
@邹扒皮.com
@mdjxyz
Followers
913
Following
737
Media
149
Statuses
1,703
云计算仁波切 顺义分切| 练习时长两年半的 K8S 练习生| 现 在线教育客服| 前 大象卷王| 前 民生皇协军| 前 SenseTime ansible 研究院首席研究员| 前 QingCloud Top 50 研发
北京
Joined December 2012
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
الهلال
• 621356 Tweets
River
• 262089 Tweets
Dubois
• 109012 Tweets
Román
• 94325 Tweets
Michigan
• 93493 Tweets
Romero
• 81875 Tweets
Riquelme
• 75316 Tweets
Gallardo
• 73411 Tweets
#precure
• 53768 Tweets
Oklahoma
• 47930 Tweets
#仮面ライダーガヴ
• 34992 Tweets
Iowa
• 31536 Tweets
Tennessee
• 31397 Tweets
Janet Jackson
• 29833 Tweets
秋分の日
• 29210 Tweets
秒速5センチメートル
• 25399 Tweets
Auburn
• 21954 Tweets
#ブンブンジャー
• 17714 Tweets
ショウマ
• 12880 Tweets
Usyk
• 11205 Tweets
ダブルドライバー
• 11162 Tweets






















隔壁组新来的老哥之前刚好也是做K8S的,问我一大堆关于K8S的问题,为什么不用X组件,人力不够呗,现在天天查问题就已经焦头烂额了。根本搞不定呀。他说从上家公司走是因为那边技术差。我想那他可是真来对地方了,让他见识一下什么叫技术差。顺手把接入层平台甩给他管了。让他震撼一下。😂
4
1
62
也不知道多写一些文章对以后失业了找工作有没有帮助。感觉找工作太难了。分享一篇一月份遇到的一个 K8S 低版本上的bug。

2
0
36
太强了,关于session 同步那短当年我就是不知道[浮动路由] 这个概念,纠结了好久,然后摇了人,最后才明白的。😂


2
2
29
时隔一年半为了玩游戏把开发环境从linux切换回了windows。直接吧之前linux的home挂了过来就能用了。可能之后最好的linux发行版本就是windows了。

1
0
27


贵司的大监控团队做出的产品用抽象这个词都没有办法形容。原来一个人维护的时候,我所有的指标接入有个管理平台。我点一点就接入了。现在,得让我给他们讲一遍,让后让我提供接口。最后还会把指标变成私有的形式,不支持promql。求爷爷告奶奶,让他们支持人家只说考虑。😬
3
0
16
也尝试分析了一下这个问题,虽然我中间踩了不少的坑。但是交给kimi的话就直接给秒了。
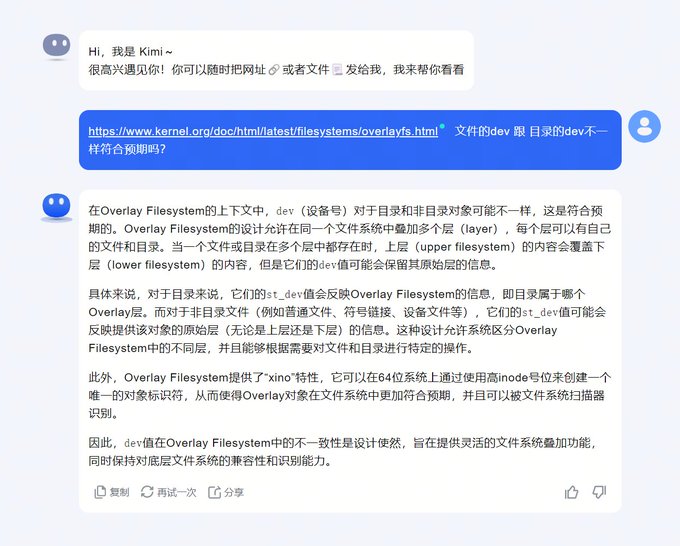

昨天遇到了一个操作系统结合虚拟化的问题,在docker中创建文件夹(dir)和创建文件(touch)所属的device(stat命令)不一致,复现了是系统的差异,今天就有小伙伴从源码层面找出来了具体的原因。所以加入
@plantegg
星球不仅仅可以学深入底层的知识,还可以有一群很厉害的人与你一起学习帮你解决问题。
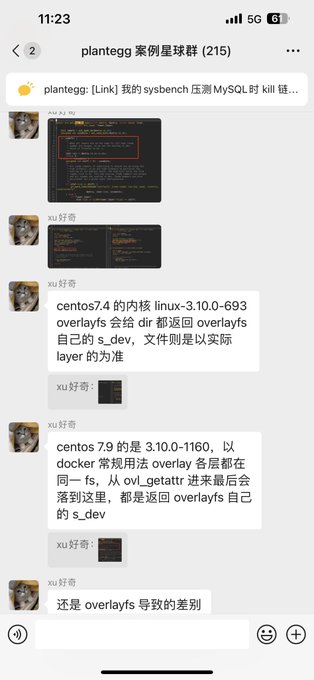
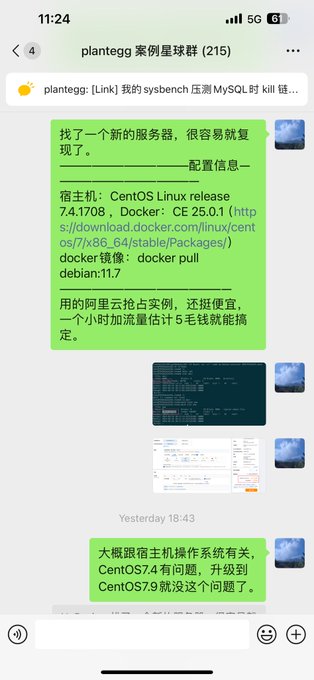
3
1
24
2
0
17


闯了一波祸,上周老板在研究把一些卡换成A800,让我统计了一些数据。最后算了一波大概要X台8卡的A800,然后老板跟他的老板吹了一波说一年能省几千万,结果今天我发现我给错数了。大体上只有X/3~X/2的卡能替换。🤣
1
0
9

回家养大鹅

This man resigned from Microsoft after 22 years, just to become a farmer 😭

1K
6K
56K
1
0
9

今天去开西替利嗪, 跟医生多聊了一会,然后医生跟我说他家小朋友比较容易过敏,但从来不吃国产的抗过敏药,都在网上买原研/进口的开瑞坦或者仙特明。就顺义这边所有的医院都没有这两个药。要买就只能网上自费,感觉这医保都白交了。仙特明3块一片,给我开的国产的2块多一盒。也不知道管不管用。🤣
5
1
8


@laixintao
这个bug依赖于openat2这个调用,如果没有的话则不会触发。可以提前看一下。复现的过程中网友还提供了个小技巧直接–w /proc/self/fd/xxx挂载proc命令,这样不用构建镜像了

0
0
7

以上指的是指metrics产品,tracing跟log是能正常使用的,而且作为内部产品算是合格的。
今天有个老哥问我们用哪个版本的k8s他们要梳理指标全部转换成自己定义的新指标。
😬
3
0
5
最近当客服当的实在心累,打算周一跟老板1:1的时候让他给我再整个全职的人打配合。虽然现在有两个兼职跟我一起搞事情的老师。但毕竟是兼职人家还有本职工作。😦
0
0
6

领导我求求你别追查用docker的事了。我做了三年开发,源码编译安装的Mysql/Nginx我搞了三年。项目被我搞延期了,公司被我搞黄了。现在好不容易有了docker。你们非说他占资源,性能差,生产不能用。能不能用我能不知道吗?你能保证一辈子不用docker吗。我项目不想延期,我想如期交付行吗?
2
0
5
下午让火山的vepfs坑了一下午,gpu升级驱动,重新加集群,之后vepfs就用不了了😬。刚才看完电影又发现pod一堆pending,一看vci某个区域没资源了。之前还特意聊了一下调度的时候能不能感知余量。说有,让后好像没起作用。😓

2
1
5

我个人觉得稳不稳定取决于
1.软件本身
2.硬件本身
3.部署方案
4.人
目前看硬件好像没厂商的可靠,
软件开源的没做啥优化,
最大的差异可能是3跟4。应该是部署方案/架构比厂商的更好或者人比厂商的更强。或者两者都有。
0
0
4
周五
@haoqixu_0o0
老师帮忙测了下eg 大体上1万规则生效时间在5min左右,我都惊了。期待优化的文章。😜

之前和读者聊到,“现在envoy用来做七层网关,要想达到好用,就差几个关键技术点没解决”。我决定开一个系列,不定期更新,写写 Envoy 目前还做得不够好的地方。 今天是第一篇,讲讲路由变更粒度。
3
11
55
1
3
4
今天风水不太好。早上出门做贵司一年四次的活动保障。出门到了地铁发现没带手机又回去取了。上午到公司第二波流量直接把DB打崩了。于是出现了我加入公司三年以来最大的一次故障。紧接着下午,阿里云新加坡C可用区down了。又花了几分钟把在C区的业务迁到了B区。周三还在讨论信不信算命。有点信了。😩
4
0
4
昨天陪亲戚看病算是开了眼了。加号到119号,一个屋里一个医生四个助理。一上午的门诊看到晚上。即使是像我这种一年在医院消费四十多次的人,也依然觉得很震撼。
北京最近非常缺血,住院啥的都要家属献血,用多少献多少。北京北站献血点基本都是积水潭跟北人过去的。🙈

2
0
4

@scnace
@VincentMucid
@ctengctsh
@flaneur2023
@plantegg
我是管集群的小卡拉米,需要预防类似的事件。出问题的集群在海外规模小,业务还在初期。如果国内也出现这种问题,我可能就要卷铺盖走人了,都是生活所迫。😭
2
0
4
@Sleepy93216599
最近在用tailscale,感觉还挺好有用的p2p打洞成功率非常高。自己有公网ipv4基本100%成功。双方都有ipv6也是100%成功。基本上能把家里上行的30多M带宽打满。
1
0
4
又j8让业务坑了一天,上来跟我说有个实例性能跟其他不一样,我从节能模式,主频,cache miss,看了一圈觉得不是容器的问题,最后开始pofile他们的代码,最后发现。开了个字节码增强,做无用代码统计。只在一个实例开,还是业务自己能控制的。🤡这个Q一个月已经过去了,OKR进展0。该让老板给我招小弟了
3
1
4
最终兵器


0
0
4
4 不要使用MySQL

数据库内核开发者给MySQL用户的三个建议:
1 不要使用任何的隐式类型转换
2 不要使用MySQL的隐式类型转换
3 不要使用任何MySQL的隐式类型转换
2
0
21
0
0
4
把买A100的钱充到openai里,能用到他公司倒闭。

有些公司真是服气的,说什么融了几千万要搞AI,找我去做规划
结果做了半天,我让买台双A100卡的机器,结果犹豫半天,开了几十个会,还是问能不能借用
我真是服了,这点钱都花不起,穷屌丝做什么AI,搬砖去啦
基本上没有8张A100卡,做个叼毛AI,扑街的
5
3
22
0
0
4






aws的eks我建了个集群。花了一周。当然这过程中有aws的外包(合作代理商),他们的sa(两位,一个整体,一个专门搞K8S的)。一起帮我研究。给我整到怀疑人生。😬

我用过多个国内公有云、AWS、Google Cloud,但登录azure云后,我居然花了5分钟在他们的页面上,还没有找到如何创建一台虚拟机的方法。。。我是不是有点菜。
40
1
85
1
0
3
@ctengctsh
@flaneur2023
@plantegg
实际上我确实是这么做的。我第一时间推给厂商看了。但是根本不解决任何问题。英文也搜了。并没有现成结论。我属于是躺平派但凡有一点办法我都不会自己查。😩求大佬轻喷。

0
0
3
草草得看了nginx-ingress-controller的代码,并不太喜欢。
但毕竟生产在用,读一下有个概括的认识。
0
0
2
去年糊了个训练平台,最近卡开始坏了,一共没多少卡,1个多月就损失了24卡,ECS团队还没备机。补不了。对比之下还是PAI团队牛逼,随随便便就能拿出千卡H800😂。
1
0
3


1
0
3