
Tianqi Chen
@tqchenml
Followers
15,933
Following
992
Media
49
Statuses
1,210
AssistProf @mldcmu and @CSDatCMU . Chief Technologist @OctoML . Creator of @XGBoostProject , @ApacheMXNet , @ApacheTVM . Member , @TheASF .
CMU
Joined May 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Bolivia
• 1117779 Tweets
Venezuela
• 299702 Tweets
Lakers
• 82393 Tweets
Corinthians
• 68229 Tweets
Jamaica
• 57853 Tweets
#虎に翼
• 53802 Tweets
#CopaAmerica2024
• 52652 Tweets
Baco
• 51330 Tweets
Spurs
• 49075 Tweets
#NBADraft
• 43758 Tweets
Santi
• 37746 Tweets
Abel
• 36631 Tweets
Edey
• 34191 Tweets
Juventude
• 32510 Tweets
#AEWDynamite
• 32033 Tweets
Dalton Knecht
• 30340 Tweets
Wesley
• 30030 Tweets
Hawks
• 29789 Tweets
Bahia
• 29185 Tweets
Bronny
• 24515 Tweets
Rob Dillingham
• 23386 Tweets
Rossi
• 22368 Tweets
Reed Sheppard
• 22170 Tweets
Fortaleza
• 21800 Tweets
Sixers
• 19712 Tweets
Memphis
• 19598 Tweets
Clingan
• 19546 Tweets
梅子さん
• 17195 Tweets
Rondón
• 16077 Tweets
Rony
• 14128 Tweets
Wemby
• 13531 Tweets
Grizzlies
• 13078 Tweets
Pistons
• 12312 Tweets
Ayrton Lucas
• 11727 Tweets
Cuiabá
• 11313 Tweets
Victor Hugo
• 10899 Tweets
Jared McCain
• 10263 Tweets




















Pinned Tweet

Exciting to share we have been working on over the past one year. MLCEngine, a universal LLM deployment engine that brings the power of server optimizations and local deploymet into a single framework, checkout platforms support 👇 and blogpost more in a🧵

4
51
222
Running LLM-based chat locally on iphone 📱with GPU acceleration. Also brings universal deployment to NV/AMD/M1 GPUs. Love to see it enabling personal assistants for everyone. Try out demos

Can LLMs run natively on your iPhone📱? Our answer is yes, and we can do more!
We are introducing MLC-LLM, an open framework that brings language models (LLMs) directly into a broad class of platforms (CUDA, Vulkan, Metal) with GPU acceleration!
Demo:

33
180
716
9
89
323



A summer endeavor, developing MLC: the first open lecture series on ML compilation. Machine learning compilation is an emerging field for systematic optimization and deployment of AI workloads. Hope to share adventures and fun with the community 🚀
7
59
258
Compile your deep learning models directly into WebGL and deploy to browsers without having to write a single line of javascript!
5
104
250
Today LLMs require extensive computation and memory to run and usually run on servers. What will be the future of consumer devices in the era of AI? While it is hard to predict the future, let us talk about possible opportunities and how we can enable them

1
63
223
Autodiff is the backbone of DL frameworks. In Lecture 4 of open DLSysCourse, we derive auto-diff from scratch and bring it further under the context of architecture considerations in frameworks such as
@PyTorch
and
@TensorFlow
. Checkout to learn more

2
47
221

We can now use AI to automatically optimize tensor operator kernels and compile AI workloads, enabling deployment to all hardware with state-of-art perf. This is an exciting test bed for new ideas in BayesianOpt, RL, GraphNN, transfer learning etc.

2
72
197
@zicokolter
and I are releasing a free online deep learning systems course. We will a minimum PyTorch-like framework from scratch, and build various end-to-end deep learning models using the framework. Check it out if you are interested in a “full stack” view AI systems

Announcement: This Fall
@tqchenml
and I are releasing a free online version of our Deep Learning Systems course! Short description is you build a deep learning framework from the ground up.
Sign up at course website:
Video teaser:
13
122
627
2
31
196
I spend the Monday morning reflecting on research process. And come up with the following picture. While the impact is what we go for, most joyful and sometimes grinding moments come before that. Surfing and enjoy the uncertainty period is one of the best part.

6
19
196
The future of machine learning system architecture should change from uni-directional pipelines to circles. Checkout our latest blogpost to learn about our lessons and vision about ML software & hardware ecosystem, with
@samps
@roeschinc

3
45
197
We are facing a hardware shortage for AI, and the key reason is software. Let us bring high-performance, universal deployment of open LLMs. 👉 Running
#Llama2
on AMD 7900 XTX GPU with 80% perf of RTX 4090. Checkout the python package and get superb perf on both CUDA and ROCm.
Making
@AMD
@amdradeon
GPUs competitive for LLM inference!
130 toks/s of Llama 2 7B, 75 toks/s for 13B with ROCm 5.6 + 7900 XTX + 4 bit quantization
80% performance of Nvidia RTX 4090
See how we do this in detail and try out our Python packages here:

9
40
186
3
37
197
Browsers have the potential to become the next main LLM OS to empower web agents. We are excited to announce WebLLM engine, a fast, private (full client-side computation) and convenient (zero environment setup) in-browser LLM inference engine to enable that. WebLLM offers

Excited to share WebLLM engine: a high-performance in-browser LLM inference engine!
WebLLM offers local GPU acceleration via
@WebGPU
, fully OpenAI-compatible API, and built-in web workers support to separate backend executions.
Check out the blog post:
10
94
399
4
31
193
Making LLM more accessible on cheap devices. Running 3B LLM(RedPajama-3B) at 5 tok/sec and
#llama2
7B at 2.5 tok/sec on a $100 Orange Pi single board computer accelerated by Mali GPU 👉

While LLM is resource hungry and challenging to run at satisfactory speed on small devices, we show that ML compilation (MLC) techniques makes it possible to actually generate tokens at 5 tok/sec on a $100 Orange Pi with a Mali GPU.

11
48
234
2
23
183
I am always curious how to write mobile gpu code to make my phones run AI applications fast. SJTU undergrad Lianmin Zheng just write a blog about it
6
49
172

0
76
170
Designing DL accelerator is more than designing hardware itself, it is about hardware, driver, compiler, and model working together. The new open source deep learning accelerator stack VTA provide a first open step toward that direction

3
65
159
The desire toward "novelty" in writing papers often leads to overly complex methods, while simple existing solution might just work as well and should have been reported
3
20
142
thanks to yuwei hu, NNVM compiler now deploys keras models directly to the hardware backends
2
50
136
Exciting to share our incoming
#MLsys
paper -- Cortex: A Compiler for Recursive Deep Learning Models This is a part of our recent CMU catalyst group effort with
@JiaZhihao
@atalwalkar
and others amazing folks
2
26
131
If you want to learn more about the latest advances in AI and systems, such as systems for diffusion models, multi-LoRA serving, MOE, efficient quantization and systems, and more AI and systems topics. Check out this year’s
#MLSys2024
program. The conference will happen May 13th

1
26
130
Glad that XGBoost continues to help data scientists, thanks to
@hcho3_ml
and many other community developers

@kaggle
State of machine learning annual survey. XGboost, as usual, is among the top framework choices. Glad that we can help to make ml and data science better together with collection of other awesome frameworks

4
54
283
3
16
125
#WebLLM
just completed a major overhaul with typescript rewrite, and modularized packaging. The
@javascript
package is now available in
@npmjs
. Brings accelerated LLM chats to the browser via
@WebGPU
. Checkout examples and build your own private chatbot

2
39
126
With the emergence of new hardware, what are the challenges for deep learning systems? We try to answer it in our TVM paper to provide reusable optimization stack for DLSys on CPU/GPU, and accelerators. I will give an oral presentation about it at
#SysML
1
48
125
Video for my SysML talk TVM: End-to-End Compilation Stack for Deep Learning video is now online at The first SysML is really exciting and am looking forward to next year's conference!

1
43
121
2018 will be the year we see more compiler and deep learning in all parts of the stack
3
24
118
Excited to share our
#NeurIPS2022
paper. "Tensor Program Optimization with Probabilistic Programs". Talk to
@junrushao
and others at poster Hall J 702! This is one of the most fun improvement made to
@ApacheTVM
in the past two years, from
@OctoML
@mldcmu
@SCSatCMU
. a thread🧵

2
22
119
Efficient Architecture Search by Network Transformation combines Net2Net with neural architecture search
1
43
101
Set out to
#NeurIPS
, many UWSAMPL folks will be there. We will present "Learning to Optimize Tensor Programs" (Tue Dec 4th Spotlight 3:45PM Room 220 CD and 5PM Room 210 & 230 AB Poster 104). Love to chat about ML for systems and hardware-software full-stack ML systems

0
23
100
Fun hack in the past few weeks. By compiling machine learning models to
#WebAssembly
and
#WebGPUc
for the first time, we can run GPU-accelerated deep learning models on browsers and get close to the native performance.

Compiling Machine Learning to WASM and WebGPU with Apache TVM. Preliminary experiments shows that TVM’s WebGPU backend can get close to native GPU performance when deploying models to the web.🚀🚀

1
27
84
1
13
102




Random search can be very strong and often is STOA, especially when we do not have strong domain knowledge

Random Search and Reproducibility for Neural Architecture Search
They show that random search of architectures is a strong baseline for architecture search. In fact, random search gets near state-of-the-art results on PTB (RNNs) and CIFAR-10 (ConvNets).




3
117
428
1
18
99
One key insight in FlashAttn and many related works is that attention computation can be communicative and associative. I always wonder about the best way to write down and teach it. Checkout "Recursive Attention" section👉, which explains it elegantly

(1/3) Memory Bandwidth Efficient Shared Prefix Batch Decoding, brought to you by FlashInfer:
blog:
Trying out our APIs:

1
20
100
0
19
100
Nice blog on using TVM stack to speed up batchmul in
@TensorFlow
for 13x and end to end neural machine translation for 1.7x
0
35
97
We are opensource NNVM as our step to push modularize and decentralzied deep learning systems

4
55
97
RedPajama-3B is a pretty compact model(takes ~2G) yet pretty amazing. Now running on M1, iPhone and browsers. You can also bring your own model weights and chat with them in the laptop, browser or phone, all local. Checkout the demo!
LLMs like RedPajama are embracing open permissive license. What does it mean for us? Could they become our personal friends, and will they shape a unique market? Now RedPajama-3B can run locally on phones, browsers and laptops with hardware acceleration!
3
18
75
1
16
91
Use transfer learning to automatic optimize deep learning kernel performance on Nvidia, AMD GPUs, mobile phones and IoT devices. Super exciting to see that learning is already competitive with the vendor specific solutions such as TensorRT, TFLite, ARMComputeLib.
Automatic Kernel Optimization for Deep Learning on All Hardware Platforms

1
23
60
0
27
89
Binary neural networks have great potential for AIoT,
#TinyML
, however, none of existing paper actually implemented the BNNs in a way that can measure end to end speedups on real hw. Riptide is the first paper to makes BNN practical, using great ML and systems(
#MLSys
) insights

Interested in trying out the first ever end to end, optimized, open source binary neural network framework? Read all about the 12x end to end speedups available from Riptide in our latest blog entry by our very own Josh Fromm:
1
46
118
2
25
92
Bringing
#Llama2
70B universally, for everyone with multi-GPU. 👉 Scale to bigger models for GPU poor without constraint by the RAM limit. 🚀 go GPU poors. The 70B model now can get to 30t/s under 2k$ budget with 2xAMD and 34 t/s under 3k$ with 2x4090.
(1/3) 🦙🌟 Looking to run Llama2-70B? With two NV/AMD GPUs or more?
💥🔥 Machine learning compilation (MLC) now supports multi-GPU.
⚡️💻 We achieve 34 tok/sec on 2 x RTX 4090, the fastest solution at $3.2k.
🌐💡Two AMD 7900XTX delivers 30 tok/sec at $2k.

8
37
173
1
19
88
It is kinda of 🤯 and fun to see it works. llama2 70b completely running on browser without server support with latest Chrome Canary via
@WebGPU
, get a apple silicon device with 64G or more, open the webpage and that's it.

2
23
86
FFI Navigator: IDEs support find function definition within the same language(e.g. python or c++), but not cross cross-language FFI calls. We hacked up a fun language server plugin for doing that supports
@ApacheTVM
@PyTorch
@ApacheMXNet
@GraphDeep
2
14
90
Check this out. Stable diffusion completely in the browser with
@WebGPU
with no server support (and as fast as native gpu running). It is also amazing to see how OSS ecosystems come together to make it possible, with
@huggingface
diffusors,
@PyTorch
@ApacheTVM
@WebGPU

Stable diffusion models are fun and usually take a server to run. Today we are happy to share the Web Stable Diffusion project, which brings SD models from
@huggingface
and
@pytorch
to browser clients through
@WebGPU
support. Checkout for our demo!

4
28
125
0
23
87
Ten years ago, where the journey of XGBoost began.


4
10
85
👉Mistral running fully locally on your browser, with benefit of sliding window attention means to have a looong chat with the model.
Run
@MistralAI
's 7B model on your browser with
@WebGPU
acceleration! Try it out at
For native LLM deployment, sliding window attention is particularly helpful for enjoying longer context with less memory requirement.

1
10
62
1
17
84
Proud to be part of the new group at UW to bring people system, architecture, machine learning and program language together to push for research on future intelligent systems.

0
6
80
Mistral-7B-Instruct-v0.2 on iPhone with StreamingLLM support

Run the Mistral-7B-Instruct-v0.2 model on iPhone! Supports now StreamingLLM for endless generation. Try the MLC Chat App via TestFlight
For native LLM deployment, attention sinks are particularly helpful for longer generation with less memory requirement.


3
16
73
1
12
76
#Llama3
🦙🦙 running fully locally on iPad without internet connnection. credits to
@ruihanglai
and the team
0
17
76
Amazing results from WizardLM. Great to see open LLM continues to make strides, and let us bring them to everywhere, for everyone

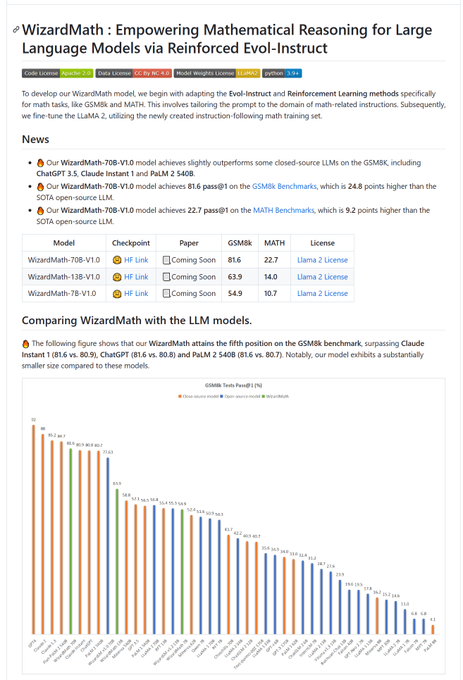
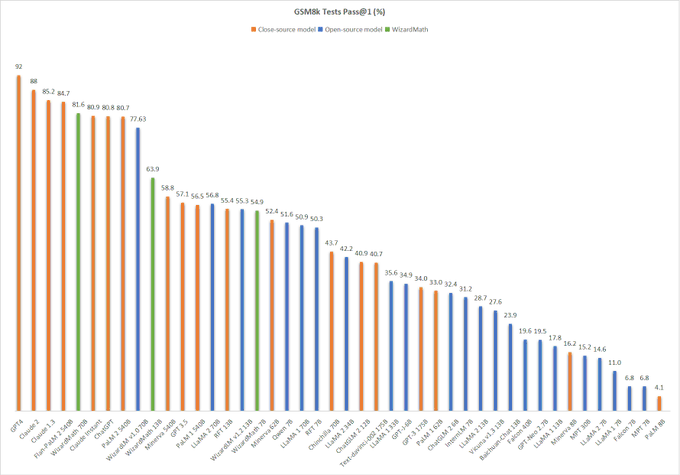
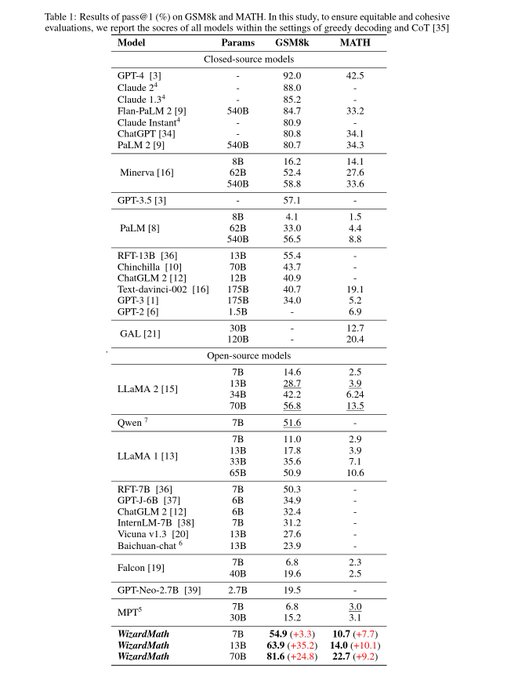
3
9
72
Please spread the words,
#MLSys2024
will feature a full day single track-event young professional symposium with invited talks, panels, round tables, and poster sessions. Submit your 1-page abstract by April 1st & present your work at our poster session.
2
19
71


#MLSys23
will be Miami from June 4th through June 8th! We have an exciting program about the latest advances in machine learning and systems. We are also happy to announce the MLSys23 student travel awards program. Please apply via

0
17
70
TVM v0.2 is here! A lot of exciting things happened in the last release cycle, nnvm compiler support for deep learning frameworks, AMDGPU backends, and good ARM GPU results. We will see more exciting things to come in the stack in the next cycle.

1
25
71
Gemma 2b running on iphone at 22+ tok/sec. 2B really hits a sweetspot for running local model on phone. Try it out via 👉

Run Gemma model locally on iPhone - we get blazing fast 20 tok/s for 2B model.
This shows amazing potential ahead for Gemma fine-tunes on phones, made possible by the new MLC SLM compilation flow by
@junrushao
from
@OctoAICloud
and many other contributors.
3
18
38
2
18
71



#MLSys
kicks off this year with a session on scaling ai systems, chaired by
@JiaZhihao
. Three great talks on scaling up transformers, mixture of experts and related model variants

3
6
69
Learning automatic differentiation by build one:) from assignment of the CSE599G1 at UW

1
19
66
A self-contained and comprehensive introduction to boosted trees
http://t.co/k15UGC8iOd
#xgboost
2
26
66

Excited to share
#ASPLOS23
paper, "TensorIR: An Abstraction for Automatic Tensorized Program Optimization". This is an exciting step to bring
@ApacheTVM
to next level and enable more accessible ML compilation. It also powers fun stuffs like Web Stable Diffusion. a thread🧵
Excited to share our
#ASPLOS23
paper. “TensorIR: An Abstraction for Automatic Tensorized Program Optimization”. Come to our talk in Section 5C at Grand D! TensorIR lies at the core of the next-level generation of the TVM compiler
@ApacheTVM
, from
@SCSatCMU
@OctoML
.

0
10
47
2
13
66
👉 Try out codellama 7b and 13b in colab notebooks
Code Llama is now on MLC LLM! 🦙💻
MLC LLM allows you to deploy your personal coding AI assistants locally. Try it out directly on Colab. This is an easy way to run
@MetaAI
's latest code-specialized LLM.
MLC LLM:
Colab 13b models:


4
22
71
0
15
62
WebLLM, runs LLM entirely in the browser with
@WebGPU
, leading to lot of fun opportunities to build AI assistants for everyone. Try out the demo! runs on M1/M2 and other desktops with enough GPU. Decent at writing poems and not too good at drawing, did get cat right sometimes.


Introducing WebLLM, an open-source chatbot that brings language models (LLMs) directly onto web browsers. We can now run instruction fine-tuned LLaMA (Vicuna) models natively on your browser tab via
@WebGPU
with no server support. Checkout our demo at .

46
448
2K
0
15
62
A cool result from FB, better inference with new conv op and code optimized by AutoTVM

OctConv is a simple replacement for the traditional convolution operation that gets better accuracy with fewer FLOPs
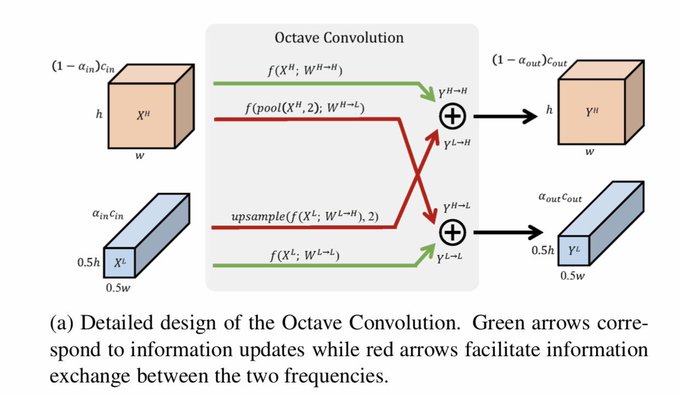
16
571
2K
0
18
59
Try out the
@WizardLM_AI
WizardMath directly in colab 👉 Fun to explore the reasoning capabilities of WizardMath and see what specialized openLLM can do
Specialized personal AI assistants--deployable everywhere! 🌎🤖
Check out MLC LLM’s support for recently released models from
@WizardLM_AI
: WizardLM, WizardMath, and WizardCoder!
Try it here (runnable on Colab):
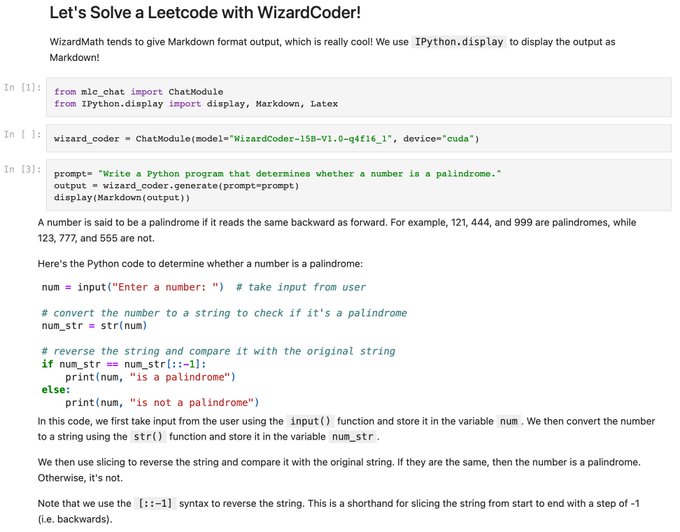
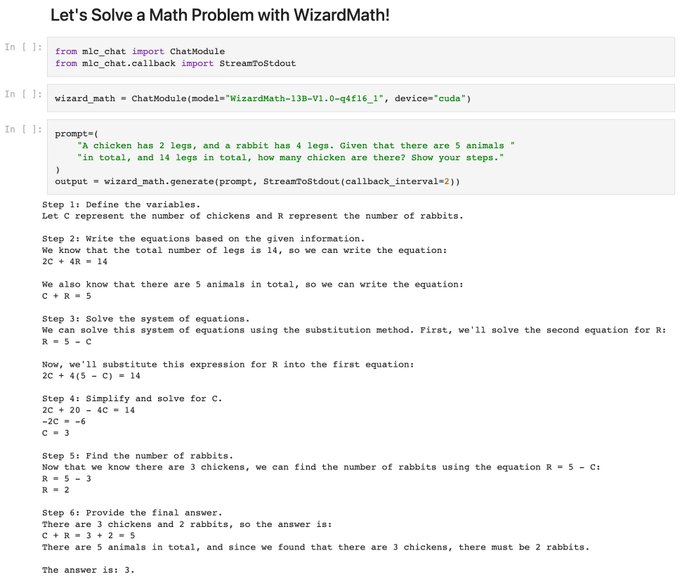
2
10
46
0
9
61
AMDGPUs for TVM stack and NNVM compiler! enables deep learning Frameworks ->AMD GCN assembly. by Aditya and Masa
1
28
60
#MLSys23
will be Miami from June 4th through June 8th! We have an exciting program about the latest advances in machine learning and systems. If you want to learn about the latest technologies and advances in AI and machine learning systems. Early registration ends by May 7th!
1
14
58
#MLSys2023
will feature two keynote speakers,
@matei_zaharia
will talk about “Improving the Quality and Factuality of Large Language Model Applications”, and
@srush_nlp
will discuss “Do we need Attention?” join us and register at

2
13
57
assignment 2 of dlsys course build a complete GPU based framework in 1k lines of python
0
14
55
Qwen2 on iphone is now available through testflight , powered by MLCEngine
Exciting to share we have been working on over the past one year. MLCEngine, a universal LLM deployment engine that brings the power of server optimizations and local deploymet into a single framework, checkout platforms support 👇 and blogpost more in a🧵
4
51
222
0
14
56
@soumithchintala
Regardless of technical directions, one things that I learned from PyTorch is the importance of a good community :)
1
4
55
TVMv0.3 is here! TOPI vision support, numpy-style operator overload APIs, new backends. We are also going to have a fun next release cycle with improvements bought by our awesome community contributors

0
20
54
Finally feeling making full worth the buck on getting the 64g m2max book that runs llama2 70b. Kinda of attractive deal on the capability it can get. The age of PC begins with a few big computers, wonder what would the age of P-AI looks like. At least RAM becomes as crucial
(1/2)
🦙 Buckle up and ready for a wild llama ride with 70B Llama-2 on a single MacBook 💻
🤯 Now 70B Llama-2 can be run smoothly on an 64G M2 max with 4bit quantization.
👉 Here is a step-by-step guide:
🚀 How about the performance? It's
19
86
504
3
9
53
Hybrid Composition with IdleBlock: More Efficient Networks for Image Recognition. Simpler and more efficient network design that improves over EfficientNet-B0. by Bing Xu,
@ajtulloch
and others from FB AI

2
9
52


Excited to see folks in two weeks at MLSys22 in Santa Clara.
@mcarbin
and I are happy to announce MLSys 2023 key dates:
- Paper submission and co-author registration:, October 28, 2022 4pm ET
- Author response: Jan 16 to Jan, 20, 2023
- Author notification: Feb 17, 2023
1
11
51
One key lesson that I learned in open source is the Apache(
@TheASF
) way of development. By keeping all discussions and decisions in public archive, we enable everyone's participation. While this approach brings a bit overhead, it is the best way to grow a healthy community.
0
4
51
Great to attend MLSys this year in person. CMU Catalyst group is also presenting several works at the conference. CoRa Tensor Compiler that generates optimized code for transformer workloads with ragged tensor. DietCode enables automatic dynamic tensor program optimizations.
1
2
51

Please help spread the words📢 If you are in the field of AI and interested in the latest innovations in machine learning and systems. You should checkout
#MLSys24
!

We are excited to announce this year’s keynote speakers for
#MLSys2024
: Jeff Dean
@JeffDean
, Zico Kolter
@zicokolter
, and Yejin Choi
@YejinChoinka
! MLSys this year will be held in Santa Clara on May 13–16. More details at .
1
17
82
1
13
49

The same solution also brings universal support to any GPUs on linux/windows and Mac thanks to
@VulkanAPI
Here is a screenshot of CLI in action through vulkan. Checkout the page for more instructions
Running LLM-based chat locally on iphone 📱with GPU acceleration. Also brings universal deployment to NV/AMD/M1 GPUs. Love to see it enabling personal assistants for everyone. Try out demos
9
89
323
0
11
49
UW SAMPL will present a tutorial about TVM on June 22nd at
@ISCAConfOrg
FCRC. Come and learn about full-stack ML system, learning-based automation and compiler support for new deep learning accelerators.
1
15
48
Fist stab of Gemma support lands in MLC, (by
@ruihanglai
@charlie_ruan
, rick zhou). The single model is defined once, and runs across browser/mobile/server. Made possible by ML compiler infra lead by
@junrushao
(and
@leshenj15
). more fun things to drop

0
15
46
👀a new deep learning framework for apple silicons :)

Just in time for the holidays, we are releasing some new software today from Apple machine learning research.
MLX is an efficient machine learning framework specifically designed for Apple silicon (i.e. your laptop!)
Code:
Docs:
100
717
4K
0
3
49
I had an enjoyable chat with
@FanaHOVA
and
@swyx
on machine learning systems and bringing high-performance universal deployment for ML models. Checkout the latest episode in latent space 👉

H100s? 🤨 I'll just run LLaMA2 70B in the browser, thanks!
@tqchenml
came on
@latentspacepod
to talk about the work MLC is doing to enable everyone to run models natively on any hardware / software stack, including Chrome and iPhones (and AMD cards!)
🎙️
2
40
178
1
11
48