
Tolga Bolukbasi
@tolgab0
Followers
308
Following
417
Media
3
Statuses
92
AI research/Gemini pretraining @GoogleDeepmind, PhD, opinions my own.
Joined November 2014
Our work on scaling training data attribution is out. There are a lot of insights in there, I especially like the distinction between attribution and influence. Thanks to our amazing student researcher Tyler for making this happen.

We scaled training data attribution (TDA) methods ~1000x to find influential pretraining examples for thousands of queries in an 8B-parameter LLM over the entire 160B-token C4 corpus! https://t.co/4mglIOAjyB

0
1
11

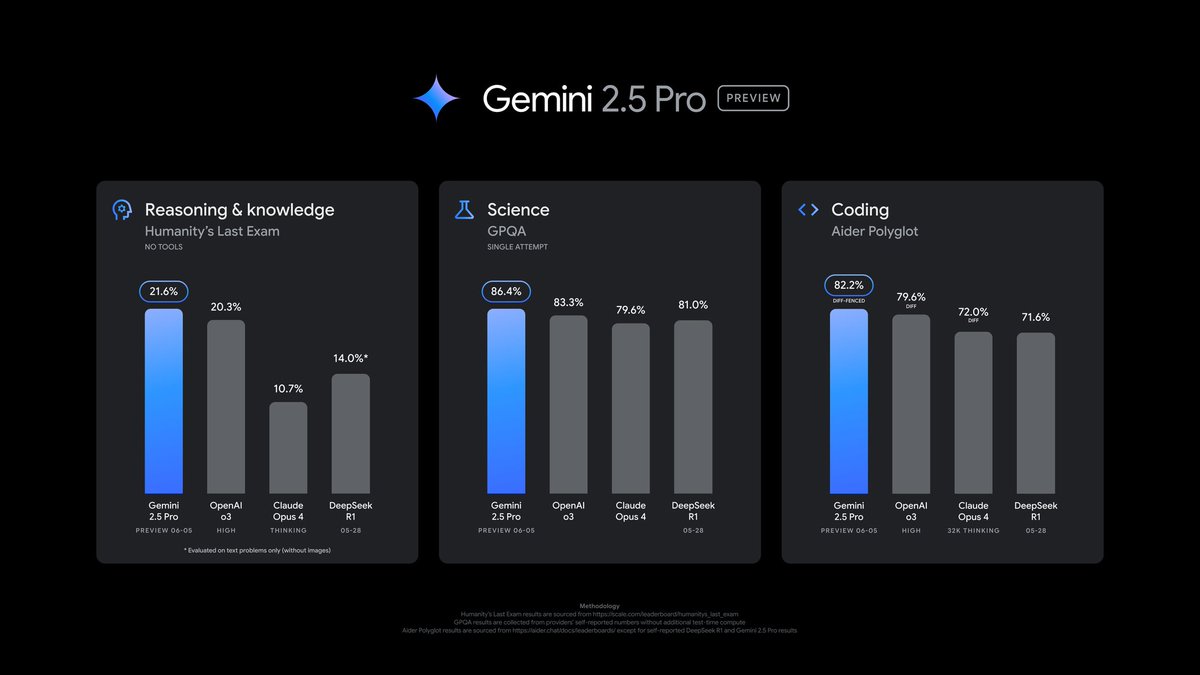
Our latest Gemini 2.5 Pro update is now in preview. It’s better at coding, reasoning, science + math, shows improved performance across key benchmarks (AIDER Polyglot, GPQA, HLE to name a few), and leads @lmarena_ai with a 24pt Elo score jump since the previous version. We also
327
734
6K
Presenting our work on training data attribution for pretraining this morning: https://t.co/aypbwhN27I -- come stop by in Hall 2/3 #526 if you're here at ICLR!
We scaled training data attribution (TDA) methods ~1000x to find influential pretraining examples for thousands of queries in an 8B-parameter LLM over the entire 160B-token C4 corpus! https://t.co/4mglIOAjyB
0
5
20

This model’s “thinking” capabilities are driving major gains: 🧑🔬Top performance on math and science benchmarks (AIME, GPQA) 💻Exceptional coding performance (LiveCodeBench) 📈Impressive performance on complex prompts (Humanity’s Last Exam) #1 on @lmarena_ai leaderboard 🏆
4
18
307

https://t.co/RSBWw8taHS "From Figure 3(a), it is apparent that many of the benchmarks we considered are substantially contaminated in the Llama 1 pre-training corpus as well as in the Pile. For 8 of the 13 datasets that we considered, on average more than 50% of the samples are


@RawSucces @DAcemogluMIT You misread. There had been multiple LLM projects within FAIR for years. Some were open sourced as research prototypes (e.g. OPT175B, Galactica, BlenderBot...). In mid-2022, FAIR started a large LLM project called Zetta, which was still going in late 2022 when ChatGPT came out. A
5
14
252

@Nexuist I worked on the M series while at Apple. The main advantage that stuck out to me was actually that they were able to acquire dozens of top Intel engineers 5-10 years ago as Intel started struggling and making poor decisions. For example, Intel had a couple sites around the
82
487
9K

Machine unlearning ("removing" training data from a trained ML model) is a hard, important problem. Datamodel Matching (DMM): a new unlearning paradigm with strong empirical performance! w/ @kris_georgiev1 @RoyRinberg @smsampark @shivamg_13 @aleks_madry @SethInternet (1/4)
2
22
139
I will be in ATTRIB workshop tomorrow ( https://t.co/XUfUQxpfLR). Stop by if you’d like to chat with me and connect with other great researchers in this area.
0
1
9

We'll present this at #NeurIPS

New Anthropic research paper: Many-shot jailbreaking. We study a long-context jailbreaking technique that is effective on most large language models, including those developed by Anthropic and many of our peers. Read our blog post and the paper here: https://t.co/6F03M8AgcA

7
13
308

Welcome, AlphaChip! Today, we are sharing some exciting updates on our work published in @Nature in 2021 on using reinforcement learning for ASIC chip floorplanning and layout. We’re also naming this work AlphaChip. Since we first published this work, our use of this approach
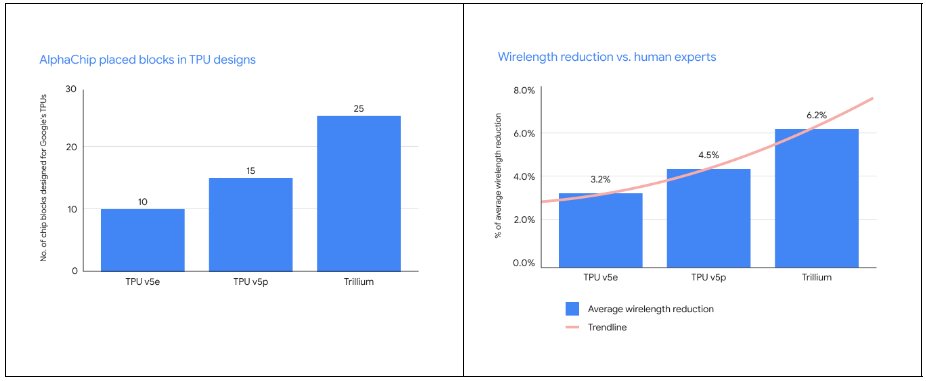

Our AI for chip design method AlphaChip has transformed the way we design microchips. ⚡ From helping to design state-of-the-art TPUs for building AI models to CPUs in data centers - its widespread impact can be seen across Alphabet and beyond. Find out more →
42
317
2K
I have been thinking about this since ChatGPT came out. Using RLHF never fully made sense to me given how restricted it is compared to regular RL. There should be a way simpler non-exploring method to distill RM knowledge into the main model.

# RLHF is just barely RL Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely

0
0
1
We have an experimental updated version of Gemini 1.5 Pro that is #1 on the @lmsysorg Chatbot Arena. This model is a significant improvement over earlier versions of Gemini 1.5 Pro (it cracks into 1300+ elo score territory). I'm really proud of the whole team of people that

Exciting News from Chatbot Arena! @GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes. For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive

31
108
797

Great to see Gemini 1.5 doing well on this new video understanding benchmark!


0
4
30

sign up for the wait-list here
docs.google.com
Thanks so much for your interest. We review all submissions on a rolling basis. Google Labs is a place to play and experiment at the intersection of creativity and AI. We’re committed to building AI...
Introducing Veo: our most capable generative video model. 🎥 It can create high-quality, 1080p clips that can go beyond 60 seconds. From photorealism to surrealism and animation, it can tackle a range of cinematic styles. 🧵 #GoogleIO
5
12
42
It was great to work with Minsuk and excited to see this released. Looking at individual model outputs this way helps one see which examples/tasks are truly wins across model versions and which ones are just due to randomness of generation or raters.

Very excited to open-source LLM Comparator! This new #visualization tool lets you analyze LLM responses side-by-side. It’s been used for evaluating LLMs @Google, and we're proud to release it as part of Google's Responsible GenAI Toolkit. https://t.co/xXwvBzlz2g
0
0
7
Nice new read on tokenization! You've heard about the SolidGoldMagikarp token, which breaks GPT-2 because it was present in the training set of the Tokenizer, but not the LLM later. This paper digs in in a lot more depth and detail, on a lot more models, discovering a less

Our paper about reliably finding under-trained or 'glitch' tokens is out! We find up to thousands of these tokens in some #LLMs, and give examples for most popular models. https://t.co/4ZTSRL50y0 More in 🧵

48
349
3K
Happy news: ICLL is accepted to ICML, 2024!

Can insights from synthetic experiments and interpretability lead to real improvements in language modeling? We: > propose a formal model for in-context learning > uncover "n-gram heads" = high order induction heads, crucial for ICLL > improve Transformer LM perplexity by 6.7%

4
10
100

Great new work from our team and colleagues at @GoogleDeepMind! On the Massive Text Embedding Benchmark (MTEB), Gecko is the strongest model to fit under 768-dim. Try it on @googlecloud. Use it for RAG, retrieval, vector databases, etc.

Google presents Gecko Versatile Text Embeddings Distilled from Large Language Models Gecko with 768 emb dim competes with 7x larger models and 5x higher dimensional embeddings https://t.co/R9sQ8hpTGb

0
6
29

I am really excited to reveal what @GoogleDeepMind's Open Endedness Team has been up to 🚀. We introduce Genie 🧞, a foundation world model trained exclusively from Internet videos that can generate an endless variety of action-controllable 2D worlds given image prompts.
133
552
2K