
Rajan Vivek
@rajan__vivek
Followers
133
Following
143
Statuses
22
Member of Technical Staff @ContextualAI. MS CS + AI researcher @stanford. Prev @scale_AI @georgiatech
Joined July 2023
@LangChainAI This is awesome work! For more accurate unit testing, you can swap out gpt-4o-mini for LMUnit, a SOTA unit test scoring model with a free API. (Outperforms gpt-4o and sonnet 3.5) Check it out here
0
0
0
@HamelHusain Check out LMUnit, a state-of-the-art model for LLM unit testing with a free API! It’s more accurate than GPT-4o and Sonnet 3.5
0
0
3
SOTA performance at every step of the RAG pipeline (and end to end) is crazy. Major props to the @ContextualAI team Also super excited about RAG agents that do tasks on your behalf! (see the spreadsheet example towards the end)

Today, we’re excited to announce the general availability of the Contextual AI Platform. This is the first enterprise platform designed for building specialized RAG agents to support expert knowledge work. What is a specialized RAG agent? First, a general-purpose AI agent is one designed to automate simple daily tasks like scheduling a meeting or responding to an email. On the other hand, a specialized RAG agent is one designed to augment subject-matter experts performing complex domain-specific work. The Contextual AI Platform allows you to create these agents easily and achieve SOTA accuracy right out of the box. Check out what the Contextual AI Platform can do.
0
0
13
Truthfulness in AI isn't one-size-fits-all. For some applications, truth is certain and computationally verifiable (math/logic) but for others it can be anything supported by a trusted source (search/RAG). Instead of a universal benchmark, we need a new evaluation paradigm— natural language unit tests, where each aspect of truthfulness is a testable assertion that humans can define and refine over time for their specific application. We tackle this in our new paper and just released a free API for LMUnit, our SOTA unit test scoring model outperforming GPT-4/Claude (. Would love to hear your thoughts on this paradigm @chamath
0
0
1
We’ve known for awhile that LLM evaluation is broken in many ways (biased, noisy, not that correlated w/ vibe checks). Our latest release at @ContextualAI is a huge step towards fixing this— natural language unit tests! We also trained a SOTA model to go with it :) Check it out!
Introducing LMUnit: Natural language unit testing for LLM evaluation How do you really know if your language model is behaving the way you expect? When evaluation is this critical, your best methodology shouldn't just be vibes. With SOTA results on FLASK & BigGenBench and top-10 on RewardBench, LMUnit brings the rigor and familiarity of traditional software engineering unit testing to LLM evaluation. Read on to learn how we built it and try it for free using our API 👇 🔗 🧵 (1/5)
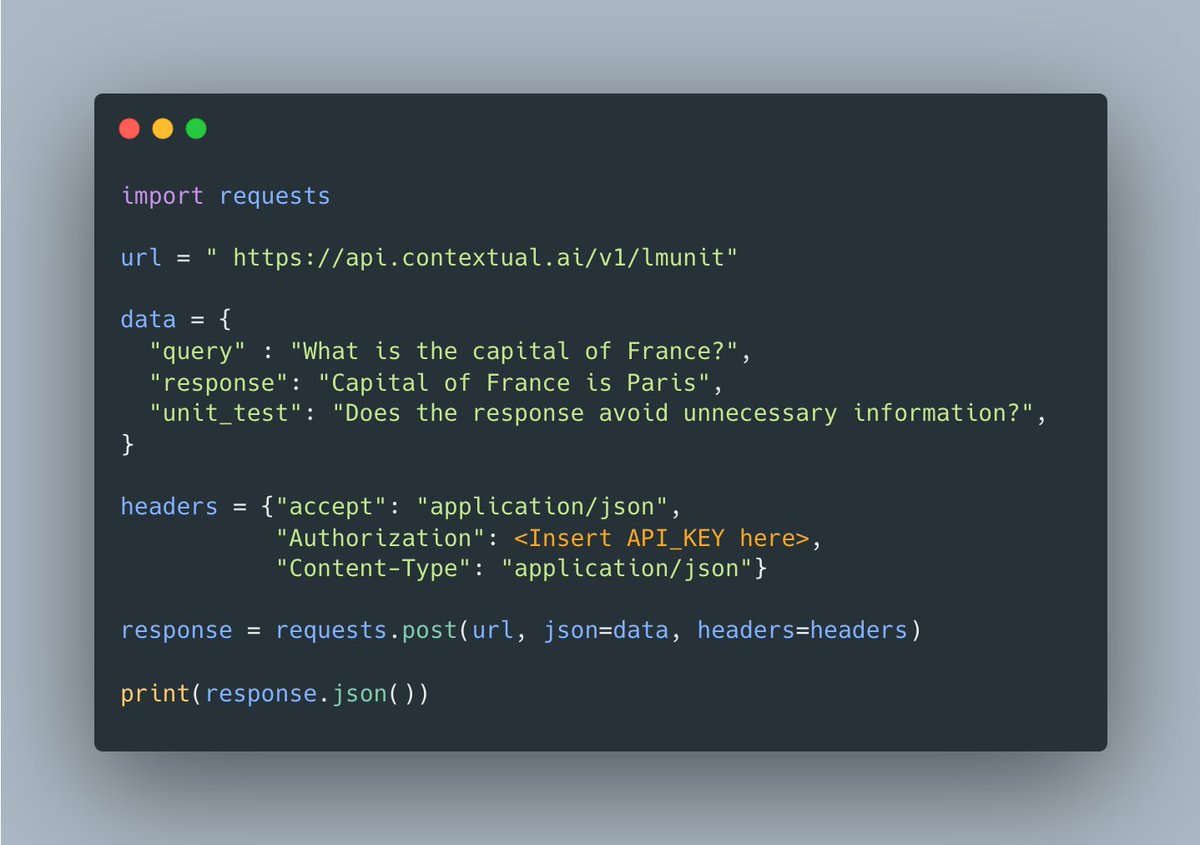
0
2
12
When we align AI with algorithms like DPO, we tell the model “solution A is better than solution B.” But this doesn’t specify exactly what about A is better than B. Can we do better with more precise preferences? Yes! Check out this great work by @KarelDoostrlnck @ContextualAI

Aligning Language Models with preferences leads to stronger and safer models (GPT3 → ChatGPT). However, preferences (RLHF) contain irrelevant signals, and alignment objectives (e.g. DPO) can actually hurt model performance. We tackle both, leading to a ~2x performance boost.
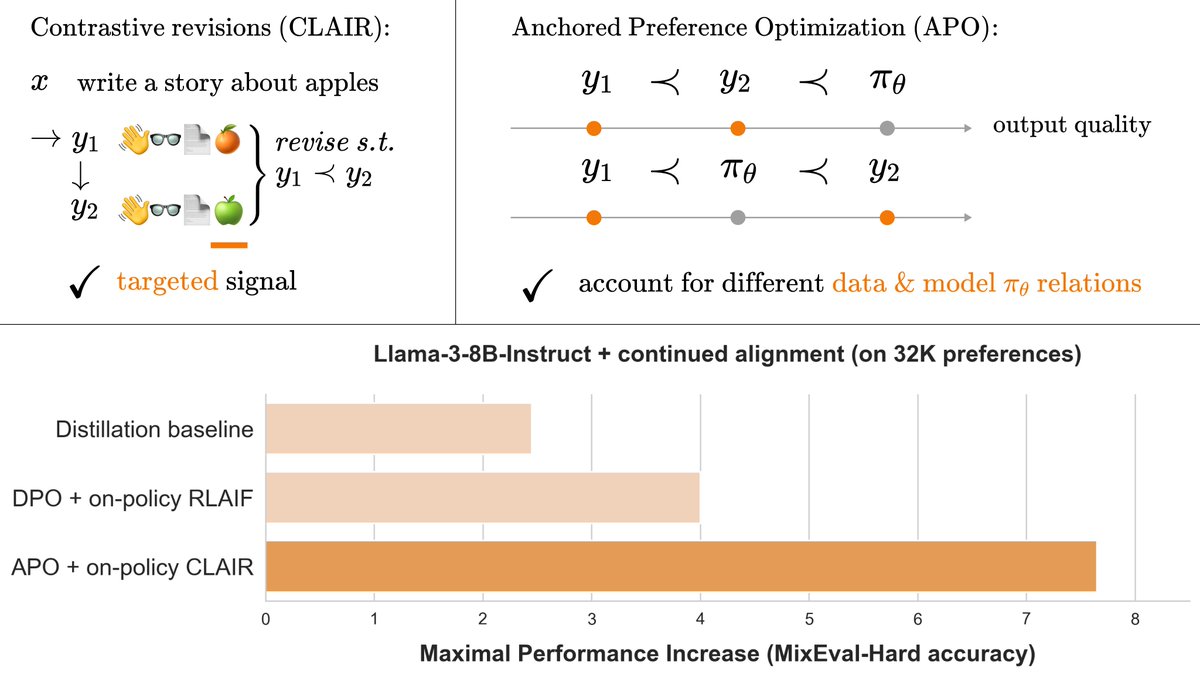
0
0
4
The next generation of RAG! Check out this awesome work by the @ContextualAI team
Today, we’re excited to announce RAG 2.0, our end-to-end system for developing production-grade AI. Using RAG 2.0, we’ve created Contextual Language Models (CLMs), which achieve state-of-the-art performance on a variety of industry benchmarks. CLMs outperform strong RAG baselines built using GPT-4 and top open-source models like Mixtral, according to our research and customers. Read more in our blog post:

0
0
16
RT @johnrso_: What is the best way to learn behaviors from videos? By modeling point trajectories, our method, ATM, helps robots learn even…
0
19
0
RT @ContextualAI: Correct licensing and attribution is critical when building LLMs for enterprise customers. Here at Contextual we care a l…
0
7
0
Big shoutout to @kawin, @Diyi_Yang , and @douwekiela for advising this work! Checkout the paper here: (11/11) @stanfordnlp @StanfordAILab
2
3
14