

Harry Ng ᯅ
@harryworld
Followers
1K
Following
4K
Statuses
2K
Father. Slow-nomad. Indie. 🍎 Technologies Instructor. Formerly @GoodnotesApp @SortedHQ @GA 🇭🇰 🇹🇼
Joined March 2009

It takes a lot of courage to rebuild a product from scratch, and I’m looking for support to push myself forward
0
0
4
The role of PMs hasn’t changed. In the past, one may rely engineering teams to deliver. Now the engineering is a bunch of AI tools or agents. If you know what you’re doing, you can probably build stuff 100x faster.

“People don’t like hearing this but this is the reason why startups don’t hire big tech folks.” made the same learnings. As a small company you want people that get sh*t done. Folks from Google & co usually aren’t that.
0
0
3
Cursor agent 有時很固執 有句代碼必須加上 self. 才能通過編譯 他總是會把 self. 刪掉 真像個挑皮的小孩
0
0
2
Setting up the 2 targets for 2025 1. Teaching app programming 2. Building app product again
1
0
6
RL vs SFT

SFT Memorizes, RL Generalizes. New Paper from @GoogleDeepMind shows that Reinforcement Learning generalizes at cross-domain, while SFT primarily memorizes. rule-based tasks, while SFT memorizes the training rule. 👀 Experiments 1️⃣ Model & Tasks: Llama-3.2-Vision-11B; GeneralPoints (text/visual arithmetic game); V-IRL (real-world robot navigation) 2️⃣ Setup: SFT-only vs RL-only vs hybrid (SFT→RL) pipelines + RL variants: 1/3/5/10 verification iterations (”Reject Sampling”) 3️⃣ Metrics: In-distribution (ID) vs out-of-distribution (OOD) performance 4️⃣ Ablations: Applied RL directly to base Llama-3.2 without SFT initialization; Tested extreme SFT overfitting scenarios; Compared computational costs versus performance gains Insights/Learning 💡 Outcome-based rewards are key for effective RL training 🎯 SFT is necessary for RL training when the backbone model does not follow instructions 🔢 Multiple verification/Reject Sampling help improve generalization up to ~6% 🧮 Used Outcome-based/rule-based reward focusing on correctness 🧠 RL generalizes in rule-based tasks (text & visual), learning transferable principles. 📈 SFT leads to memorization and struggles with out-of-distribution scenarios.

0
0
0
While AI can be used to teach hard skills, future teachers should spend more time to teach kids about being a human

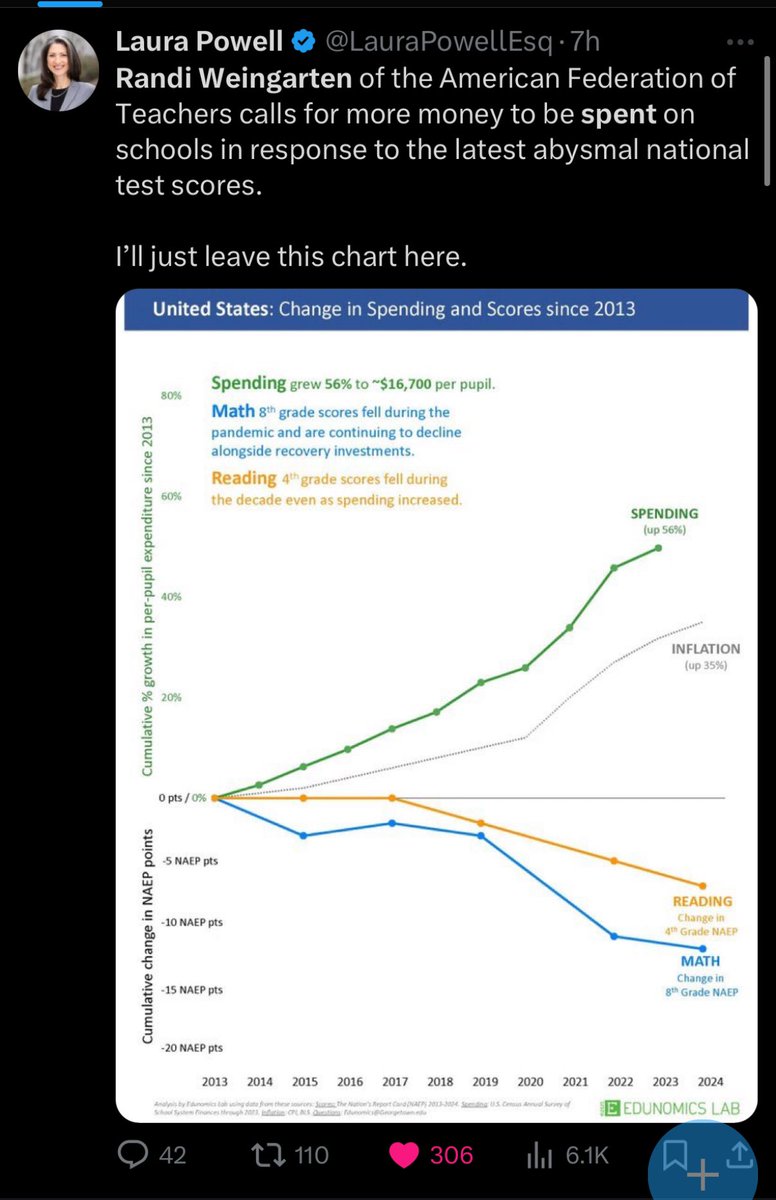
Prediction: One of the defining political conflicts of the next decade will be AI vs the extremely powerful teachers unions
0
0
2
I have been rethinking about how AI can enhance daily planning in general, and saw YC RFS, seems to be a good opportunity
0
0
0
RT @ycombinator: From the AI breakthroughs of the last few months, a wave of new startup opportunities have been unlocked. Here are some o…
0
325
0
This is a wrap for this 🇸🇬 trip, and I definitely enjoy the food in Singapore. Now is the time to onboard my flight ✈️ back to Taiwan. I’m missing my wife and kids ❤️




0
0
5