

Yakup Buğrahan Sevdi
@ybsvd
Followers
1K
Following
12K
Statuses
327
Yumruklarımı sıktım ve gece gündüz çabaladım. Öyle bir takıntım oldu ki başarı, hayatımı bile yaşamadım.
3
12
194
Belki de ilk defa doğru yerde konumlandık, ne dersiniz?

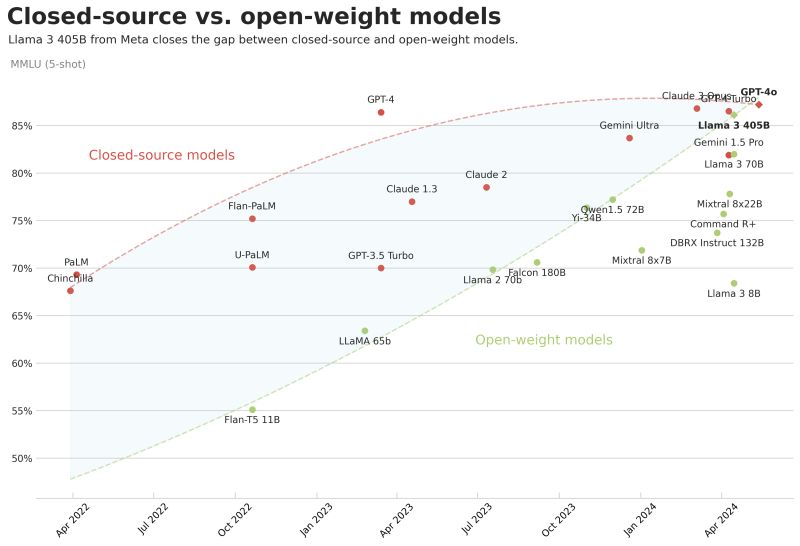
Artık çevremdeki herkese saçma yatırımlar yerine acilen güçlü bilgisayarlar almaları gerektiğini söylüyorum. Gelin bunun nedenini en ince ayrıntısına kadar anlatayım. Öncelikle sizi 2015'de yayınlanan bir blog gönderisine götürmek istiyorum. Henüz OpenAI ortada yokken Tim Urban çıktı The AI Revolution: The Road to Superintelligence diye bir blog gönderisi yayınladı. Burada anlattığı şey, grafikten de basitçe anlayacağınız üzere yapay zeka ile insanlık gelişiminin en büyük sıçrama noktasına geldiğimizin artık kaçınılmaz şekilde görünebildiği fikriydi. Bu blog gönderisini daha sonra uzun uzun anlatırım ancak şimdilik çok detaya girmeyeceğim, sadece büyük bir kırılmanın eşiğinde olduğumuzun tescilli olduğunu şimdilik hatırlasak yeter. Size açık kaynaklı modelleri nasıl çalıştıracağınızdan tutun teknik yeterliliklere ve çiplere kadar bilmeniz gereken her şeyi anlatayağım ama önce açık kaynağın önemini anlamamız gerekiyor. Lütfen şu grafiğe çok iyi bakın. Bu grafik, açık kaynaklı modeller ile kapalı kaynaklı (ChatGPT, Claude etc.) arasındaki gelişim farkını gösteriyor. Önce özel sermaye fonları ile kapalı güçlü modeller geliştiriliyor. Geliştirmek için de devasa eğitim verisine ihtiyacımız var. Bu nedenle OpenAI veya Google gibi bütçeli firmalar çok büyük avantaja sahip gibi görünüyor. Ama aslında iş o kadar da basit değil. Bunu da yeni anlıyoruz zaten. Anlıyoruz derken, yapay zeka topluluğu olarak. Görünüşe göre, bir yapay zeka modeli eğitebilmek için internetten tonla veri çekmemize gerek yokmuş, meğer bu verilerle eğitilmiş bir yapay zeka modelinin yanıtlarını kullandığımızda bile bu gelişmişlikte bir modelin veri setine sahip oluyormuşuz. İşte bu olay ortaya çıktığı anda da tonla yapay zeka geliştiricisi şirket doldu etraf. Deepseek de bunlardan birisi. Tonla ambargoya sahip ve yapay zekanın can damarı olan çiplere rahat rahat erişememesine rağmen tüm benchmarklarda OpenAI'ın geçtiğimiz aylarda çıkardığı ve çok pahalıdan sunduğu O1 ile eşdeğer performansa sahip bir model çıkarabiliyor. Deepseek R1. Closed source yapay zeka modellerinin neden bu şartlarda bu stratejilerle ilerleyemeyeceğini anladık bu mantıkla düşününce. Şimdi, gelelim zurnanın zort dediği yere. Rekabetin bu denli kızıştığı ve diğer küçük rakiplerin sizin modellerinizi veri kaynağı olarak kullanabildiği ortamda, siz büyük bir şirket olarak ya erişim kısıtlaması yaparsınız, ya büyük bloklamalar ve engeller koyarsınız, ya da bu teknolojiyi sadece çok büyük şirketlere veya devletlere verirsiniz. Çünkü malum, O1 bile 157 IQ'ya sahip. Yarın AGI geldiğinde adam neden tersine mühendislik yapılacak modeli açık açık sağa sola versin 20 dolara veya 200 dolara veya 2000 dolara? Kısacası, kapalı kaynaklı modellere her zaman erişebileceğimizin bir garantisi yok. Ve yine kısacası, açık kaynaklı modeller bu denklemde kapalı kaynak şirketlerini zugzwang pozisyonda bıraktılar ve deliler gibi gelişebiliyorlar. Bu senaryoyu düşündüğümüzde tweetin başında dediğim lafa geri dönüyoruz, saçma yatırımlar yerine acilen güçlü bilgisayarlar almamız gerekiyor. Bir yapay zeka modelini kendi bilgisayarımızda kimseye muhtaç kalmadan çalıştırabilmek için güçlü bir RAM miktarına ihtiyaç duyuyoruz. Okey hocam güzel, anladık bunları, sen bize hangi modeli çalıştıracağımızı nasıl hesaplıcaz, hangi bilgisayarı alacağımızı, hangi ekran kartına ihtiyacımız olduğunu nasıl anlayacağımızı anlat diyorsanız, hadi geçelim. Şimdi bu modelleri kendi bilgisayarımızda çalıştırırken dikkat etmemiz gereken iki olay var, birincisi RAM miktarı, ikincisi bant genişliği. RAM miktarı malum işlem gücü, bant genişliği ise çipin saniyede ne kadar veri alıp göndereceğini temsil ediyor. Bant genişliği RAM miktarından daha önemli çünkü yapay zeka modelleri transistör dediğimiz temel bileşenler üzerinde çalışıyor ve bu transistörler saniyede milyarlarca işlem yaparken veriyi olabildiğince hızlı alıp işlemek zorunda. Eğer bant genişliğiniz düşükse, sisteminiz modelin hesaplamalarını destekleyemez ve bu da performansı öldürür. RAM konusu GPU kadar kritik değil gibi görünse de aslında bir bottleneck yaratabilir. Çalıştıracağınız modelin boyutu RAM ihtiyacını belirler. Örneğin, 8B (8 milyar parametre) boyutunda bir model için 16 GB RAM işinizi görürken, 13B veya 30B boyutundaki bir model için 32 GB RAM gibi bir kapasiteye ihtiyaç duyabilirsiniz. Eğer 64 GB veya daha fazlasına çıkabiliyorsanız, bu sadece mevcut değil, gelecekteki modeller için de sizi garanti altına alır. Ben de sırf bu nedenle M2 Max 64 GB kullanıyorum. Hem max çiplerin verdiği yüksek okuma/yazma genişliği, hem de apple metal'in yapay zeka modelleri için yüksek uyum göstermesi benim için en pratik çözüm oldu. Sistem detaylarına daha fazla girmeden önce windows kullancısı arkadaşlar için de kişisel kullanım donanım önerisinde bulunayım kısaca. Bugün yapay zeka modellerini çalıştırmak için olmazsa olmaz iki şey var, yüksek VRAM kapasitesine sahip bir ekran kartı ve bunu destekleyecek şekilde yapılandırılmış bir işlemci. DeepSeek R1 gibi "büyük" dil modelleri, genellikle 16 GB VRAM’in üzerinde bir ekran kartına ihtiyaç duyuyor. RTX 4090 gibi modern bir kartla bu işi kusursuz bir şekilde halledebilirsiniz, ancak daha düşük bütçeli seçenekler için RTX 3060 (12 GB) bile başlangıç seviyesinde işinizi görebilir. Evet, şimdi işin biraz daha teknik ama çok kullanışlı bir kısmına gelelim: Hangi modelin bilgisayarınızda çalışacağını nasıl hesaplayabilirsiniz? Bu hesaplama, bir modelin boyutunu (örneğin, 7B, 13B, 30B gibi), kullanılan quantization (kuantizasyon) seviyesini ve ekran kartınızın VRAM kapasitesini temel alıyor. Hepsi bu kadar zaten, başka bileşen yok. Hadi kafalarda netleşmesi için bu formülü parçalayıp herkesin kolayca anlayabileceği bir şekilde açıklayalım: VRAM Hesaplama Formülü: (Model Boyutu * Quant Boyutu / 8) * 1.2 = İhtiyacınız Olan VRAM (GB) Model Boyutu: Bu, modelin toplam parametre sayısını ifade eder. Örneğin, 7B = 7 milyar parametre, 13B = 13 milyar parametre. Quant Boyutu: Bu, modelin bellekte kapladığı alanı küçültmek için kullanılan bir teknik. En yaygın kullanılan kuantizasyon seviyeleri şunlar: FP16 (Floating Point 16-bit): En yüksek doğruluk ama aynı zamanda en fazla VRAM tüketimi. Q8 (Quantized 8-bit): Orta seviye doğruluk ve daha az VRAM ihtiyacı. Q4 (Quantized 4-bit): Çok daha az VRAM tüketir, kayıp azdır. Ben Q4 çalıştırmayı tercih ediyorum genelde. Diyelim ki bilgisayarınızda 8 GB VRAM’li bir ekran kartınız var ve 8B boyutundaki bir modeli Q4 formatında çalıştırmak istiyorsunuz. Hesaplama şu şekilde olurdu: Model Boyutu: 8B → 8 milyar parametre. Quant Boyutu: Q4 (4 bit). (8×4/8)×1.2=4.8 GB VRAM(8×4/8)×1.2=4.8GB VRAM Bu durumda, bu modeli çalıştırmak için gereken VRAM miktarı 4.8 GB. Yani 8 GB VRAM’li ekran kartınızla bu modeli rahatça çalıştırabilirsiniz. Bu arada bu işler için yeni bir cihaz alacaksanız bilmeniz gereken bir iki nokta daha var. NVIDIA ekran kartı alıyorsanız, sadece bant genişliğinin en azından 1000GB/s olduğuna emin olsanız yeterli. RAM hesabını anlattım zaten. Ancak Apple alıyorsanız, dikkat etmeniz gereken bir nokta var. Apple metal, her ne kadar birleşik bellek mimarisi sayesinde CPU ve GPU'nun aynı bellek havuzunu paylaşmasına olanak tanıyor olsa da, bu yapı aynı zamadna sahip olduğu RAM'i olduğu gibi VRAM'e aktarmasının da önüne geçiyor. Örnek olarak 32GB RAM'li bir M2 Max macbook'unuz varsa, VRAM'e aktarımda yaklaşık %10luk bir kayıp yaşıyorsunuz. Buna dikkat edin, ek olarak da Max çipli cihazlar seçmeye odaklanın, genişlik 800GB/s olduğu için gayet yeterli oluyor, Air veya normal çiplerde bu oran 400GB/s 'in altına iniyor ki bu da bizim token yazdırma hızımızı mahvediyor. Son olarak şu t/s olayını da anlatayım. Modelleri çalıştırdıktan sonra performansını değerlendirirken, "t/s" oranı (saniye başına üretilen token sayısı) en önemli metrik oluyor. Bu metrik, modelin ne kadar hızlı yanıt üretebildiğini gösteriyor ve donanımınızın işlem gücü, bellek bant genişliği ve modelin boyutu gibi faktörlerden etkileniyor. 15 t/s üzerinde çalıştırabildiğimiz sürece modellerden insan okuma hızı ve üzerinde çıktı alıyoruz. Sonuç olarak, yapay zeka modellerini kendi donanımınızda verimli bir şekilde çalıştırmak istiyorsanız, yüksek VRAM kapasitesine sahip ve yeterli genişliğe sahip bir sisteme sahip olmanız gerekiyor. Şunu rahatlıkla diyebilirim ki bu yatırım, gelecekteki gelişmeler ne olursa olsun kendi yapay zeka modelimize kimseye bağlı olmadan sahip olabilmemizi sağlıyor. Yol yakınken ben uyarıyorum, yarın neler olacağının asla belli olmadığı bu alanda birden OpenAI gibi büyük modellere erişimimiz kısıtlanırsa (çin'e olduğu gibi) hazırlıklı olmuş oluruz. Unuttum, Anthropic olayına da kısaca değineyim. Geliştiricinin teki geçen çıktı Deepseek R1'in thinking kısmını alıp Claude 3.5 sonnet'e bağladı. Kısacası O1 gibi düşünüyor, ardından o düşünme sürecini sonnet'e veriyor ve sonnet yorumlayıp yanıt veriyor. Arkadaşlar, sonuçlar çılgın gibi. Zaten biliyorsunuz Claude'un thinking olmayan modelleri emsal OpenAI modellerinden fersah fersah iyi yanıt veriyor, benchmarklara yansıma da insan tecrübesi bu yönde en azından. Deepseek'i özel yapan da bu olay işte. Gidip bu thinking aşamasını alıp her modele bağlayabiliyoruz. 3B'lik Llama'ya da bunu bağlıyoruz, devasa 3.5 sonnet'e de. Deepseek'in önemi bu yani. Birden hayatımıza girdi ve bugüne kadar geliştirilmiş tüm yapay zeka modellerine OpenAI'ın O1 stilindeki thinking yöntemini hediye etti. Hype sebebi bu. Sorularınız olursa müsait anımda mentlerde yanıtlarım, kalın sağlıcakla.

0
0
0
RT @ucoklardan: Bir bakmışsın Yusuf kuyuda zordadır. Bir bakmışssın Yusuf, Mısır’a sultandır. #ÜmitÖzdağYalnızDeğildir
0
745
0
RT @elcin1283: %2.5 Oy, üç kuruş bütce ve 2 mitingle krndini yakma pahasına apo sürecinizi s*kip attı ya bunun acısı bin yıl yeter.! Ümit…
0
1K
0

RT @AvAykutBayrakci: Avukat babanın ninnisi de ancak böyle olur dedirten sempatik bir videoya denk geldim. Bebişin söylediği ilk kelime inf…
0
109
0
RT @salcareyiz: Tüm hafta arda turan’ın üstüne oynadık yanlışlıkla galatasaray’dan puan aldı ndndsndnsndnsbxb
0
729
0