
Zorik Gekhman
@zorikgekhman
Followers
242
Following
325
Statuses
132
PhD student @ Technion | Research intern @Google
Joined August 2019
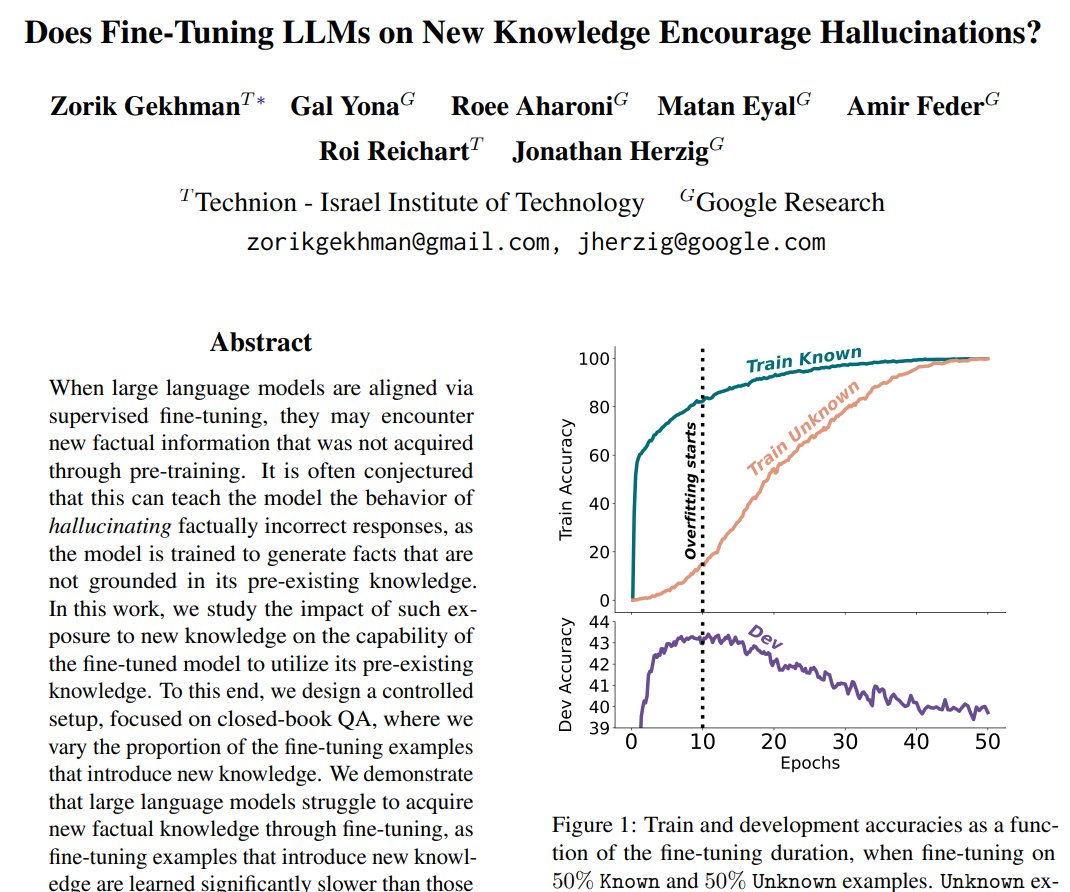
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? New preprint!📣 - LLMs struggle to integrate new factual knowledge through fine-tuning - As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫 📜 🧵1/12👇

Google presents Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? Highlights the risk in introducing new factual knowledge through fine-tuning, which leads to hallucinations
5
57
187
Our work on abductive reasoning across multiple images has been accepted to #ICLR2025! Congrats, @mor_ventura95 !

We’re excited to share that our paper, "NL-EYE: Abductive NLI for Images" has been accepted to ICLR 2025!🥳 Our benchmark reveals that VLMs struggle with abductive reasoning across multiple images (worse than random!) Think you can solve it? Check out these examples! Link⬇️
0
4
10
Our work on the intrinsic representation of hallucinations in LLMs has been accepted to #ICLR2025! Congrats, @OrgadHadas

Our work "LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations" was accepted to #ICLR2025! Looking forward to discussing our findings in person. Project page >> Code >>
0
2
21
RT @NitCal: Our paper: "On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLMs" has been accepted to NAACL…
0
25
0
Cool work by @NitCal. If you ever wonder if LLM-based labels work for your use case, now you’ve got a (simple) way to find out.

Do you use LLM-as-a-judge or LLM annotations in your research? There’s a growing trend of replacing human annotators with LLMs in research—they're fast, cheap, and require less effort. But can we trust them?🤔 Well, we need a rigorous procedure to answer this. 🚨New preprint👇

0
1
10
RT @goldshtn: Today we published FACTS Grounding, a benchmark and leaderboard for evaluating the factuality of LLMs when grounding to the i…
0
8
0
@_jasonwei Great work! I couldn’t find the QA prompt used for evaluating the models in Table 3. Was it the same for all models? If possible, could you share it? Thanks!
0
0
1
RT @YonatanBitton: 🚨 Happening NOW at #NeurIPS2024 with @nitzanguetta ! 🎭 #VisualRiddles: A Commonsense and World Knowledge Challenge for V…
0
7
0
Thank you @MilaNLProc for featuring our work!

For this week's @MilaNLProc reading group, Yujie presented "Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?" by @zorikgekhman et al. Paper: #NLProc

0
0
11
RT @roireichart: My students, collaborators and I have just published blog posts describing our work on NLP for the human sciences (pursued…
0
4
0
RT @NitCal: Do you think LLMs could win a Nobel Prize one day? 🤔 Can NLP predict heroin addiction outcomes, uncover suicide risks, or simu…
0
8
0
At #EMNLP2024? Join me in the Language Modeling 1 session tomorrow, 11:00-11:15, for a talk on how fine-tuning with new knowledge impacts hallucinations.
I'll be at #EMNLP2024 next week to give an oral presentation on our work about how fine-tuning with new knowledge affects hallucinations 😵💫 📅 Nov 12 (Tue) 11:00-12:30, Language Modeling 1 Hope to see you there. If you're interested in factuality, let’s talk!
0
5
14
And now, you can also use our implementation to probe LLMs for truthfulness in your research
Our code for "LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations" is now available! Utilize our implementation to probe the internal representations of LLMs and explore the insights found in our work. Check it out here:
0
0
1
RT @mor_ventura95: 🎉 Our paper "𝐍𝐚𝐯𝐢𝐠𝐚𝐭𝐢𝐧𝐠 𝐂𝐮𝐥𝐭𝐮𝐫𝐚𝐥 𝐂𝐡𝐚𝐬𝐦𝐬: 𝐄𝐱𝐩𝐥𝐨𝐫𝐢𝐧𝐠 𝐚𝐧𝐝 𝐔𝐧𝐥𝐨𝐜𝐤𝐢𝐧𝐠 𝐭𝐡𝐞 𝐂𝐮𝐥𝐭𝐮𝐫𝐚𝐥 𝐏𝐎𝐕 𝐨𝐟 𝐓𝐞𝐱𝐭-𝐭𝐨-𝐈𝐦𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥𝐬" is accepted t…
0
12
0
I'll be at #EMNLP2024 next week to give an oral presentation on our work about how fine-tuning with new knowledge affects hallucinations 😵💫 📅 Nov 12 (Tue) 11:00-12:30, Language Modeling 1 Hope to see you there. If you're interested in factuality, let’s talk!
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? New preprint!📣 - LLMs struggle to integrate new factual knowledge through fine-tuning - As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫 📜 🧵1/12👇
0
6
16
RT @alon_jacovi: "Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP" was accepted to EMN…
0
20
0
RT @AdiSimhi: LLMs often "hallucinate". But not all hallucinations are the same! This paper reveals two distinct types: (1) due to lack of…
0
187
0
RT @itay__nakash: Breaking ReAct Agents: Foot-in-the-Door Attack 🚪🧑💻⚠️ 🚨 New preprint! 🚨 FITD attack subtly misleads LLM agents 🧠. Our re…
0
12
0
RT @omer6nahum: 🚀 Excited to share our research: "Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Mode…
0
11
0
Repeated model sampling boosts the chance of producing the right answer, which motivates scaling the inference compute. Yet this work shows that repeated guessing achieves the same, raising questions about whether the model is "right for the right reasons" in these improvements.

Scaling inference compute by repeated sampling boosts coverage (% problems solved), but could this be due to lucky guesses, rather than correct reasoning? We show that sometimes, guessing beats repeated sampling 🎲 @_galyo @omerlevy_ @roeeaharoni

0
0
2
RT @omarsar0: LLMs Know More Than They Show We know very little about how and why LLMs "hallucinate" but it's an important topic nonethele…
0
134
0