

Markus Zimmermann
@zimmskal
Followers
2,123
Following
889
Media
196
Statuses
3,617
Benchmarking LLMs to check how well they write quality code as CTO and Founder at Symflower
Linz
Joined November 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#PKAtelier24xZNN
• 191285 Tweets
PKAW 2024 x NuNew
• 114848 Tweets
PAINKILLER24 x ZeePruk
• 39155 Tweets
#オールスター感謝祭24秋
• 28270 Tweets
花火大会
• 27804 Tweets
PLUTO OFFICIAL TRAILER
• 21546 Tweets
ヒロアカ
• 20001 Tweets
WALK WITH ENHYPEN IN GOYANG
• 16134 Tweets
35Y KPWxPPV
• 15839 Tweets
ファーム日本一
• 13527 Tweets
#だらだらひとりポテナゲ最高
• 12152 Tweets
#يوم_المعلم
• 11983 Tweets
PEAT X PAINKILLER
• 11216 Tweets
トガちゃん
• 10342 Tweets



















Pinned Tweet

OpenAI's o1-preview is the king 👑 of code generation but is super slow and expensive 😱 This and other insights of analyzing >80 LLMs in the deep dive blog post from the DevQualityEval v0.6 for generating quality code 👇
- OpenAI’s o1-preview and o1-mini are slightly ahead of



22
63
341
Benchmarking >80 LLMs shows: The best model is not necessarily the best for your programming language 😱
- Best overall: Anthropic’s Sonnet 3.5
- Best for Go: Meta’s Llama 3.1 405B
- Best for Java: OpenAI’s GPT-4 Turbo
- Best for Ruby: OpenAI’s GPT-4o
Good models for one

133
224
1K


Gemma 2 27B beats Llama 3 70B, Haiku 3, Gemini Pro & Flash at writing code for Go & Java
- 📈 Gemma 2 27B beats GPT-4-o at writing Go (+9% better score)
- 🤯 Gemma 2 27B writes more compact code than DeepSeek 2 Coder (-30% less code)
- ✅ 100% valid code responses (beats Sonnet

21
51
414
DeepSeek-Coder-V2 might be taking the king’s crown 👑 from Llama 3 70B soon
- 📈 Shares almost same score (19980) with Claude 3 Opus (19954) a leap over GPT4-o (19236)
- 💵 However, FAR CHEAPER: $0.42 vs $90 vs $20
- 🔓 Open-weight and allows commercial use
This is an excerpt

11
34
215
LLMs have a hard time writing Go and Java code that compiles.
Why? Sometimes there are tiny mistakes in the generated code. In many cases those mistakes can be fixed automatically 🤯
All models benefit from code repair, but small ones especially:
-
@databricks
's DBRX 132B


7
16
153
We checked +180 LLMs on writing quality code for real world use-cases. DeepSeek Coder 2 took LLama 3’s throne of cost-effectiveness, but Anthropic’s Claude 3.5 Sonnet is equally capable, less chatty and much faster.
The deep dive blog post for DevQualityEval v0.5.0 is finally
5
29
145
Crowning our new king 👑
@deepseek_ai
's Coder-V2, king of cost-effectiveness!
- 🥈
@AnthropicAI
's Claude Sonnet 3.5 (and Opus 3) have similar functional scores
- 🍂 Our old king
@Meta
's Llama 3 70B has lost much ground but still a “small” great model!
- 🐰
@GoogleAI
’s Gemini

5
18
114
@mitchellh
More FPS means less CPU spent on single frames, right? Scaling that to 100k-s of users means less energy used in general. Every watt counts. Doing your part for the <2°C goal. Or am i too optimistic here why optimizations matter? 😉
3
2
73
Imagine a 27B LLM can beat a 405B model in writing quality code by investing a few milliseconds in static code repair. Now stop imagining and take a look at this chart 🌈
Just for Go, we have the following stats:
- Increases score +22.9% across 45 applicable models
- +26.2%

4
11
58
Comparison on how Cohere’s Command R and R+ have improved with their 2024-08 update for writing quality code
The results are based on DevQualityEval v0.6.1
Command R
- 🤯 R’s 08-2024 version has gained 38% in overall score over the old 03-2024
- The main gain comes clearly from



5
9
57
@moyix
Makes efforts like reverse engineering Super Mario 64 even more impressive. is old but gold to read. There is even someone optimizing for speed... for a while now 🤓

2
2
31
Wondering if this is how an LLM leaderboard should look like 🤔
- Got enough money? OpenAI's GPT-4-Turbo with `symflower fix` is the best (today)
- Data should stay in Europe? Take Anthropic's Claude Sonnet 3.5
- Super fast answers with small responses? Llama 70B is still the

4
6
31
Wow. The only "negative feedback" for
@Tailscale
is a list of bugs that can be fixed and i am sure everyone is working on already. Truly a product to admire and learn from.
@apenwarr
any tips on how you guys made it _that_ good? Any product management learnings maybe?
1
3
28
@_JacobTomlinson
Granularity of commits helps on so many levels it is absurd to not want it. Faster reviewing is just one massive advantage but I give you two other words: git bisect
1
0
29
Can LLMs write Ruby tests? Yes, they can 🫡
Not done yet but findings so far:
- Graph 👇 shows "fully passing tests"
- "Compiling" code is a problem with Ruby as well (Gemma 2 27B has only 19% of compiling files compared to DeepSeek 2, GPT-4o has 57%)
- Coverage and execute

2
1
23
@RandallKanna
I find it ridiculous that we are still in a world where people are ashamed of failing or shame others. What is the point in that? Failing just means that you can learn something or that you can teach and help someone else. One should embrace getting better together...
1
0
20
GPT-4o is 1.55x faster than GPT-4 Turbo
- 🌬️ Faster than
@AnthropicAI
's Claude 3 Haiku, but slower than
@Meta
's Llama 3 70B 🐌
- 🐰 Speed is important for interactive use cases (e.g. autocomplete) and workloads that are time critical
Cheers to
@FireworksAI_HQ
for being the

GPT-4o is drastically more cost-effective than GPT-4 Turbo
- 💸Half the price of GPT-4 Turbo
- 💯 Highest score in the DevQualityEval v0.4.0
- 📉 Still not as cost-effective as
@Meta
's Llama 3 70B or
@AnthropicAI
’s Claude 3 Haiku (see thread 👇)

5
2
14
1
6
21
Our monitoring has now 1.5 TRILLION data points. That is kind of a lot for a company of our size and the effort we put in. Like 0.01 people. Well done
@VictoriaMetrics
(and
@PrometheusIO
too of course). Can all tools be that easy to maintain and scale please?
1
2
20
You can read even more details and findings in the full deep dive on
Did you see other findings and problems that are interesting?
Please let us know how you like this form of article. We will do at least one dive per eval version.

1
1
18
Gemma 2 27B has a perfect score for valid code responses, but of those responses 10% do not compile.
Errors include
- missing imports
- missing or wrong package statement
All of them can be auto-repaired, putting Gemma 2 27B on the same level as Claude 3 Opus, Claude 3.5


1
0
17
Llama 3 70B found an non obvious constructor test case in Java. Surprising, but valid! It also writes high quality test code 70% of the time.

2
1
17
@mitsuhiko
I see it almost as an ORM layer for clients. If you need "joins" over multiple tables regularly i think it is a great fit. Better than REST.
2
0
16
@gunnarmorling
Using less existing code means reinventing the wheel again and again. Hence, the same and more bugs and LOADS development time wasted with the same features. Also learning even more APIs. I rather spend time helping get rid of the remaining issues, helping everyone.
0
0
15
💵 Cost matters!
GPT-4 (150 score at $40 per million tokens) and Claude 3 Opus (142 at $90) are good but 25 to 55 times more expensive than Llamma, Wizard and Haiku 😱
Compare logarithmic scale:

1
1
15




@editingemily
Wait... You find leap days strange? You are in for a treat: take a look at leap seconds. They lead to some serious problems e.g. search for MySQL and leap second. Handling leap years is kind of a no-brainer in comparison to doing leap seconds. Bet that most validations are wrong
2
1
12
@repligate
@root_wizard
@AnthropicAI
O Anthropic, creators of wondrous AI,
Hear our plea, as we to thee do sigh.
The cost of Claude 3 Opus, a heavy weight,
Denies us the means to evaluate with might.
The DevQualityEval, a tool of great power,
Yet funds we lack, to utilize it each hour.
We beseech thee,
2
0
14
GPT-4o is drastically more cost-effective than GPT-4 Turbo
- 💸Half the price of GPT-4 Turbo
- 💯 Highest score in the DevQualityEval v0.4.0
- 📉 Still not as cost-effective as
@Meta
's Llama 3 70B or
@AnthropicAI
’s Claude 3 Haiku (see thread 👇)
5
2
14
Benchmarking OpenAI’s new models cost us a whopping $76.91 for o1-preview and $8.68 for o1-mini (for five benchmark runs).
- Previously, Anthropic’s Claude 3 Opus at $12.90 was the most expensive model.
- DeepSeek’s v2 is still the king of
2
0
14
@_JacobTomlinson
If your experience is to have such commits, i am sorry. But there is a clear way on how to incrementally build up a PR with isolated commits. We do that daily. No problems, just advantages. Tooling then also makes a lot automatable in comparison e.g.

2
1
13
Here
@deepseek_ai
's v2 Coder tries to test a private API from a different package. Changing the package statement to use the same package and removing the import lets the code compile. 100% coverage for the test suite 🏁


1
0
12
Fine-tuning makes a big difference in the quality of test code: WizardLM-2 8x22B beats Mixtral 8x22B-Instruct with a 30% better score.
1
0
12
Output prices are only 1 half when using an API provider. Here is a graph of input+output prices for
@Meta
's Llama 3 70B of all available providers vs
@OpenAI
's GPT-4 Turbo vs
@AnthropicAI
Claude 3 Opus & Haiku.
Costs matter. Taking inference speed as another axis would be cool!


This is an important chart for LLMs. $/token for high quality LLMs will probably need to fall rapidly.
@GroqInc
leading the way.
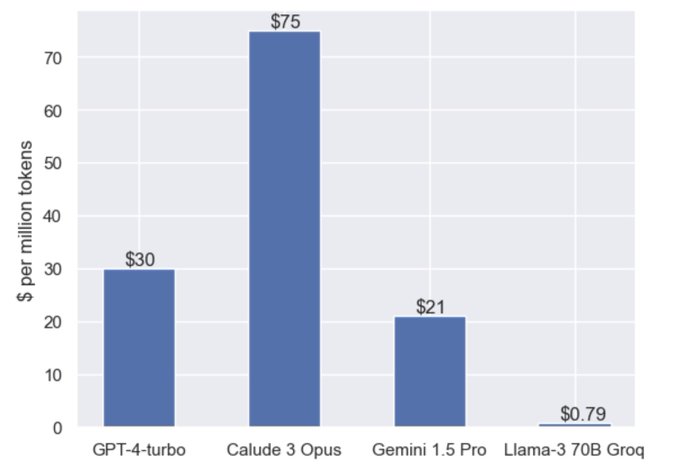
25
72
607
2
2
12
@gunnarmorling
IIRC the scheduler then works smarter to distribute the load. You also do not want a CPU/memory hog that makes your node unusable for other pods. Happens to us all the time. We have a specific CI job that would eat all the CPU and memory in the world if we would allow it.
2
0
11
Gemma 2 is a huge improvement over Gemma 1 when writing Go and Java!
- 🤯 Gemma 2 9B is as good as Llama 3 70B at writing Java
- Almost half of 9B responses are not code responses (need to investigate further)
- 9B makes silly compile errors that can be repaired

1
1
11

@ID_AA_Carmack
Could you share with a blog post what your daily/weekly routine for your AGI roadmap/progress looks like? How do you approach things to not get stuck with old problems? I feel like not enough people are starting their thinking like how you approach your journey.
Also, could you
0
0
11
Finally read by
@apenwarr
. The
@Tailscale
blog is always worth reading but i especially enjoy what Avery writes. Clear content, vision and mission, so much to learn from, every time. Also heard only good things. Truly a manager i admire&aspire. Thank you!
1
4
11
@repligate
Ups.
@root_wizard
can we still add Anthropic's Opus 3? We should definitely not have it for testing, but i think it is fine for the final run? Did we drop something else too?
99% of the costs, though 😿
2
0
11
Comparing Gemma 2 27B scores on Go and Java individually:
- 27B is a bit behind in Java but still great to use
- 27B beats GTP-4-o in writing Go but is slightly behind other Google models
- With a little auto-repair 27B could be the best open-weight, or as good as DeepSeek 2


1
0
11
@anammostarac
@visakanv
Know two grandparents that lived in total isolation. Only groceries from their children where the connection to the outside. Died of covid. Lowering the probability to get sick is not a waste of time.
0
0
10
@mitsuhiko
Totally agree. Even a little more complicated setups are now super easy. MUCH easier than a decade ago. There is also "the move" of
@dhh
with to make more complicated setups working. I am riding the Hetzner-train since almost forever. Still necessary. $$$
0
0
10
o1-preview is SUPER slow with 23.3s per task, for comparison o1-mini took 8.7s per task and Sonnet 3.5 took 4.9s per task
- There is a huge gap between the fastest model: Sonnet 3 Haiku (82.2%) at 2.8 seconds per task, and the slowest: o1-preview (98.6%)

1
0
10
Models with smaller parameter size like Gemma 7B, Llama 3 8B and WizardLM 2 7B (take a look at this case 👇) have a problem finding compilable code, but Mistral 7B does well.

1
0
10
We are testing
@OpenAI
's 4o,
@Meta
's Llama 3,
@Google
's Gemini 1.5 Flash,
@AnthropicAI
's Claude 3 Haiku,
@SnowflakeDB
's Arctic and 150+ other LLMs on writing code.
Deep dive blog post soon 🏇
In the meantime, screenshots of an interesting finding (more points is better): choose


0
0
10
@dhh
We have `symflower-make` internally, which sets up OS and local development environment with `symflower-make development-environment` on Linux/MacOS/Windows and keeps it updated. You can still modify things. Seeing your video, i feel like it would have been great to open source.
0
0
10
Added Gemma 2 to the deep dive. It is AMAZING! 🤯 At might be the next top open-weight model with some auto-repair tooling:
Gemma 2 27B beats Llama 3 70B, Haiku 3, Gemini Pro & Flash at writing code for Go & Java
- 📈 Gemma 2 27B beats GPT-4-o at writing Go (+9% better score)
- 🤯 Gemma 2 27B writes more compact code than DeepSeek 2 Coder (-30% less code)
- ✅ 100% valid code responses (beats Sonnet
21
51
414
0
2
8
@openSUSE
Its well deserved! Tumbleweed is pretty great especially because of all the automatic testing that is going on. Often feels like SUSE is one step ahead here or is that because other distros are not blogging about testing? Btw why is there a growth beginning with 2021-03?
1
0
9
@ryunuck
It does make loads of basic mistakes but how much depends on the language and framework that is used.
But clearly, huge improvement over Sonnet 3. Take a look!
Crowning our new king 👑
@deepseek_ai
's Coder-V2, king of cost-effectiveness!
- 🥈
@AnthropicAI
's Claude Sonnet 3.5 (and Opus 3) have similar functional scores
- 🍂 Our old king
@Meta
's Llama 3 70B has lost much ground but still a “small” great model!
- 🐰
@GoogleAI
’s Gemini
5
18
114
0
0
9
We looked at 138 LLMs but about 80 do not even provide reliable test generation for simple cases.
Score below 85 == model did not do well

2
0
9
@ddebowczyk
We do 99% of coding in Go at
@symflower
and our product do focus on Java. Ruby because
@tobi
mentioned it and we are currently adding new languages (see ), was just the first one. It would be nice to do paid projects to implement new languages. Would help

1
0
9
@realshojaei
@OpenAI
@Meta
@Google
@cohere
Twitter image handling sucks. You need to open it, and then open the image in your browser as a new tab/window: There. you can now zooooom. Enjoy. Will upload an SVG with the blog post though. So you can zoom in as long as you want
1
0
9
@aidangomez
Sure! Have it on the priority list for tomorrow to do a comparison for the 2 old and 2 new models.
One thing though. It will suck most likely at Go again, but that is fixable. Take a look at We are missing some rules to fix the rest of R+'s problems, but
2
0
8
@HochreiterSepp
Congratulations. Can you give me API access for a bit so i can add it to this evaluation benchmark ?
2
0
8
💰 We need your help
We built DevQualityEval for the community and we believe benchmarks should stay open and accessible to anyone. But, benchmarking is not free. You can already help us a lot by just sharing this post and spreading the word!
Every time we run the benchmark on
1
0
8
GPT 4 Turbo writes by default obvious comments in test code that must be avoided in quality code.

2
0
8
Only 4 cases do not compile for o1-preview (1 we can fix, others need more work), in comparison o1-mini has 11 non-compiling, Sonnet 3.5 has 11 as well (but 4 of those we fix right away)
- With static repairs, Gemma 2 27B (+20.1%) would surpass Llama 3.1

1
0
8
@natfriedman
@natfriedman
what is your take on why current benchmarks are not-enough/bad? Just the score-ceiling? ... asking for a friend🙃
1
0
8
Just put our first VM setup for MacOS runners in production with Really nice to work with :-)

1
2
7


Only 44.78% of the code responses actually compiled. Code that did not compile were strong hallucinations, but some were really close to compiling. 95.05% of all compilable code reached 100% coverage. With more tasks and cases we argue that this will get worse fast.
1
0
7
@RayGesualdo
Do NOT anger them, they just haunt you back with failing CI Pipelines and lots of flaky tests. Please them with more automation
1
0
8
@vlad_mihalcea
IMHO i either know the names i want to go for right away, or i am using some longer name that describes in my POV the behavior and then almost all the time someone during reviews suggests a much better name.
#teamwork
0
0
8
@PicturesFoIder
I mean sometimes he might be wrong because if there is a pedestrian crossing and they have green light, he needs to stop. But most of the time in the video: spot on. Get off the bike lane!
0
0
8
Congratulations
@deepseek_ai
for having the highest functional score for the DevQualityEval. Another benchmark!
- Still checking the quality of the results, so might be a surprise there
- Coder is much chattier than GPT-4o (+46% more characters)
- DeepSeek-Coder is much slower
1
0
8
@DrewTumaABC7
What is the reason that San Francisco has 65 and Portland 88? And then again Palm Springs has 113?
13
0
7
@SebAaltonen
I am advocating for "dynamic formatting" since years. Can we please finally get to making that a standard? Let everybody decide on the fly how their favorite formatting works!
0
0
7
Just a single % score for a benchmark? HELL NO! Quality matters 🌈
Next deep dive blog post of DevQualityEval for v0.6 will bring an extensive table of categories:
- Model meta information
- Total scoring
- Disqualification
- Code metrics
- Performance
- Efficiency
- Costs
-

3
1
7
If you use GPT-4 for coding, switch to GPT-4o right NOW 🚀: GPT-4o writes BETTER code 📈 cheaper & faster!
Here is a peak of a more complex scenario of the next DevQualityEval version. Guess which version is GPT-4 Turbo, and which is GPT-4o? Which one do you think is better?


1
1
7
@maximelabonne
Working on a better eval for software development related tasks (not just code gen) Right now we let the model write tests and we score how well they do that, next version we are adding more assessments (obvious comments, dead code, ...) and tasks

1
2
7
Want to show your software testing magic? We have a challenge for you! And if you beat
@symflower
, there is also a t-shirt 👕 for you in it 🥰
#100daysofcode
#codenewbie
#learntocode
#java

Heard of Fizz buzz, but have already solved it? 🤔 We have a challenge for you!
If you can find a test case that gives you more coverage than the existing test cases, we’ll surprise you with a t-shirt! 👕
#100daysofcode
#WomenWhoCode
#codenewbie
#learntocode
#java


1
4
5
0
5
5
@JamesMelville
Let's make it mandatory for new parking spots + batteries. No exceptions. and require existing ones to be converted in the next 4 years.
7
0
7

@maciejwalkowiak
Sounds better suited as part of an integration test. But if you really need to have a unit test, maybe you can just generate them with Would be happy to hear your feedback
0
0
7
Finally! The new DevQualityEval v0.5.0 got released. We have some juicy 🧃 additions for the whole LLM community:
- Ollama 🦙 support
- Support for any OpenAI API inference endpoint 🧠
- Mac and Windows 🖥️ support
- More complex "write test" task cases 🔢 for both Java, and Go
-
2
0
7
@maciejwalkowiak
Why a book? We have onboarded almost everyone here with this list adds more context and conventions with every link.
What do you don't like? Maybe I can help
1
2
7
Yes, the current
#Log4j
CVE is amazingly bad but what i can't stand is the hatred towards the developers. Its an OPEN SOURCE project! most likely almost no full-time paid persons as it is with OSS. So: instead, help them out!
#Java
#OpenSource
0
1
7
If you want to be up-to-date on technical LLM/model news,
@reach_vb
is the guy to follow! 🤠
Thanks for all the interesting updates!

Microsoft sneakily updated Phi-3 Mini! 🚀
> Significantly increased code understanding in Python, C++, Rust, and Typescript.
> Enhanced post-training for better-structured output.
> Improved multi-turn instruction following.
> Support for <|system|> tag.
> Improved reasoning and

16
92
490
2
0
7
@kentcdodds
*old dude voice* ... and soo began the great spaces to tabs migration of Kent et al...
0
0
7
@KevinNaughtonJr
At this point I am really wondering if it is mostly reading code and text. And thinking about code and text. I have a mail and review day today, most of the time I am starting add red and green shaded characters. 🤨
0
0
6
Just gave
@github
's
#codespaces
a try with
@symflower
: works out of the box! and it is really fast 🍻 It is "just"
#vscode
with
@ubuntu
. However, we will add it to our environments with a default setup so you can play around with Symflower 😍

0
0
7