

Nishith Rastogi
@nishith_rastogi
Followers
2K
Following
1K
Statuses
3K
AI is the new UI. Founder & CEO at https://t.co/tL5rJnTyHq
London, United Kingdom
Joined February 2007
Do things worth failing at!

“Do not make any small plans, because it cannot inspire the soul” - John D. Rockefeller
1
1
1
RT @TheRealDanSaedi: They should let you airdrop off a flight early if you don’t have checked bags

0
1
0
RT @arthurmensch: Self-qualifying oneself as heavyweight while shipping nothing of significance looks like hubris to me
0
103
0
Mr. Bean son enlisted in the elite Gurkha unit, wow! He went and learned Nepali, and the full cultural deal. Awesome! Also, before the ads, the internet looked like the link above!
0
0
0
Food delivery apps, especially when opening for first time in a new city, should have a “Too Tired to Order but Hungry” button. Take my history of orders, match it with currently available restaurants and menu, & give a one click order interface.
0
0
2
RT @deeppurpled: Ultrahuman's annual report 2024 is here! Revenue grew 6x, we turned profitable and launched Ring AIR in 2200+ stores world…
0
45
0
0
1
2
Zuck added Dana White to Meta Board, and it is only Jan
0
0
1
RT @dieworkwear: For someone more contemporary, check out Amitabh Bachchan. The Bollywood actor sported knits-on-knits, suits with flared t…
0
128
0
RT @elonmusk: @JeffBezos That said, I hope you do hold an epic wedding. It’s nice to know that epic events are happening somewhere in the…
0
512
0
@jdkanani Text makes it easier to think. I often go back to start of prompt/essay to edit, after I have written the second half. Voice makes that hard, without a representation of everything spoken till then, at which point it is text.
0
0
1
We don't articulate at rate of voice, versus writing in text. I often go back to start of prompt to edit, after I have written the second half. Voice makes that hard, without a representation of everything spoken till then, at which point it is text.

I think there's a good chance AI voice will end up being as big or bigger than AI text. A conversation is the precursor to decisions/actions for humans just as often as text, so it makes sense that this will be central for AI too.
1
0
2
A small routing game, right in your browser

Step into Santa’s boots, plan the perfect delivery route, and spread holiday cheer to every home in the neighborhood. Can you light up all 7 Christmas trees before your fuel runs out? Let’s find out! Play The Santa Way now! Ho ho ho! Let the fun begin!
1
0
1
7 months ago, I had my first child at 36. This is a question, I had been asking myself in the couple of years leading up to it. Especially, as I had a great happy childhood, and owe large parts of present day success to parents. The core difference, was that we were raised to raise the floor we will ever fall to, while with the cushion of our resources, we can push our child to only focus on breaking the ceiling.
1
0
2
This could be very relevant by next year as on device inference increases

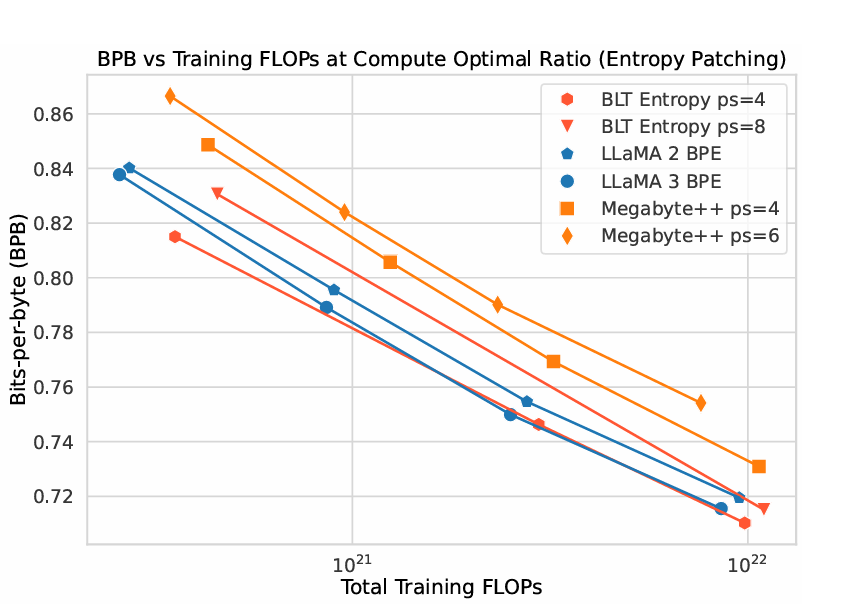
META JUST KILLED TOKENIZATION !!! A few hours ago they released "Byte Latent Transformer". A tokenizer free architecture that dynamically encodes Bytes into Patches and achieves better inference efficiency and robustness! (I was just talking about how we need dynamic tokenization that is learned during training 🥲 It's like fucking christmas!) I don't want to talk too much about the architecture. But here's a nice visualization from their paper. Let's look at benchmarks instead :) "BLT models can match the performance of tokenization-based models like Llama 3 at scales up to 8B and 4T bytes, and can trade minor losses in evaluation metrics for up to 50% reductions in inference flops!" This is basically a perplexity vs training flops chart - scaling laws with compute. BPB is a tokenizer independent version of perplexity. BLT is on par or better than LLama 3 BPE! Most importantly they scale this approach to train Llama-3 8B model on 1T tokens which beats the standard Llama-3 architecture with BPE tokenizer!



0
0
0

0
10K
0