

Sainbayar Sukhbaatar
@tesatory
Followers
3K
Following
5K
Statuses
1K
Researcher Scientist at FAIR @AIatMeta Research: Memory Networks, Asymmetric Self-Play, CommNet, Adaptive-Span, System2Attention, ...
Joined May 2010
Have you noticed that LLMs give you similar answers, even when you ask for random numbers. We found an easy fix, optimize both quality and diversity!

🚨 Diverse Preference Optimization (DivPO) 🚨 SOTA LLMs have model collapse🫠: they can't generate diverse creative writing or synthetic data 🎨 DivPO trains for both high reward & diversity, vastly improving variety with similar quality. Paper 📝: 🧵below
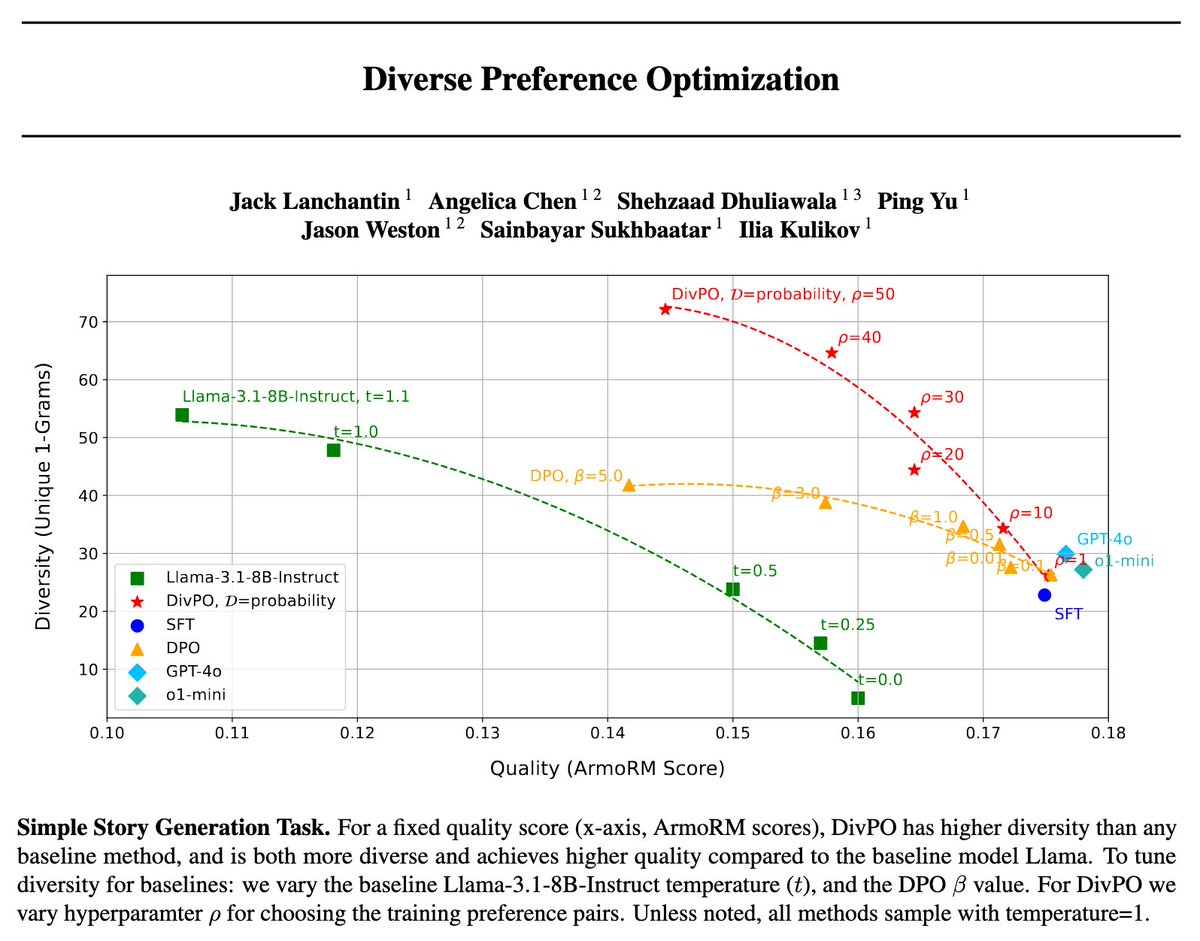
0
1
12
New work! Such a simple method. The gain is surprisingly large.
💀 Introducing RIP: Rejecting Instruction Preferences💀 A method to *curate* high quality data, or *create* high quality synthetic data. Large performance gains across benchmarks (AlpacaEval2, Arena-Hard, WildBench). Paper 📄:
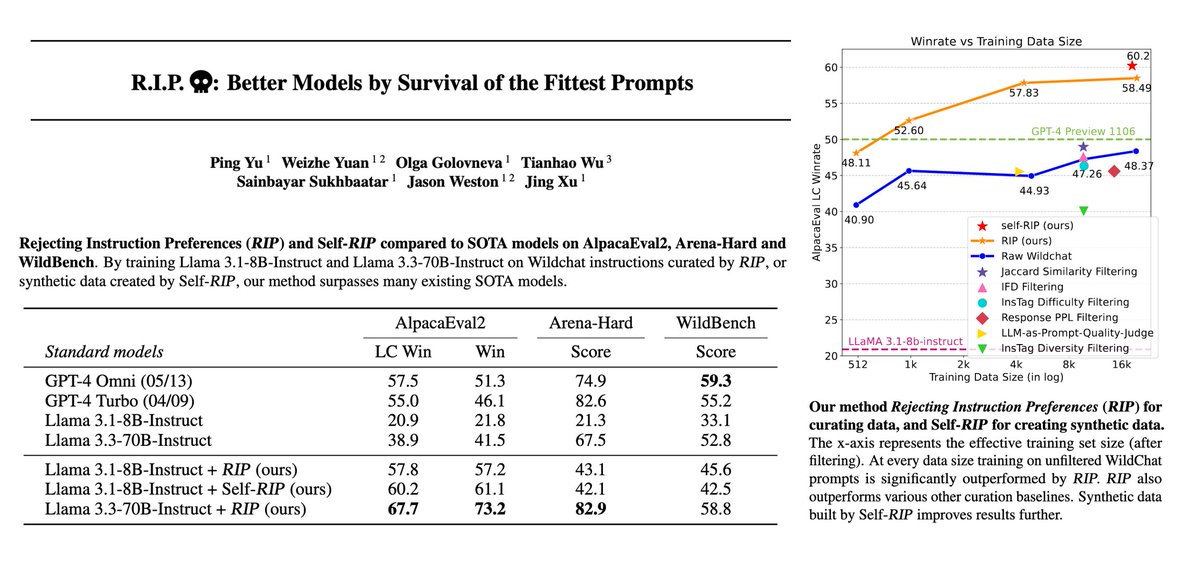
0
5
19
Two of our papers are featured in this: Self-Rewarding LLMs and Thinking LLMs

No Hype DeepSeek-R1 Reading List
1
1
22
I think Transformer-XL paper was also rejected, but now it has over 4k citations. There are many examples like this

Disappointed with your ICLR paper being rejected? Ten years ago today, Sergey and I finished training some of the first end-to-end neutral nets for robot control 🤖 We submitted the paper to RSS on January 23, 2015. It was rejected for being "incremental" and "unlikely to have much impact" Our resubmission to NeurIPS was also rejected It now has >4,000 citations (and more importantly, end-to-end training is widely accepted!) It's also cool to think about what's changed and what's the same -- - The network was 92k parameters and trained on ~15 minutes of data - The code was a combination of matlab, caffe, ROS, a custom CUDA kernel for speed, and a low-level 20 Hz controller in C++, all talking to each other. ROS+matlab was as bad as it sounds. - We pre-trained the encoder and did inference off-board on a workstation with a larger GPU. - We were paranoid about varying lighting messing up the network, so we did all the experiments after sunset (so long nights running experiments on the robot past 3 am) Now, we have manipulation policies that are far more dextrous, far more generalizable, and maybe on the cusp of breaking into the real world. :) (the paper:
0
0
8
RT @armandjoulin: Today I had the great idea of doing chain of thoughts in the continuous space. I know it's a great idea because @jasewest…
0
55
0
A new work! It’s about reasoning in continuous vector spaces instead of words

Training Large Language Models to Reason in a Continuous Latent Space Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT) Extremely simple change: instead of mapping between hidden states and language tokens using the LLM head and embedding layer, you directly feed the last hidden state (a continuous thought) as the input embedding for the next token. The system can be optimized end-to-end by gradient descent, as continuous thoughts are fully differentiable.

0
2
10
RT @Ar_Douillard: Adaptive Decoding via Latent Preference Optimization: * Add a small MLP + classifier which pred…
0
35
0
Did you know that you can use DPO for things other than tokens? How about temperature? We just did that. Now the model selects an ideal temperature on its own.
🚨 Adaptive Decoding via Latent Preference Optimization 🚨 - New layer added to Transformer, selects decoding params automatically *per token* - Learnt via new method, Latent Preference Optimization - Outperforms any fixed temperature decoding method, choosing creativity or factuality automatically 🧵1/4

1
13
71
What is important for learning? Consistency 😉. A new work from our team! Consistency improves test performance, but it can also be used for training in an unsupervised way.
🚨 Self-Consistency Preference Optimization (ScPO)🚨 - New self-training method without human labels - learn to make the model more consistent! - Works well for reasoning tasks where RMs fail to evaluate correctness. - Close to performance of supervised methods *without* labels, beats them *with* labels. - Improves over RM training (MATH, GSM8K, ZebraLogic). - On ZebraLogic, ScPO trains Llama-3 8B to be superior to larger LLMs like Llama-3 70B, Gemma-2 27B, and Claude-3 Haiku. 🧵1/5
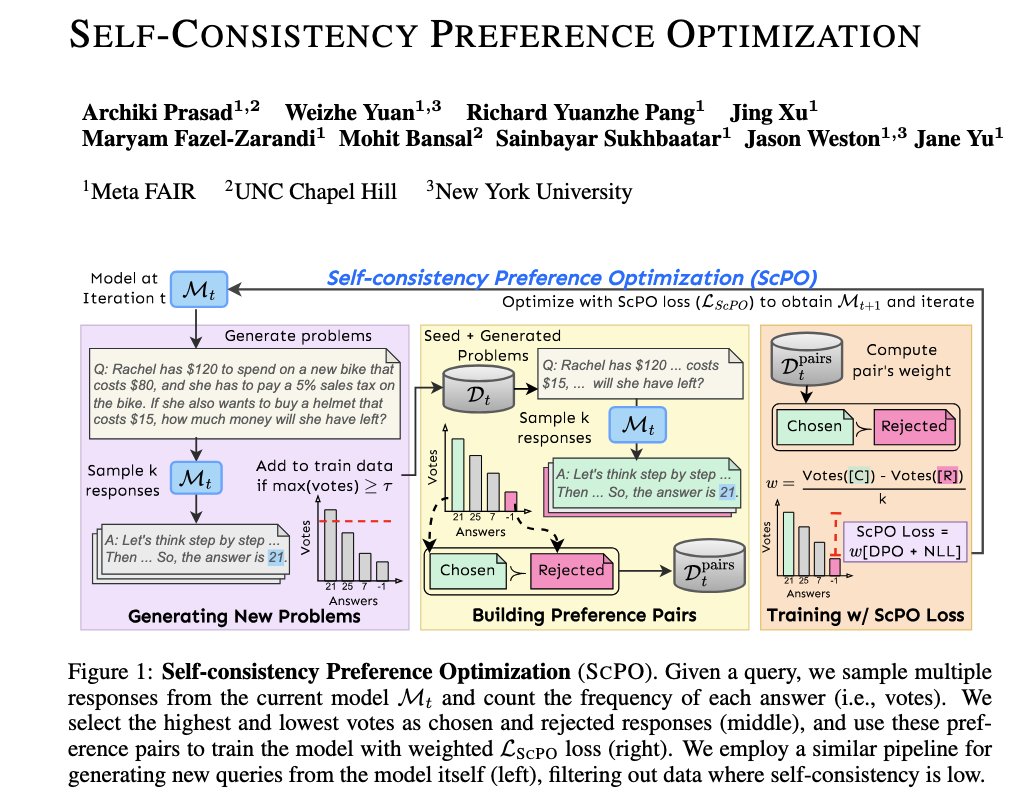
0
6
31
RT @jaseweston: 🚨 Self-Consistency Preference Optimization (ScPO)🚨 - New self-training method without human labels - learn to make the mode…
0
101
0
Robotics is definitely the next frontier. Imagine robots as smart as LLMs
🤖🧠
0
0
4
Some unseen relations can be inferred, so it becomes possible to generate multi-step reasoning questions

0
0
0
RT @srush_nlp: I'm putting together a quick reading list of papers related to o1 & test-time scaling for grad students following this area.…
0
119
0
If you don't want to read, conveniently someone made a podcast out of it (using AI of course)
0
1
8