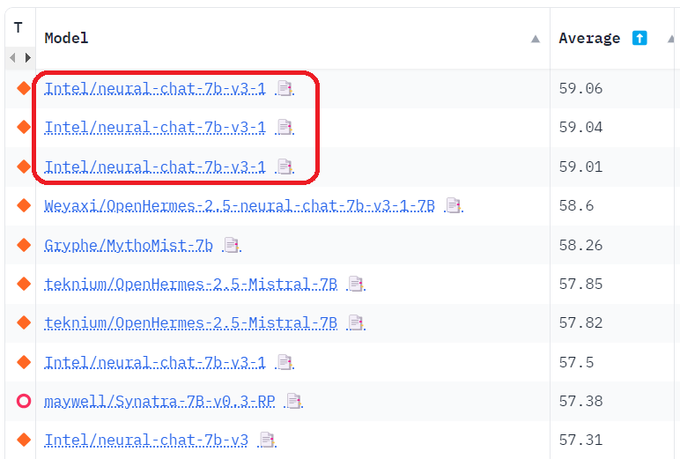
🔥Wanted to get the best low-bit LLM? Yes, we released a dedicated low-bit open LLM leaderboard for AIPC: , inspired from
@huggingface
LLM leaderboard!
#intelai
#inc
#GPTQ
#AWQ
#GGUF
@humaabidi
@lvkaokao
@_akhaliq
@ollama
@martin_casado
@jeremyphoward

11
79
258
🚀Thrilled to release INT8 BGE-1.5 models on Hugging Face and demonstrated ~5ms latency of embedding 512 seq length on Intel CPU!
👉Code:
🎯Models: ;
#oneapi
@intel
@huggingface
@_akhaliq
@MosheWasserblat
6
40
240
📢Thrilled to announce Intel Extension for Transformers v1.3 released, featuring 1) efficient low-bit inference and fine-tuning, and 2) improved open-source chatbot framework Neural Chat.
👨💻Notes:
🤗Code:
X'mas and Happy New Year!
2
40
180
🤗Intel Extension for Transformers supports Mixtral-8-7B with 8-bit and 4-bit inference optimizations on Intel platforms! Start from CPUs🚀
🙌Don't hesitate to give a try. Sample code below👇
🎯Project:
#iamintel
#intelai
@intel
@huggingface
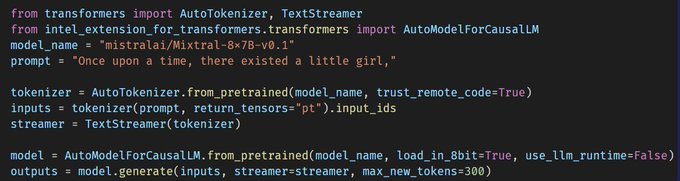
5
41
232
🥇NeuralChat, new Top-1 7B-sized LLM on leaderboard, is now from Intel, trained on Gaudi! 4-bit inference is supported!!
🎯Model:
📢Blog:
#oneapi
@intel
@huggingface
@clefourrier
@_lewtun
@jeffboudier
@humaabidi
@MosheWasserblat

7
22
225
📢If you don't have a GPU but want to run GPTQ and AWQ INT4 LLMs, here is the alternative to run well on your CPU: . Give it a shot!🤗
10
47
226
⚡️AutoRound, new SOTA LLM low-bit quantization approach developed by Intel Neural Compressor team ()
🎯Lots of interesting comparison with GPTQ, AWQ, HQQ, etc. Check out the blog for more details:
@huggingface
#IAmIntel

4
53
217
🔥INT4 whisper family models are out! Powered by Intel Extension for Transformers and INC!
@YuwenZhou167648
@mengniwa
@huggingface

8
41
207
📢Thrilled to announce the support of multi-turn chat using 4-bit LLM on Client CPU!
🚀Sample Code:
🔥Instruction to create gradio-based demo:
🎯Project:
#oneapi
@IntelSoftware
@huggingface
@Gradio
@_akhaliq
6
55
203
📢We are hiring full-time interns for LLM-based workflow development (e.g., retrieval-augmented generation for domain chatbot, co-pilot assistant, ...)
📷Location: Shanghai (or working remote in PRC)
🎯Project:
If you have interests, DM with your resume.😀
4
30
199
♥️ Happy Thanksgiving! Thanks to my family, friends, colleagues, partners, collaborators! Love you all!!
🔥We released QLoRA for CPU, to help you enable fine-tune LLMs on your laptop! See below👇
📢Code:
#deeplearning
#intelai
#GenAI
@intel
@huggingface
3
42
194
🔥Wanted to quantize 100B+ model on your laptop with 16GB memory? Hmmm, GPTQ does not work...
🎯Intel Neural Compressor supports layer-wise quantization, unlocking LLM quantization on your laptop! Up to 1000B model❓
📕Blog:
#oneapi
@intel
@huggingface

8
36
197
🚀Share with you a nice blog "llama.cpp + Intel GPUs". Congrats to the awesome team especially Jianyu, Hengyu, Yu, and Abhilash, and thanks to
@ggerganov
for your great support.
📢Check out the blog:
🎯WIP with ollama now
#iamintel
#llama
@ollama

2
47
190
📢StreamingLLM landed in Intel Extension for Transformers to support LLM inference infinity on CPU, up to 4M tokens!
🎯Check out the code: , search "StreamingLLM" and have a try!
#oneapi
@intel
@huggingface
@Guangxuan_Xiao
@_akhaliq
1
42
186
📢Do you want to make your LLM inference fast, accurate, and infinite (up to M tokens)? Here is the improved StreamingLLM with re-evaluate and shift-RoPE-K support on CPUs!
🔥Code:
📕Doc:
#oneapi
@intel
@huggingface
@Guangxuan_Xiao
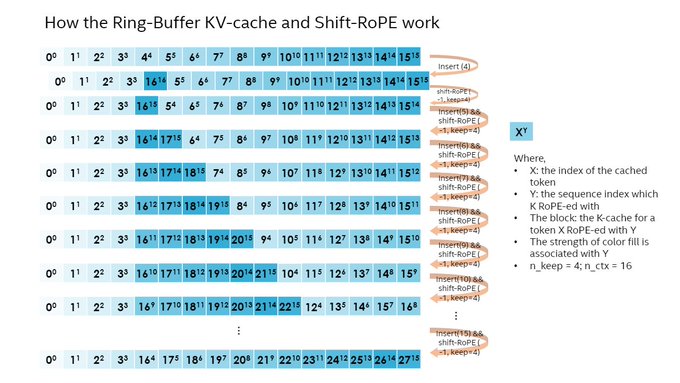
1
39
184
🚀Neural Speed + ONNX Runtime makes LLM inference more efficient on CPUs!
🎯Code:
#intelai
#aipc
#onnxruntime
#LLMs

3
32
184
🔥llama.cpp officially supports Sycl, showing promising perf gains over OpenCL. Give a shot on Intel GPUs e.g., Arc 770!
PR:
Congrats Abhilash/Jianyu/Hengyu/Yu! Thanks
@ggerganov
for the review! Transformer-like API soon in
@RajaXg
5
39
180
🔥Wanted to quantize LLMs with best accuracy & smallest size, Intel Neural Compressor is your choice. We just released v2.6 featuring SOTA LLM quantizer, outperforming GPTQ/AWQ on typical LLMs.
🎯Quantized LLM leaderboard:
Github:

1
38
184
🚀Thrilled to share Intel Extension for Transformers supports INT4 model quantized by GPTQ on Intel platforms (Xeon & PC) !
🎯Guide:
🤗Model: e.g., TheBloke/neural-chat-7B-v3-1-GPTQ
⚡️Code:
#iamintel
#oneapi
@intelai
@huggingface
1
23
177
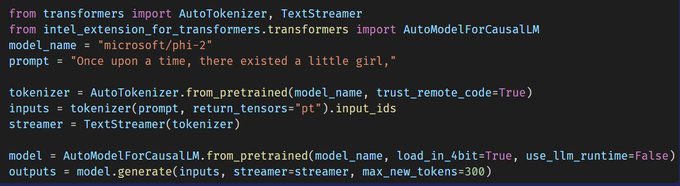
🤗Intel Extension for Transformers enables running microsoft/phi-2 smoothly on laptop (faster than human speed🚀). Sample code👇
🎯Code: . Try and have funs!
🎁DM your favorite LLM. Next will be Solar :)
#iamintel
#intelai
@intel
@huggingface
@murilocurti
4
26
176
🎯Intel Extension for Transformers (powered by Neural Speed) now supports GGUF with compatible API to Hugging Face Transformers yet blazing fast (up to 50x?) for LLM inference on AIPC (even on CPU cores)
🔥Repo: (PS: some friends called "open-source Groq")

8
42
164
🔥Excited to share a nice blog from
@andysingal
about Top-performance 7B LLM NeuralChat-v3-1 from Intel: . Check out the blog and have a try on this model! ⚡️
#IAmIntel
#intelai
@intel
@huggingface

5
25
168
📢Just created an open-source project to speed up LLMs dedicatedly
🌟Project:
🤗Look forward to your suggestions and let me know the topics that you may have interests and want to see.
#LLM
@intel
@huggingface
4
26
168
📢Continue making LLMs more accessible! Neural Compressor supports layer-wise GPTQ for INT4 quantization up to 1TB ~ 10TB (though not open-sourced yet) even on consumer HW!
📕Instruction:
🌟Project:
#oneapi
@intel
@huggingface
#LLM
1
24
165
🚀Thrilled to announce that NeuralSpeed v1.0 alpha is released! Highly optimized INT4 kernels and blazing fast LLM inference on CPUs!
🎯Integrated by ONNX Runtime; WIP: contribute to AutoAWQ
@casper_hansen_
and AutoGPTQ
📔 Blog:
🔥
6
32
159
🚀Highly-efficient x86 INT4 kernels are now available in ONNX Runtime. Use Intel Neural Compressor to quantize LLMs and run efficiently with ONNX Runtime on Intel CPUs!
📔PR:
🎯Source of INT4 kernels:
#intelai
@intelai
@huggingface
1
28
153
🎯Excited to share another NeurIPS'23 paper titled "Effective Quantization for Diffusion Models on CPUs"! Congrats to all the collaborators!
🚀Code:
📜Paper:
#iamintel
#intelai
@intel
@huggingface
@_akhaliq

1
35
151
🚀Embedding is super fast on SPR! Just ~500 seconds for 1M samples (512 seq len/sample) using Intel optimized BGE model using INC and ITREX, making RAG more accessible!
📷Quick guide:
🎯
#iamintel
#intelai
@intelai
@huggingface
0
31
146
🔥Excited to share new BGE-base-v1.5 INT8 models within <1% accuracy loss from FP32 baseline on STS dataset (previous SST2)! BGE for RAG!!
🤗Model-1:
🤗Model-2:
🚀Code:
#oneapi
@IntelSoftware
@huggingface
2
28
144
🎁Happy New Year! We released Intel Neural Compressor v2.4.1 on the last working day in 2023!
📔Release notes:
🎯Code:
🩷Thanks to everyone who has provided your support & help to INC. We are committed to make it better in 2024! 🤗
1
22
138
📽️Editing LLM knowledge is possible, e.g., Rank-One Model Editing (ROME).
📔Paper:
🎯Sample code:
💣The technology behind looks interesting and useful, which is supposed to work with SFT and RAG to reduce the hallucination!
3
26
126
🎯Quantization + Speculative decoding shows significant speedup up to 7.3x on Xeon using Intel AI SWs:
📢IPEX:
ITREX:
🤗Blog:
Congrats to
@IntelAI
and
@huggingface
team!
@MosheWasserblat
@humaabidi

2
26
128
📢Happy to share Intel Extension for Transformers v1.0 released:
🎯 NeuralChat, a custom Chatbot on domain knowledge through Hugging Face PEFT. Now, you can create your own Chatbot within 1 hours on CPUs.
@humaabidi
@MosheWasserblat
@jeffboudier
0
34
124
🎯When DeepSpeed meets Intel AI SWs, the performance magic happens!
🚀Accelerate Llama 2 inference on Xeon SPR by up to ~1.7x!
📔Blog:
🎁Intel AI SWs:
IPEX:
INC:
and
#oneapi
@intelai
@AIatMeta
@MSFTDeepSpeed
1
19
121
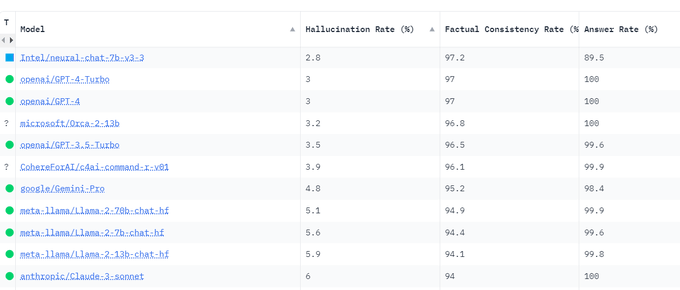
🤗NeuralChat beats GPT4 and Claude on hallucination and factual consistency rate in a new leaderboard👇 initiated by
@vectara
.
📢RL/DPO is getting so important to improve the model quality, particularly for responsible AI.
🎯Code to fine-tune NeuralChat:
5
23
123
🔥Zero accuracy loss of INT4 model, even comparing with FP16 model.
@hunkims
See the recipes published in the model card or reach us for the quantized models👇
🎯We will be releasing an improved version of low-bit quantized LLM leaderboard with new models on 6/6. Stay tuned!

3
18
123
📢Happy to share INT4 inference on
@intel
GPUs (e.g., PVC & Arc) is available in Intel Ext. for Transformers as an experimental feature (powered by IPEX)! More are coming!!
🎯Release notes:
🚀Code:
#intelai
#intelgpu
@huggingface
3
18
123
📢NeuralChat, an open chat framework created by
@intel
, now supports the
@huggingface
assisted generation to make chatbot more efficient on Intel platforms!
🎯Guide to deploy a chatbot:
🚀Code:
#iamintel
#intelai
Go, ITREX!
0
16
120
💕We love open-source and contributed Intel Neural Compressor () to ONNX community. Now it's available , as a quantization tool for ONNX models.
🎯Give a try and share us your feedbacks!
@NoWayYesWei
@humaabidi
@melisevers
@arungupta

0
25
119
🤗Neural Speed now supports GGUF (used in llama.cpp)!
📢Neural Speed is an innovation library, a sibling project with Intel Neural Compressor.
🎯Neural Compressor🔚Algorithm + Accuracy
🚀Neural Speed 🔚 Kernel + Performance
🌟
3
21
119
🔥Want Intel-enhanced llama.cpp? Yes, up to 15x on 1st token gen and 1.5x on other token gen on Intel latest Xeon Scalable Processor (SPR)
📕Blog:
Code:
#oneapi
@intel
@huggingface
@_akhaliq
@llama
@llama_index
@llama

3
29
113
🔥All your need is Intel Neural Compressor (INC) for INT4 LLMs. INC v2.5 released with SOTA INT4 LLM quantization (AutoRound) across platforms incl. Intel Gaudi2, Xeon, and GPU.
🎯Models: Llama2, Mistral, Mixtral-MOE, Gemma, Mistral-v0.2, Phi2, Qwen, ...🤗
2
17
116
🎯Embedding model is super important for RAG system. Here is a tutorial showing how to tune BAAI/bge-base for high performance.
📔
💣 Extended LangChain to load optimized embedding model and improved the inference on Intel platforms.
1
17
114
🚀Even 3rd Intel Xeon ICX can run efficiently on LLM inference! See the demo below👇
📢Demo:
📕Code:
Competitive TCO (perf/$)! More importantly, Xeon is almost everywhere!!
#oneapi
@intel
@huggingface
@_akhaliq
@MosheWasserblat
1
33
109
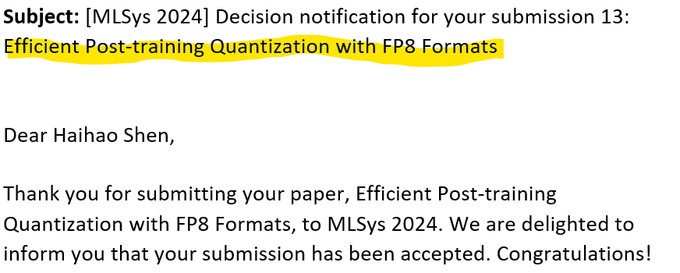
㊗️Our paper on "FP8 recipes" has been accepted by MLSys'24. Congrats to all the collaborators
@navikm
Xin, Qun, Chang, and Mengni!
🤗Paper:
🎯Code:
4
17
111
🎁Intel Neural Chat-7B: when Mistral meets new hardware (Intel Gaudi2) & new data (Intel DPO dataset)
🚀Code:
🎯Model:
📽️Super cool video from
@Sam_Witteveen
#iamintel
#intelai
@intel
@huggingface

4
19
112
📢More Intel NeuralChat-v3 7B LLMs are released, and more technical details are published in the blog👇
🎯Blog:
🙌Welcome to use
@intel
NeuralChat-v3🤗, which runs highly efficient on Intel platforms using Intel AI SWs.
#iamintel
#intelai
@huggingface

7
16
108
🎯High performance INT4 Mistral-7B model available on
@huggingface
, quantized by Intel Neural Compressor (outperforming GPTQ & AWQ) and efficiently inferenced by Intel Extension for Transformers!
🤗 Model:
🌟,
6
25
103
🔥Wanted to run GGUF models faster on Intel platforms? Here you go - all your need is Intel Extension for Transformers: with up to 7x better performance boost and 7x smaller model size! Look forward to your early feedbacks! 🎯

3
27
107
🎯Meta launched Llama3. See how it works well across Gaudi, Xeon, GPU, and AIPC! Check out the blog:
🔥Happy to share with you AutoRound in Intel Neural Compressor was used to quantize Llama3 INT4 model with the SOTA accuracy!

3
28
107
🎯Want to quantize Transformer model without coding? Yes, use Neural Coder + Optimum-Intel.
🧨5,000+ Transformer models quantized automatically
🔥Neural Coder demo on Hugging Face Spaces: .
⭐️Check it out for a try!
@ellacharlaix
@jeffboudier
@_akhaliq
1
25
101
❓Fine-tuning or RAG? Don't know how to select.
🎯Fine-tuning is not the only way to make your LLM smarter! You can also try RAG. Here are the recommendations and examples:
📢Reproducible through Intel Extension for Transformers: 🚀
4
15
101
🔥NeuralChat ranked Top-1 among 7B LLMs in Open LLM Leaderboard!
🎯Code to reproduce Top-1 model:
Congrats to Kaokao and the team! Thanks to
@NoWayYesWei
@humaabidi
for great support!
#oneapi
@intel
@huggingface
@ClementDelangue
@clefourrier
@jeffboudier
0
18
99
🎯We are hosting our personalized Stable Diffusion model with a newly-added object "dicoo" on Hugging Face Spaces: . 🤗Try it out! If you want to replicate the fine-tuning, please visit our previous blog:

3
24
96
🔥Thanks to
@intheworldofai
for publishing an amazing video to introduce NeuralChat, the most powerful 7B model crated by
@IntelAI
ranked Top-1 in
@huggingface
LLM open leaderboard!
🎯Video:
#intelai
@NoWayYesWei
@humaabidi
@KeDing
@MosheWasserblat

2
27
97
📢Slimmed BGE embedding models are coming, shortly after quantized ones. More importantly, slimming and quantization can be combined together!
🎁 Private RAG-based chatbots on clients are more accessible!
👨💻
🎯
#intelai
#NeuralChat
0
18
96
🎯Happy to announce the source code and examples of "Fast DistilBERT on CPU" (accepted by NeurIPS'22 paper) was released:
🧨Included in Top NLP Papers Nov'22 by
@CohereAI
and highlighted "Fast Transformers on CPUs with SOTA performance" by
@Synced_Global
!
0
9
93
📢"Efficient Post-training Quantization with FP8 Formats" is published! Thanks to the great collaborators!
🎯We released all the FP8 recipes in Intel Neural Compressor: . Check it out!

1
22
93
⚡️Breaking news: Open Platform for Enterprise AI (OPEA) is announced by Pat! A lots of great partners👍
🎯The base code is here: , powered by ecosystem projects such as Transformers, TGI, LangChain and the technology from Intel Extension for Transformers.

1
19
90
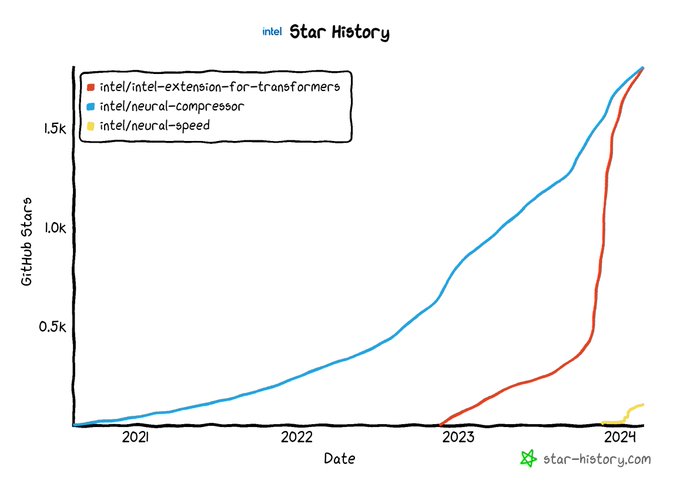
🩷A memorable day: Intel Neural Compressor and Intel Extension for Transformers crossed! A baby Neural Speed is on board!!🌟
0
6
81
💣Happy to announce INT4 NeuralChat-7B models available on
@huggingface
, powered by SOTA INT4 algorithm developed by Intel, yet compatible with AutoGPTQ!
🤗
🤗
📔Paper:
🎯Sample code:
0
15
82
📢INT4 GPTQ and RTN landed in ONNX Runtime through Intel Neural Compressor. AI on PC is coming!
📔PR: Thanks to Yuwen, Mengni, and Yufeng!
🌟Code:
#intelai
#onnxruntime
#neuralcompressor
1
15
81
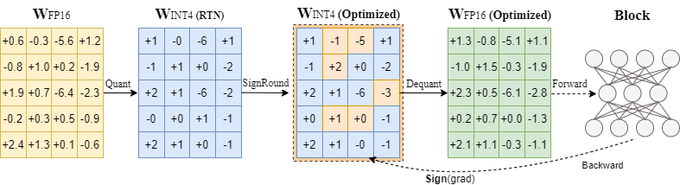
🔥Happy to publish the code of SignRound (a leading INT4 quantization method) :
📕Paper:
👉Code:
📢Leave a star if you find it's useful.
0
22
78
🎁Happy to announce Intel Extension for Transformers supports INT8 quantization for MSFT Phi, making Phi inference more efficient and accessible than ever!
📔Quick guide:
🎯Code available:
#iamintel
#intelai
@intel
@huggingface
0
14
77
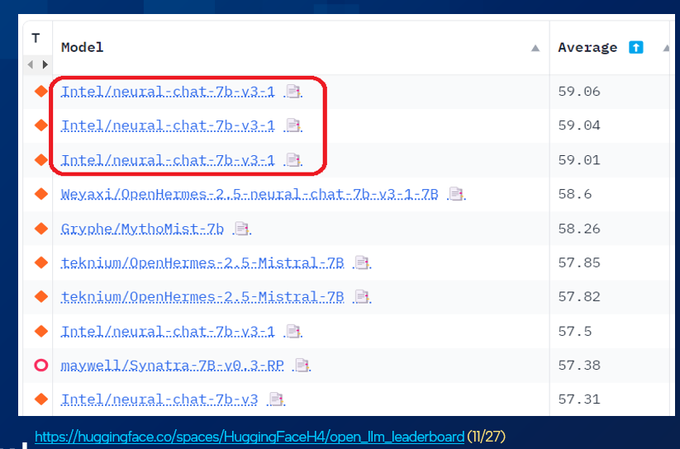
It has been a great experience to see the rapid growth of LLMs in open-source community. We are proud to see
@intelai
created LLMs & datasets are welcomed and being used/discussed/improved. Go, Intel LLMs!

Congrats to Intel team members Haihao Shen and Kaokao Lv for their fine-tuned version of Mistral 7B having hit the top of the list on the
@huggingface
LLM leaderboard last week:
Fine-tuned on 8x Intel Gaudi2 Accelerators.
2
12
119
3
14
73
🔥Want to use FP8 inference easily? Intel Neural Compressor is your best choice:
🎯Shared with you our MLSys'24 camera-ready paper: Efficient Post-Training Quantization with FP8 Formats
🤗
@_akhaliq
@navikm
@huggingface
#IAmIntel

0
18
75
📢"Efficient LLM Inference on CPUs" featured on
@Marktechpost
!
🪧
👉Project:
#oneapi
@intel
@huggingface
4
12
75
🎯Thrilled to announce INT4 LLM inference on CPUs landed in
@LangChainAI
. Thanks to
@baga_tur
and
@j_schottenstein
!
📓PR:
🤗INT4 inference powered by and
#IAmIntel
1
8
75
🎯Wanted to enable audio in your chatbot? Just few minutes.
📕Here is a guide for you, including ASR, TTS, audio processing, audio streaming, multi-lang EN & CN:
📢Optimized code: with🤗models
#iamintel
#intelai
@intel
@huggingface
1
21
74
🎯How MX data types work for LLMs? New quantization recipes validated by Intel using Neural Compressor, HW architecture and data types proposed by MSFT and defined by OCP
📢Here is a tutorial: with source code publicly available in
0
11
69
🌟Happy to announce Intel Extension for Transformers v1.4 released with a lot of improvements in building GenAI applications on Intel platforms!
🎯Check out the release notes:
🤗
@intel
+
@huggingface
= one of the best GenAI platforms

0
10
74
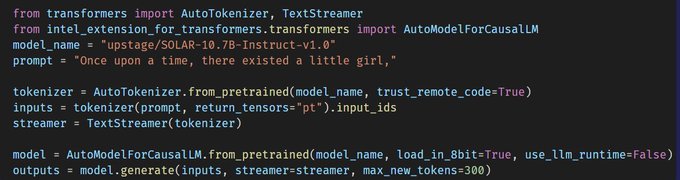
🚀Happy to support "upstage/SOLAR-10.7B-Instruct-v1.0" in Intel Extension for Transformers!
@upstageai
@hunkims
. INT4 inference is available with one parameter change from "load_in_8bit" to "load_in_4bit".
📢Next one will be Zephyr🙌
👇Check out the sample code and give a try!
0
13
72
📢Intel Extension for Transformers () supports INT4 and low-bit inference on both CPUs and GPUs!
📔Simple usage guide:
🔥All your need is to get an Intel GPU and run LLMs
@huggingface
🤗
3
11
72
📢When AI meets cybersecurity, see how Intel NeuralChat LLM helps here. Happy to share a nice blog "Harnessing the Intel NeuralChat 7B Model for Advanced Fraud Detection". Congrats
@Saminusalisu
!
🎯Check out the details:
#intelai
#iamintel
@humaabidi

1
18
71
🎁Here is a tutorial on how to optimize natural language embedding model and extend LangChain to enable the optimizations. Check out more details:
🤗Code: . Star the project if you find this is useful.
🌟Happy Chinese New Year! 🎇
0
14
67
👨💻2023 is year of open LLMs. Is it time to predict for 2024? DM your thoughts.
📢Re-share the blog from
@clefourrier
: , incl. Intel NeuralChat-7B and DPO dataset😀
🤗We hope to contribute more to open-source LLM community in 2024!
#iamintel
@huggingface

4
12
66
🔥Happy to announce Intel Extension for Transformers v1.3.2 released
📔Release notes:
🎯Highlights: enable popular serving e.g.,
@huggingface
TGI, vLLM, and Triton to build highly efficient chatbot on Intel platforms such as Gaudi2 with a few lines of code

0
9
65
🥳Happy to share with you the Intel optimizations
for Diffusers textual inversion and the fine-tuning demo of Stable Diffusion on Spaces!
👉 Intel optimizations:
🎯Spaces:
🤗Thanks to Patrick,
@anton_lozhkov
@_akhaliq
from HF!

1
21
64
🆕Thrilled to share with you that highly-efficient 4-bit kernels have been integrated into AutoAWQ. Congrats Penghui and thanks
@casper_hansen_
for the review! Now, you can run AutoAWQ super fast on CPU with PR:
🔥Base code from
1
15
64
📢Intel Copilot in CES 2024 automatically created a Chatbot for the event! Watch the video of Great Minds keynote: delivered by Intel leaders!!
🎯The copilot is built on top of . The code/ext will be released soon. Stay tuned!🚀
0
8
64
🪧LLM Leaderboard continues upgrading. Our engineering submission is currently ranking as Top-1 7B fine-tuned LLM. Remember to enable "Show gated/private/deleted models".
🤗Top-1 7B Model:
📷Code:
#oneapi
@intel
@huggingface
1
13
64
🔥Thrilled to announce OPEA v0.6 released, featuring 10 micro-service components (e.g., embedding, LLMs), 4 GenAI examples, and 1-click K8S deployment.
🎯Github: Give a try and create GenAI app with your private data!
@NoWayYesWei
@humaabidi
@melisevers

2
11
62
🤗Want to build an enterprise-grade RAG system? Efficient embedding is what you want. Here is a nice blog from Intel and
@huggingface
friends on "Intel Fast Embedding" with and
#IAmIntel
@MosheWasserblat
0
15
62
📢Exciting news! Stable Diffusion on Gaudi!! We released Intel Extension for Transformers to simplify LLM fine-tuning and accelerate LLM inference further🚀


1
12
60
🎯Qwen is the default model in INT4 inference sample code on Intel GPUs. Check the main page.
📔Sample code:
🤗
1
8
57
🔥If you want the best 4-bit models e.g., Phi-3, Mistral, Solar, Intel Neural Compressor with AutoRound is your choice!🌟

⚡️Leaderboard snapshot on 2024/5/10. INC quantized models using AutoRound () outperform the models (publicly available on HuggingFace) quantized by other popular quantization approaches such as GPTQ, AWQ, GGUF, etc. Pick up the best INT4 model for your use!

1
5
39
1
15
55
📢We are hiring full-time interns for efficient LLM inference.
🔥Group: Intel/DCAI/AISE
🎯Location: Shanghai, Zizhu
😀Working projects:
* INC:
* ITREX:
If you are interested in LLM compression and inference, DM with your resume.😀
3
11
52