

Prakhar Ganesh
@prakhar_24
Followers
42
Following
78
Statuses
35
PhD @ McGill and Mila | Interested in Responsible AI and Revenge
Joined May 2017
RT @afciworkshop: TODAY it is time for the Algorithmic Fairness Workshop #AFME2024 at #NeurIPS2024! 📍West Meeting 111-112! Excited for ou…
0
4
0
RT @yash_347: 1/ 🚨 How vulnerable are large language models (LLMs) to extraction attacks? Our paper (presented at ACL PrivateNLP) explores…
0
6
0
RT @nandofioretto: 🆘Help needed! Are you working on Privacy (from a Technical (e.g., Differential Privacy), Policy, or Law perspective)?…
0
14
0
RT @yash_347: 1/ 🚨 Large Language Models (LLMs) like ChatGPT are changing our daily workflows, but what are the hidden costs? At COLM 2024,…
0
7
0
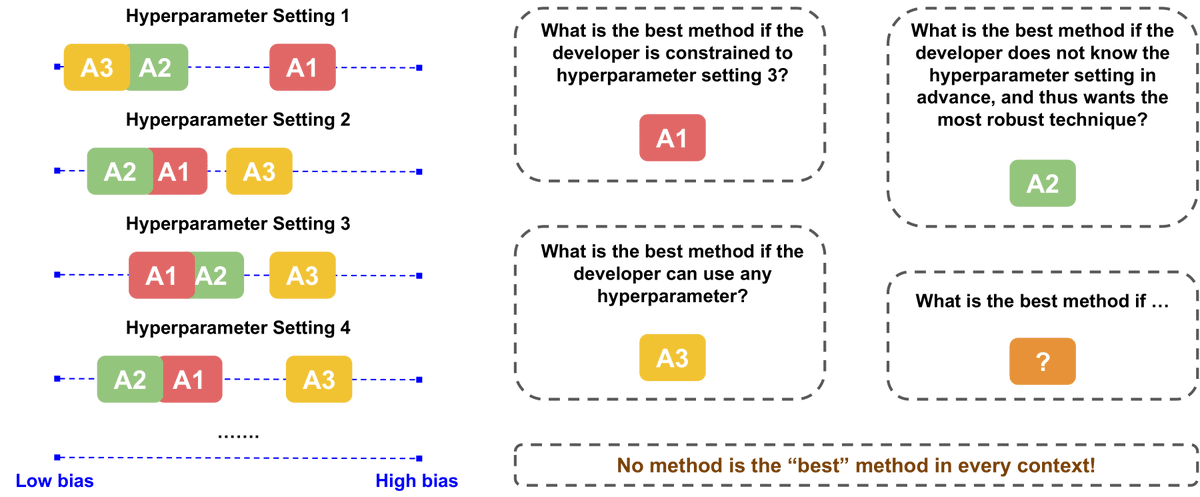
What's the best bias mitigation algorithm? There isn't one! Benchmarks often miss critical nuances. In our latest paper, we unpack these pitfalls. Critical work w/ @UsmanGohar , @luchengSRAI , @gfarnadi 🔥Spotlight @afciworkshop @ NeurIPS 2024 📰
1
6
14
RT @nandofioretto: Excited to share our work on data minimization for ML! The principle of data minimization is a cornerstone of global d…
0
9
0
@savvyRL Federated learning? It might be a "models that aren't trained with data"-adjacent topic, if not exactly what you have in mind.
0
0
0
@savvyRL As for how powerful are they, this table might help..

Is your BERT-based NLP model too big / slow / power-hungry for mobile devices? Read our new TACL paper on SOTA methods for compressing Transformers

1
0
4
RT @sama: ChatGPT is incredibly limited, but good enough at some things to create a misleading impression of greatness. it's a mistake to…
0
3K
0
RT @SashaMTL: We need to stop conflating open/gated access and opensource. ChatGPT is *not* open source -- we don't know what model is und…
0
127
0
RT @beenwrekt: It's deeply depressing that the killer app of contemporary machine learning is bullshit generation.
0
202
0
RT @nazneenrajani: Here's hoping I don't need to update this slide again before my talk next week @emnlpmeeting If anyone is planning to…
0
78
0
RT @NeurIPSConf: The preliminary list of accepted #NeurIPS2022 workshops is out! No matter whether you are attending in person or virtually…
0
30
0
RT @KLdivergence: Evaluating subgroup disparities in ML shouldn't only be a "fairness" thing. It should be ML/data science best practice in…
0
46
0
RT @dpkingma: Generative models (such as Dall-E 2 and PaLM) are becoming just such an insanely powerful, almost magic-like technology, it's…
0
325
0
@vitalyFM @Mitchnw @ChrSzegedy @KevinScaman @Kangwook_Lee @RohYuji @fhuszar @trustworthy_ml Day 11 : Wow!! I'm gonna need some time to digest counterfactuals😅Maybe those recommended readings will help! Nevertheless, great talk🙌!! @fhuszar
0
0
0