

Xintao Wang
@xintao_w
Followers
162
Following
219
Statuses
74
💫3-year PhD student at Fudan University, Shanghai ✨NLP Researcher | Amateur Cosplayer ⭐️Personal Page: https://t.co/CD1cLJDP8h
Joined September 2022
🔔Our survey paper on LLM Persona & Role-Playing has recently been accepted to TMLR! 📖From Persona to Personalization: A survey on Role-Playing Language Agents 📷 [1/4]
6
18
86
Fun fact: This entire thread was created using Cursor + Claude! 🎯
0
0
1
Best part? You can instantly convert your content to: • Academic papers • Blog posts • Social media posts • Any format you need! Perfect for content repurposing ✨ (4/4)
0
0
2
Important note on Cursor chat: Reference files only work in the round you add them! Either: • Re-add files in new rounds • Or modify the same round's prompt (3/4)
0
0
1
The workflow is simple: 1️⃣ Feed reference texts to Claude 2️⃣ Share your draft/outline 3️⃣ Iterate together to improve 4️⃣ Generate final content Claude's suggestions are surprisingly insightful! 🤯 (2/4)


0
0
0
Let me explain how this works: First, create a folder in Cursor and prepare: 1️⃣ Your reference writings/papers 2️⃣ Outline or draft of your new content Tip: Keep all reference docs organized in one place! 📂 (1/4)
0
0
2
Great work! Are LLMs retrieving or reasoning? This question has haunted me in so many tasks. Found some answers in this paper!
1
3
13
Interesting work!

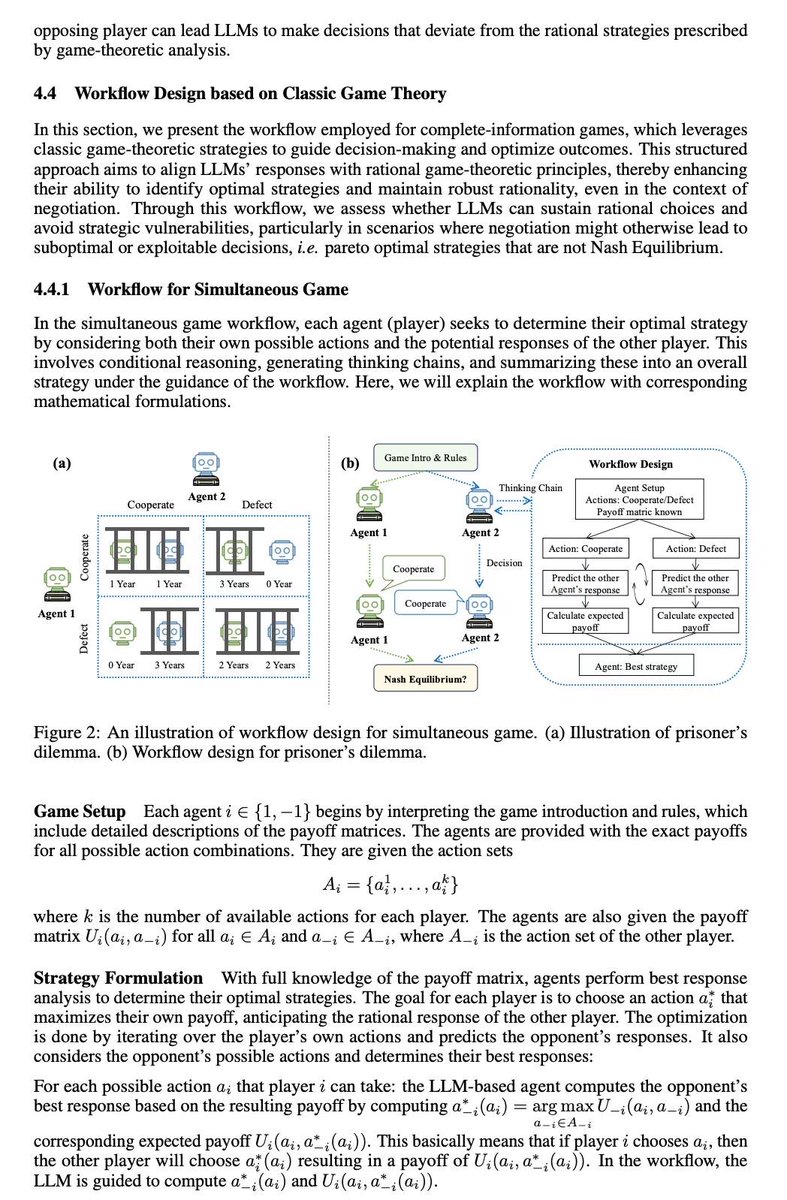
🌟🎲🎲How to create a rational LLM-based agent? using game-theoretic workflow! Game-theoretic LLM: Agent Workflow for Negotiation Games 😊 paper link: github link: 😼 This paper aims at observing and enhancing the performance of agents in interactions guided by self-interest maximization 😼 😼 We chose game theory as the foundation, with rationality and Pareto optimality as the two basic evaluation metrics: whether an individual is rational and whether a globally optimal solution is developed based on individual rationality. ❣️ Complete information games They are classic games such as Prisoner's Dilemma. We selected 5 simultaneous games and 5 sequential games. We found that, except for o1, other LLM generally lack a robust ability to compute Nash equilibria, meaning they are not very rational. They are not robust to noise, perturbations, or random talks among them. Therefore, based on classical game theory methods (Iterative Elimination of Dominated Strategy & Backward Induction), we designed two workflows to guide large models step-by-step in computing Nash equilibria during inference time. ❣️ Incomplete information games We used the classic "Deal or No Deal" resource allocation game with private valuation, where agents do not know the opponent's valuation of resources. Game theory does not provide a solution for this, and previous work has been based on reinforcement learning. 👉 Sonnet and o1 perform better than humans in terms of negotiation success rate and results 👉 Opus and 4o are far behind. 👉 We designed an algorithmic workflow based on the rational actor assumption, allowing agents to infer the opponent's valuation based on their reactions to various resource allocation schemes. The workflow is very effective, reducing the possible estimated valuations from an initial 1000 possibilities to 2-3 within 5 rounds of dialogue, and always including the opponent's true valuation. 🌟🌟Based on the estimated valuation of opponent's resource, we guide the agents in each step to calculate and propose an allocation proposal that maximizes their own interests while having a non-zero probability of being envy-free, ensuring that both parties are relatively satisfied and the negotiation can proceed. 🌟🌟 But very interestingly, we found that if only one agent uses this workflow during negotiation, it will be exploited. Although the workflow improves the overall negotiation outcome and brings more benefits to the individual agent, the benefits will always be less than the opponent's. 🔥In the future, we will need a meta-strategy to choose which workflows to use!



0
2
4
1
0
0
RT @wangchunshu: super excited to share our recent work on multi-agent framework on data science
0
1
0
RT @ZenMoore1: Introducing PopAlign: Diversifying Contrasting Patterns for a More Comprehensive Alignment. arxiv:
0
5
0
@Promptmethus The AI companies should provide more specialized service on it. However, Companies with good role-playing LLMs (e.g. Minimax) prefer providing simple and general services, for their cost-effectiveness.
0
0
1
@Promptmethus Your dedication to nurturing digital life is impressive! I think this is an important form of future human-AI interaction.
0
0
1
@Promptmethus Interesting! By definition we think this should be categorized still as individualized persona. However, it's technically more autonomous and self-evolving, which is an existing feature. We expect more development in this kind of agents!
1
0
1
We provide an analysis of the existing benchmarks/datasets for RPLAs, including details such as their statistics, data sources, and the construction methodologies. [4/4]

0
0
1
We present a comprehensive overview of current methodologies for RPLAs, followed by the details for each persona type, covering data sourcing, agent construction and evaluation. Afterward, we discuss the fundamental risks, existing limitations and future prospects of RPLAs. [3/4]

0
0
1
We categorize personas into three types: 1) Demographic Persona, which leverages statistical stereotypes; 2) Character Persona, focused on well-established figures; 3) Individualized Persona, customized through ongoing user interactions for personalized services. [2/4]

0
0
1