

Fred Sala
@fredsala
Followers
1,038
Following
570
Media
6
Statuses
234
Assistant Professor @WisconsinCS . Chief scientist @SnorkelAI . Working on machine learning & information theory.
Madison, WI
Joined July 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#HouseOfTheDragon
• 604065 Tweets
Le Pen
• 598091 Tweets
Melenchon
• 324486 Tweets
Rhaenys
• 279983 Tweets
seokjin
• 203847 Tweets
FRED GLOBAL AMBASSADOR JIN
• 185342 Tweets
Meleys
• 184313 Tweets
Bautista
• 179633 Tweets
#OccupyMOH
• 145531 Tweets
#JinxFredJewelry
• 125414 Tweets
Aegon
• 113462 Tweets
Aemond
• 108058 Tweets
Vhagar
• 107871 Tweets
Kyiv
• 49439 Tweets
#MondayMotivation
• 37481 Tweets
Francji
• 24508 Tweets
セレクトセール
• 23673 Tweets
オールスター
• 21426 Tweets
hyuna
• 21267 Tweets
間宮祥太朗
• 19250 Tweets
ドウデュース
• 18260 Tweets
PakPRABOWO SiapkanPROGRAM
• 17684 Tweets
UntukNKRI LebihSEJAHTERA
• 17010 Tweets
Happy New Week
• 16810 Tweets
萩のツッキー
• 16705 Tweets
Frankrijk
• 16640 Tweets
Convenience
• 14327 Tweets





















Thrilled to share that I will be joining the University of Wisconsin
@WisconsinCS
as an assistant professor in January 2021. Incredibly grateful to all of the wonderful people who have supported me on this journey!
16
8
216
Generative models are awesome at producing data, and weak supervision is great at efficient labeling. Can we combine them to get cheap datasets for training or fine-tuning?
Excited to present our
#ICLR2023
paper "Generative Modeling Helps Weak Supervision (and Vice Versa)"

2
19
73
Very excited to share that our NeurIPS tutorial with Ramya Vinayak on efficient dataset construction is now freely available:
Bonus: amazing panel with
@MayeeChen
,
@rdnowak
,
@codyaustun
, and
@SnorkelAI
's
@ajratner
!
0
17
72
Can't wait to see everyone at
#NeurIPS2023
!
Excited to present lots of fun work from my group and with our awesome collaborators, including

1
18
51

Join us tomorrow at
@ICLR_conf
for our work on automating dataset construction for diverse data types
Poster Session 12, Thursday evening
3
15
38
Excited to share that our work on improving the robustness of foundation models, without training or data, will be at
@iclr_conf
!
Longer version of our paper that won best paper honorable mention at the NeurIPS R0-FoMo workshop last month.

While you’re waiting for NeurIPS decisions—check out a fun problem! Can we improve large pre-trained models’ robustness *without* getting more data and fine-tuning?
1
12
42
0
8
33
Fun new work from our group spearheaded by
@nick11roberts
: we build new hybrid mixed-architecture models from pretrained model building blocks!
Feedback and comments appreciated!

So many new LLM architectures (Mambas🐍, Transformers🤖,🦙,🦔, Hyenas🐺,🦓…), so little GPU time to combine them into hybrid LLMs…
Good news! Today we release Manticore, a system for creating **pretrained hybrids** from pretrained models! 👨🌾🦁🦂
1/n

9
51
178
1
10
35

@TinaLNeal
@MSNBC
@GarrettHaake
@JoeBiden
Where was his fight for equality when he worked with white supremacists to end busing, or when he threw Anita Hill under the bus?
1
2
25
Get hyperbolic about your relationships! Exploring the limits of embedding your databases, graphs, and structures in low dimensions using hyperbolic embeddings:
1
13
20
Super proud of my student
@nick11roberts
who was just recognized as a
@MLCommons
Rising Star!
Congratulations Nick!

We are pleased to present the inaugural MLCommons Rising Stars cohort. This talented group of PhD students are the future leaders of ML and Systems research.
1
8
53
0
1
20

Excited to share a cool result from our group showing how to do smart aggregation for all those pesky language model objects---labels, thought chains, trees, and more.
This time in blog post format---check out
@harit_v
's awesome work!

1
6
16
Very excited about our fun new work on alignment with truly minimalist requirements! Next up---instant, personalized alignment for everyone?
Can we align pre-trained models quickly and at no cost? 🤔 Sounds challenging!
Our latest research tackles this question. Surprisingly, we found compelling evidence that it just might be possible! 🌟🔍
Preprint:
3
16
84
0
1
16
Weak supervision systems rely on crafting high-quality labeling functions, which is sometimes expensive. Can we automate this? Yes! I wrote an introduction for
@SnorkelAI
↓

0
5
15
Incredibly excited to share Snorkel work on enterprise alignment!

Excited to share our new focus on enterprise alignment: building for the real blockers of AI today
Ex: we make an LLM chatbot 99% compliant with an enterprise-specific financial analyst policy (+20.7 pts) in a few hrs. of programmatic development.
Blog:
1
10
16
0
1
13
Please reach out if you want to chat about data-centric ML, foundation models, geometric ML, or anything else.
Also come chat with my students
@dyhadila
,
@nick11roberts
,
@harit_v
,
@zihengh1
,
@Changho_Shin_
,
@srinath_namburi
!
0
2
11
At the
#DistShift
workshop, with
@zhmeishi
, Yifei Ming, Ying Fan, and Yingyu Liang, our work on improving domain generalization via nuclear norm regularization
1
1
9
Super excited to share new work from
@MayeeChen
and
@realDanFu
---let's make weak supervision more interactive!

1/2 Excited to share Epoxy: fast model iteration with weak supervision + pre-trained embeddings. We look at how to use pre-trained embeddings without the need for fine-tuning - model iteration in <1/2 second, instead of hours or days.
Paper on arXiv now:
1
4
13
0
2
8
Very excited to chair this year's AutoML Cup with
@nick11roberts
!

Announcing the AutoML Cup 2023!!! 🤖🏆📊
The AutoML Cup is an automated machine learning competition with a focus on diverse machine learning tasks and data settings — which will be part of the
@automl_conf
2023.
1
9
16
0
0
8
*Coming up* with Ramya Vinayak, our tutorial on automatic data set creation! Super excited for Monday!
1
0
7
@harit_v
showed how to make weak supervision work for almost *any* kind of label---opening up the way to use WS with structured prediction, with guarantees!

Excited to present our work on 💪🏋️ Lifting Weak Supervision to Structured Prediction 💪🏋️
@NeurIPSConf
this week! We’ll be in Hall J,
#334
at 4pm on Wednesday– drop by and chat with us!
#NeurIPS2022
[1/n]

1
4
21
1
0
7
• Improving pretrained models without training or data,
• Getting foundation models to learn skills faster,
• Figuring out how self-training techniques like autolabeling work,
• A new way to exchange model components,
• Making weak supervision fair,
•And a lot more!
1
0
6
@nick11roberts
and
@tu_renbo
presented NAS-Bench-360 a new NAS benchmark for diverse tasks, with
@atalwalkar
,
@khodakmoments
,
@JunhongShen1
Can’t wait to share NAS-Bench-360, our new Neural Architecture Search benchmark for diverse tasks at
@NeurIPSConf
next week!
Come chat with us on Tuesday in Hall J,
#1029
at 11:30!
#NeurIPS2022
[1/n]

1
9
25
1
0
7
@nick11roberts
presented our new benchmark for automating weak supervision, with lots of collaborators including
@XintongLi0501
,
@zihengh1
,
@dyhadila
and
@awsTO
Excited to share our Automated Weak Supervision benchmark at
@NeurIPSConf
next week!
We’ll be in Hall J,
#1029
at 11:30a on Thursday – drop by and chat with us!
#NeurIPS2022
[1/n]

2
12
39
1
1
6
0
1
5
Excited to chat!
(1/n) This week we have
@fredsala
on the Stanford MLSys Seminar, live on Thursday at 1:30 PM! Fred was a postdoc at
@StanfordAILab
, and is now a professor at
@WisconsinCS
and a research scientist at
@SnorkelAI
-- so he knows a thing or two about MLSys.
1
6
23
0
0
5
Excited to speak at at 1:30 PT! Will be sharing recent work on fusing weak supervision and structured prediction, freshly accepted at ICLR '22.
0
0
5
Last but not least at
#MP4PS2022
, with
@MayeeChen
and
@BPNachman
, new work applying weak supervision principles to improve anomaly detection in high energy physics
0
1
5
6. Also in collaboration with
@HazyResearch
and led by
@MayeeChen
, we introduce🍳Skill-It: a data-driven framework for understanding and training LMs (Spotlight!):

Large language models (LMs) rely heavily on training data quality. How do we best select training data for good downstream model performance across tasks? Introducing 🍳Skill-It: a data-driven framework for understanding and training LMs!
Paper: 1/13
7
127
461
1
0
4

Last but not least—fun new non-NeurIPS work that we’d love to chat about from my student
@dyhadila
. How do we get large pretrained models to effectively use all of that knowledge they’ve picked up on to become more robust, automatically?
While you’re waiting for NeurIPS decisions—check out a fun problem! Can we improve large pre-trained models’ robustness *without* getting more data and fine-tuning?
1
12
42
0
0
4
1. Led by my student
@nick11roberts
, we show how to improve your pretrained models using the geometry of the label space:
Tired of reading about superconductors?
Check out our new work that just hit arXiv: about rethinking how we get predictions out of classifiers, and how to incorporate the *geometry* of the labels —i.e., how labels relate to one another! ⚙️📐
[1/n]
4
15
82
1
0
4
We're excited for this line of work! Representation editing has the potential for huge gains in data efficiency---see awesome recent work ReFT on using this approach for fine-tuning

ReFT: Representation Finetuning for Language Models
10x-50x more parameter-efficient than prior state-of-the-art parameter-efficient fine-tuning methods
repo:
abs:
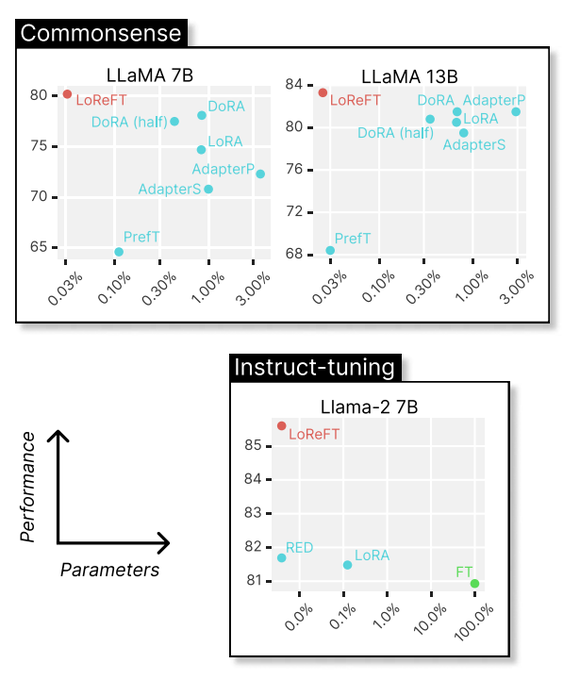
5
97
503
2
0
4
5. With
@HazyResearch
and led by
@NeelGuha
, a fun new work on supervision-free ways to improve LLM predictions via multiple representations:

We’re excited to share Embroid: a method for “stitching” together an LLM with embedding information from multiple smaller models (e.g., BERT), allowing us to automatically correct LLM predictions without supervision.
✍️:
📜:

2
48
209
1
0
4
3. Weak supervision is a powerful tool—but it can inject bias into datasets. How can we mitigate it and still get great performance? Our first effort, led by students
@Changho_Shin_
and
@SonNicCr
:
1
0
3
@ajeet
@chamii22
@_albertgu
@HazyResearch
You might also want to check out some of our general results for hyperbolic tree representations, especially tradeoffs and limitations:
0
0
2
More recently, we've been thinking about how to use representation editing to "program" model behavior---especially for alignment! More on this from our group soon.
1
0
2
If you have a chance, come chat with
@Changho_Shin_
!
We'd love to hear your thoughts and ideas about data-centric approaches to
#LLM
adaptation and alignment.
0
0
2
Spoiler: yes, and we extend many of the benefits of weak supervision---flexibility, efficiency, and theoretical guarantees. Come by for more!
1
0
1
@SouadH9
Yes, but unlike eigendecomposition, it decomposes a matrix into a sum (not a product). The two components in the sum are low-rank and sparse. The paper that introduced this idea is
2
0
1
@KartikSreeni
@davisblalock
Probably you've tried this for your paper already---awesome work!---but have you tried varying the base beyond base 10 in your training data to try to force the model to better understand the concept of 'carries'?
2
0
1
Weak supervision has been awesome at automatically 🤖 creating large labeled datasets for model training, but how do we get it to work for the rich label types used in structured prediction?
1
0
1
@SouadH9
There, the idea is to do PCA (a low-rank decomposition) even when the matrix is affected by sparse noise. For us, the "noise" is the sparse inverse covariance structure and the low-rank part comes from the fact that there's a latent variable so we don't get to observe everything
1
0
1
@SouadH9
Points in manifolds are just one example. In that case, we need to generalize the machinery of learning labeling function accuracies by using distances. See and
0
0
1