

Rohan Nuttall
@rohancalum
Followers
1K
Following
5K
Statuses
629

a step towards fixing bloom’s 2 sigma problem — inspiring results extending the reach of teachers with AI: “nearly two years of typical learning in just six weeks”

New randomized, controlled trial of students using GPT-4 as a tutor in Nigeria. 6 weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interventions. And it helped all students, especially girls who were initially behind


0
0
4
RT @tszzl: LLMs are truly at a level where people have life changing conversations with them every day. we better build intelligent machine…
0
78
0
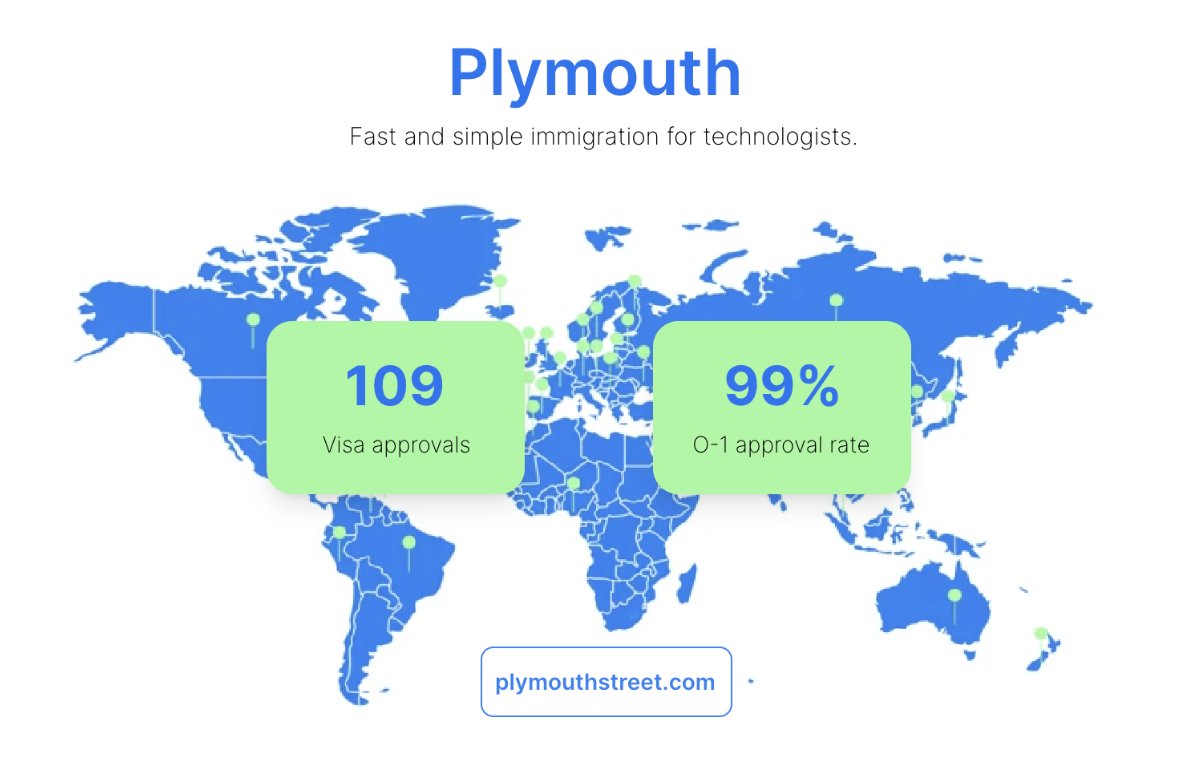
Remarkable results from @lisawehden and team. Accelerating the arrival of global talent to America is important for so many reasons.

Excited to announce that @plymouthstreet has achieved over 100 O1 and EB1 US work visa approvals for extraordinary individuals to build here in America.
1
0
10
sora generates some fun looking single track.. incredible, inspiring work by the @OpenAI team:
1
1
31
“It’s like you’re thinking with the internet”... such powerful features and a wonderful story about the future of browsing. Congrats @joshm and team!

0
0
19
Fantastic curriculum of RAG techniques in a single tweet.

here are some basic → advanced strategies that I see for optimizing RAG implementations these days: basic 1. using effective prompt eng, templating, and conditioning. eg: “given the context information and no prior knowledge, answer the query..” etc. ok, we've all done some pretty aggressive prompt engineering. 2. understand the challenges: don’t overoptimize and first really identify common issues with retrieval, augmentation, and generation. you always want to start simple. simplicity is sexier. 3. choose the right chunk size: determine the optimal chunk size for your data to ensure efficient processing and retrieval. chunk overlaps don't always work; use smaller chunks? 4. using summaries for data chunks: apply summarization techniques to data chunks to provide the model with a concise representation of the information 5. data, data, and data: carefully managing, scrutinizing, versioning, and cleaning data sources and pipelines. quality > quantity. garbage data, garbage r-a-g. 6. evaluating retrieval: this can include 1/assessing retrieval performance by measuring the proportion of relevant documents retrieved (precision) and all relevant documents retrieved (recall) and 2/ integrating human-in-the-loop evals/feedback and basic evaluations. think about use-case-specific evaluation metrics. 7. evaluating generation: evaluating faithfulness and answer relevancy using something like ragas or a custom-built eval framework. 8. the enlightening realization that you don't always need a vector db or just appreciate simpler options like pgvector intermediate 1. metadata filtering: adding meta-data to the chunks to help process results. remember: similar ≠ relevant. this could also include filtering by relevancy. be careful about metadata, tho. 2. managing embeddings: strategies to handle frequently updated or newly added documents; challenges include incremental indexing and dynamic document ranking. 3. trustworthiness: using citations/attributions and employing techniques such as confidence estimation, uncertainty quantification, and error analysis to ensure the accuracy and trustworthiness of the generated content; sooner or later, thinking about "answerable probability" + "I don’t know" problems for retrieval. 4. leverage hybrid search techniques or other index types: integrate different search techniques, such as keyword-based and semantic searches (eg: bm25). again, similar != relevant for your use case. 5. apply query transformations: modify the user's query to better match the information needed from the data sources. users don’t always know what they want. query transformations can include strategies like hypothetical document embeddings which take a query, generate a hypothetical response, and then use both for embedding lookup 2/ decomposing the original query into multiple sub-queries or questions and 3/ iteratively evaluating query for missing information, and generate response once all information is available. 6. trade-offs: considering trade-offs between precision, recall, computation/cost to optimize the retrieval and generation process 7. advanced chunking strategies: experiment with different chunking strategies, such as sentence window retrieval and auto-merging retrieval to improve precision and relevance; there's a lot here? 8. re-ranking: re-rank (reordering the retrieved documents) the retrieved documents based on their relevance to the user's query. you can also combine multiple retrieval techniques and reranking strategies to improve the overall performance. advanced 1. fine-tune the model and/or the embeddings: either continue the training process on a smaller, more specific dataset to optimize performance or fine-tune to better represent the relationships between data points. fine-tuning on domain-specific datasets can sometimes help the generator understand the context the retriever provides. 2. customize embeddings using labeled training data: the approach involves creating a matrix that you can use to multiply your embeddings. the product of this multiplication is a 'custom embedding' that will better emphasize aspects of the text relevant to your use case." 3. query routing: have more than one index or tool then route sub-queries to the appropriate index or tool/function call. 4. multi-retrieval: combining the results from multiple retrieval (and generator?) agents to improve the overall quality and fidelity. 5. contextual compression and filtering: apply compression techniques to reduce the size of the context while preserving its relevance, and use filtering to select the most relevant information for the model 6. self-querying: use the model's output as a query to retrieve more information, which can be combined with the initial response to generate a more truthful answer 7. document hierarchies and knowledge graphs: use document hierarchies and knowledge graphs to improve the organization and retrieval of information. this could also include combining the strengths of both knowledge graphs with vector db. I’ve also seen folks leveraging knowledge graphs to improve the interpretability/explainability. let's go build.
0
0
7
@biggerthanx @OpenAI @biggerthanx sorry for the trouble here. This is definitely a frustrating experience. Would you mind sending me a DM with your org ID? Will look into this for you :)
0
0
0
The @streamclimate team is onto something special. Very inspired rewatching @HelenaMerk’s AI Frontiers talk
1
4
23
We’re back.

Returning to OpenAI & getting back to coding tonight.
0
1
34
Voice is now available to all. Never doubt, we’ll keep shipping.

ChatGPT with voice is now available to all free users. Download the app on your phone and tap the headphones icon to start a conversation. Sound on 🔊
1
2
52
@theashbhat @vkhosla @eshear @OpenAI @theashbhat our commitment to customers remains unwavering and steadfast. Engineering remains on-call and the stability of our services actively monitored. You are our top priority.
0
0
5
