
Sergey Pozdnyakov
@spozdn
Followers
276
Following
218
Statuses
107
PhD student at EPFL | Geometric deep learning on 3D point clouds for atomistic modeling
Lausanne
Joined May 2023
RT @marceldotsci: the recording of the talk i gave a while back about the "invariance is easy to learn" paper with @spozdn and @MicheleCeri…
0
3
0

RT @lab_COSMO: Join the dark side of the forces (or not!). TL;DR - Using forces that are not conservative is not a great idea. Latest and g…
0
9
0
RT @ADuvalinho: ⚛️🤗 Announcing LeMaterial ⚛️🤗 @huggingface & @entalpic_ai are teaming up to release LeMaterial -- an open source initiativ…
0
26
0
RT @valence_ai: We curated 40+ quantum mechanics datasets covering 250+ quantum methods & 1.5B geometries. All of this is easily accessible…
0
16
0
It was a lovely symposium! Enjoyed it much


0
1
11

0
3
0
RT @kabylda_: Couldn't have asked for better timing #NobelPrize Our new work on 'Molecular Simulations with a Pretrained Neural Network a…
0
40
0
RT @MarkNeumannnn: Our technical report from the team at @OrbMaterials is now on Arxiv: Feedback welcome - a remi…
0
11
0
RT @MLSTjournal: Great new work by @marceldotsci @spozdn @MicheleCeriotti @lab_COSMO @nccr_marvel @EPFL_en - 'Probing the effects of broken…
0
10
0
RT @MarkNeumannnn: We are hosting a November Seminar Series at @OrbMaterials! We have 2 scheduled talks (with a third coming soon), featuri…
0
6
0
RT @marceldotsci: accepted now in @MLSTjournal! final manuscript, scripts, and data coming soon.
0
7
0
Remarkable empirical evidence of the efficiency of unconstrained models!

We are using a simple architecture, augmented with attention, so these models scale very well (5x faster than MACE with a system of 10k atoms). In particular - our models are NOT equivariant. Our models hopefully show that this is a modeling choice, not a requirement for Matsci.
0
0
10
RT @lab_COSMO: A summer treat from Filippo Bigi and @spozdn, now published on @JChemPhys. Fully local, kernel based #ML potentials that mat…
0
9
0
RT @MLSTjournal: Great new work by @LinusKellner and @MicheleCeriotti @lab_COSMO @Materials_EPFL - 'Uncertainty quantification by direct pr…
0
11
0
RT @lab_COSMO: 🌶️🌶️🌶️ how I learned to stop worrying and let #machinelearning models learn 🌶️🌶️🌶️ 🧑🚀 #preprint just landed on the @arxiv:…
0
18
0
RT @marceldotsci: well… @spozdn and @MicheleCeriotti and I had a look: In this, we check what exactly non-invaria…
0
10
0
In atomistic machine learning structure = equivariance (most of it) 👀

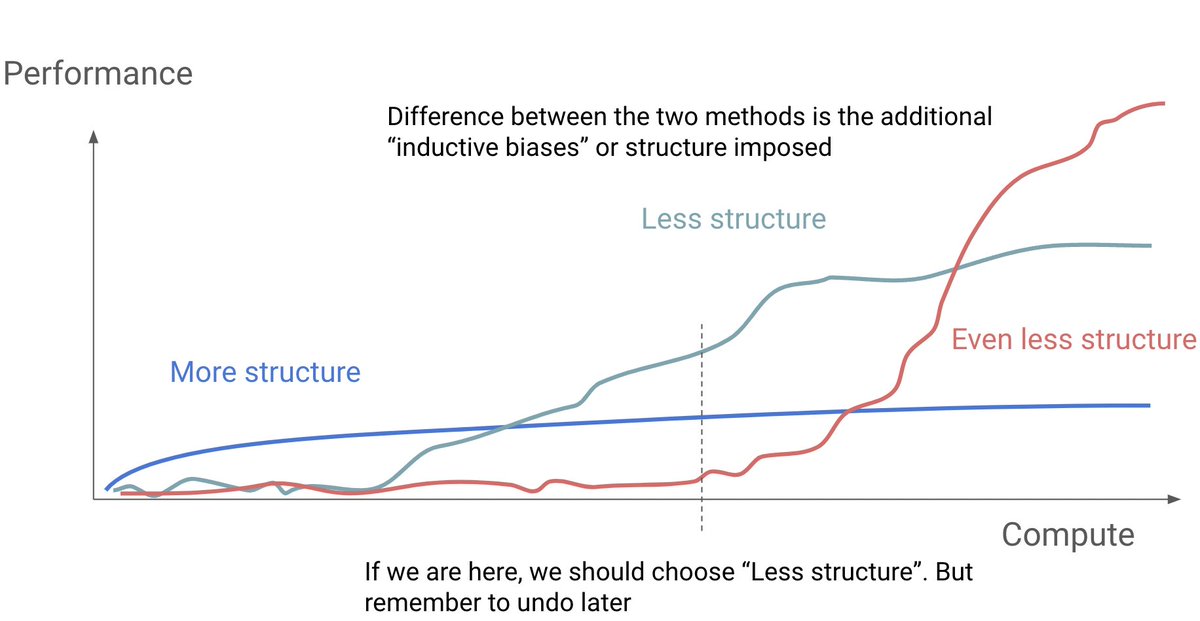
I gave a lecture at @Stanford CS 25. Lecture video: AI is moving so fast that it's hard to keep up. Instead of spending all our energy catching up with the latest development, we should study the change itself. First step is to identify and understand the dominant driving force behind the change. For AI, a single driving force stands out; exponentially cheaper compute and scaling of progressively more end-to-end models to leverage that compute. However this doesn’t mean we should blindly adopt the most end-to-end approach because such an approach is simply infeasible. Instead we should find an “optimal” structure to add given the current level of 1) compute, 2) data, 3) learning objectives, 4) architectures. In other words, what is the most end-to-end structure that just started to show signs of life? These are more scalable and eventually outperform those with more structures when scaled up. Later on, when one or more of those 4 factors improve (e.g. we got more compute or found a more scalable architecture), then we should revisit the structures we added and remove those that hinder further scaling. Repeat this over and over. As a community we love adding structures but a lot less for removing them. We need to do more cleanup. In this lecture, I use the early history of Transformer architecture as a running example of what structures made sense to be added in the past, and why they are less relevant now. I find comparing encoder-decoder and decoder-only architectures highly informative. For example, encoder-decoder has a structure where input and output are handled by separate parameters whereas decoder-only uses the shared parameters for both. Having separate parameters was natural when Transformer was first introduced with translation as the main evaluation task; input is in one language and output is in another. Modern language models used in multiturn chat interfaces make this assumption awkward. Output in the current turn becomes the input of the next turn. Why treat them separately? Going through examples like this, my hope is that you will be able to view seemingly overwhelming AI advances in a unified perspective, and from that be able to see where the field is heading. If more of us develop such a unified perspective, we can better leverage the incredible exponential driving force! Slides:
0
0
5
RT @tis930: Our latest paper at @lab_COSMO on the thermal conductivity of LPS solid-state electrolytes is out on @PhysRevMater
https://t.co…
0
13
0