

愚指导🐟🐠🐡🐬🦈🎣
@yudao1024
Followers
791
Following
804
Statuses
333
愚指导(Fish)🐟🐠🐡🐬🦈🎣 Web3 全栈开发,抄底爱好者。坚定的共产主义战士。兴奋地期待 AGI。 POW at @zan_team Buidling @AntDesignWeb3
Mars
Joined June 2011

兄弟们谁懂啊🤔,虽然现在个人博客渐渐没落了📉,但是还是忍不住要搭建自己的个人网站💻。重新搞了个域名 🌐公众号文章都同步过来了,有 AI 加持🤖 很多事情都快了许多⚡。支持 RSS 订阅📬,不过话说现在还有多少人还在用 RSS?
0
1
12
没有考虑不同城市的土地供需情况。 没有考虑时间成本。 没有考虑未来的现金贬值。 真正做决策的时候可不能想这么简单。

国内楼市真的没有底部。未来想买房子,不需要很急,而且房价会越来越便宜。 汽车的价格会越来越便宜。现在国内燃油车拼命降价,燃油车未来会越来越便宜。新能源车虽然现在很火,但未来的降价空间很大。 汽车今后一定是白菜价,房子汽车今后是不值钱的东西。
0
0
3
V 神也 emo 了。然而,我们没法回到过去,以太坊也必须前进!

The more I think about it, the more I think 2013-era morality is pretty much correct: * free speech good * starting companies and making good products good * monopolies bad, vendor lock-in bad * democracy good * greed bad * trying to achieve national security through oppressing people bad * cosmopolitan humanitarian values, caring about faraway people, etc good Things we've "learned" since then have been harmful more than helpful
0
0
2
大模型太卷了,而且只会更卷,今年会有越来越多好用的基础大模型出来,用户不会再去自己挑模型了,根本挑不过来。 今年会开始卷应用,会出现很多不错的 AI 应用,用户不用再关心背后的模型。 研究 AI 研究得人都要 emo 了,新的一年都不知道怎么定目标,啥也不说了,拥抱 AI 吧。
0
0
1
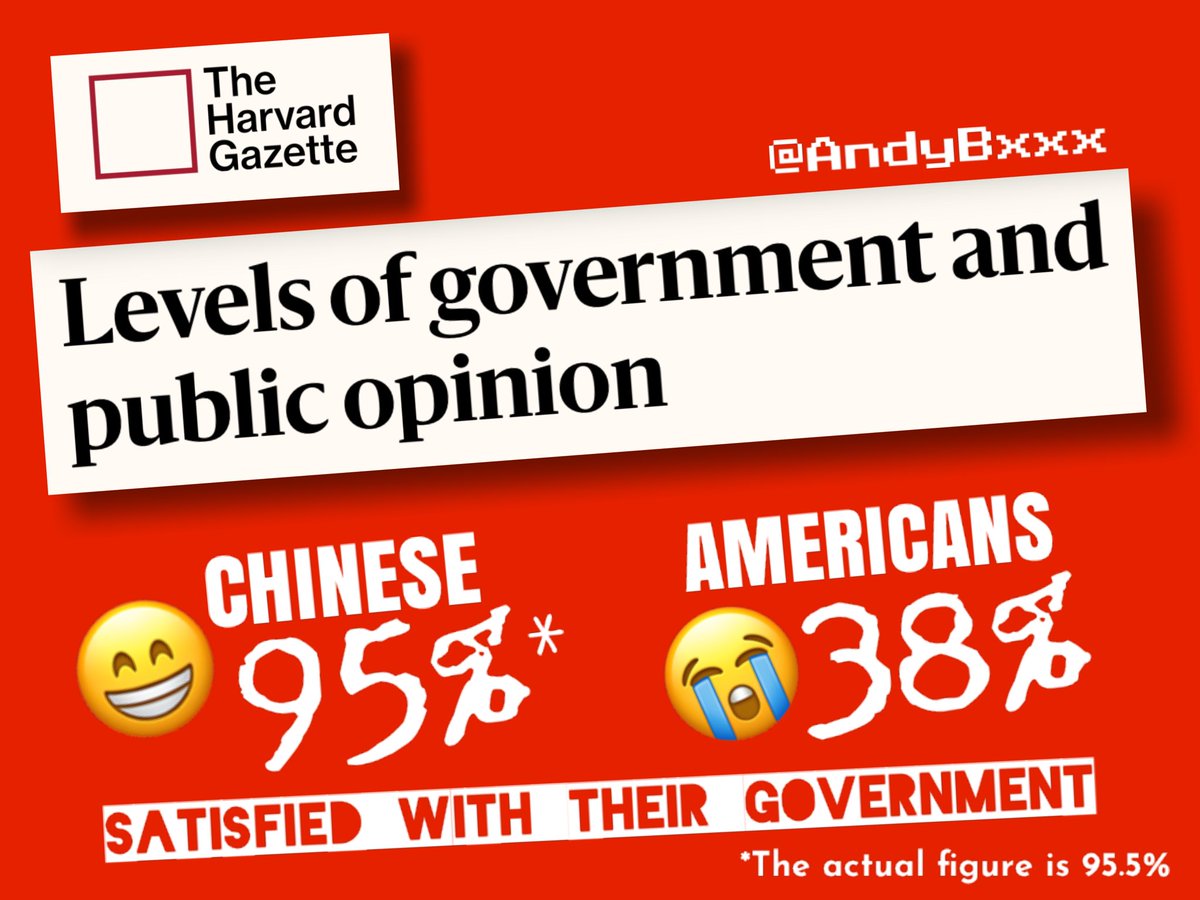
建议统计一下中国人对美国政府的满意度,尤其是简中 twitter 的中国人。满意度 200%,别的不说,就说可以投票选总统这事,那就值得了🧐

🇨🇳95.5% of Chinese people are satisfied with their gov’t. 🇺🇸Only 38% of their American counterparts are. SOURCE: Harvard University ⚠️Please save and use ⬇️
0
0
0
笑死我了

1
0
1
马斯克还是很成熟的,很懂政治,这样的人没准真能成。DOGE 改革要清算的利益团体真要慌起来了。

None of this would be possible without President @realDonaldTrump
1
0
1
在所有逛的社区中,简中 twitter 这个圈子 SB 是最多的。比如很多人看到我发的这条推,会觉得我就是个 SB,当然,我觉得他也是。
2
0
1
川普:你在给我提建议?
The risk of politician coins comes from the fact that they are such a perfect bribery vehicle. If a politician issues a coin, you do not even need to send *them* any coins to give them money. Instead, you just buy and hold the coin, and this increases the value of their holdings passively. Furthermore, there is deniability: holding the coin is, in terms of financial effect, a linear combination of donating to the issuer and gambling. Hence you can have the intention of doing the former but when challenged claim that you are doing the latter. You can even hold the coin privately, and show that you are holding it to whoever you need to show; you do not need any zero knowledge proofs, you just send a test transaction. This is all risky to democracy, for reasons very similar to what I wrote in , and elsewhere. TLDR: the economic arguments for why markets are so great for "regular" goods and services do not extend to "markets for political influence". I recommend politicians do not go down this path.
0
0
0
DeepSeek 牛

We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive - truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely. DeepSeek-R1 not only open-sources a barrage of models but also spills all the training secrets. They are perhaps the first OSS project that shows major, sustained growth of an RL flywheel. Impact can be done by "ASI achieved internally" or mythical names like "Project Strawberry". Impact can also be done by simply dumping the raw algorithms and matplotlib learning curves. I'm reading the paper: > Purely driven by RL, no SFT at all ("cold start"). Reminiscent of AlphaZero - master Go, Shogi, and Chess from scratch, without imitating human grandmaster moves first. This is the most significant takeaway from the paper. > Use groundtruth rewards computed by hardcoded rules. Avoid any learned reward models that RL can easily hack against. > Thinking time of the model steadily increases as training proceeds - this is not pre-programmed, but an emergent property! > Emergence of self-reflection and exploration behaviors. > GRPO instead of PPO: it removes the critic net from PPO and uses the average reward of multiple samples instead. Simple method to reduce memory use. Note that GRPO was also invented by DeepSeek in Feb 2024 ... what a cracked team.

0
0
0
RT @deepseek_ai: 🚀 DeepSeek-R1 is here! ⚡ Performance on par with OpenAI-o1 📖 Fully open-source model & technical report 🏆 MIT licensed: D…
0
8K
0