

テッツォ
@tetsuro731
Followers
2,562
Following
2,063
Media
1,452
Statuses
25,688
機械学習とか統計とかやってる人。企業のデータサイエンティスト。個人で分析系のお仕事やAIベンチャーのアドバイザーなども。物理学博士。身長と体重がベジータと同じ。Kaggle Competition Expert 🥈3🥉1 英語も勉強中。
Joined December 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#LaCasaDeLosFamososMx
• 168300 Tweets
#MHA430
• 160153 Tweets
無課金おじさん
• 120688 Tweets
トルコのおじさん
• 118610 Tweets
ROCKSTAR SPECIAL STAGE
• 101301 Tweets
Yuji
• 92280 Tweets
Corinthians
• 71983 Tweets
Ricardo
• 70033 Tweets
Karime
• 66134 Tweets
Gala
• 63647 Tweets
Happy New Month
• 61361 Tweets
Deku
• 48499 Tweets
Amad
• 36831 Tweets
#ピッコマでマンガ読んでポイ活
• 28068 Tweets
Arath
• 21641 Tweets
संसद भवन
• 20981 Tweets
リーリヤ
• 16826 Tweets
#総額3億円分
• 15619 Tweets
Καλο
• 13295 Tweets





















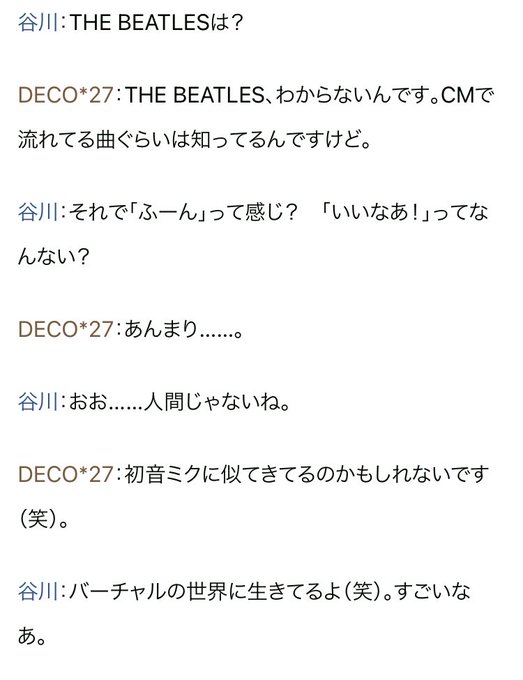
DECO27の教養よりも、谷川俊太郎が「それくらい知ってなきゃいけない」と説教したり老害ムーブを一切出さずにひたすら肯定、感心しているのが凄いと思う。
多分これができる大人って多くないんじゃないかな。



229
13K
98K
オムツを履いていない状態で泣いた場合、参照すべきオムツがnullになってエラーになるバグがある。


95
10K
43K

これは非常に面白い思考実験で、例えばAという名字の総数は男の場合は結婚で+1、女の場合は-1される。つまりこれは一次元のランダムウォークと呼ばれる動きになる。ただし、一度ゼロになった名字は復活しないため、もし人類が今後無限に存在すれば名字は”ただ一つに”収束するはずだ。


ふと思ったんだけどさ。
「名字」って基本的に、新規に発生することって無いよな?
ってことはだ、基本的に結婚して片方がもう片方の姓を名乗ることになるので、
2人につき片方は消滅する訳じゃん?
子無しなら結局は消滅する訳じゃん?
単身の場合も自然消滅する訳じゃん?
393
10K
59K
18
2K
7K
いやオムツのnull pointer exceptionを実装で回避したとしても、例えば全裸でうんちをぶちまけてた場合に「オムツが汚れていない」とみなして抱っこしたりタケモトピアノのCMを聞かせ続けてしまうといった行動を取るリスクがあるので、この問題はビジネスの抽象度でも解決しない。

この指摘は実装時の関心事であり、フローをビジネスレベルの抽象度と捉えた時、オムツを履いていない場合は汚れたオムツが存在しないのであるから「いいえ」に分岐することで問題ない。実装はomutsu.isDirtyではなく赤ちゃん.wearsDirtyOmutsu()での判定を想定
4
379
1K
14
2K
7K

音楽/作詞という「共通のフィールドで」「自分よりはるかに年下が」「自分が当たり前に知っている教養のなさを晒して」きたときに説教せずにいられるだろうか?
それでも相手の言葉に耳を傾けて素直に凄いと言えるだろうか?
10
399
3K
以前「弊社から内定もらったけど蹴った」という内容で有料の情報商材販売してる人がいて、かなり詳細に面接の内容とかチーム構成とか暴露されてた上明らかに間違った内容も多くて「うーん」って思ってたんだけど、今日上長に話したらそもそも内定出してないって言っ��てホラーだった。
6
676
3K
単なるオムツorientedな考え方だと、「お風呂でうんちをぶち撒け泣いた」場合や「オムツ替え中でうんちまみれ、一時的にオムツを履いてない」などの様々な例外に対応できない。そこでまず処理すべき汚物があるか?に注目するオムツ指向→汚物指向への転換を提唱したい。
2
241
917
他にも実装によっては汚れたオムツを外した瞬間に「オムツを履いていない→オムツが汚れていない」状態へシフトしおむつ替えを中断し初手に戻る無限ループが生じ、外部の介入がない限り無限に高速でオムツを外して付けてを繰り返す危険性がある。
1
196
755
データサイエンティストって企業によって微妙に定義が違うんだけど、大まかに4つの「型」があるので、どのタイプを目指すのか意識しておくのが大事。




2
60
712
そもそも最初の問いで「オムツ」にフォーカスすること自体が問題であるように感じる。「顧客が欲しいのはドリルではなく穴」であるように、今回のイシューであり本質はオムツそのものというより「うんちやおしっこなどの汚物が処理すべきものとして滞留していること」だと捉えることができる。
2
133
668
続きの議論です
いやオムツのnull pointer exceptionを実装で回避したとしても、例えば全裸でうんちをぶちまけてた場合に「オムツが汚れていない」とみなして抱っこしたりタケモトピアノのCMを聞かせ続けてしまうといった行動を取るリスクがあるので、この問題はビジネスの抽象度でも解決しない。
14
2K
7K
4
164
660
自分も同じ経験したことあるけど、アカデミアの場合はきちんと再現性のある結果を定量的に出して論文にする必要があるけど、ビジネスの場合は有意差頑張って出すよりもさくっと次の実験回したり要点偉い人に報告して次のビジネス判断に繋げる方が良い場合があるんだよね。ゴールが違う。

これ結構大発見だったんだけど、会社で「数字を出せ」と言われる時は厳密に統計学的な有意差を求められているわけではなく、定性的に作った仮説がある程度間違っていなさそうかどうかのざっくりした根拠が求められているだけらしかった
アカデミアに染まりすぎててウケた
8
867
7K
1
107
612
スタバのデータサイエンティスト募集中です。
募集要項出たので貼っておきます。
楽しい福利厚生:コーヒー豆無料でもらえる、オフィスでコーヒー飲み放題など(基本リモート)
Python, SQL等ができる+ビジネスレベルの英語力が必要です。
興味のある方はぜひご連絡ください!
1
177
601
これには理由があって、データサイエンティストは職業柄「自分の書いたコードを誰かが長期保守運用する」みたいなことが少なく、リファクタするくらいなら実験回して汚いコードでもいいから綺麗なプロットやら分析結果やら出す方が優先されるから。逆に少しでもエンジニアリングできると価値が上がる。

データサイエンティストの多くが、コードぐちゃぐちゃです。笑
・Jupyter Notebookしか使わない
・class使わずfunctionしか使わない
・モジュール化せずにfunctionをコピペ
・APIキーをnotebookにベタ打ち
・GitHub、Dockerを使わない
2
134
1K
3
105
556
バズったので宣伝します!
赤ちゃんが読んでる論文はこれです。
レコメンド精度向上にTransformerと自己教師学習を取り入れることでLightGBMをはじめGBDTを越える性能が出たという去年トロント大学から出たrecsys challangeで優勝した論文です。
面白いのでみんな読んでみて!
4
42
506
「教育教育教育教育教育教育教育教育教育教育教育教育教育教育教育教育死刑死刑死刑死刑死刑死刑死刑死刑死刑死刑死刑教育教育教育教育教育教育教育教育教育教育教育教育教育教育教育」は漢字3バイト*86文字で258バイトですが、ランレングス符号化を使えば「教育18死刑11教育14」と16%まで圧縮可能です
1
100
456
スタバのデータサイエンティスト、また新しく募集してるので興味のある方はぜひ~
>データサイエンスにおける2年以上の関連業務経験
なのでジュニアレベルの人も応募しやすいと思います。
3
63
406
ただし、名字が変わるタイミングは基本一生に一度であるためこのランダムウォークは人類の体感だと非常にゆっくりになる。
ではもしネズミに名字を与えて長い時間繁殖を観察し続けたらどうだろう?
一つの名字に収束するのが見れるかも。あるいは簡単な数値シミュレーションでも見れるだろうね。
2
54
396
これは割と真理な気がしていて、kagglerの中では当たり前な「leakに気をつけてcv切ってlgbmにぶちこむ」ができてない会社やサービスは意外と多いので、それをやるだけでビジネス的な価値がある。
逆にコスト度外視の複雑なアンサンブルとか細かすぎるチューニングが必要なサービスはほとんどない印象。

kagglerに機械学習でナントカシテェ!って頼むと謎のaugmentationとハイパラチューニングでaucを0.01上げるなんてことはせず、leakに気をつけてcv切ってlgbmにぶちこんだらこんなもんやで!くらいの答えが返ってきそう
1
19
195
1
48
378

ランダムウォークはかなり一般的だけど、名字の問題はすでにゴルトン・ワトソン過程という名前で定量化されてるらしい。こっちは知らなかった。
0
83
334

面接で話した内容はある程度は広まってもしょうがないし暗黙の了解的なのはあると思うけど、たかだか数千円のお小遣い稼ぎのために商材化して信頼を失ってしまうのは割に合わないからやめた方がいいと思う。匿名アカウントでもわかる人からしたら誰なのか分かってしまうし、業界は意外と狭いので…
1
48
333
さらに言えばこの動きは確率論で決まるため、佐藤や高橋などの名字は総数の初期値が大きいため有利ではあるが、シミュレーションでは毎回異なる名字が生き残るだろう。「今回は高橋が優勝した」「今回は村田が逆転優勝した」みたいに。
1
36
251
職場の同僚に薦められてみた映画「マネーボール」
ブラッドピットが統計学とデータを駆使して弱小チームを強くする話。
データサイエンスを仕事で使ってる俺にはとても刺さった。

3
11
218
転職活動についてちょっとだけ。
外資IT企業/部門を受けるならleetcode周回がおそらく最もコスパいいです。
英語の技術面接はPrampというサービスで練習できるので、何回かやると慣れてきます。
1
13
207
polarsが「pandasより速くていいよね」ってのはここ数年言われてることではあるんだけど、積み上げてきたOSSが pandas前提のものが多くて今はまだ共存状態。逆にそのへんの移行が終わればいよいよpandasオワコンになるかもなので今のうちにpolars慣れておきたいところ。
1
23
191
MLFlow+LightGBMやってみよう。
MLFlow最近あんまりさわってなかったけどこんな簡単に使えるんだっけか。

0
14
179
Kaggle、Twitterには強い人がいっぱいいすぎて「金メダル取れない=ダメだった」的な考えになりがちだけど、銅メダルでも上位10%だから十分凄いしコンペ完走する体力あるだけでも凄いし、完走できなくても主体的に解放とか読んで勉強してるだけ凄いと思う。それができない社会人も多いので。
0
9
177
pandasでstrの場合、単純に一文字1バイトとすると文字数×行数のデータになるので平均10文字×数億行とかだとそれだけでGBオーダーで消費する。なのでcategory型にするかlabel encodingしてint型にすればかなり節約できる。ちなみにpolarsだとstrのままでも内部でいい感じに最適化処理してくれるから便利

Pandasのobject型とcategory型
カラムのデータの種類が限られているのであればcategory型にした方が処理速度とメモリ使用量が改善するらしい
今までメモリは対して意識したことなかったけど、大規模データを使うようになるならこういう処理にも詳しくなりたい


0
2
61
1
25
173
「L1とL2正則化の違いは何か?」って初学者が学ぶ超基本事項なんだけど、意外と機械学習エンジニア職の面接で口頭で聞かれることも多くて、答えられないと即死なのでちゃんと意味を理解してるか大事だと思う。
GAFAMレベルでも聞かれることある。
1
13
155
人間の目は横よりも縦の方が変化が大きいから、デフォルメした結果本来より縦長になるんだと思う。(目を見開く、薄める、つむる、etc)
同じ理由で鼻よりも口が強調される。
つまり、コミュニケーションの際に表情変化に敏感な箇所はデフォルメすると大きく描かれる傾向がある。

いつからか気になりだしたんだけど、人間の眼の形って横長なのに、ある時期までの漫画って縦長の目が多かったのってなんでだろ
まあディズニー由来とは思うんだけど、そもそもなんで「縦長にしよう」って発想になったのか
しかもこれでちゃんと女の子でも「可愛い」と感じるのがなんとも不思議



91
2K
13K
1
30
154
なんやかんやで5年以上レコメンドモデルの作成や改善の仕事してるので、一般論としてまとめてみようと思う。(あくまで一般論なので僕の経験と100%イコールではない)
レコメンドとはネトフリとかAmazonとかで出てくる「あなたへのオススメ」みたいなやつ。日本語だと推薦システム。
1
7
149
kagglerに子持ち会社員が多く競プロerに
若い学生が多い理由、前者は家族がいると毎週休日夜に90分とかコンテスト出るのが厳しいので空き時間でちまちま進捗出して数ヶ月スパンで結果出すほうがやりやすい一方で、学生にとっては数ヶ月スパンは長すぎて毎週確実にアウトプット出せる方が良いからかな
1
17
143
リファラルの場合は尚更紹介してもらった人の顔に泥を塗る行為になりうるのでリスキーだと思う。
更に言えばプロフにkaggleの肩書き書いてあるけどアカウント名は載せてないし誰も知らない、kaggle経験者とは思えないkaggleディスしてたりで以前から他の人から怪しまれてたのは目撃していた。
0
22
141



@UnseenJapanSite
I started to get a lot of English comments in addtion to Japanese, probably because of this post.
Thank you!
0
0
117
久しぶりにLightBGM回したら今までのearly stoppingの書き方通用しなくなってた、慌てて調べてたらちょうどいい記事があったので読む。
#Qiita
@c60evaporator
より

0
4
111


統計の勉強してて思うのは機械学習よりもアウトプットがしづらいなということ。
機械学習はどんどん新しいフレームワークや手法が出てくるのでそれを適当にまとめるだけで技術ブログ一本書けるけど、数理統計は既に完成されて数学科の学生が教科書で読んで記事にまとめてたりするので差別化しづらい。
2
14
142
とりあえず統計検定準一級の問題集解き始めたけど、最尤推定量の漸近分散のあたり全然知らなくてさっそく詰んだので勉強してる。
コンペの脳みそから統計の脳みそに切り替えるゾ

0
2
99


pandasの裏側はCやCythonで動いてるけど、polarsの裏側はRustで動いてるらしい。
結局Python自体の実行速度が貧弱だから計算速度に関してはいろんなライブラリのサポートが前提になるんだなぁ
1
6
91

このあたりはindeedの面接対策資料が分かりやすいのでおすすめ。
転職考えてない人でも10問中いくつちゃんと説明できるかやってみると機械学習の理解度測れると思う。

0
15
91
僕「え、データサイエンティスト採用の社員も店舗研修やるんですか??」
かつて仕事ができなすぎてコンビニバイトを3ヶ月でクビになった僕が、10年以上の時を経て再び接客にチャレンジする感動の物語、始まる。
1
4
88
転職活動してたころ、どんなサービスでも最終的にはABテストしないとユーザーの反応は分からないと思ってたので、難しい効果検証や分析手法、アルゴリズムやMLモデルよりもABテストの話にフォーカスして面接で話したら「ABテスト以外の経験が乏しい」と言われて落ちたことあるので面接は難しい
0
4
86


pytorchとかぶん回せるけどNNのお気持ちがいまいち分からないみたいな場合には役立つかも?
むしろpytorchやらtensorflowやらのフレームワークやBERT、transformerやらの応用は日々新しいものが出てきて変化が激しいけどベースのNNの概念は普遍的なので一度学んでおいて損はないと思う。

むしろ今日日「データサイエンティスト」と呼ばれる人にゼロから作るDLシリーズはあまり必要ないのでは?と思ったがどうなんだろう
1
4
37
1
5
85
こちらのレコメンド国際学会コンペ、RecSys Challengeで僕は約200チーム中8位でした!
賞金圏内の3位には届きませんでしたが個人的目標だった10位に入れたので満足です!
参加されたみなさんお疲れ様でした。

The
#RecSys2024
challenge by
@EkstraBladet
ended with exceptional results, from both industry and academia!
With around 200 teams, more than 500 people and 760 submissions, it was a resounding success! 🤩
Congratulations to everyone involved.
1
2
9
3
0
84
PyTorchはMetaだしLightGBMはMSだからそのへんの企業はみんな凄いと思ってる

2
10
82
p値の説明、特に数学や統計学に素養のない人に説明するのに困難を極めることが多く、そもそもp値という概念は人類には早すぎるのでは?と思うことがある。


1
10
80
普通に聞かれること多いし大事だよ。
「聞かれない場合もある」
「自分の知ってる範囲だと聞かない」
を主語デカくして一般論で語るのは危険。
そもそもSQLなんて習得に時間かかるもんでもないし、ちゃちゃっとやってできるようにしとけば損ないと思う。

データサイエンティストを目指す方へ。「SQL」を覚える必要はありません。ほぼ見られないです。現に未経験DSの採用担当の私も、評価の項目に一切入れてないです。
3
2
41
4
4
79
一方LightGBMは適当に口にねじ込んでもなんか消化してくれるイメージある。


0
3
78
これは正論。
開封率低いメルマガの効果測定を難解な手法使ってドヤァするよりも「そもそもメルマガって意味あります?LINE訴求の方が良くないですか?」
みたいな議論の方がよっぽどビジネス価値高かったりするからなぁ

やる前にCTRがx%上昇すると売上がy%あがることをきちんと調べたり、なんでそもそもメルマガおくってるんだっけ?等をきちんと事業部門と話してお互い同じ認識合わせる作業が出来るコミュ力がないと、俺達は正しい分析したのにあいつらが理解できない!みたいなオタク発病して嫌われるってだけです。
2
25
136
0
5
75
期待値より悪い分析結果が出た場合に「この結果だと納得できません」「良い結果が出るまで別の尺度で分析し直しては?」「実験期間を延長したら…」「悪い結果は見せないように…」などと言われるのは割とデータサイエンティストあるあるなんだけど、これに屈せずなおかつ納得してもらうのが結構難しい
1
6
75
polarsで書いてるコードの一部をpandasで書いたまま放置してたらそこだけ処理がめちゃくちゃ遅くなって結局全部polarsに書き直した。
やはりpolarsは正義
0
5
75
chatGPTのcode interpreterでタイタニックのEDAができたと話題ですが、タイタニックは今まで散々いじられてきたデータなので、去年のKaggleのコンペであるH&Mのデータを使ってEDAをやらせてみました。
初手でやるEDAとしてはかなりいい感じ!




1
3
72


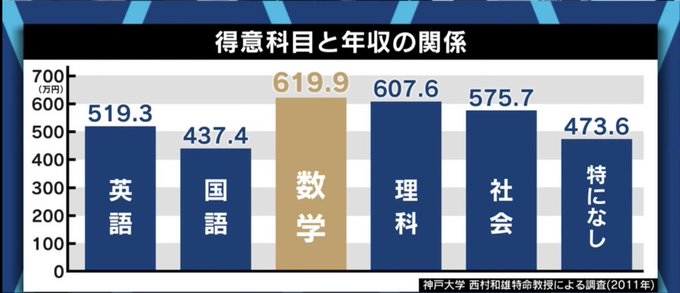
1.数学が得意なのは男が多い
2.男の方が年収が高い
3.数学が得意だと年収が高い
のように「性別」という交絡因子により疑似相関を起こしてるかも?というのが一つ。
あとは「得意科目なし」は出来杉くん的な万能人が含まれる可能性があるので平均だけじゃなく分散や中央値も見てみたい。

0
18
67
Kaggleの何が良いって、コンペが終わってさえしまえばどのコンペで何を考えてどんなコードを書いたのか完全にオープンにして話せるところなんだよな。
仕事だと基本どんなに綺麗なコード書いてもどんなロジック組んでもそれがオープンになって見ず知らずの人のフィードバック貰えることってないから。
0
3
67
これ実はバカにできなくて、正しく訳すためには文法だけじゃなくて
「トムは男の名前でキャシーは女の名前」
「従ってキャシーがトムと呼ばれるのはおかしい」
って理解しなきゃいけないんだよね。機械翻訳とかだと以前はその辺が難しいポイントだったという理解

2
9
64
GBDTに突っ込めばそれっぽい結果になるっていうのはむしろ実業務のほうが多くて、kaggleだとそれをベースラインにしてどんなアイディアを加えていくかを考えないと勝てない。
更に言えばベースラインがGBDTなのは基本テーブルデータに限られるし、特徴量エンジニアリングで個性出すことだってできる

1
3
66
SPIの対策とか本当に不毛だと思うので、もし願いが一つだけ叶うならこの世界からSPIを消し去りたい…

経歴詐称の対策方法が『SPIなどの適性検査を実施することをおすすめします』なの、おもしろすぎる。
いや、普通にバックグラウンドチェックしなよ
0
4
21
1
10
63
Kaggleだとニュートリノが飛んできた方角当てるコンペ(IceCube)とかGNN前提だった気がするので、問題設定次第で強いイメージはあります。
どのポジションの装置が光を検出したかという三次元的な構造のみが与えられてるので。

付加的な情報が多ければGNNよりもLightGBMの方が使いやすくて性能出しやすいのかなぁとか思ってます。みんなLightGBM使うの得意ですもんね
逆にグラフの構造的な情報しかなくて頂点や辺に特徴量がないケースとかだとGNNの方が有利な気がする(あまりそんなケースは見かけないですが)
3
3
49
1
6
64
院生の時、海外の研究者からよく「お前の大学の院生はどれくらい給料を貰えるんだ?」と聞かれた。
「貰えない。むしろ払っている」
と言うとだいたい驚かれた。
アホみたいに時間かけて毎年学振の書類書いて落とされてを繰り返すうちに日本にいるのが馬鹿らしくなったりした。

19)1980年代の中頃、私はスェーデンのウプサラ大学の実験室で、友人の同国院生と雑談していて驚愕した。彼らは大学院へ行くと給料を国から支給される。それは当然で、同年代で就職すれば給料がもらえる、院へ行けば逆に学費を払うと仮にすれば、誰も院に行かないから、国の政策だと説明を受けた。
1
137
249
3
32
61
別に小池百合子推しってわけでもないんだけど、実際子供産まれたときに15万円分のポイントもらえて018サポートで月5000円貰いつつ児童手当も別である上に所得制限もないor撤廃の方向に進んでるのですごい助かってるんだよね。なので今更カイロ大学がどうのこうの言われてもあまり興味がないというか…
2
7
61
自分の友人で会社員でも年収1000万~1500万くらいの人はいっぱいいるけど、誰もSNS、ましてやプロフには書かない。なぜなら基本的に高年収を公開してもいいことはないから。逆にプロフで年収アピールしてる人は怪しんだ方がいいと思ってて、何かしらの有料コンテンツに誘導してくる可能性が高い。
0
2
59
20代独身の頃ならこの働き方できたかもだけど、30代既婚子持ちになると自由に使える時間が減るので違う戦い方が必要になるんだよなぁ。
限られた時間で価値を出せるようにならなきゃ…
2
2
58

給料は希少価値で決まり、希少価値は掛け算で決まると思ってる。
例えば「プログラミングできる」「英語ができる」「マネジメントが上手い」、それぞれが10人に一人(=上位10%)の人材だと掛け合わせれば1000人に一人の逸材になれるし、その条件に合致した求人を見つければ自然に年収は上がると思う
2
4
54

Senior Decision Scientistのポジション募集中です。
今回は機械学習とかよりはBIツールとかデータ民主化とかそのへんの経験ある人が対象です。
興味ある人はリンクから申し込むか僕まで連絡下さい!
福利厚生でコーヒー豆貰えたりオフィスでラテアート練習できたりしますゾ

0
6
54
自分はGoogle Colab Pro+に課金してTPU使うことで300GB以上確保してます。

0
1
53
DSの仕事、個人事業主でやってて法人化するか迷ってる人みんな集めて起業すればいい感じになるのでは?とか思ったり。
自分含めそういう人ちょこちょこTLで観測するので。
現状一人だと起業するメリットはあんまりない。
1
2
53