

Leland McInnes
@leland_mcinnes
Followers
5,864
Following
819
Media
79
Statuses
3,864
A mathematician dabbling in the world of data science. Researcher at the Tutte Institute for Mathematics and Computing. UMAP, HDBSCAN, PyNNDescent. He / Him.
Ottawa, Ontario
Joined October 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
ジェンティルドンナ
• 122735 Tweets
#Solingen
• 92556 Tweets
満塁ホームラン
• 87481 Tweets
大谷翔平
• 76911 Tweets
TO MAESTRO KHEM WITH LOVE
• 70486 Tweets
Brighton
• 66535 Tweets
#ラヴィットロック2024
• 48025 Tweets
史上最速
• 45225 Tweets
Vielfalt
• 40809 Tweets
#V最協S6
• 35877 Tweets
ML IN MACAU
• 32896 Tweets
ケンタッキー
• 29733 Tweets
Täter
• 29577 Tweets
Gabbar
• 29418 Tweets
大谷さん
• 28280 Tweets
Cemal Enginyurt Tutuklansın
• 27338 Tweets
Slogan
• 26155 Tweets
#FNTHWIN
• 26013 Tweets
Messer
• 25479 Tweets
悪役令嬢の中の人
• 24728 Tweets
グランドスラム
• 23699 Tweets
大谷選手
• 22243 Tweets
江戸川花火大会
• 19652 Tweets
Kアリーナ
• 18431 Tweets
オオタニサン
• 16940 Tweets
ALNP FANMEET IN HK
• 14985 Tweets
スーパースター
• 14206 Tweets
STRAY KIDS DOMINATE SEOUL
• 10845 Tweets





















Our paper on UMAP, a faster alternative to t-SNE, is now up on arXiv! The paper provides a more detailed account of the theoretical underpinnings of the algorithm, as well as performance benchmarks.
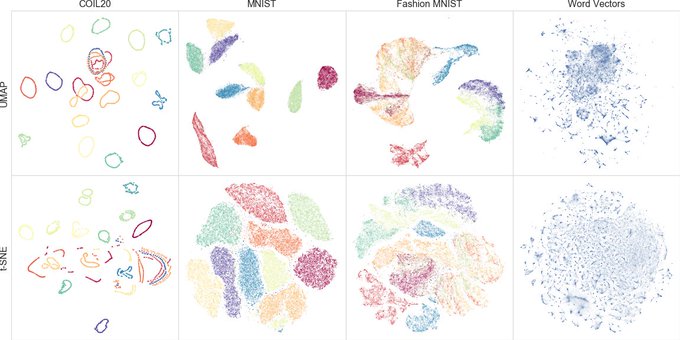

15
573
1K
The first release candidate for UMAP 0.4 is out providing lots of new features, including performance improvements, embedding to different manifolds, inverse transform, and plotting tools.

10
359
1K
The latest version of umap-learn is now out. Version 0.5 includes some major new features, including ParametricUMAP, DensMAP, AlignedUMAP, model composition, and model updating. Thank you to everyone who contributed! 1/14
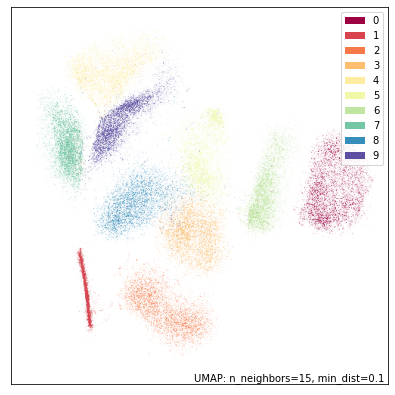
9
304
1K
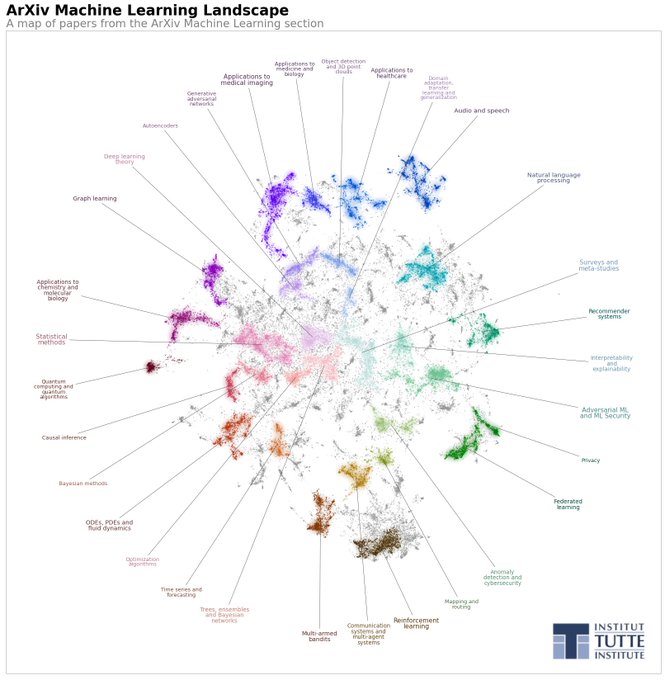
The landscape of the Machine Learning section of ArXiv.
23
166
797
Understanding UMAP - an interactive introduction to the algorithm and how to us (and mis-use) it from
@_coenen
and
@adamrpearce
. A must read for anyone interested in dimension reduction.

7
232
653
UMAP 0.4 is now out! It includes a host of new features, including plotting support, better sparse data support, inverse transforms, and embedding to non-euclidean manifolds.
pip install umap-learn
See this thread for some of the new features:
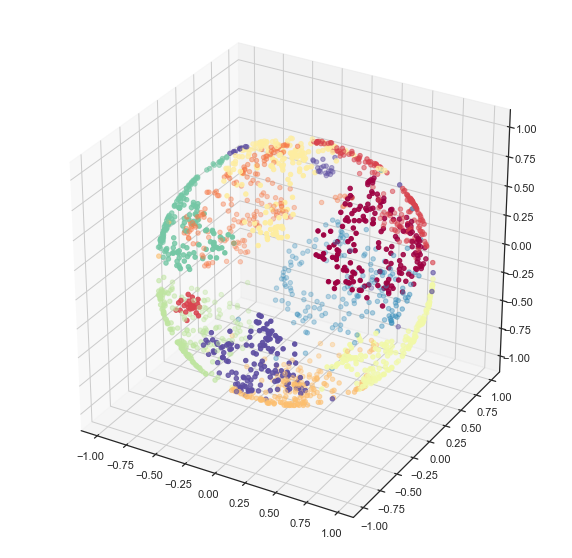
UMAP 0.4 supports embedding to non-Euclidean manifolds, including spheres, Poincare disks, and more.
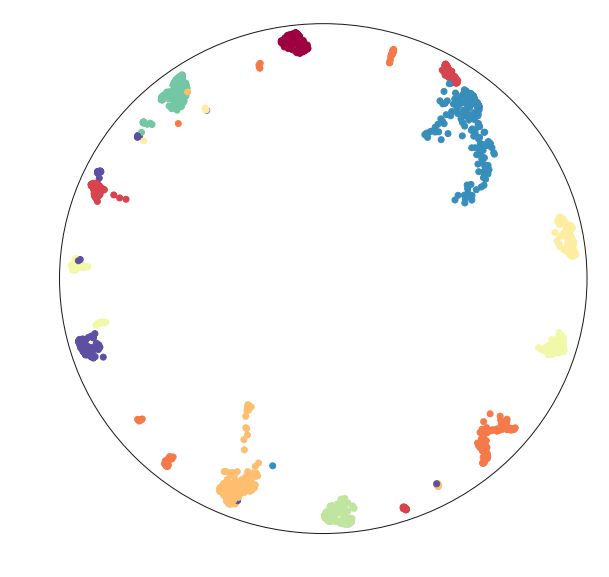
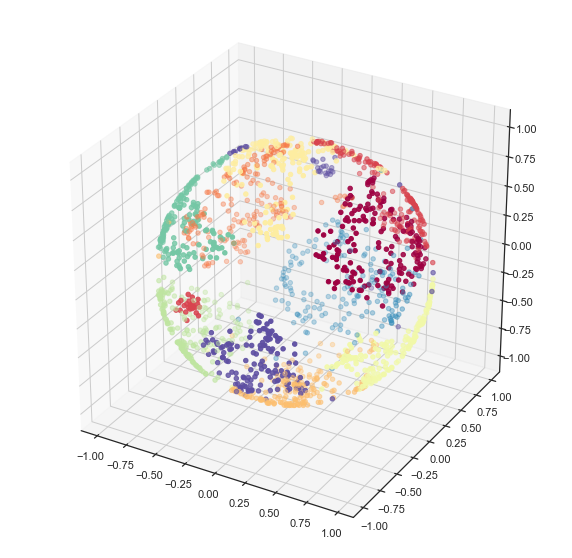
8
41
132
5
178
584
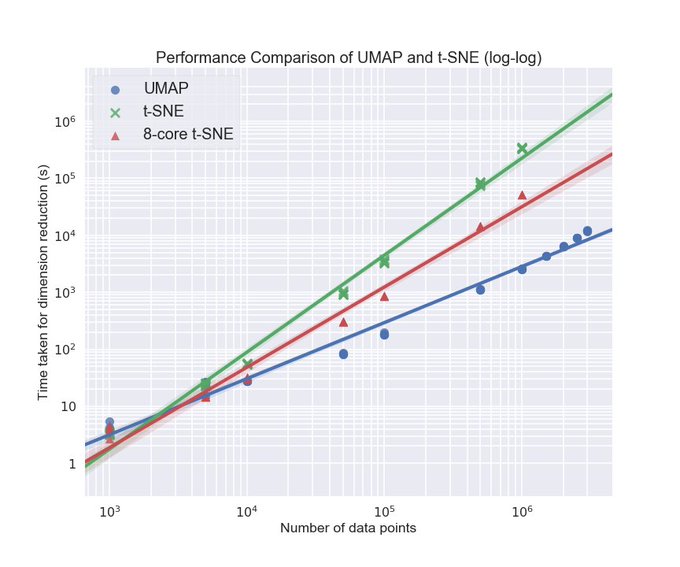
An updated and significantly expanded version of our UMAP paper is now on arXiv:
More explanation, algorithm descriptions, and more experiments looking at stability, and working directly on high dimensional data -- as high as 1.8 million dimensional data!
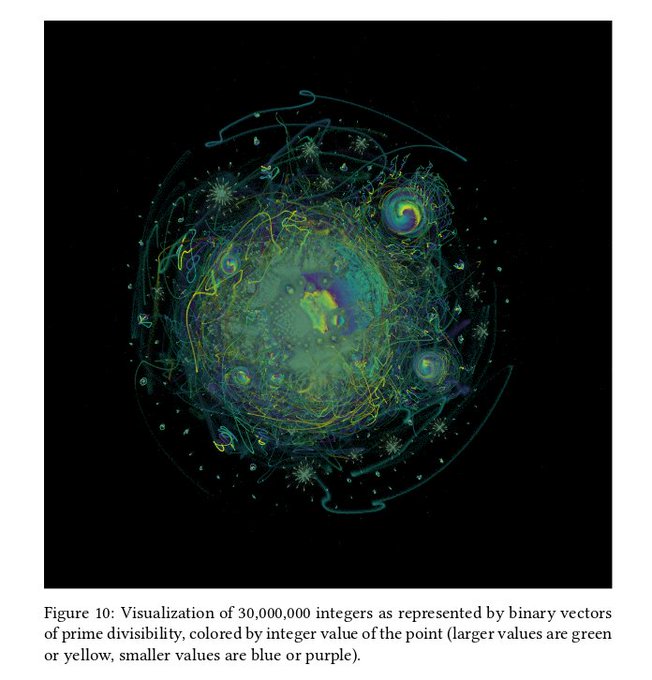
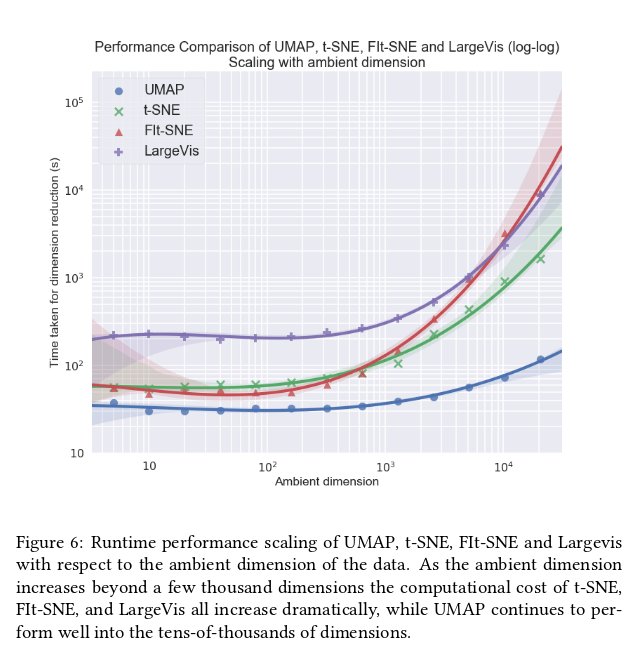
11
231
572
Introducing DataMapPlot for creating beautiful presentation ready plots of data maps. 🧵


10
111
543
UMAP version 0.3 is now available. You can now add new data to an existing embedding, embed using labelled data, or use both features for metric learning. Documentation is on readthedocs: .
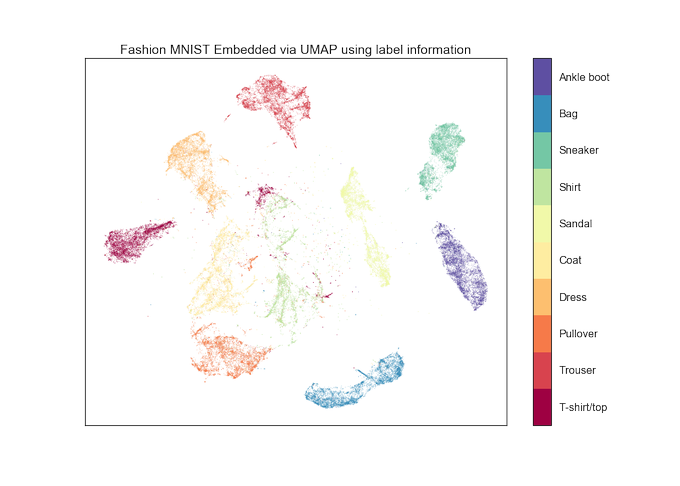
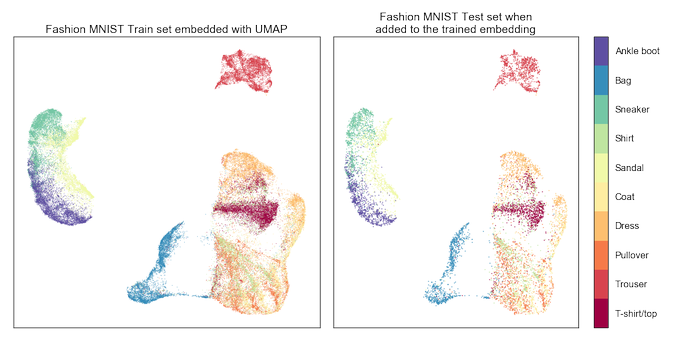

8
187
499
Ever needed a few more colours than the standard colour cycle for your plot? Ever wanted a categorical colour palette based around your own custom colours? With glasbey you can create and extend custom categorical colour palettes with ease.🧵

12
60
465
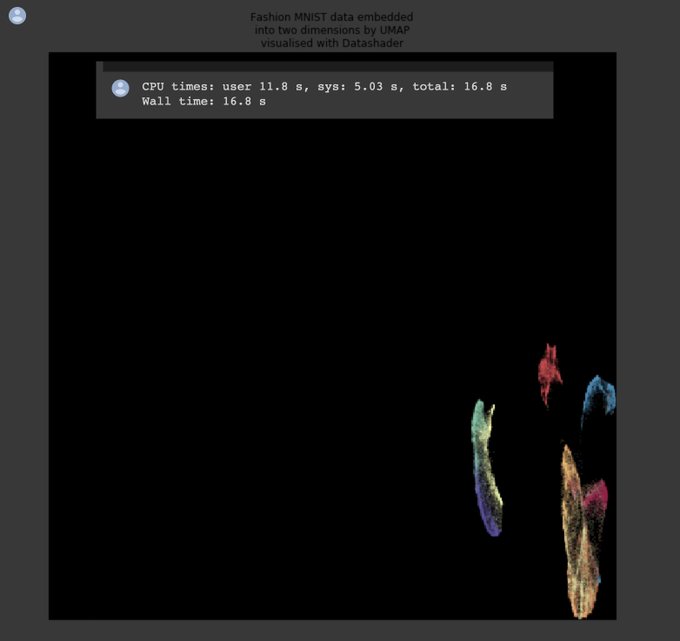
The new numba based version of UMAP is out. Now faster than ever, it takes only 2.5 minutes to embed the full 70000 points of the 784-dimensional "Fashion MNIST" dataset.
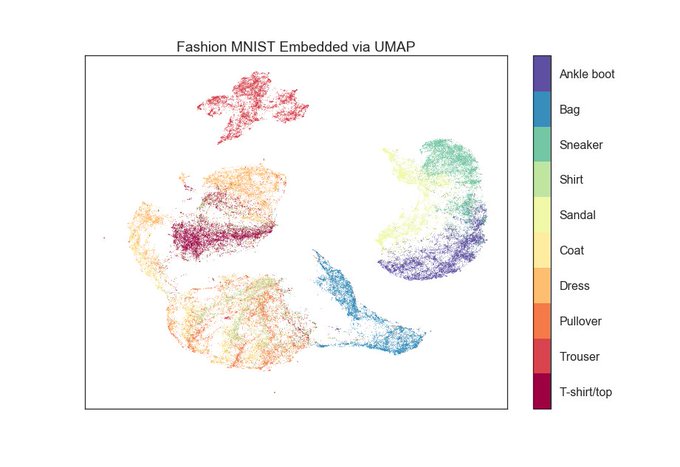
11
173
465
Here's a really nice simple intuitive explanation of th HDBSCAN clustering algorithm:

4
75
293
Really enjoying the
#mlprague
conference. Slides for my talk on topological approaches to unsupervised learning problems can be found here:

6
66
260
A major update for DataMapPlot adds interactive plots.
See for an example.
Let's dig in to what you can do with DatMapPlot 0.2 ... 🧵
6
55
250
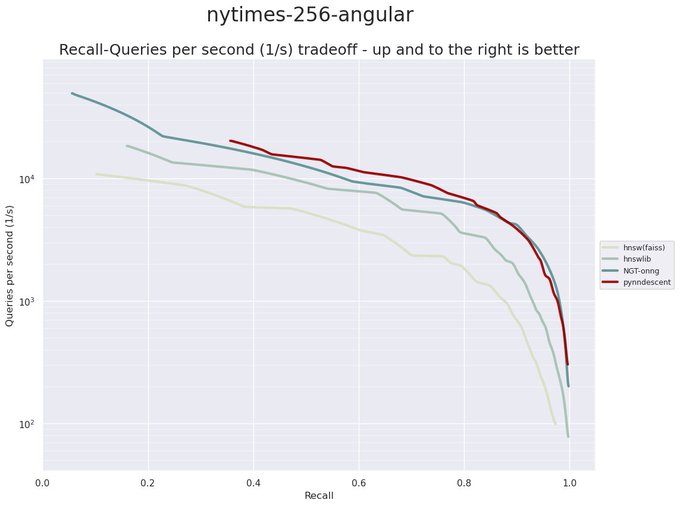
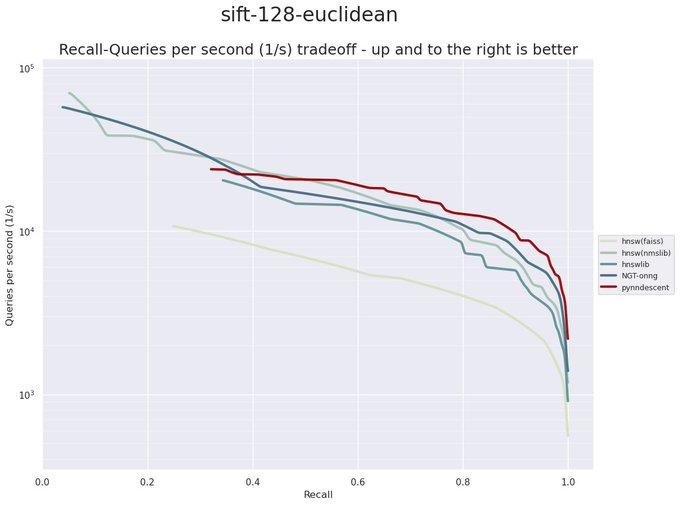
Pynndescent, an approximate nearest neighbor search library, got a major update recently. Index construction is now multicore by default. Querying is now much faster -- competitive with some of the fastest ANN libraries around.
(1/4)
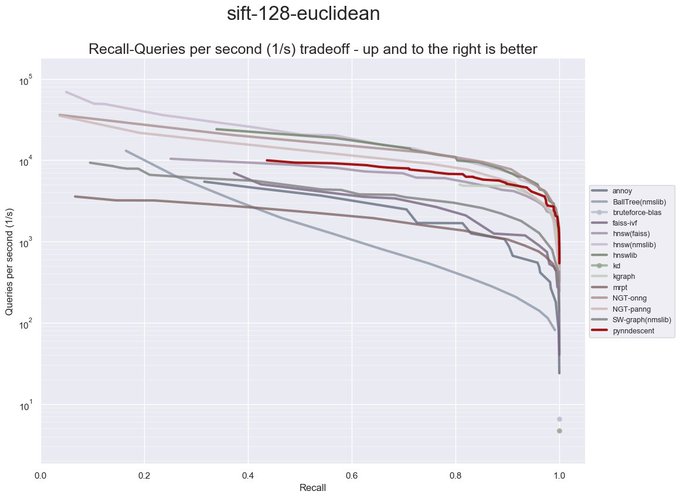
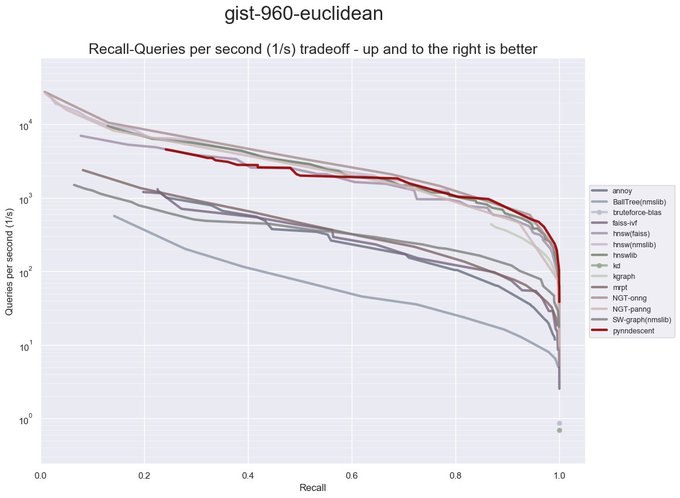
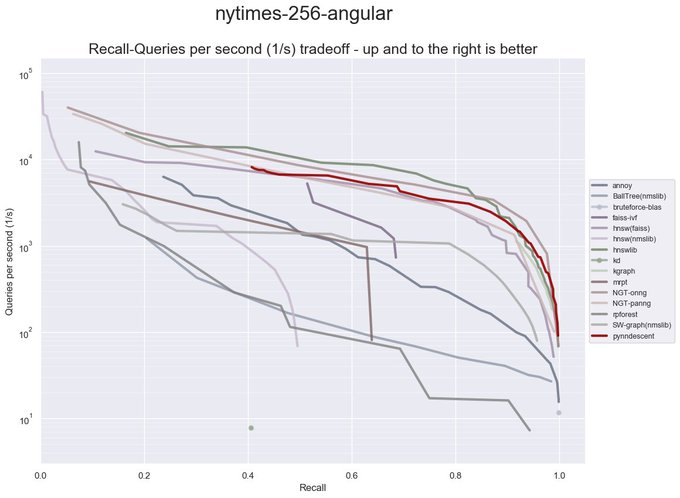
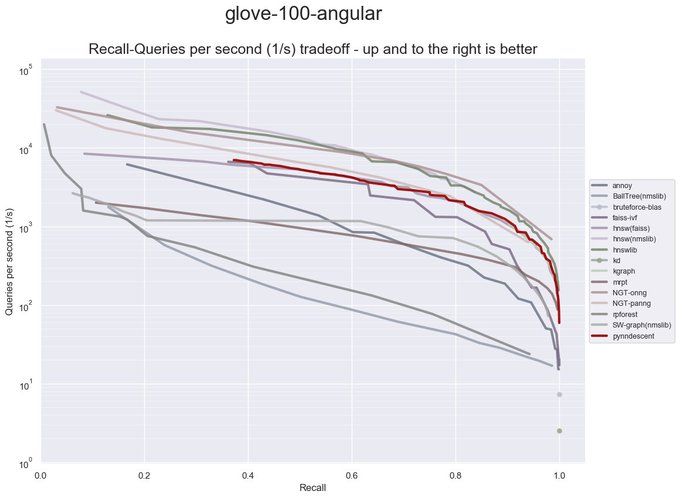
4
49
242
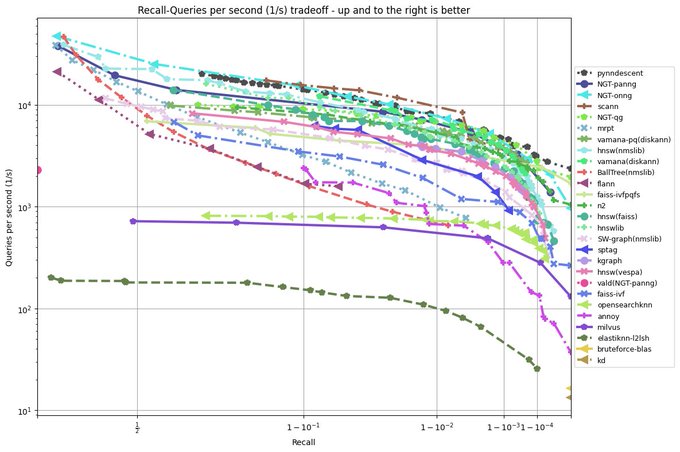
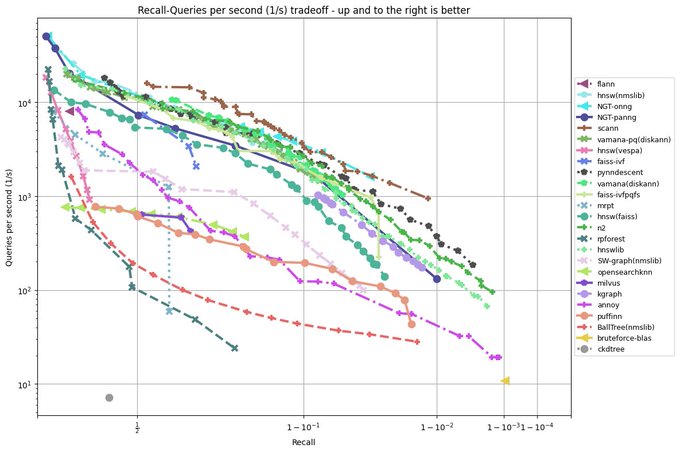
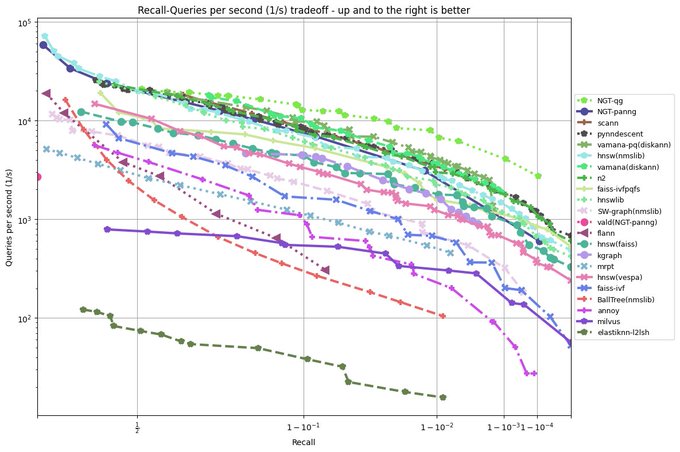
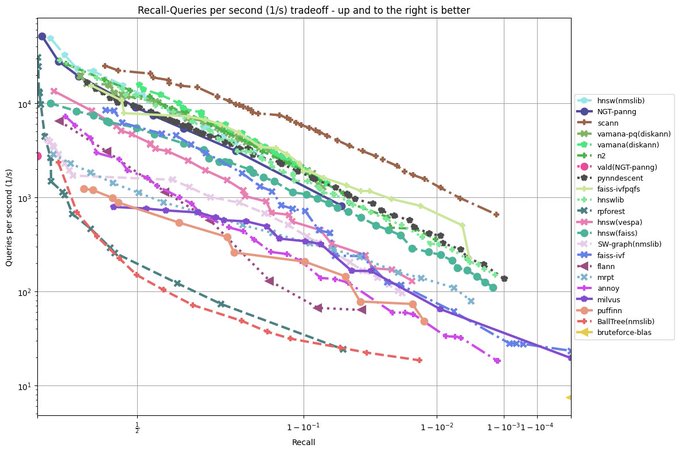
A new round of Approximate Nearest Neighbour search benchmarking by is out, including lots of new libraries and algorithms.
It is good to see PyNNDescent still performing very well.
5
38
190
I just started playing around with
@datashader
edge bundling for visualizing graphs associated to UMAP embeddings. Here's one for MNIST:
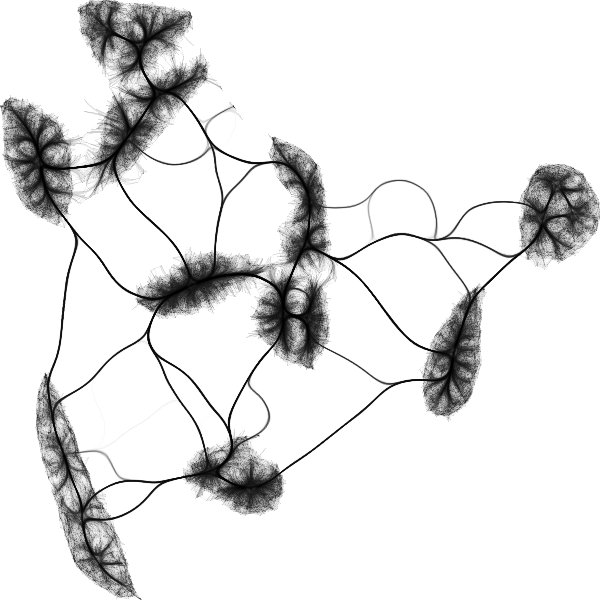
7
29
182
My talk at PyData NYC on dimension reduction is now available. Hopefully it provides a useful basic taxonomy to help people navigate the vast zoo of dimension reduction techniques.

6
42
177
A new release of DataMapPlot adds the ability to place labels over top of the map for a word-cloud style look. As usual there remain a lot of options to fine tune and customize to your needs.

2
32
165
This is some amazing work from
@tim_sainburg
. Some major takeaways:
- lightning fast transform/inverse_transform operations (comparable to PCA if you have a GPU);
- semi-supervised classification: 97.8% accuracy on MNIST with only 4 labelled items per class!

New paper "Parametric UMAP: learning embeddings with deep neural networks for representation and semi-supervised learning" with
@leland_mcinnes
and
@TqGentner
! 1/

4
61
294
1
38
154
Have you been frustrated that HDBSCAN doesn't use all your cores, or is too slow? Fast-hdbscan is a numba based version of HDBSCAN that can use all your cores and significantly outperform the hdbscan python package for low-d Euclidean data.
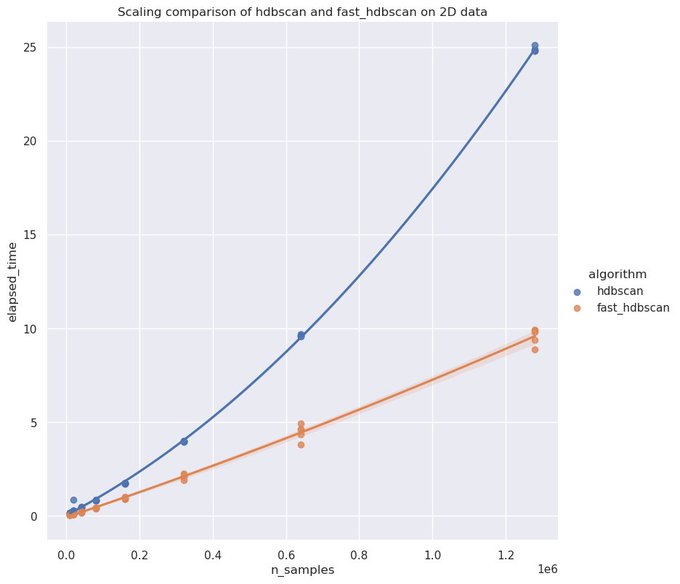
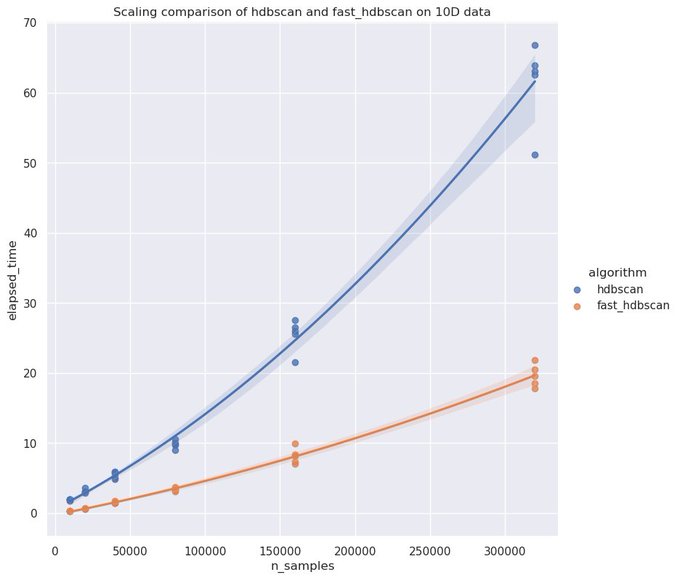
2
18
145
UMAP 0.4 supports embedding to non-Euclidean manifolds, including spheres, Poincare disks, and more.
8
41
132
If you want to experiment with a work-in-progress Embedding Vector Oriented Clustering library you can try out EVōC (pronounced "evoke").

8
29
132
I just gave a talk at
#PyDataNYC
on dimension reduction -- focussing on core intuitions and unifying concepts. You can find the slides for it here:
5
52
129
Initial experimental version of UMAP code now on github: . Aiming for better dimension reduction than t-SNE.
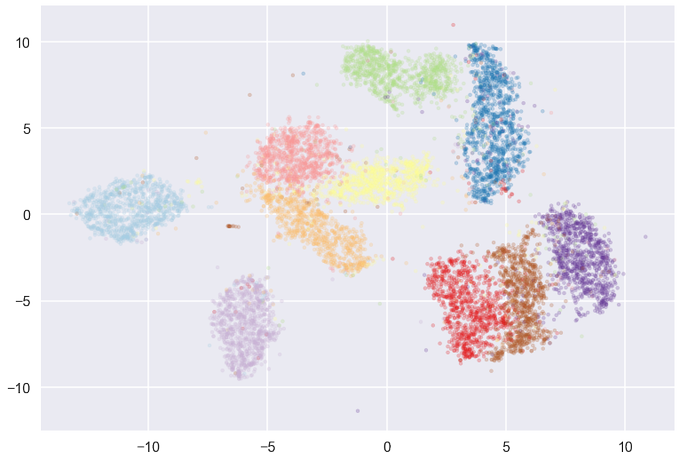
7
49
122
Here's a useful term when looking at t-SNE/UMAP plots ...

Apophenia: The tendency to see patterns in random data.
5
177
437
2
32
121

The landscape of Machine Leaning on ArXiv: Now available in a zoomable, searchable version with paper titles on hover.
The landscape of the Machine Learning section of ArXiv.
23
166
797
0
27
113
If you have GPU resources handy the new HDBSCAN implementation in
@RAPIDSai
cuML is amazingly fast. You can get to millions of points clustered in only a few minutes!

3
20
112
If you could get a clustering algorithm and library specifically designed for fast clustering of embedding vectors (CLIP, sentence-transformers, Cohere-embed, etc.), what features would you most want it to have?
30
17
111
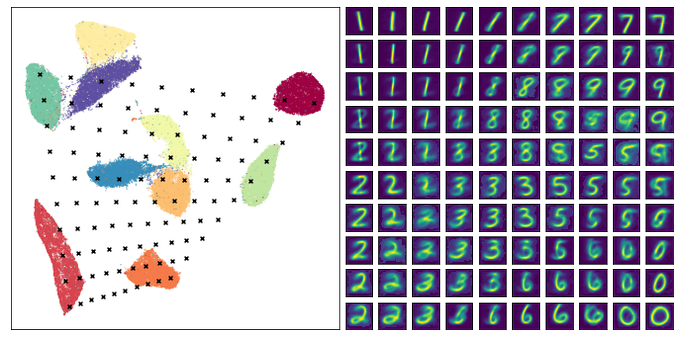
Playing with some nlp related tools I've been working on, I ended up with some nice visualizations. This is Top2Vec style topic words on a UMAP layout of 20-newsgroups document vectors using masked word-clouds for each newsgroup.
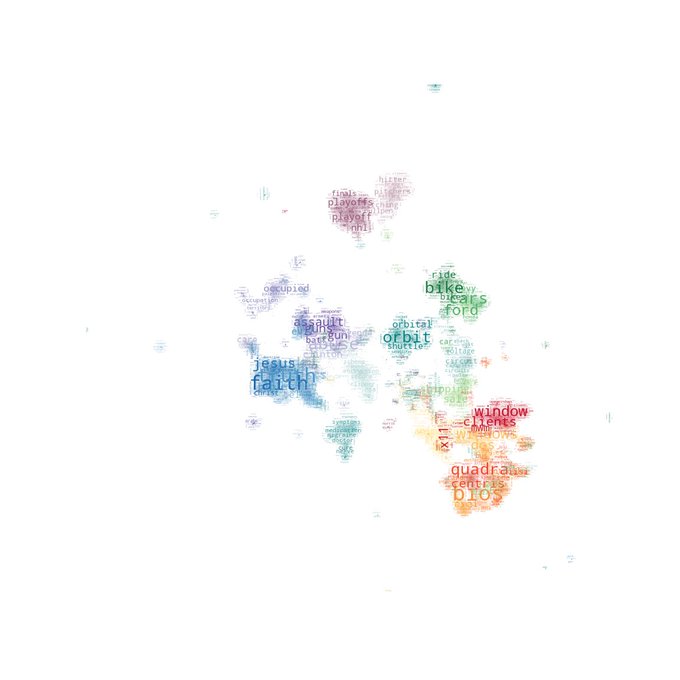

3
19
110
Using UMAP to make neural net activation spaces more interpretable.

In collaboration with Google, we're releasing Activation Atlases: a new technique for visualizing what interactions between neurons can represent.
💻Blog:
📝Paper:
🔤Code:
🗺️Demo:
18
848
2K
2
22
107

2
33
103
If you want to spend some time exploring a UMAP embedding of images (like MNIST)
@GrantCuster
put together a nice tool:
2
37
104
A great introduction to HDBSCAN and density based clustering:
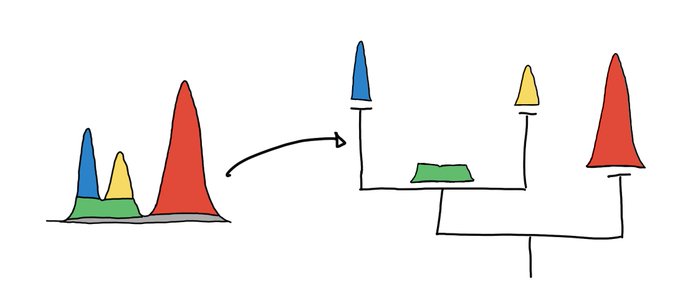
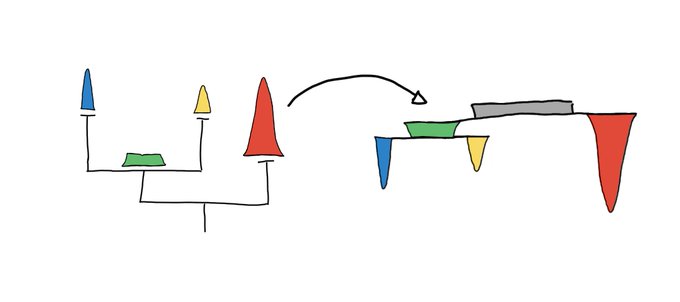
0
22
100
Simplicial Autoencoders using UMAP theory to build better autoencoders (and a nice introduction to UMAP as well):
3
30
98
What if I redesigned HDBSCAN from scratch based on the theory behind UMAP? Apparently it might actually work fine and look something like this:

3
23
99
My
#scipy2021
talk on PyNNDescent, a library for fast approximate nearest neighbour search is now available:

5
23
97
The first release candidate for umap-learn 0.5 is out. Take the opportunity to verify the new version works for you.
3
15
97
A great example of what UMAP is for: look at your data and realise it wasn't what you thought -- and then use it to ask better questions about your data before proceeding with fancier ML tools.

It was only when we visualized the UMAP that we got suspicious: the representations of all IDRs split into two big blobs. That's when we decided to interpret the features, and then we realized: half the features had a big "M" capturing the start methionine.
1
3
10
0
21
95
Here's a new cluster extraction method for HDBSCAN that has some significant potential benefits and makes the algorithm that much more flexible.

0
28
92
My talk on topological data analysis at ML Prague is already online! It provides a brief whirlwind tour of why topological methods matter for unsupervised learning problems.
#mlprague

0
35
92

A spin off from UMAP work: a small easy to install library for approximate nearest neighbour search.

2
25
89
This is a nice way to get some sense of what UMAP is doing at least for low dimensional data.

2D UMAP of a 3D woolly mammoth, to build intuitions about how features are preserved in dimensionality reduction. Wonderful 3D scan from the people at
@3D_Digi_Si
.
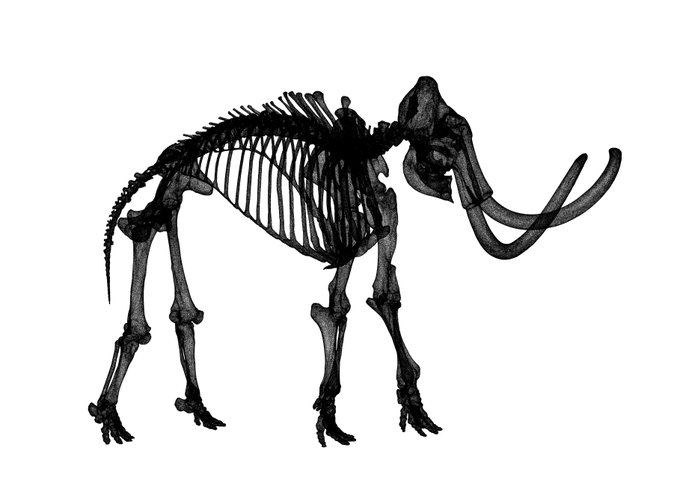
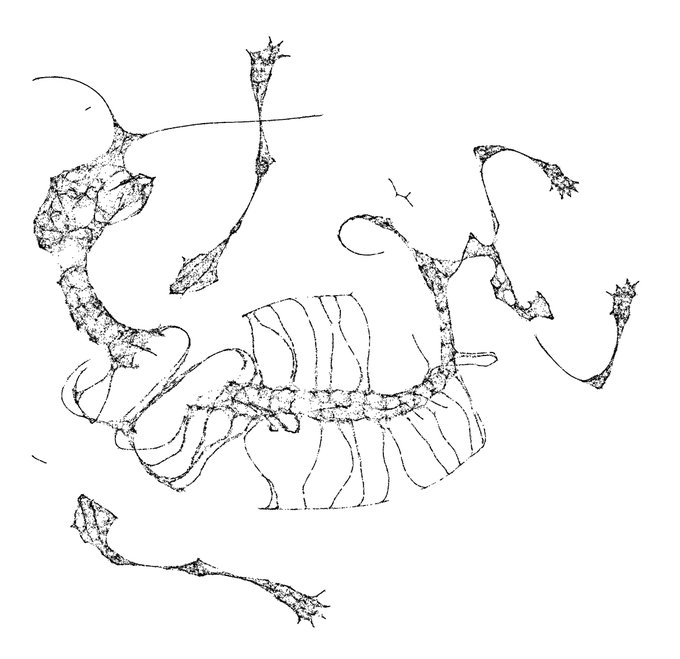
5
27
76
0
26
87
The video for my talk at PyData LA 2019 on "Topological Methods for Unsupervised Learning" is now online:

1
13
86
Hypergraphs and simplicial complexes are going to become ever more prevalent. Here's a great article on some of the reasons why they are so interesting.

2
21
85
Embedding the MNIST test set with a new manifold learning approach. Captures more global structure than t-SNE.
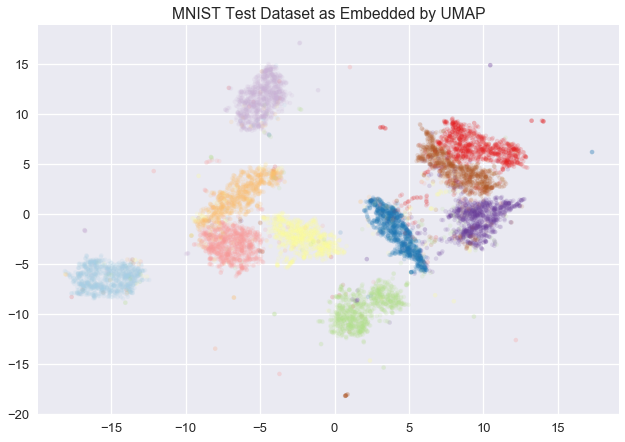
6
26
82
I'm considering dropping python 2.7 support for hdbscan and umap-learn. Let me know if this would be extremely painful for you. Also let me know if this would make you happy.
16
1
83
Embed All The Things! John Healy's PyData LA talk on using UMAP on diverse types of data is well worth watching.

2
22
77
I really want to emphasize how amazing
@numba_jit
is. Pynndescent is pure python code relying on numba for acceleration. It is performance competitive with *highly optimized* C++ code. I still can't actually believe how incredibly well numba works!
3
20
78
Delivery is apparently a little slower to Canada, but I finally got my copy of
@math3ma
's book! Certainly worth the wait...

2
5
79
Suppose UMAP could represent data not as 2d points, but as 2d gaussians with a full covariance matrix. Would that be useful? What would be the best way to represent that visually?
11
8
77
I have been revisiting pynndescent recently, and with help from the
@numba_jit
team I managed to get some significant performance gains. Preliminary tests on
@fulhack
's ann-benchmarks is looking very promising. Hopefully I'll have a new 0.5 release with these changes out soon.
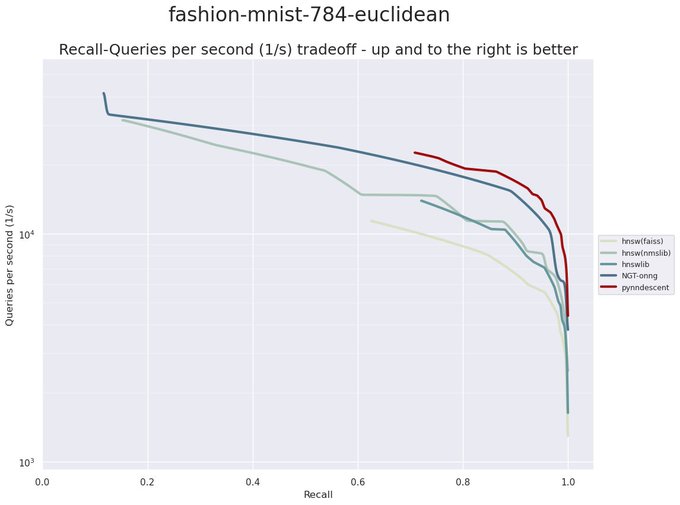
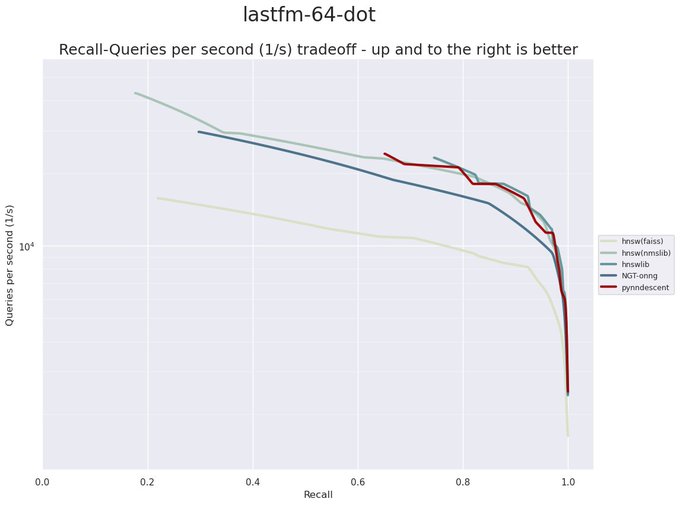
2
17
74
I just added support for these binary embedding vectors to pynndescent. Using them directly with UMAP should be possible very soon...

🚀 𝐂𝐨𝐡𝐞𝐫𝐞 𝐄𝐦𝐛𝐞𝐝 𝐕𝟑 - 𝐢𝐧𝐭𝟖 & 𝐛𝐢𝐧𝐚𝐫𝐲 𝐒𝐮𝐩𝐩𝐨𝐫𝐭🚀
I'm excited to launch our native support for int8 & binary embeddings for Cohere Embed V3.
They slash your vector DB cost 4x - 32x while keeping 95% - 100% of the search quality.

15
79
443
4
8
72
Plots not meta enough? Here is a nice UMAP plot of different plots.
From "Viral Visualizations: How Coronavirus Skeptics Use Orthodox Data Practices to Promote Unorthodox Science Online"

2
16
74
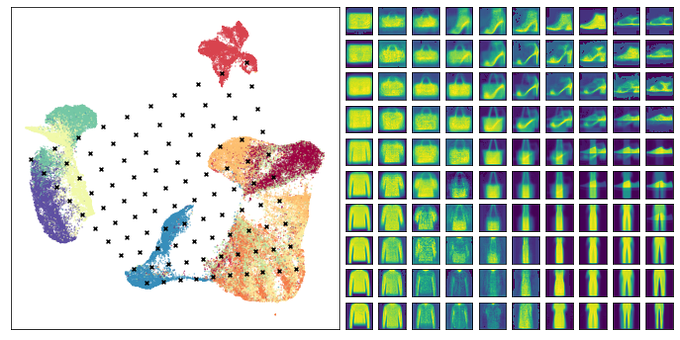
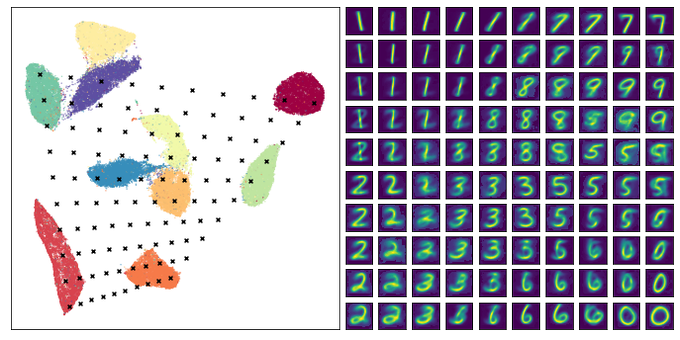
Support for an "inverse transform" has been added to UMAP 0.4, providing the ability to generate a high dimensional representation of a point in the embedding space.
2
19
66
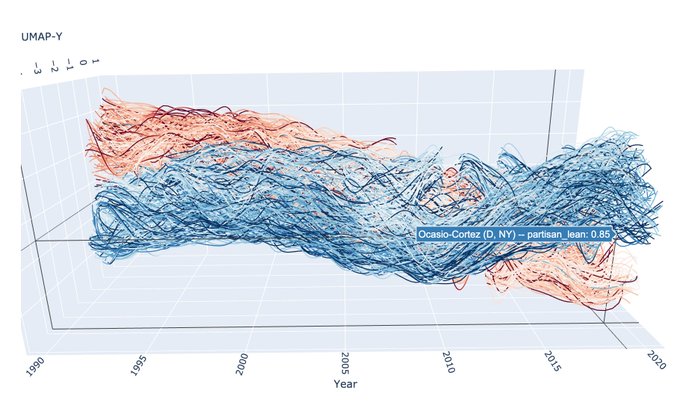
AlignedUMAP allows sequences of different UMAP embeddings to be aligned with each other according to relations among the datasets. This can be particularly useful for situations such as time evolving data. 7/ 14
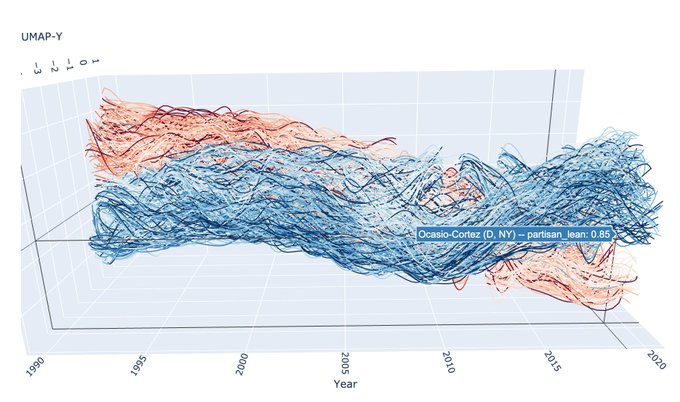
8
9
69
An upcoming feature currently in the 0.5dev branch of UMAP will make this much easier to do. e.g.
mapper1 = umap.UMAP(metric='euclidean').fit(continuous_data)
mapper2 = umap.UMAP(metric="dice").fit(discrete_data)
consensus_mapper = mapper1 * mapper2

0
14
67
A paper in
@JOSS_TheOJ
for the UMAP software implementation is now published: .
Thanks to the editors (
@arokem
) and reviewers (
@TerryTangYuan
) for providing such a smooth process for publication.
1
23
65
An interesting alternative approach to topic modelling using doc2vec, UMAP and HDBSCAN:

0
12
62
@DrPattiJones
PCA provides a global linear projection onto the hyperplane defined by the directions of global maximal variance in your data. UMAP attempts to stitch together many local views of the data accounting for local variance, into an intermediate structure, then represent that in low D
3
3
60
Inspired by the t-SNE animation from
@ChaseClarkatUIC
I decided to try something similar for UMAP. Here is an animation for varying values of the n_neighbors parameter. Increasing values give more weight to global structure over local structure.
2
20
60
UMAP now has 1,000 github stars! Thanks to all the users and contributors! There are more features coming in version 0.3 soon, and some exciting ones in very early development.
1
11
57
@ch402
@SuhnyllaKler
@AnthropicAI
An example of current work: is linear optimal transport applied to word vectors a decent sentence/document embedding model? It turns out yes, yes it is.
There's still a long way to go to scale and benchmark on larger datasets, but it's promising.
4
11
56
A new minor release of umap-learn adds some very useful features:
- Updating ParametricUMAP to Keras3 (kindly provided submitted by
@fchollet
);
- Initial support for binary embedding vectors with metric="bit_hamming" and metric="bit_jaccard".
1
3
57
I'll be giving a talk on PyNNDescent, a library for approximate nearest neighbour search, at
#SciPy2021
on Friday.
0
10
54
Code from my lightning talk: ensemble topic modelling in Python with pLSA for fast stable topic modelling with the enstop package:
#SciPy2019
1
17
51
HDBSCAN is now in RAPIDS!

2
6
53
It's well worth reading the paper on FIt-SNE -- useful techniques and fun math.

@F_Vaggi
@leland_mcinnes
FIt-SNE uses an O(N) interpolation scheme to accelerate the computation of the gradient at each step. More details are available in the preprint () or some notes I wrote ()
1
1
20
1
9
48
I belatedly got to experimenting with FIt-SNE from
@GCLinderman
. It's very impressive and very fast -- definitely the implementation you should be using if you want to use t-SNE for visualization.
1
11
48
Good news for
#rstats
users looking for dimension reduction: An R package wrapping UMAP: ; and an independent implementation of UMAP in R: !

0
25
46

The video of my talk from PyData Seattle on "Data Maps for Data Exploration" is now available:

1
11
44
Thanks also go to James Melville, author of the UWOT implementation of UMAP for R (), who has joined as a co-author.

0
9
45
Documentation is on ReadTheDocs:
Code is on Github:
$ pip install datamapplot

2
3
45
The ambient coordinates of your data (coming from features) need not be related to the intrinsic notion of distance internal to the data itself. An idea worth wrapping your head around.

'It's not so easy to free oneself from the idea that coordinates must have an immediate metrical meaning.' -- Albert Einstein
0
26
107
4
14
42
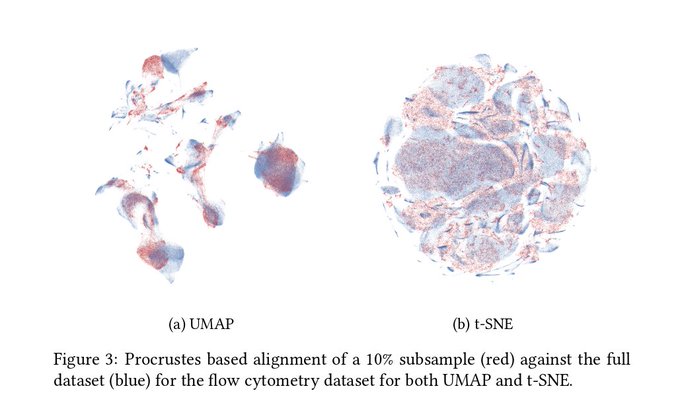
Really interesting to see UMAP on real-world data!

Checkout Etienne Becht's bioRxiv preprint that compares UMAP with t-SNE for visualizing CyTOF and scRNAseq data. Many advantages of UMAP over t-SNE for high dimensional single-cell data!
@leland_mcinnes
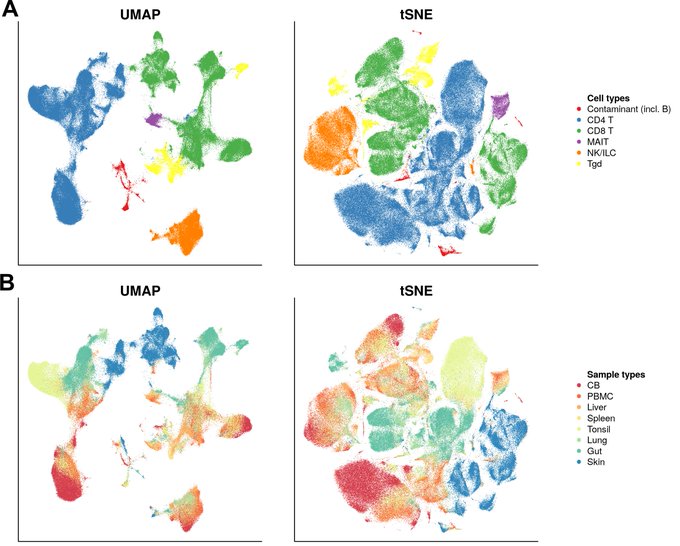
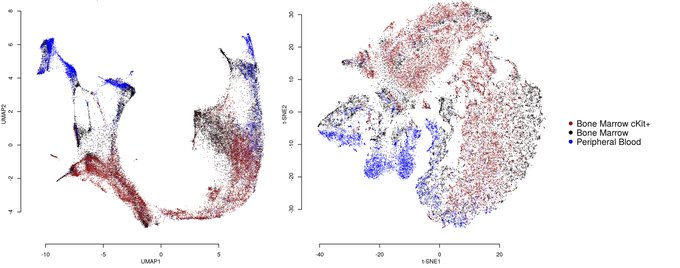
11
109
227
2
10
43
Documentation for UMAP 0.4 now includes examples of UMAP usage for visualization, exploratory analysis, and scientific publications. If you have a compelling use case, we would love to include it as well.
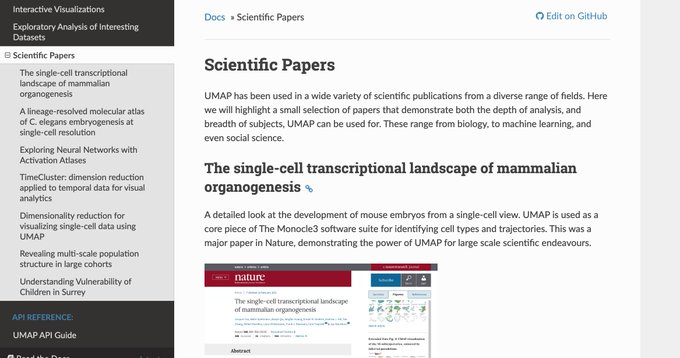
4
3
42
This was a fantastic series of of posts! If you want a well written intro to some of the ideas in topological data analysis this is a great place to start.

@asemic_horizon
@scikit_tda
@leland_mcinnes
I wrote a series of posts leading up to some TDA (see "Topology" section here: ) And then a few posts in the TDA family before I lost steam (see Computational Topology section of )
1
4
36
1
13
42
Many thanks to
@datametrician
@cjnolet
and
@rapidsai
for making this possible -- definitely some amazing performance available for UMAP on GPU!

Reproduced the
#UMAP
on
#RAPIDS
example by
@ceshine_en
() on Colab (with help from ). Seeing 60X speedup on Colab
@leland_mcinnes
@rapidsai
@keithjkraus
@datametrician
@rodaramburu
see Colab Gist
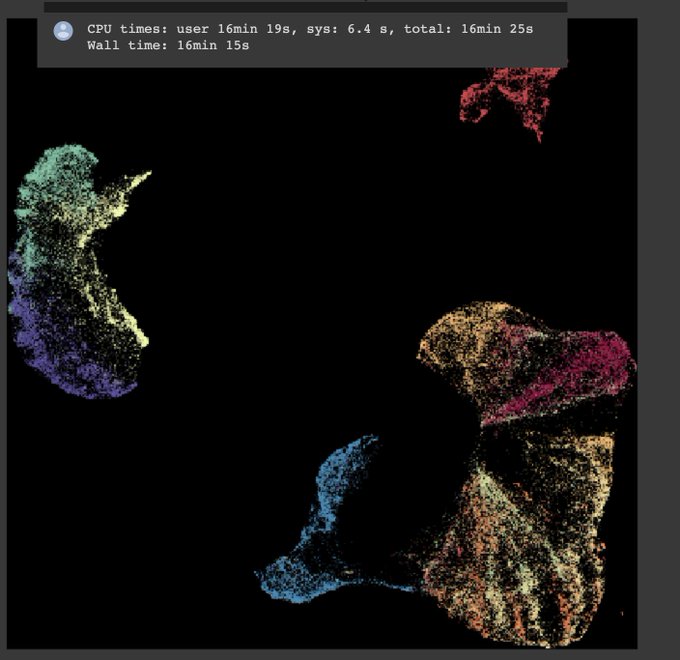
0
13
44
1
18
41
Code from my lightning talk: ensemble topic modelling in Python with pLSA for fast stable topic modelling with the enstop package:
1
10
42
It is a huge testament to the power of
@numba_jit
that a pure python library like PyNNDescent can be performance competitive with C++ libraries from Google (ScaNN), Microsoft (DiskANN), and Facebook (FAISS) among others.
Many, many thanks to the whole
@numba_jit
team!
3
6
40
The glasbey library is on github:
Documentation can be found on readthedocs:
And you can pip install it:
$ pip install glasbey

1
6
38
@EmilyTWinn13
@SC_Griffith
After the flood Noah is checking up on the animals. They're all breeding well, except for a pair of snakes. Noah gets a little worried and follows them. Eventually they find a fallen tree, and suddenly ... lots of baby snakes. It turns out that adders need logs to multiply.
1
4
39
@rctatman
Here's a plan we use: Take the term-frequency matrix, remove the "expected" frequency (by subtracting, or using the column marginal as a noise model), UMAP with hellinger distance, and HDBSCAN for clustering. Still fine tuning the process, but has been very powerful so far.
3
2
39
An amazing introduction to UMAP and its parameters. This is for UMAP what the Distill article was for t-SNE. Great work from
@_coenen
and
@adamrpearce
as always!

Understanding UMAP - a high-level introduction to how the algorithm works, how to use it effectively, and how it compares with t-SNE.
8
182
631
1
19
39
@michaelhoffman
Many of the t-SNE (and UMAP) plots I see suffer from potential over-plotting issues. This is particularly dangerous if you are trying to eyeball cluster purity. Using such plots as a starting point for further analysis rather than an endpoint is critical.
4
10
38
This is a fascinating paper -- using a contrastive approach on augmentations of images to learn a low dimensional representation they generate truly impressive results for image datasets!

Ever wondered what image datasets look like if they could be visualized? We have developed a new algorithm for visualization based on contrastive learning. Joint work with
@hippopedoid
and
@CellTypist
. The full details are available as a preprint 🧵/16
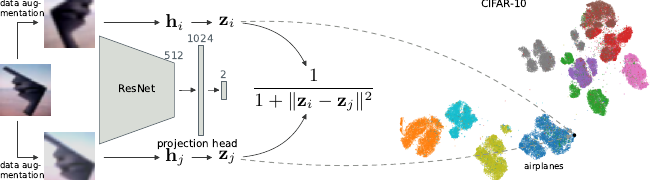
4
66
264
1
3
37
I've started telling people "Look at your data, because whatever you think you know about the data is almost certainly wrong". I'm not sure it works any better, but at least I warned them...

“Have you tried looking at the data?” is my most common question when talking to folks who are inexperienced with data. Over the last two years, about 90% of the time, the answer has been, “Why?” or “What good would that do?” 🙄
0
2
13
2
11
36
A new version of UMAP is now available. A new layout algorithm provides more accurate embeddings even faster than before.
1
17
35
I'll be speaking at the Fields Institute today on using UMAP theory for general unsupervised learning. I'll be happy to chat more about these ideas afterwards as well.
2
2
37
Here's a really great interactive article using UMAP to explore and compare large deep neural networks by
@mwli16
and
@scheidegger
:
0
9
35
I will be co-chairing the machine learning track at SciPy this year. Submissions are open, so if you have a machine learning project in python consider submitting. This is a great opportunity to share your work with a wide audience.
@SciPyConf
0
6
36
Getting close to finishing version 0.3 of UMAP, including some useful new features. Ideally it'll come at just before or at
@SciPyConf
this year.
2
4
34
The core neighbor search in UMAP has been expanded upon in a separate library, PyNNDescent, which provides significantly improved performance. Combined with PyNNDescent UMAP 0.4 now support multi-core computation end-to-end (MNIST in ~45s on a laptop).
2
7
34
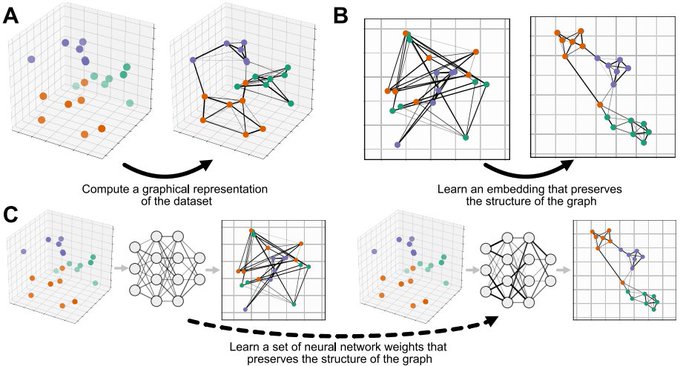
ParametricUMAP uses a neural network to learn a UMAP embedding. This allows for a number of significant advantages. 2/14
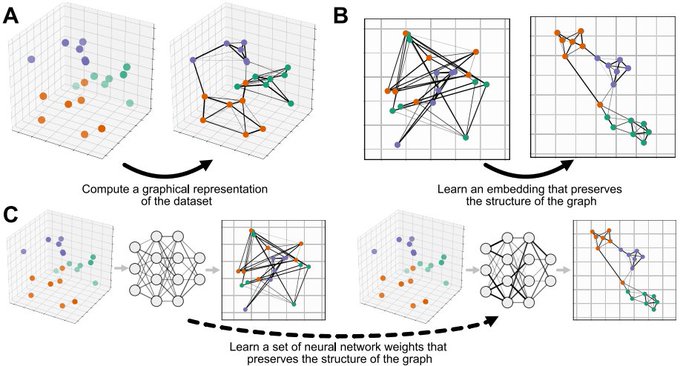
3
5
32