

Bartłomiej Cupiał
@CupiaBart
Followers
1K
Following
736
Statuses
82
I sure do like machine learning
Warsaw, Poland
Joined May 2019
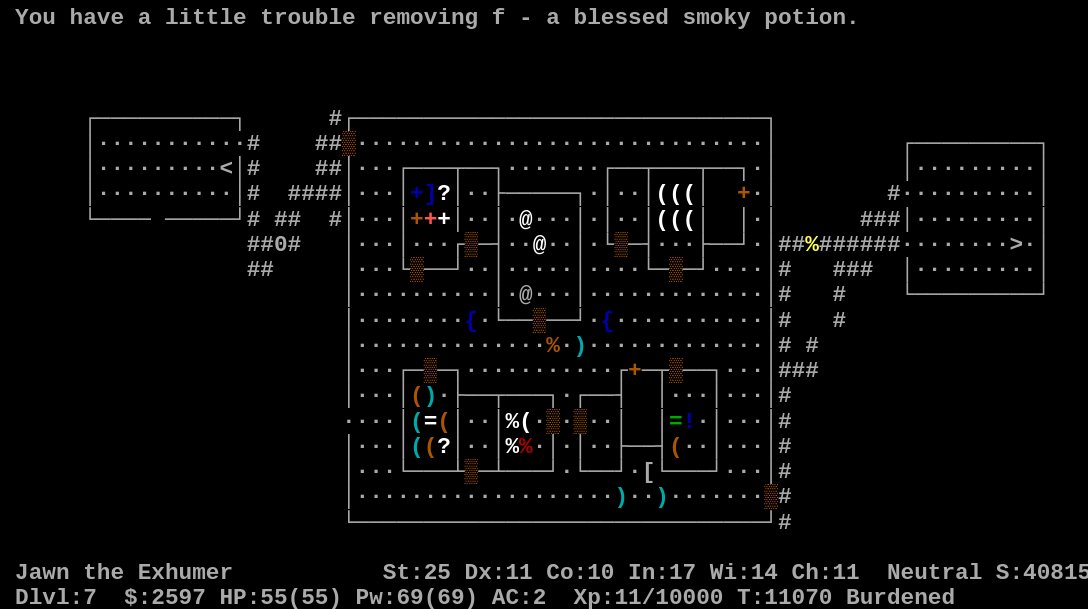
So here's a story of, by far, the weirdest bug I've encountered in my CS career. Along with @maciejwolczyk we've been training a neural network that learns how to play NetHack, an old roguelike game, that looks like in the screenshot. Recenlty, something unexpected happened.
140
1K
9K
Fascinating work from my colleagues on MoE scaling laws! 🔥 They showed you can actually get better performance with MoEs under the same memory constraints as dense models. Really cool to see how they challenged the common assumption about memory vs compute trade-offs.

(1/n) Introducing Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient We show that MoE is so compute-efficient that, under the same memory budget, it can beat a dense alternative!

0
0
15
RT @MartinKlissarov: Can AI agents adapt zero-shot, to complex multi-step language instructions in open-ended environments? We present Mae…
0
52
0
RT @aviral_kumar2: 🚨Current scalable RL algos train a policy w/o value func, which is limiting with learning in open-ended, non-stationary,…
0
51
0
BALROG, our benchmark for agentic LLM and VLM reasoning on games, has just been accepted to #ICLR! See you in Singapore 🇸🇬!

Tired of saturated benchmarks? Want scope for a significant leap in capabilities? 🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games! BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come. 1/🧵

1
4
34
RT @PaglieriDavide: 🚨BALROG leaderboard update This week's new entries on are: Llama 3.3 70B Instruct 🫤 Claude 3…
0
5
0
@danijarh The goal was to compare VLMs on the same environment with different rendering to try to disentangle the underperformance of some VLMs on BALROG Turns out it doesn't help.
1
0
3

RT @emollick: This may sound odd, but game-based benchmarks are some of the most useful for AI, since we have human scores and they require…
0
110
0
RT @_rockt: Excited to announce "BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games" led @UCL_DARK's @PaglieriDavide! @douwekie…
0
5
0
RT @ulyanapiterbarg: Led by @PaglieriDavide @CupiaBart, with @scowardai @maciejwolczyk @akbirkhan @edupignatelli @LukeKucinski @LerrelPinto…
0
1
0
Want to know if your LLMs can truly act in the real world? BALROG is your answer. Our benchmark rigorously tests planning, reasoning & decision-making in LLMs and VLMs - the skills that matter for real applications.
Tired of saturated benchmarks? Want scope for a significant leap in capabilities? 🔥 Introducing BALROG: a Benchmark for Agentic LLM and VLM Reasoning On Games! BALROG is a challenging benchmark for LLM agentic capabilities, designed to stay relevant for years to come. 1/🧵
0
5
22
RT @ulyanapiterbarg: There are infinitely many ways to write a program. In our new work, we show that training autoregressive LMs to synthe…
0
17
0
I am happy to announce that I will be presenting our paper about fine-tuning in RL at this year's MLinPL conference! 🥳

0
3
31
RT @PiotrRMilos: Excellent news from NeurIPS. Two papers in, including a spotlight. 1. Repurposing Language Models into Embedding Models:…
0
16
0
0
0
4