

David Andrés 🤖📈🐍
@daansan_ml
Followers
11,305
Following
404
Media
841
Statuses
9,323
📈 I summarise Machine Learning, NLP and Time Series concepts in an easy and visual way • 💊Follow me in 👉 Inquiries in david @mlpills .dev
Spain
Joined May 2022
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Kyiv
• 431105 Tweets
LINGORM TSOU EP3
• 179134 Tweets
#ใจซ่อนรักEP3
• 174483 Tweets
#海のはじまり
• 104965 Tweets
Smeraldo Garden
• 102125 Tweets
#HappyBirthdayARMY
• 76260 Tweets
Kiev
• 75632 Tweets
STRAY KIDS WORLD TOUR
• 69317 Tweets
Houston
• 63407 Tweets
石丸構文
• 49698 Tweets
Morning Joe
• 45572 Tweets
#マウンテンドクター
• 44160 Tweets
XO MV TEASER 1
• 43442 Tweets
MIS TÍAS IS COMING
• 37898 Tweets
LATAM
• 36251 Tweets
Greenwood
• 34408 Tweets
進次郎構文
• 28410 Tweets
配信視聴
• 24691 Tweets
THANK YOU KIM TAEHYUNG
• 24345 Tweets
TYPE 1 BY V OUT NOW
• 23866 Tweets
KSPO
• 22455 Tweets
Kh-101
• 19409 Tweets
弥生さん
• 17434 Tweets
THE PIECE OF PEACE RETURN
• 16825 Tweets
海ちゃん
• 16616 Tweets
不要不急の外出
• 15183 Tweets
しんちゃん
• 12140 Tweets
니콜라스
• 10964 Tweets






















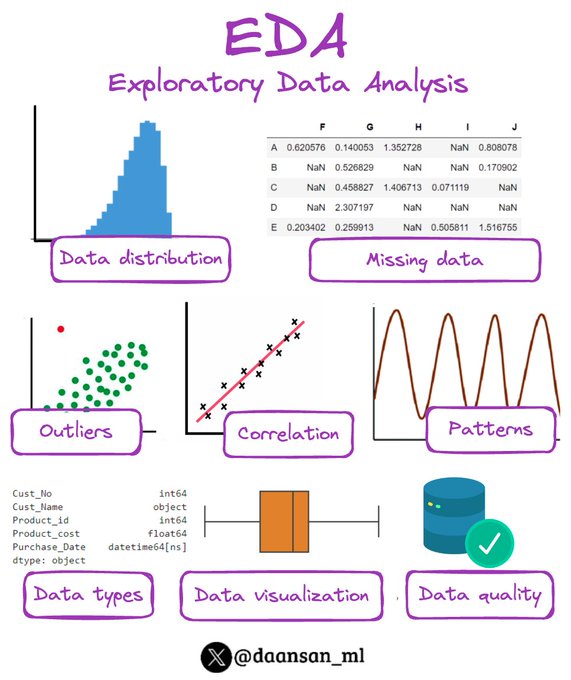
Exploratory Data Analysis (EDA) is a process used for investigating your data to discover patterns, anomalies, relationships, or trends using statistical summaries and visual methods.
Let's find out more 🧵👇
17
646
3K
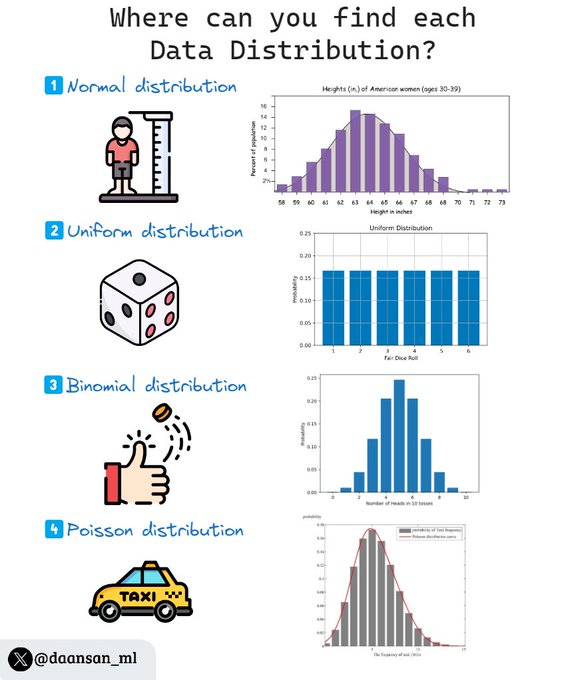
In Data Science you can find multiple data distributions...
But where are they typically found? 🤔
This is part 1 - tomorrow I'll share the second one!
Check it out 🧵👇
14
362
2K
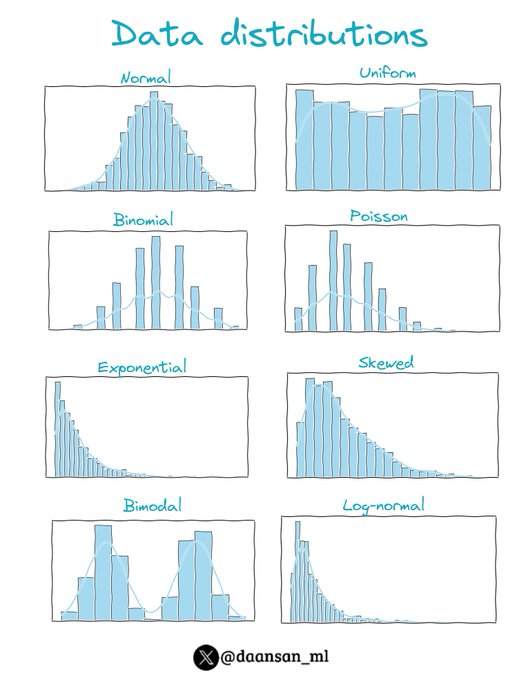
There are several types of data distributions you might encounter in a dataset.
Here are some common ones 👇🧵
18
256
1K
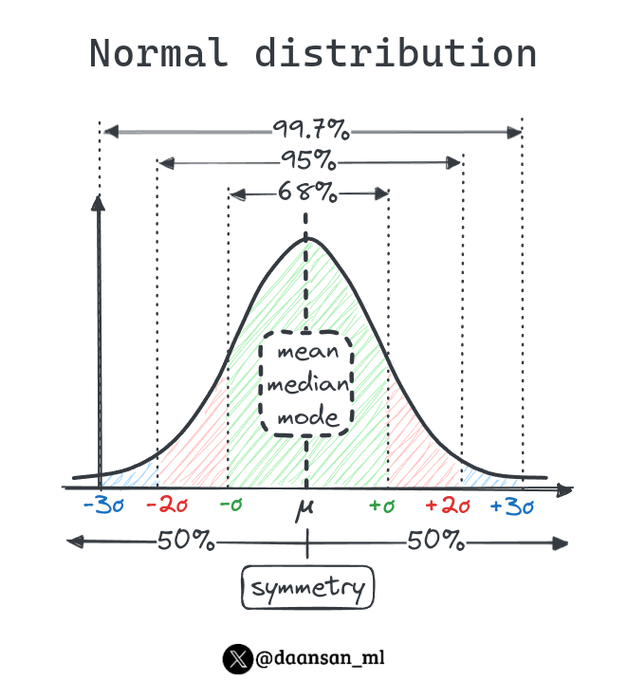
Is your data normal? 🤔
What I meant is if your data follows a normal distribution...
Discover this elegant distribution 🧵👇
13
265
1K

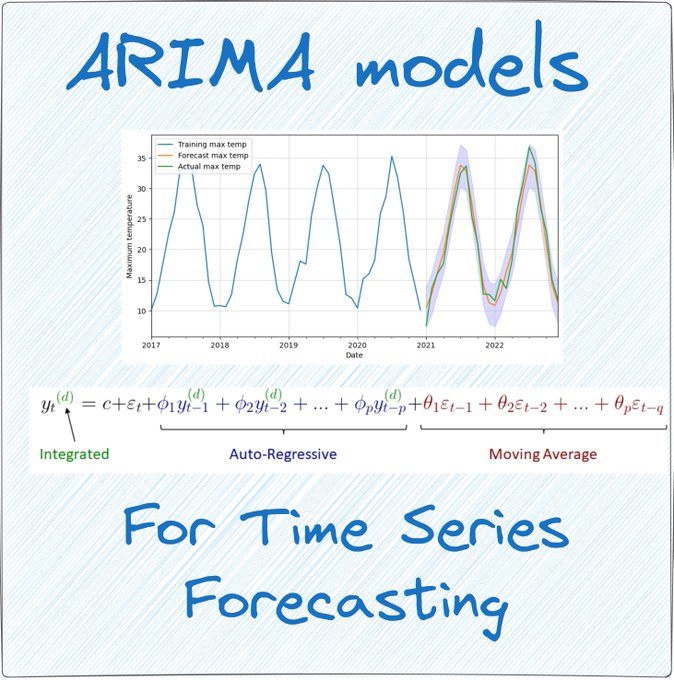
ARIMA is one of the most popular traditional statistical methods used for time series forecasting.
THREAD 🧵 👇
19
178
889
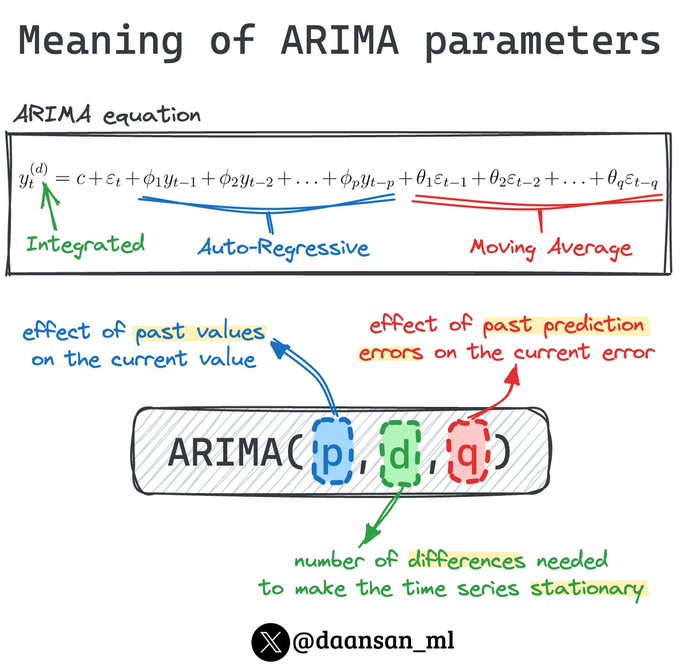
ARIMA models have three parameters: 'p', 'q' and 'd'.
They need to be optimized... but, before that, do you know how to interpret each of them?
Learn what each of them mean here 🧵 👇
13
198
811
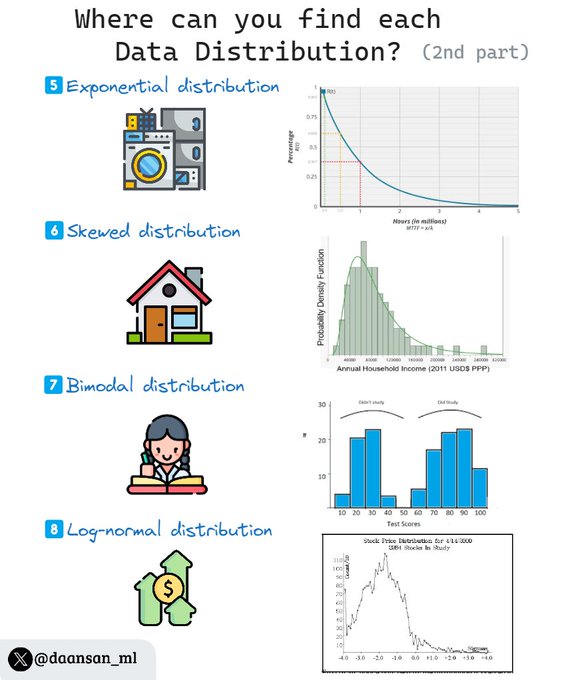
Where can you find the most common data distributions? (2nd part)
Check this thread for real-world examples! 🧵 👇
7
156
764
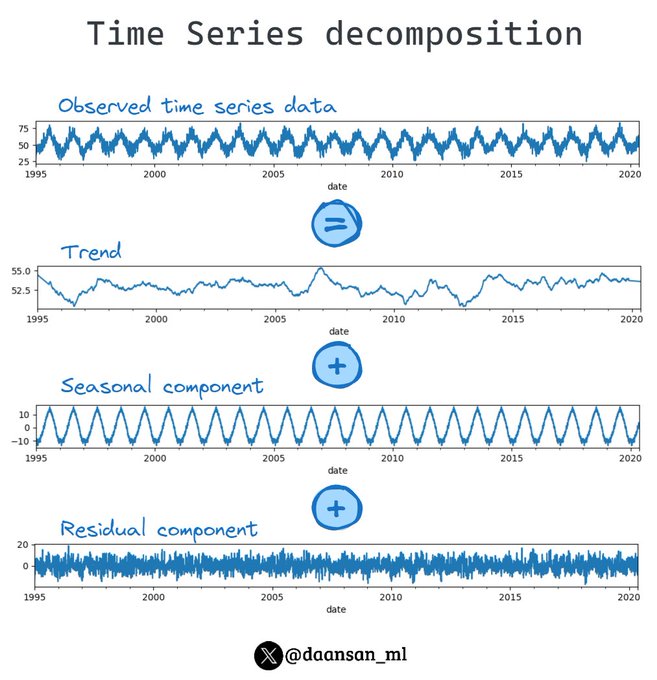
Time Series data with seasonality?
Split it into its main 3 components!
Check an example here (code at the end) 👨💻
🧵 👇
7
145
747
Are you familiar with the most common Machine Learning algorithms?
Today, I introduce 6 of the most commonly used ones!
Check them out 🧵 👇
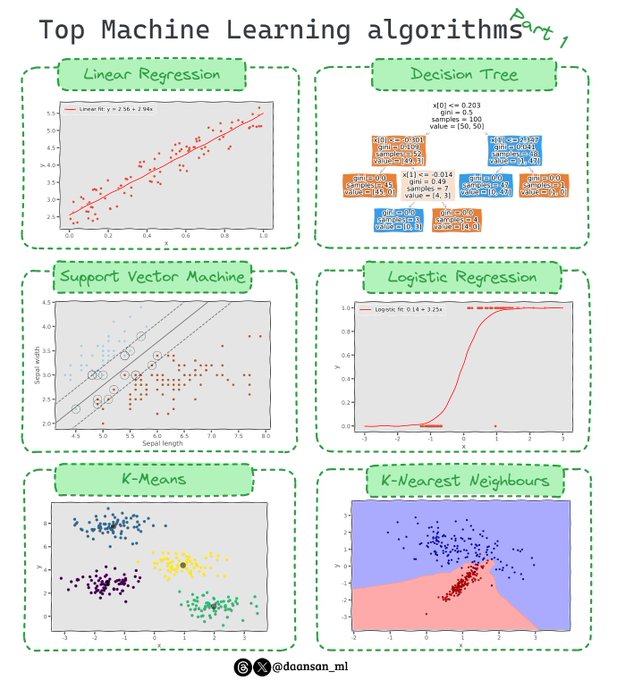
10
193
730
ARIMA models are essential in Time Series forecasting.
You can add multiple components to make them fit your particular data:
go from a basic AR model to a complex SARIMAX model! 🧵 👇

17
163
715
ARIMA is one of the most popular traditional statistical methods used for time series forecasting.
THREAD 🧵 👇
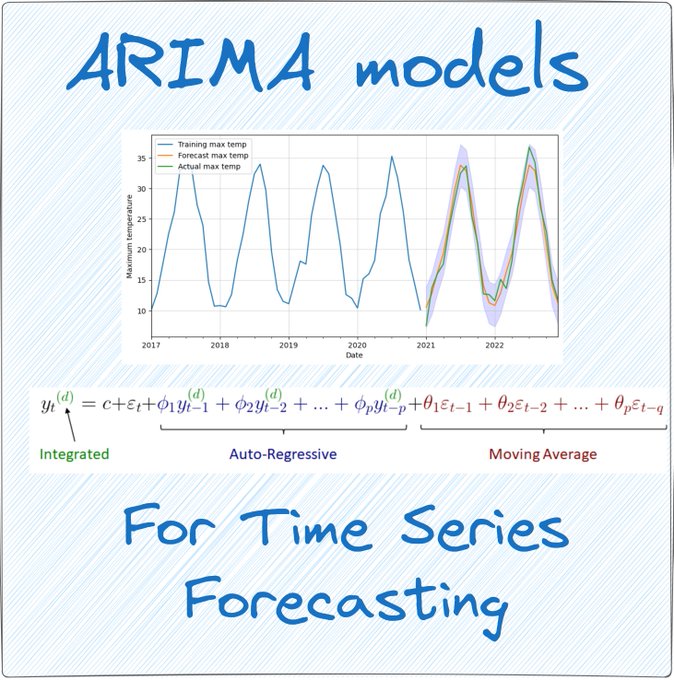
10
145
694
ARIMA is one of the most popular traditional statistical methods used for time series forecasting.
THREAD 🧵 👇
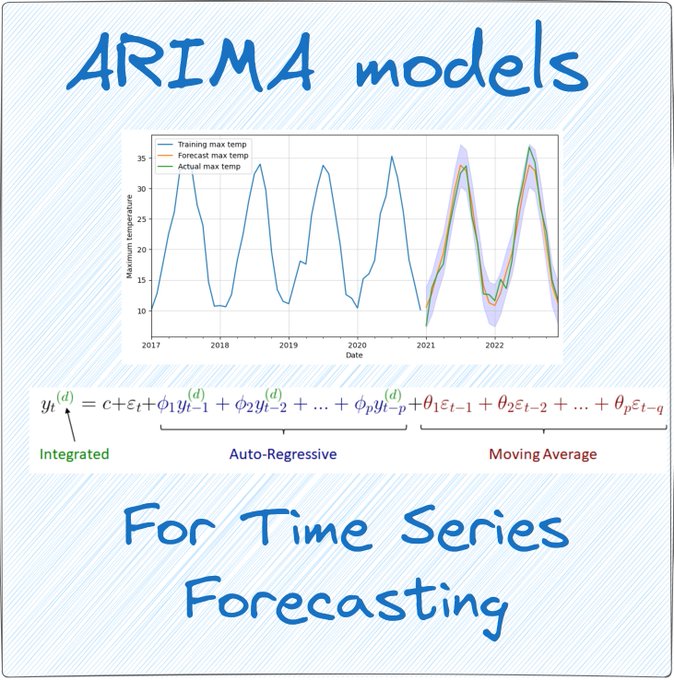
21
145
680
Volatility can be a big problem in Time Series forecasting!
Be careful with it:
✅ Low volatility
❌ High volatility
Learn how you can take it into account 🧵👇
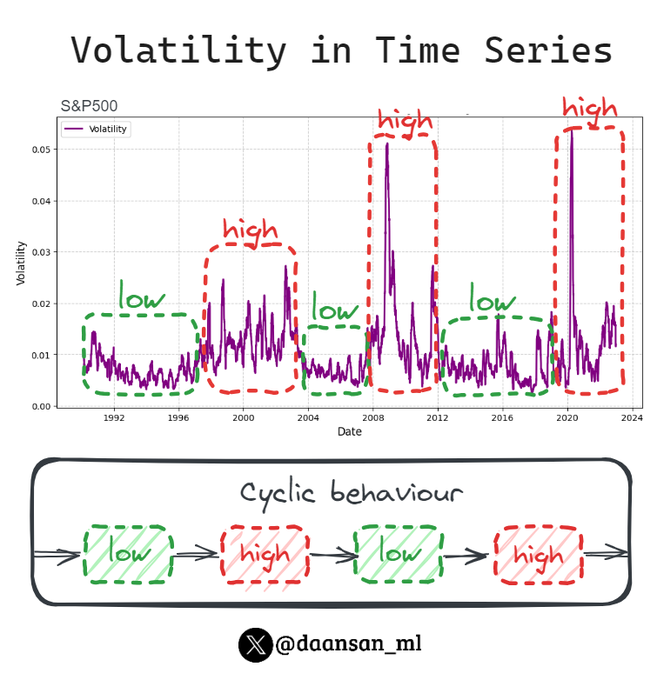
14
135
678
Do you want to forecast seasonal time series data?
Remove the seasonality and add it back at the end! That's basically what STL method does.
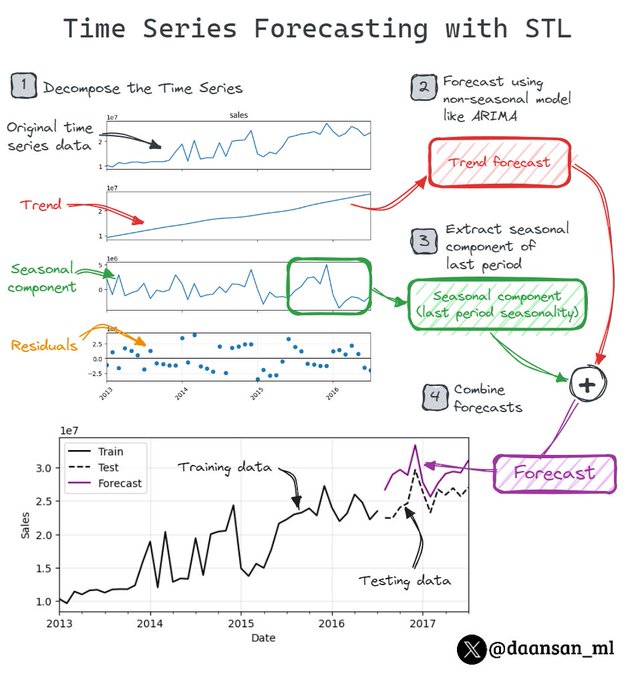
7
140
656
ARIMA is really useful for time series forecasting, however you can only forecast 1 variable at a time...
VAR (Vector AutoRegression) solves this problem!
Discover more 🧵 👇
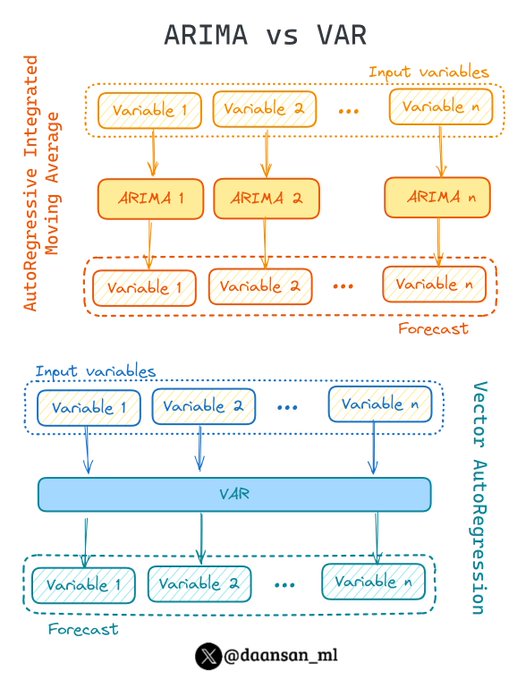
9
153
658
Do you have outliers in your data?
What should you do with them? 🤔
Here's a guide on effectively managing them 🧵 👇
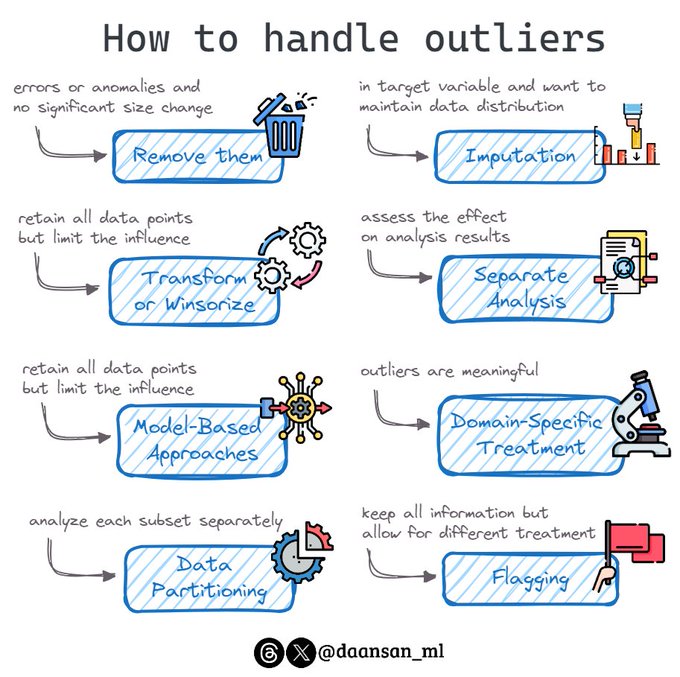
16
158
648
How can you detect outliers?
But first of all, what are outliers? 🤔
🧵 👇
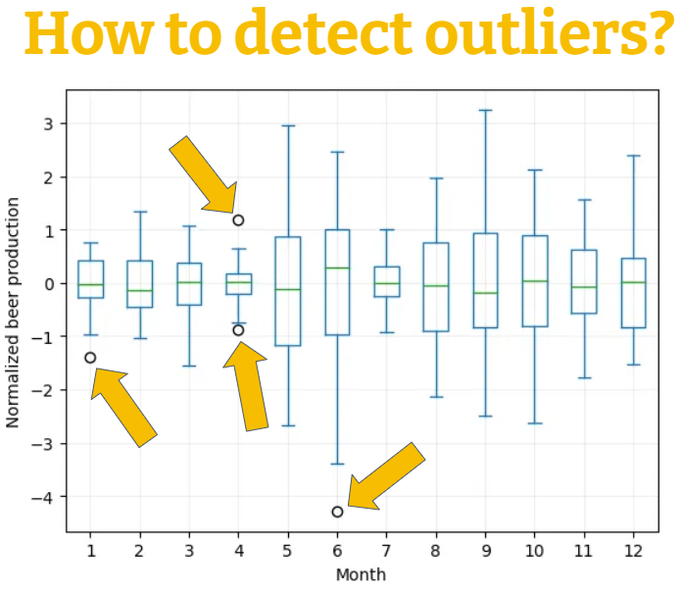
20
145
602
⭐ Time Series is an essential skill in Data Science.
You don't know where to start?
Here you have a roadmap for you to start on the right foot!
Have a look 👇 🧵

13
148
595
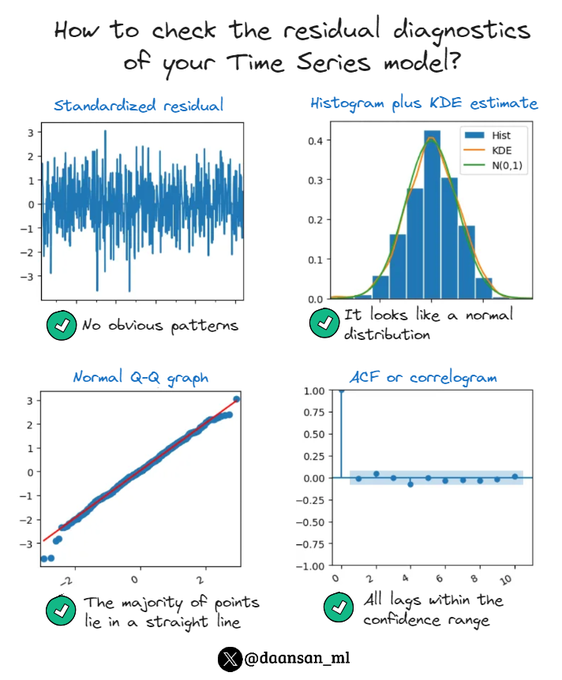
After fitting a Time Series model such as ARIMA, you should always check the 𝗿𝗲𝘀𝗶𝗱𝘂𝗮𝗹 𝗱𝗶𝗮𝗴𝗻𝗼𝘀𝘁𝗶𝗰𝘀 to assess how well your model captures all the patterns in the data.
See how to do it 👇
9
130
586

In Data Science you can find multiple data distributions...
But where are they typically found? 🤔
This is part 1 - tomorrow I'll share the second one!
Check it out 🧵👇

4
112
571
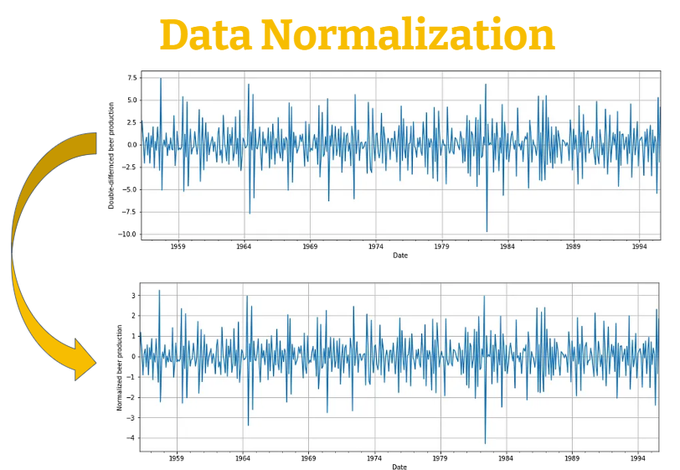
What is data normalization, and how can it be achieved?
Let's find out more about this!
🧵 👇
11
114
553
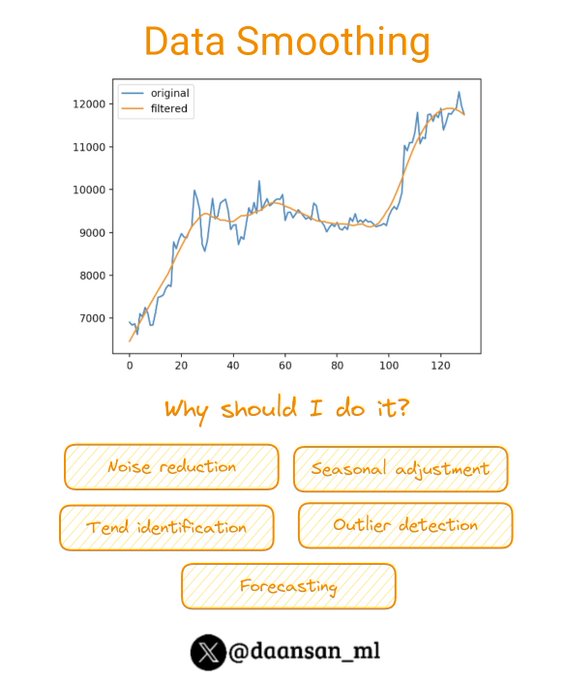
What is data smoothing?
...and why may you need it? 🤔
Read this thread to learn more about it!
🧵 👇
9
112
550
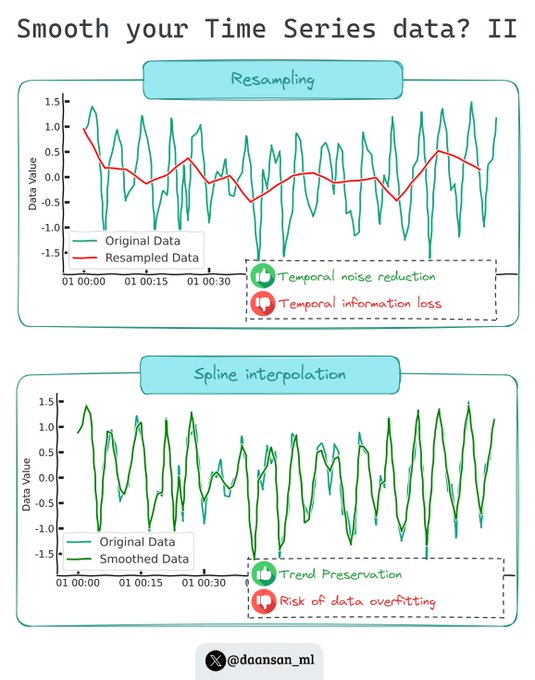
Your data is possibly too noisy!
You can try these 2️⃣ techniques to discover its trend, seasonality or even outliers! 🧵 👇
10
98
543
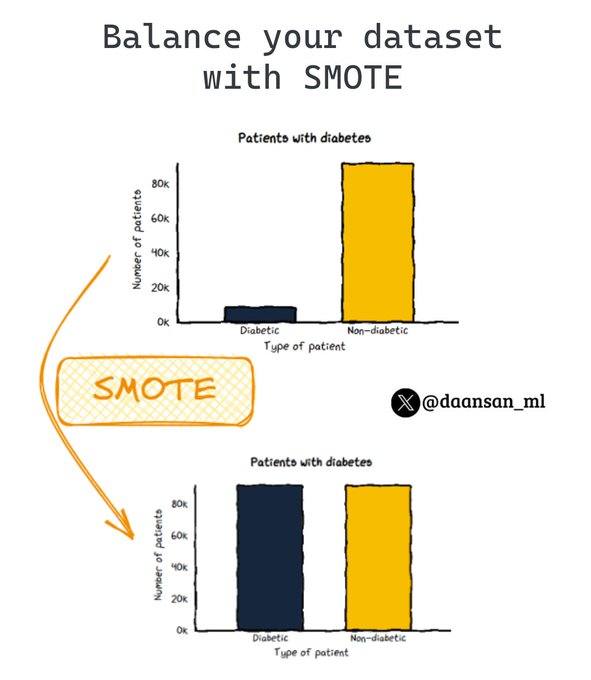
Having an imbalanced dataset is a problem. 😟
Discover SMOTE, it can help you deal with this!
🧵 👇
32
87
537
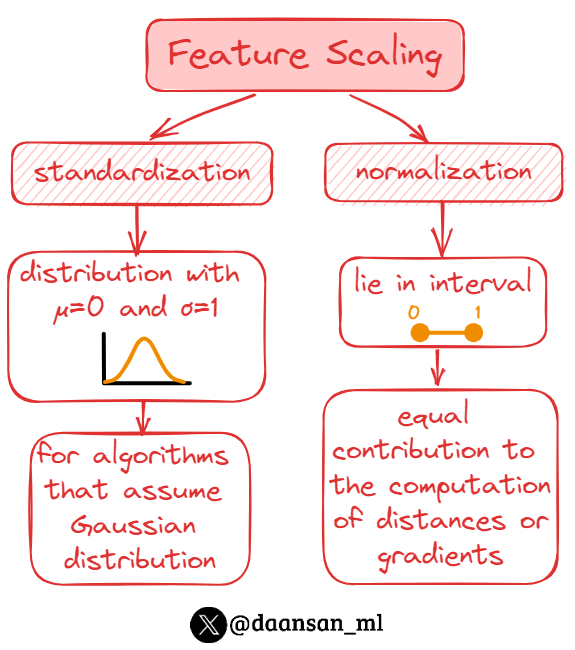
Data preprocessing is a crucial step in the machine learning pipeline, ensuring that the dataset is ready for training.
One essential aspect of data preprocessing is ✨feature scaling✨, which involves adjusting the range and distribution of the data.
🧵 👇
7
106
533
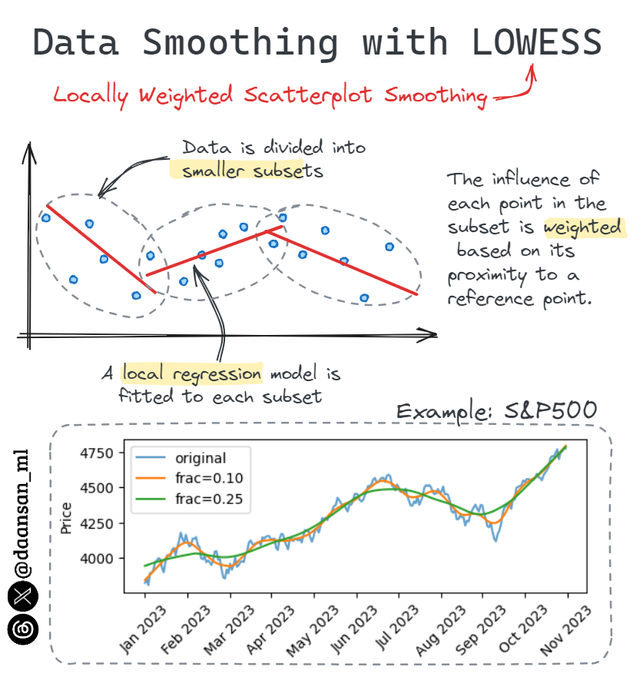
Do you want to identify outliers or find a global trend in your Time Series data?
LOWESS may be what you are looking for!
It means Locally Weighted Scatterplot Smoothing, and you can find out more about it here 🧵 👇
10
100
533
5 great courses to learn Time Series Analysis and Forecasting in Python
🧵👇👇👇

11
121
527
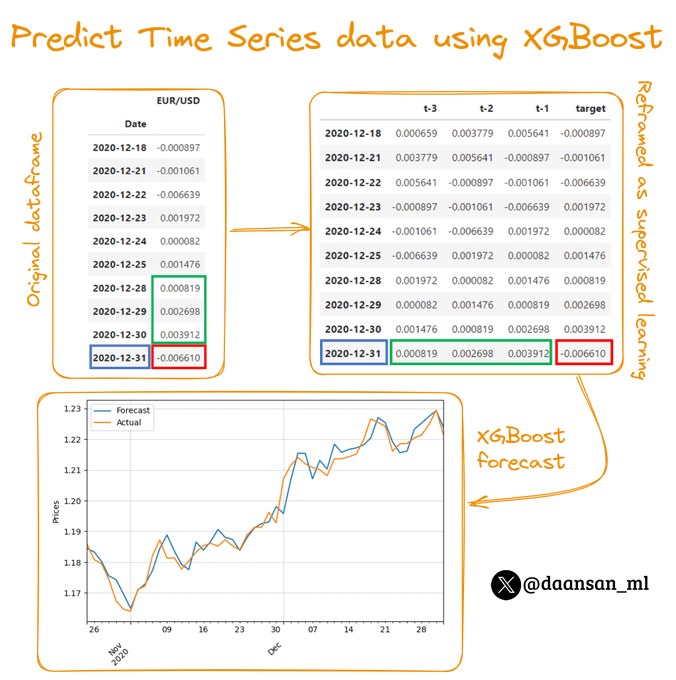
You can forecast Time Series data using a Machine Learning algorithm like XGBoost or Random Forest.
However, you need to reframe your problem as a Supervised Learning one.
Learn here how to do it 🧵 👇
9
109
524
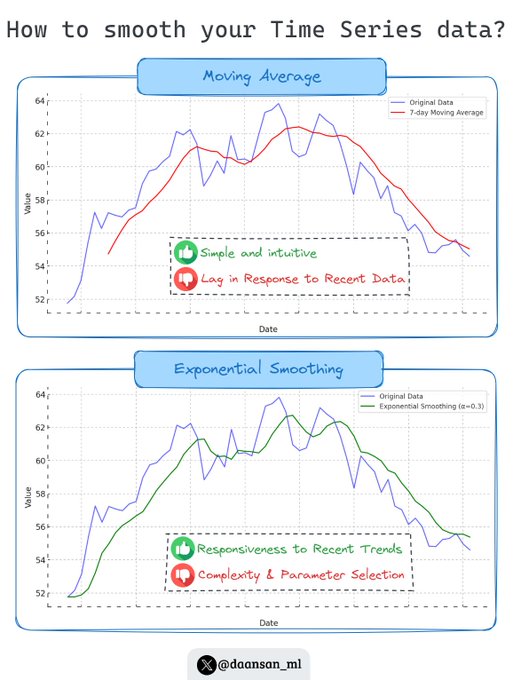
🚨Your data may be hiding a trend, seasonality or even outliers !!
Let's learn 2️⃣ basic techniques to smooth your data and get rid of the noise 🧵 👇
14
100
522
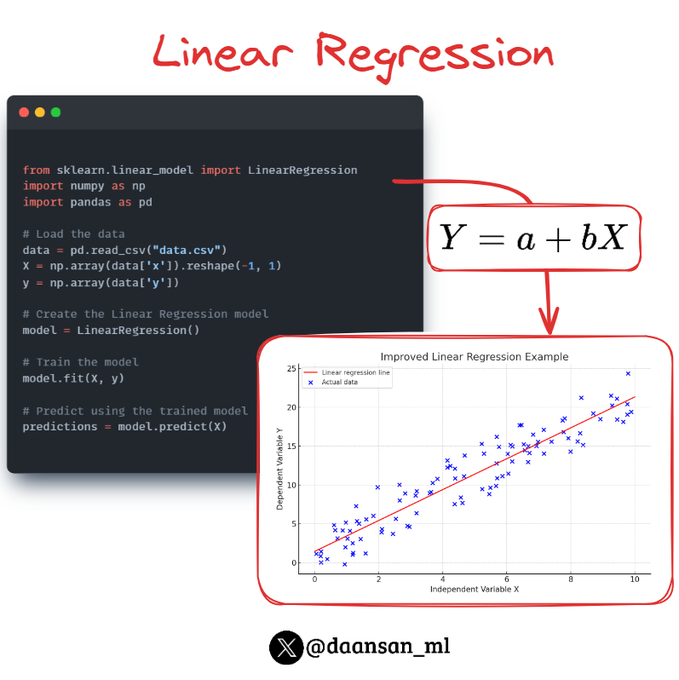
Linear Regression is a fundamental algorithm in supervised Machine Learning used for predictive modeling.
Learn more about it here 🧵 👇
12
107
517
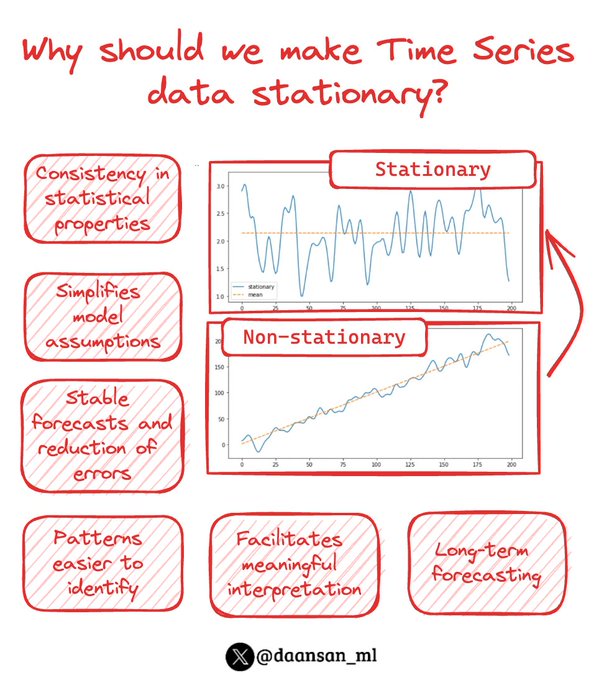
Time Series Forecasting plays a crucial role in predicting future values based on historical patterns.
However, most of the time, to achieve accurate and reliable results, one of the key prerequisites is working with stationary data.
But, why is that? 🤔
🧵 👇
5
87
510
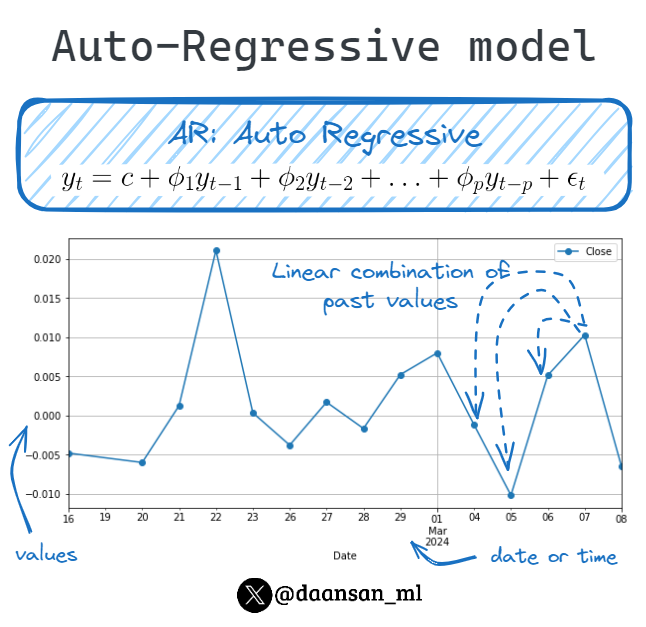
In the ARIMA methodology, the AR part stands for Auto-Regressive model.
An AR model suggests that the current value of a time series is a linear combination of its previous values and a random error term.
Let's find out more about it! 👇 🧵
9
112
503
You can forecast Time Series data using a Machine Learning algorithm like XGBoost or Random Forest.
However, you need to reframe your problem as a Supervised Learning one.
Learn here how to do it 🧵 👇
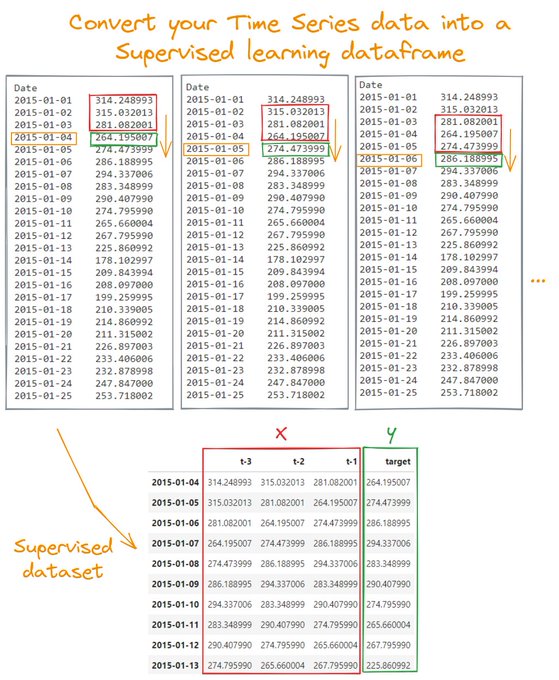
3
118
495
Make sure your model is considering all your data features equally!
Scaling can be your life saver!
Learn how to do it when you have normally distributed features 🧵👇
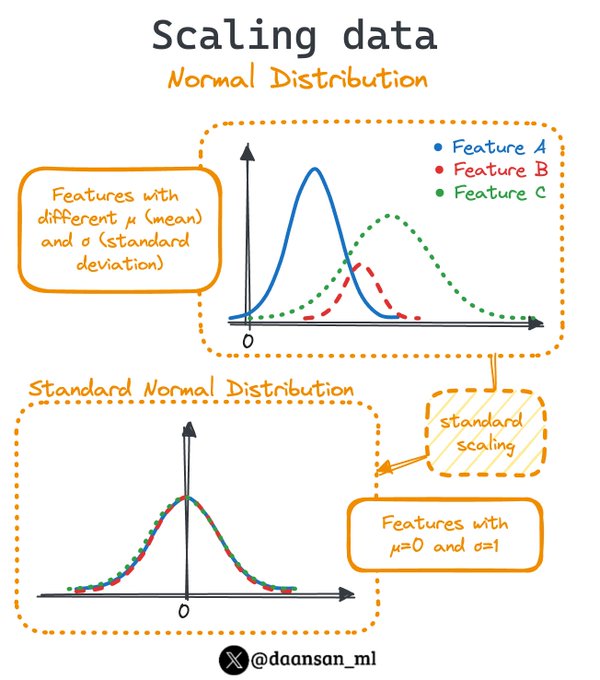
13
105
479
Discover how Kernel Smoothing can discover hidden trends in your data!
Do you know this Data Smoothing technique?
Find out more here 🧵 👇
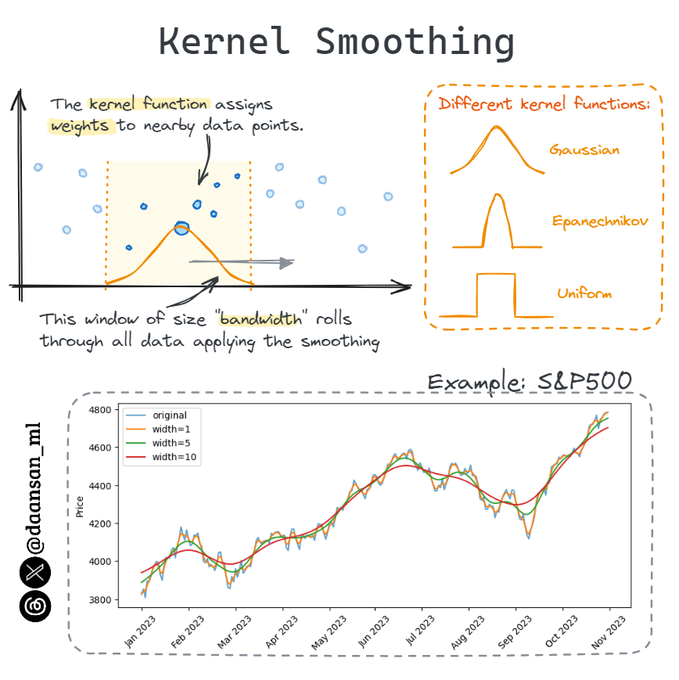
7
104
482
Stationarity is a property of a Time Series where its statistical features such as mean and variance remain constant over time.
It's crucial for Time Series analysis because many statistical models assume stationarity for reliable forecasts.
Find out how to check it 🧵👇
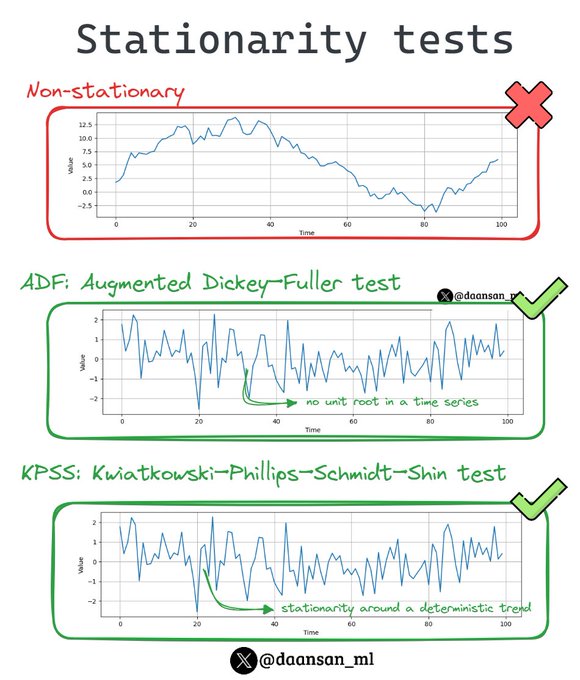
12
119
464
What is the difference between Classification and Regression in Machine Learning? 🤔
🧵 👇

13
114
442
Too much noise on your time series data?
Looking for hidden trends?
You may want to consider data smoothing.
Here's when to use it 🧵 👇
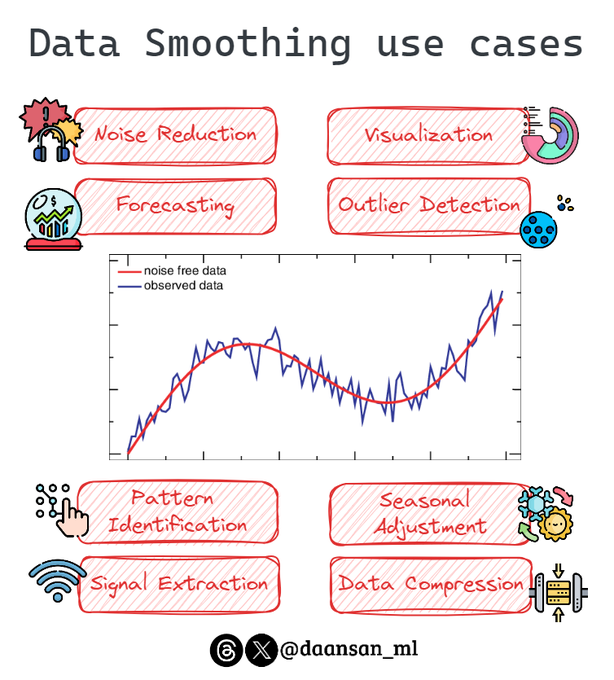
5
85
453
In this week's 💊MLPills we talk about how to discover the Data Distribution of your dataset features.
Join almost 5000 subscribers and don't miss any future issues... for free!
(Check next tweet)
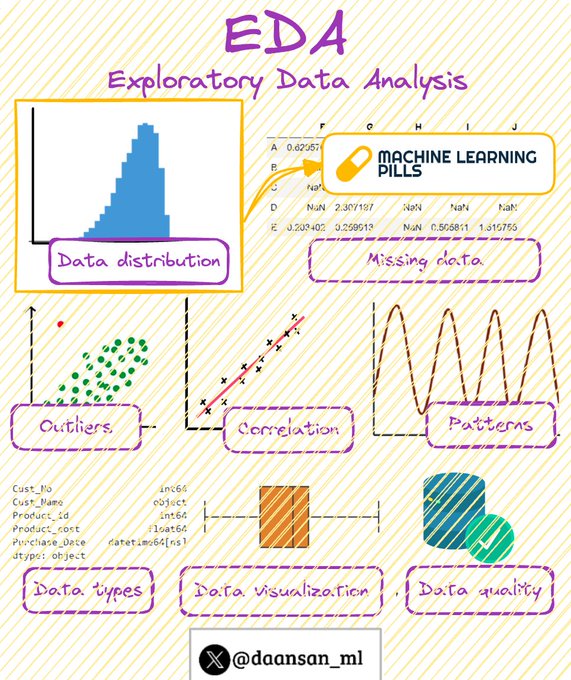
3
95
445
What is the difference between Classification and Regression in Machine Learning? 🤔
🧵 👇

4
93
418
ARIMA is one of the most popular traditional statistical methods used for time series forecasting.
Let's understand its components 🧵 👇
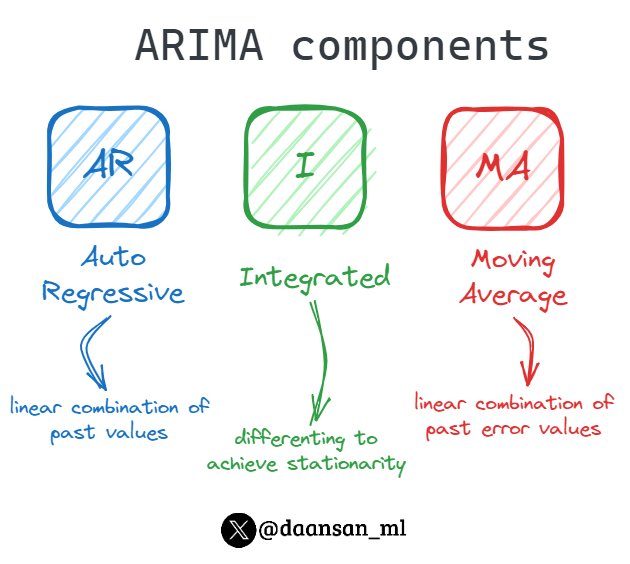
6
97
418
You've trained your ARIMA model, but is it a good model?
Today you'll learn how to evaluate the performance of your model.
Also when to use each metric 🧵👇
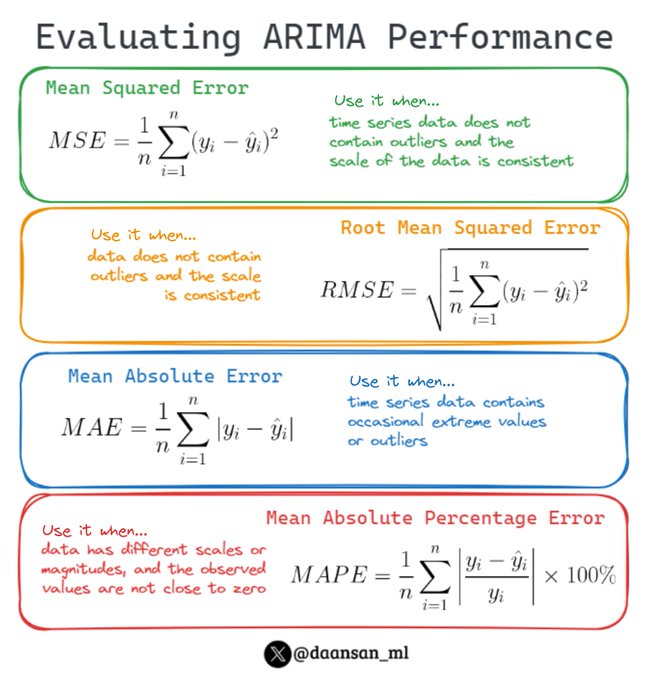
6
105
411
Retrieval Augmented Generation (RAG) for LLM systems clearly explained 👇

6
104
491
How can you estimate a suitable value for 'p' in your ARIMA model?
Here you have the definite guide! 🧵👇
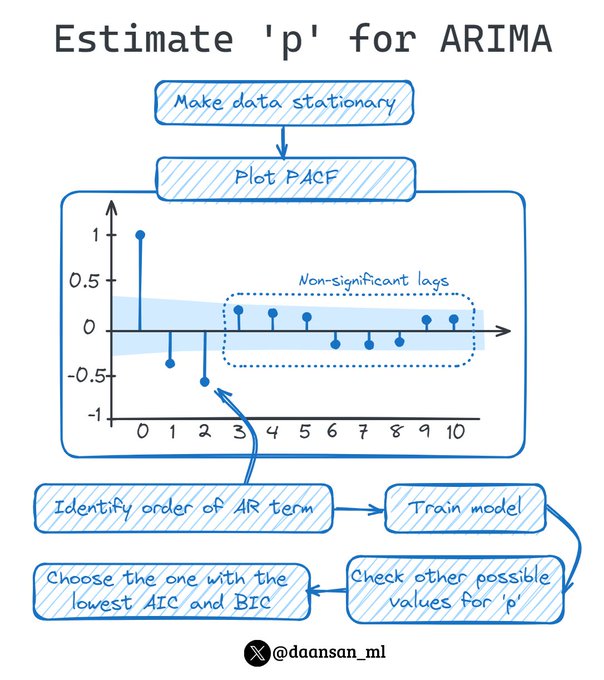
8
83
398
Have you chosen the best model?
You may want to check AIC and BIC.
Let's explore what they are and how they can help in finding the optimal ARIMA model 🧵👇
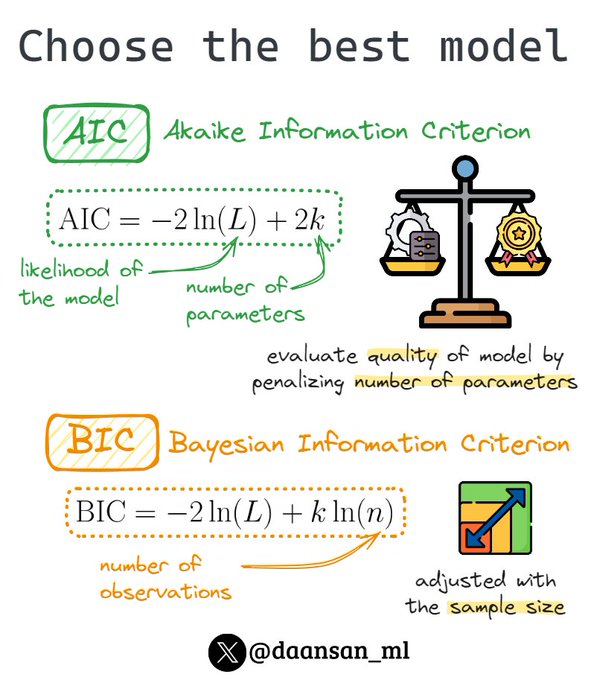
12
112
395
XGBoost is powerful and very well-known.
But it's not the absolute best for every single case...
Find out how to choose between the best 3️⃣ algorithms for tabular data 🧵👇

12
82
396
Creating the right features for Time Series data can make a significant impact on the performance of your model.
Today I'll introduce 2 key ones, essential for capturing the sequential aspect of time series! 🧵👇
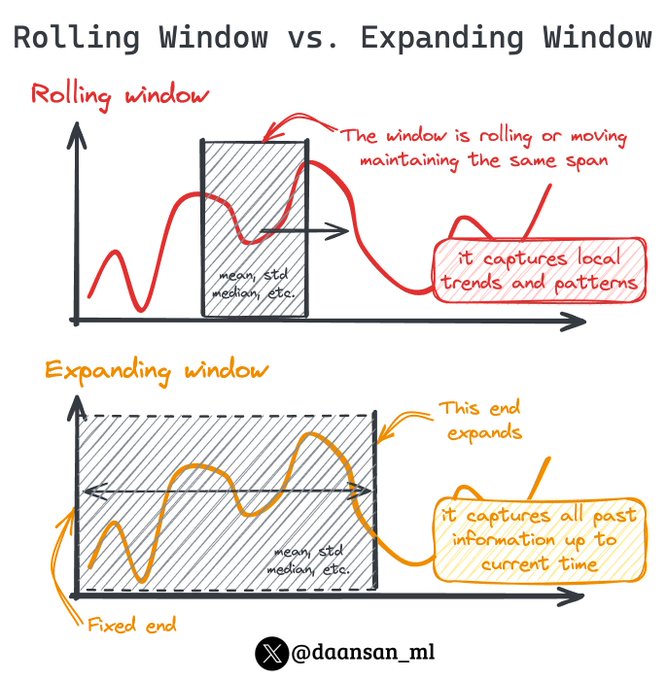
9
76
388
Understanding feature importance in machine learning models is essential for interpreting their predictions.
Today I'll share with you 2 methods to get it 🧵 👇
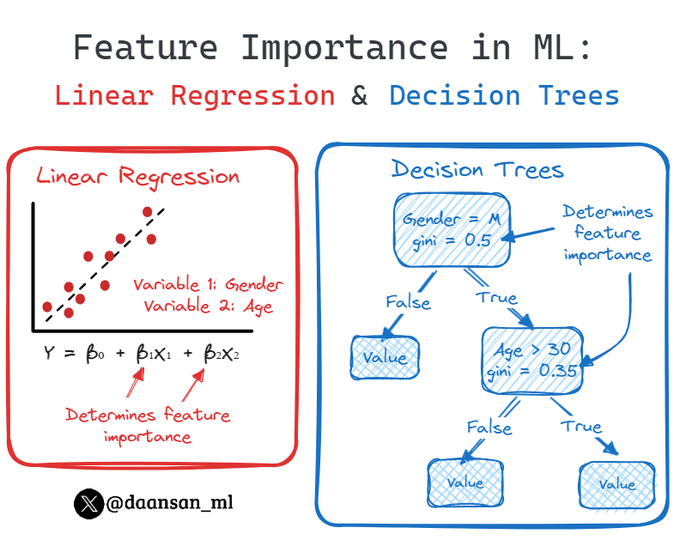
8
82
384
🚨NEVER split your data randomly!
At least when working with Time Series data...
Learn here what are the dangers of doing so 🧵 👇

13
76
383
Do you need to build an ARIMA model.... but you don't want the hassle of selecting the parameters to find the optimal model? 😟
Say hello to autoArima!
It simplifies the process of selecting the best ARIMA model.
👇 🧵

12
77
358
What is the difference between seasonality and cyclicality in time series forecasting❓
Discover it below 👇
🧵
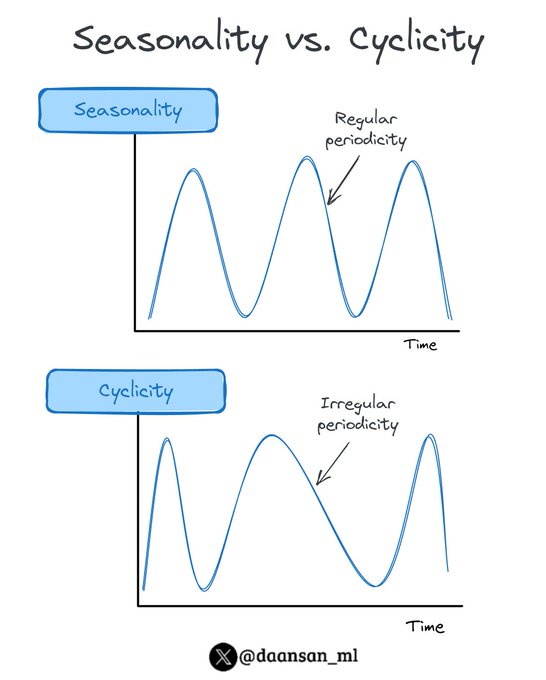
6
91
359
You can forecast Time Series data using a Machine Learning algorithm like XGBoost or Random Forest.
However, you need to reframe your problem as a Supervised Learning one.
Learn here how to do it 🧵 👇
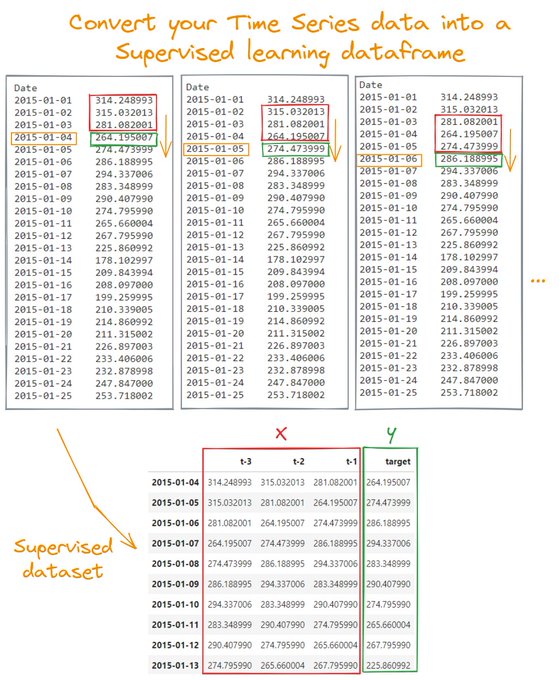
11
81
356
ACF and PACF are two important concepts in time series analysis, especially if what you need is an ARIMA model!
Let's understand what they are🧵 👇

9
88
350
In time series analysis, the trend component is key.
It indicates the directional movement of data over time.
Let's learn more about the trend 👇🧵
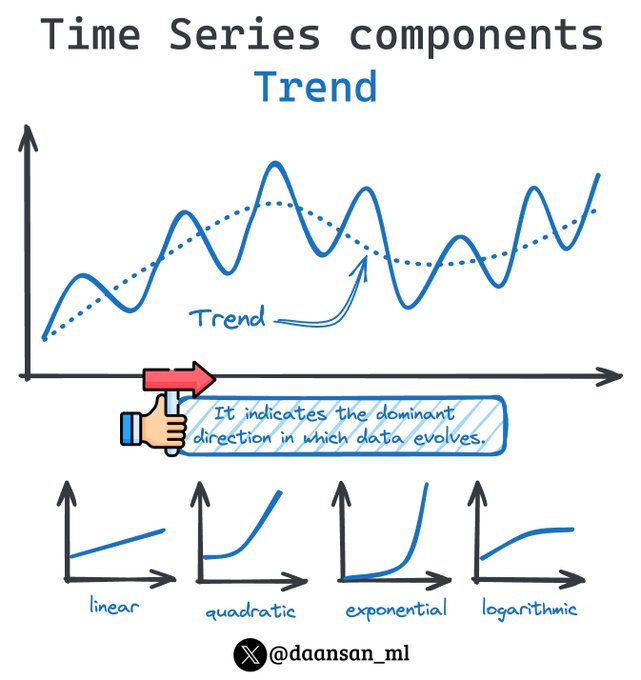
7
87
351
After fitting a Time Series model such as ARIMA, you should always check the 𝗿𝗲𝘀𝗶𝗱𝘂𝗮𝗹 𝗱𝗶𝗮𝗴𝗻𝗼𝘀𝘁𝗶𝗰𝘀 to assess how well your model captures all the patterns in the data.
See how to do it 👇 🧵
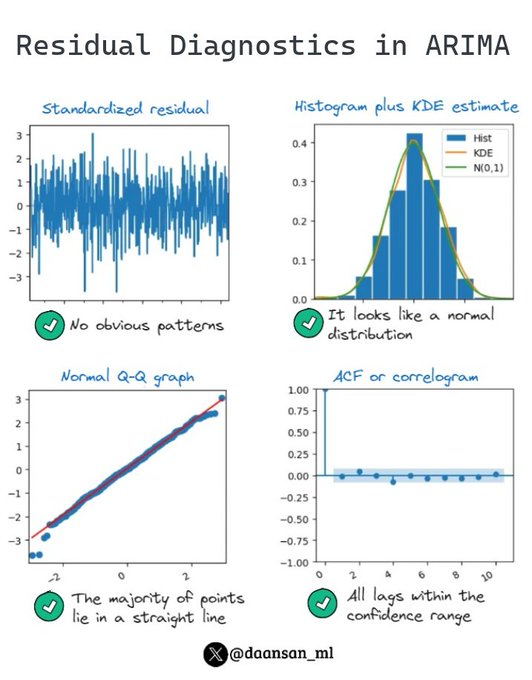
4
85
354
Time Series analysis and forecasting is a really valuable skill to have in your Data Science toolkit.
Here are 4️⃣ reasons WHY you should learn it...
Do you agree? 🧵👇

11
77
346
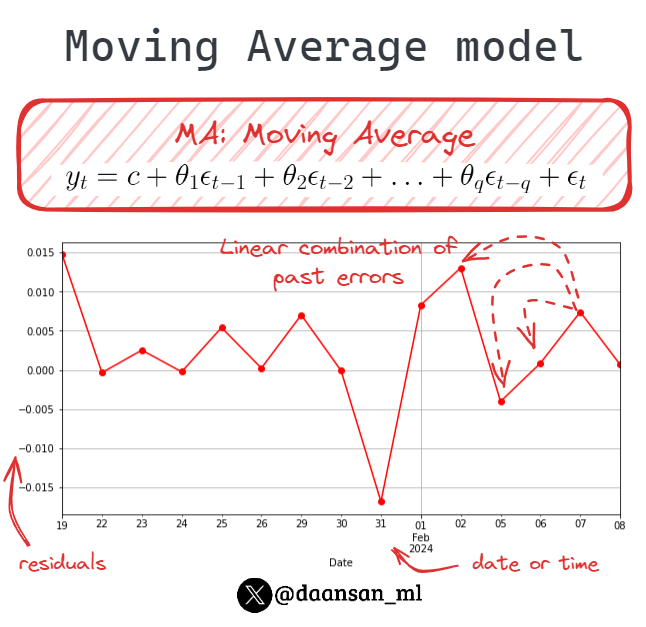
In time series analysis and forecasting, the Moving Average (MA) model plays a crucial role within the ARIMA framework.
Let's delve into what it entails! 👇 🧵
5
91
341
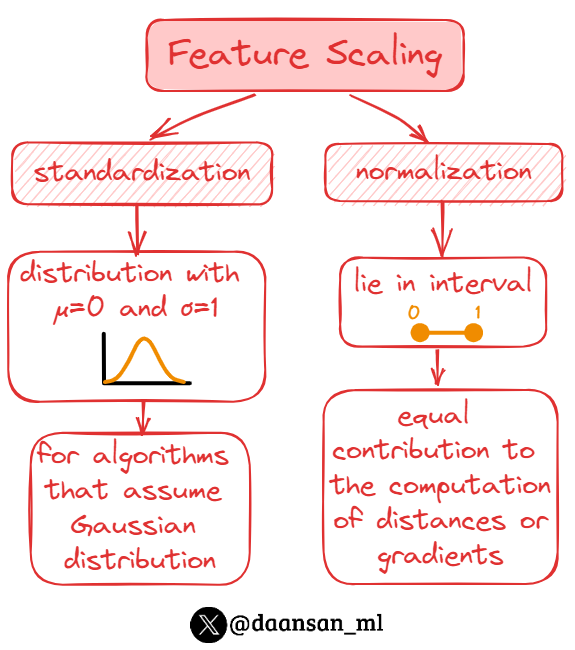
Data preprocessing is a crucial step in the machine learning pipeline, ensuring that the dataset is ready for training.
One essential aspect of data preprocessing is ✨feature scaling✨, which involves adjusting the range and distribution of the data.
🧵 👇
7
76
332
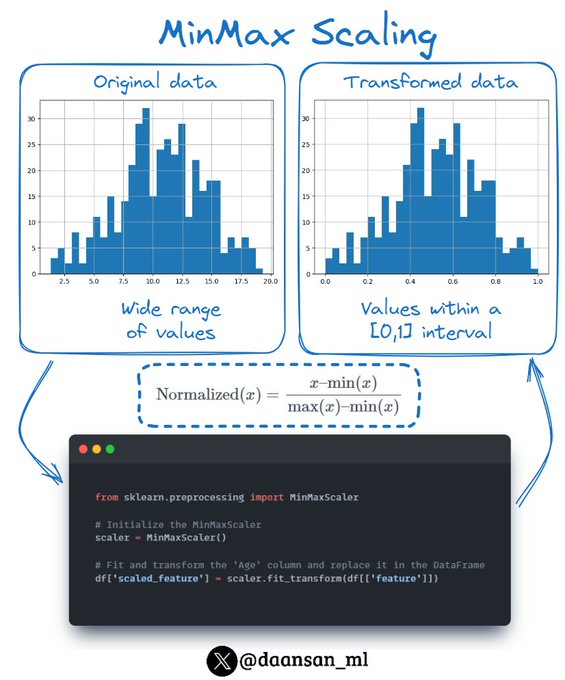
Discover one of the most used feature scaling techniques:
✨Min-Max Scaling✨
🧵 👇
12
59
324
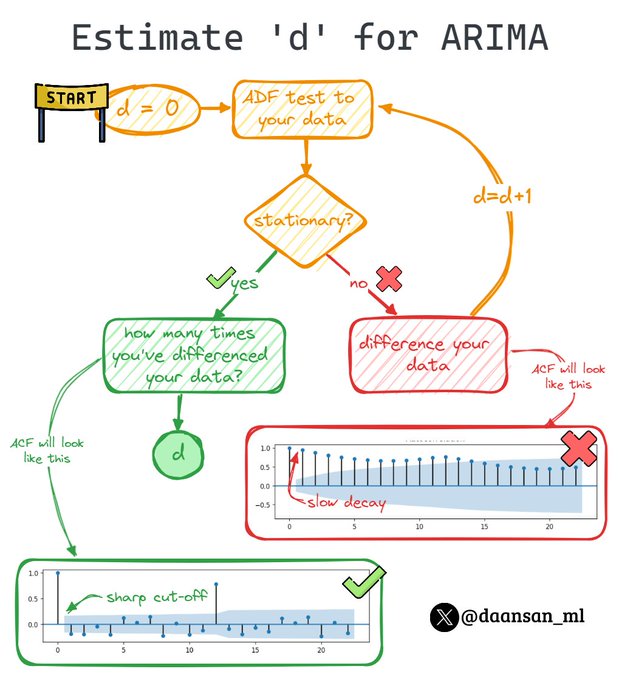
Which value of "d" should you choose for your ARIMA model?
Today I present an easy method to find it! 🧵 👇
6
78
322
Generating or engineering features from Time Series data when using an ML approach involves extracting meaningful information that can be used by algorithms to understand patterns, make predictions, or identify trends.
Here are some feature engineering techniques 🧵👇

15
90
325
Prophet is an open-source library developed by Facebook for Time Series Forecasting and has many advantages.
Find 6️⃣ of them below 🧵 👇
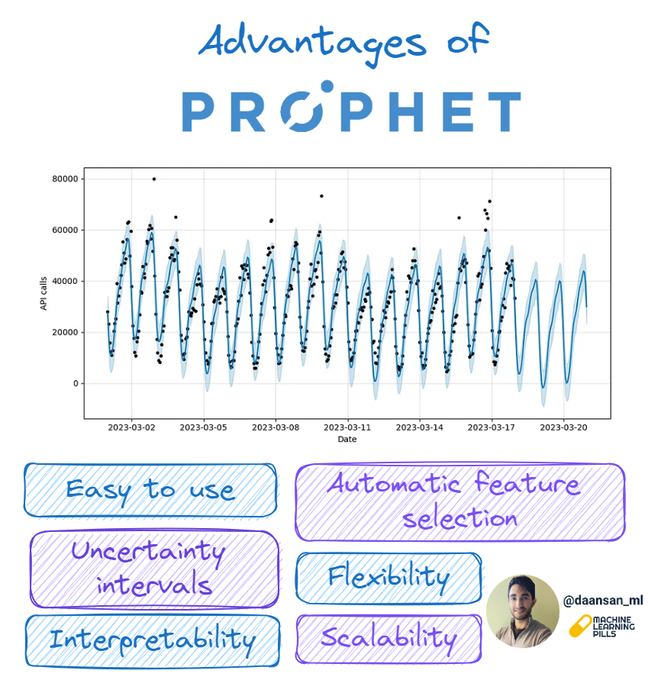
7
59
318
What is missing data?
Missing data refers to the absence of values in a dataset where they are expected.
It can arise from various reasons, such as:
▶️Data Entry Errors: Human errors during data entry can lead to missing values. For instance, someone might forget to fill in a
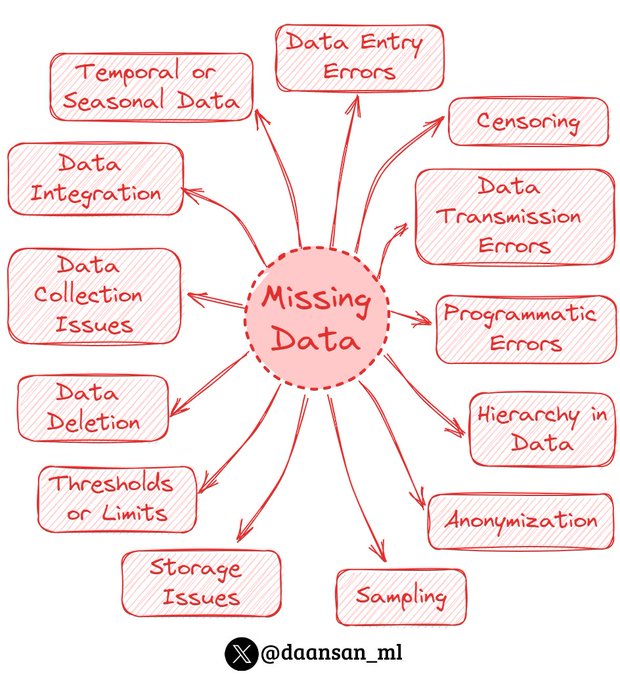
10
87
318
What is the difference between seasonality and cyclicality in time series forecasting❓
Discover it below 👇
🧵
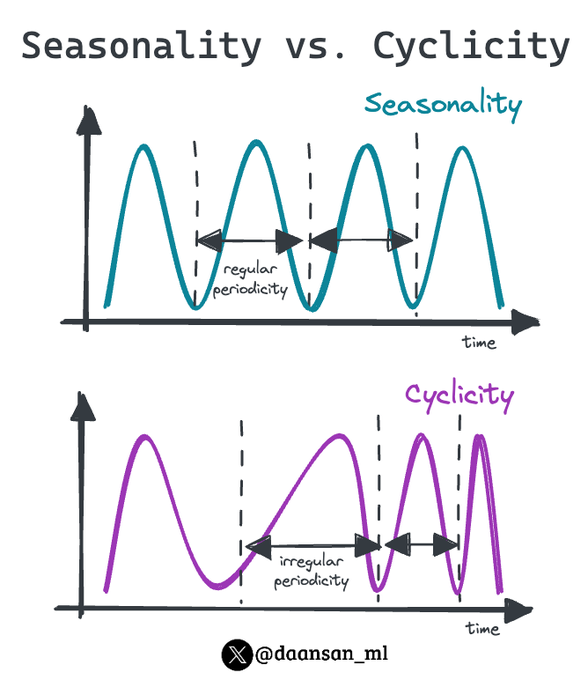
3
73
323
Permutation Importance and SHAP are two model-agnostic techniques employed in machine learning for estimating the importance of features within models.
Let's compare these 2 techniques 🧵👇
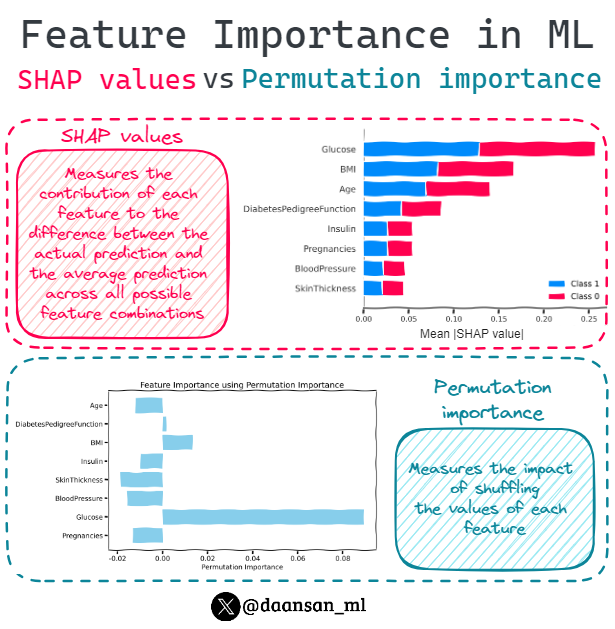
5
86
325
Does my data have a Unit Root?
What is that and why it is important in Time Series forecasting?
🧵👇
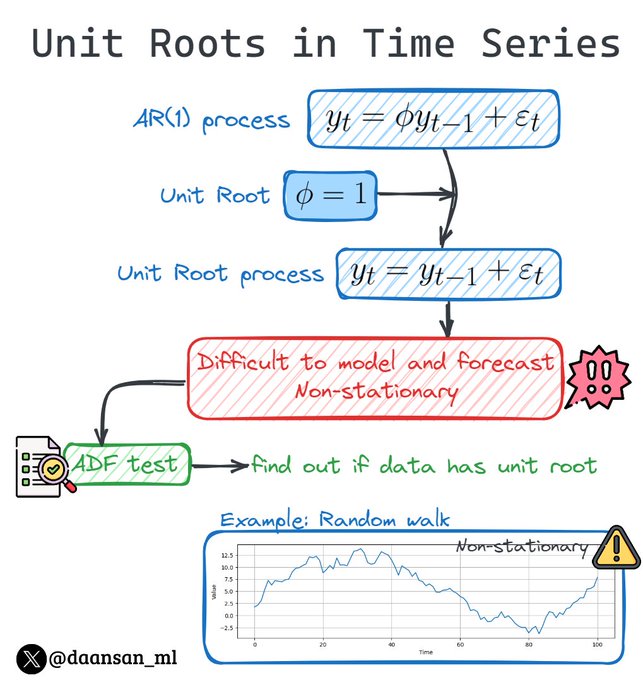
9
69
318
Would you like to create and train a neural network using TensorFlow and Keras?
You can find the main steps to achieve a simple version of this here 👇
1⃣ Begin by importing the necessary modules:
- Sequential to define a linear stack of network layers
- Dense for fully

4
75
320
What is data smoothing?
...and why may you need it? 🤔
Read this thread to learn more about it!
🧵 👇
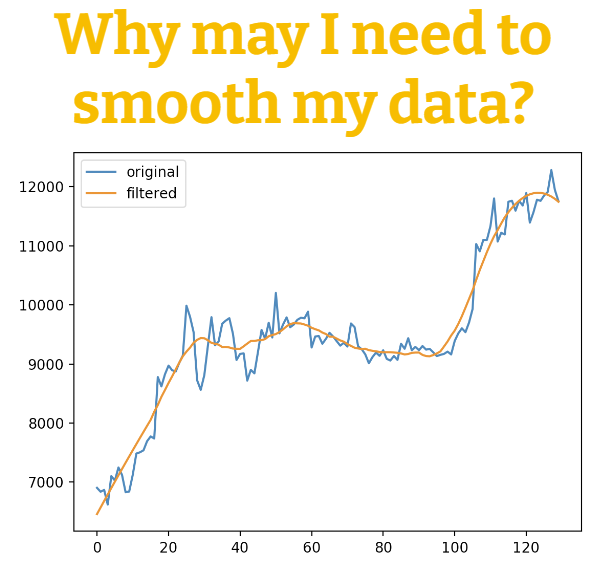
17
71
313
There are several types of data distributions you might encounter in a dataset.
Here are some common ones 👇🧵

3
73
321
When evaluating the performance of Time Series forecasting models, several metrics can be used to assess their accuracy and predictive power.
Here are 4️⃣ of the most used metrics for time series forecasting
🧵 👇
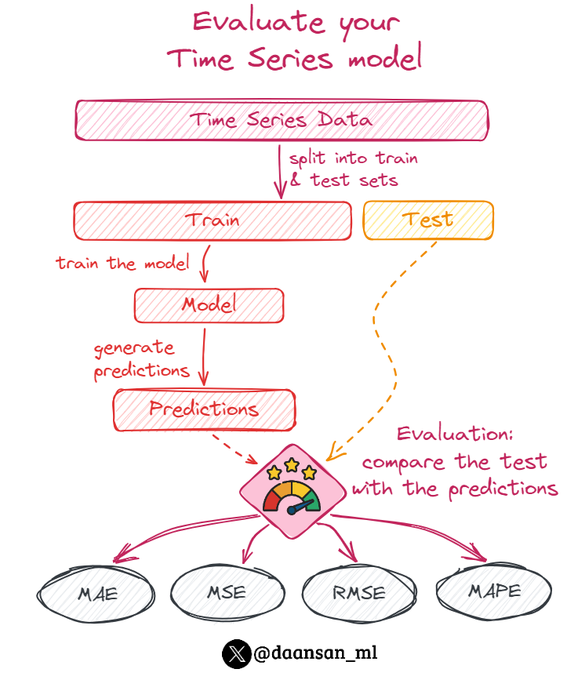
14
81
307
How can you assess whether your ARIMA model is good or not?
One way is checking the "summary" that the statsmodels library offers you 👇 🧵

6
72
313
Doing feature engineering for your Time Series data?
Here is an interesting technique: "Time Since an Event" 🧵 👇

5
62
307
Cleaning your data before building your Time Series model is crucial.
Learn how to do it, step by step 🧵👇
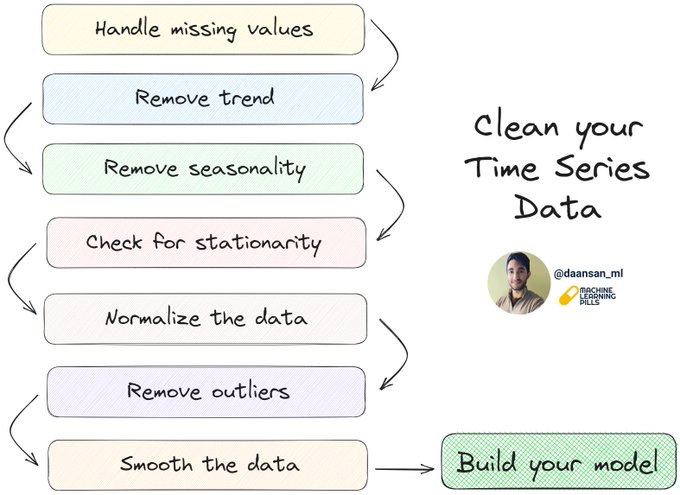
8
68
309
Yesterday we released a new article:
"How to forecast Time Series data using XGBoost?" 🤔
Discover it below 👇
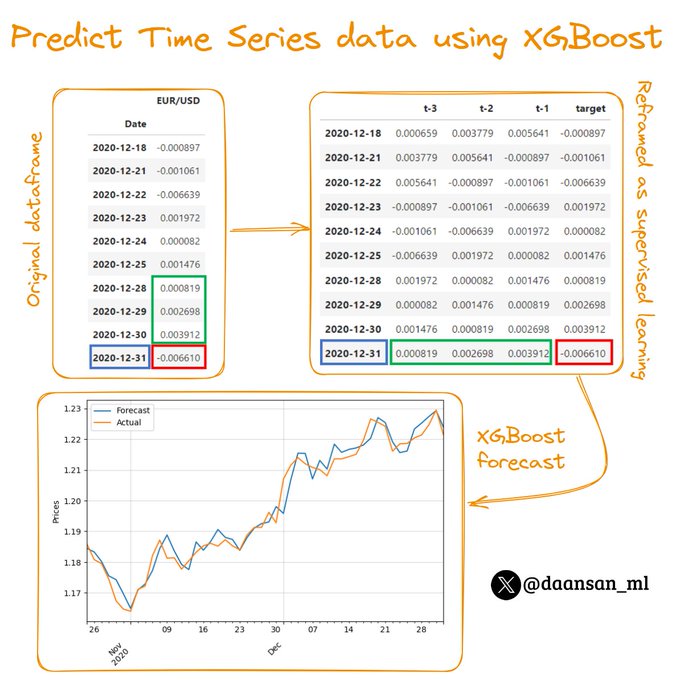
16
64
304
Are you familiar with the most common Machine Learning algorithms?
Today, I will complete the Top 10 of the most commonly used ones!
Check them out 🧵 👇
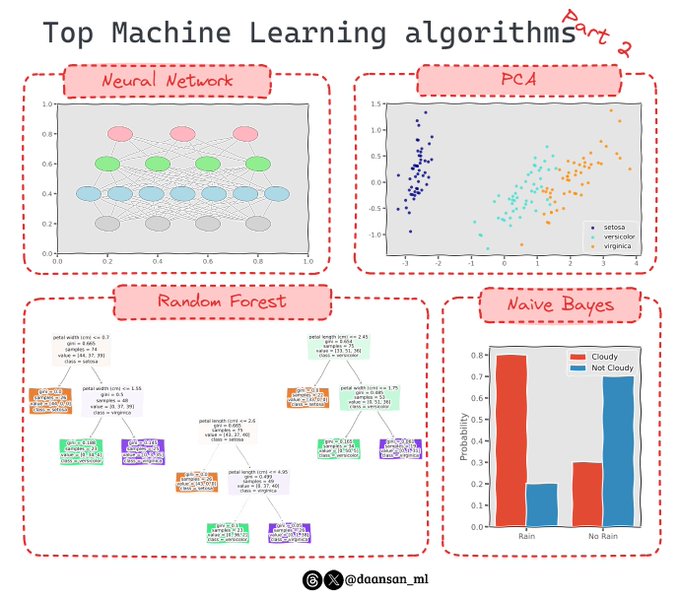
6
49
302
How can you estimate the value of the MA term - q - in your ARIMA model?
Here you have a step-by-step guide! 🧵👇
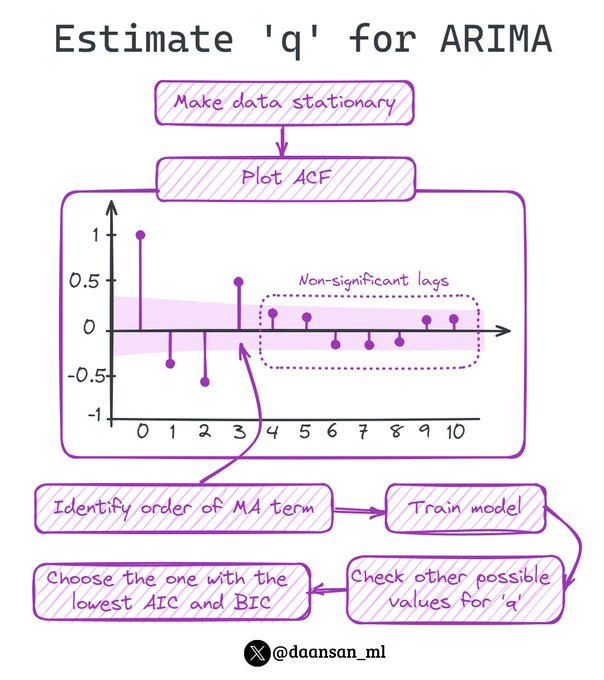
7
68
301
Do you know that you can separate trend and seasonality in your time series data?
Two popular decomposition methods are Seasonal Decompose and STL (Seasonal-Trend decomposition using LOESS).
Let's find out more about them 🧵👇
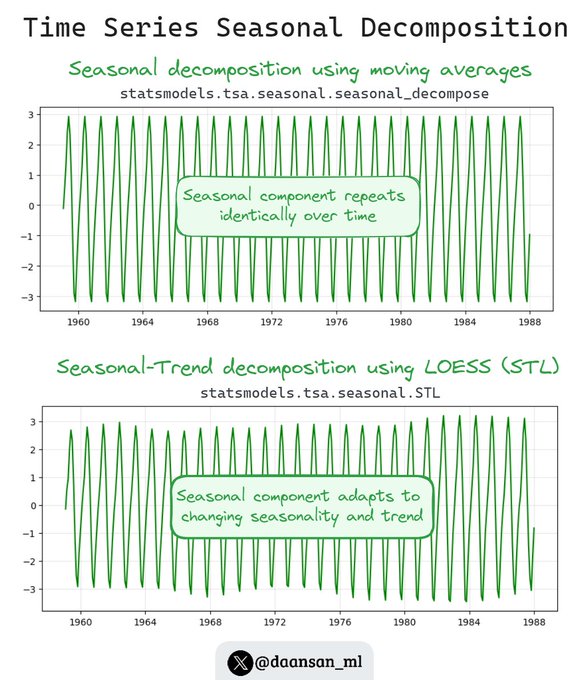
9
54
296
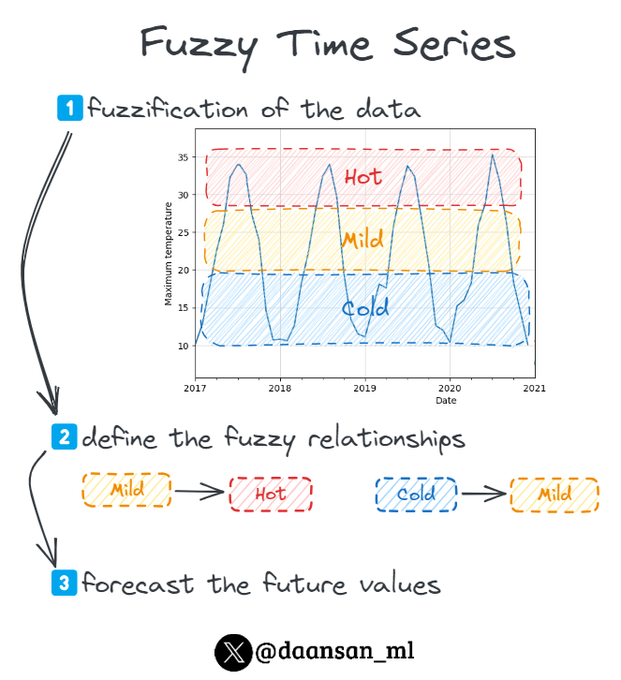
Last week I heard about the "Fuzzy Time Series"...
I had never heard about that before, so I researched it.
Here's what I found 🧵👇
5
60
287
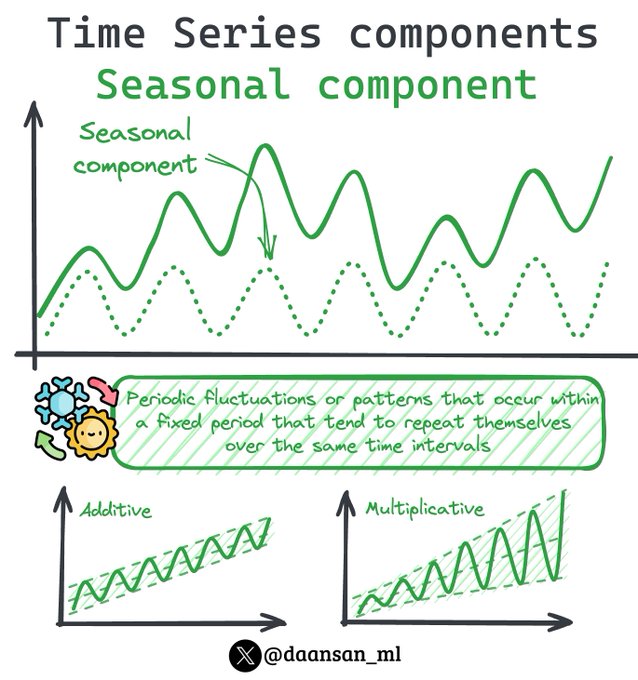
What is the seasonal component in time series analysis?
Let's break it down! 👇🧵
2
74
285
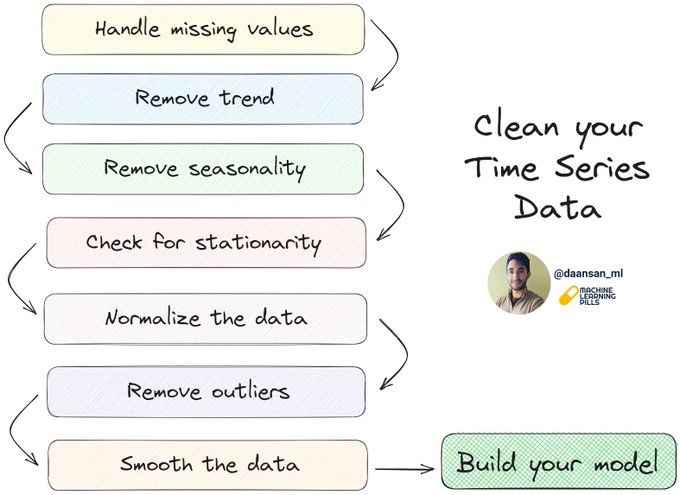
Cleaning your data before building your Time Series model is crucial.
Learn how to do it, step by step 🧵👇
8
79
275
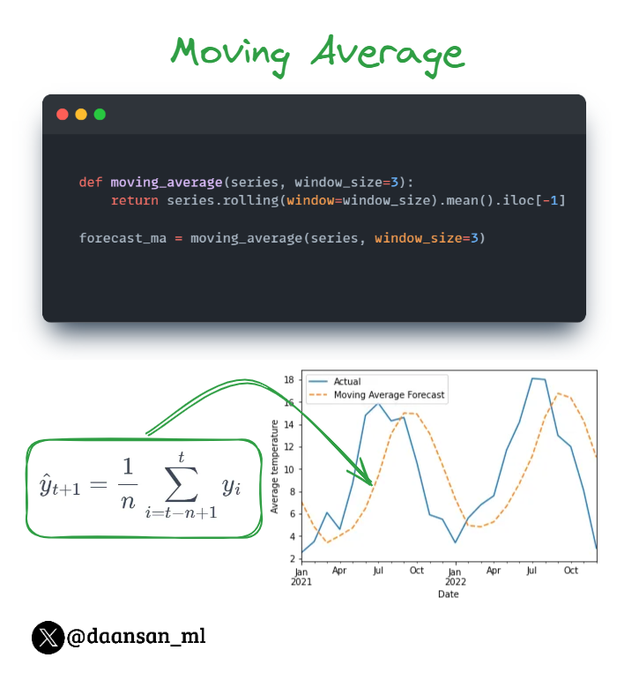
In Time Series Analysis and Forecasting, a base model is often a simple model used as a benchmark to compare the performance of more complex models.
Last time we talked about Simple Average...
Let's introduce now Moving Average (MA)! 🧵 👇
10
62
275
What are the steps of any Data Science project?
1️⃣ Define the problem or question to be answered: Clearly articulate the problem you aim to solve or the question you want to address.
2️⃣ Gather and understand the data: Collect relevant data and gain a thorough understanding of
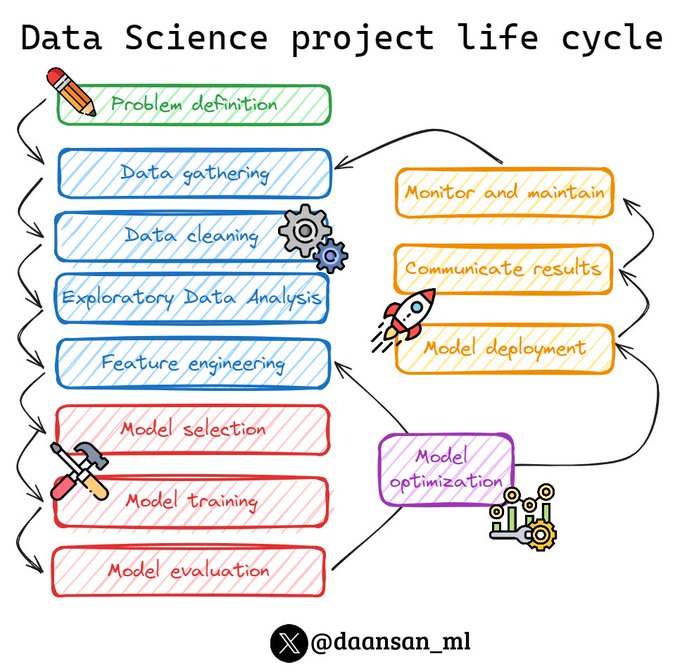
9
69
271
Permutation importance is a model-agnostic technique used to assess the importance of features in a model.
This method involves systematically shuffling each feature's values one at a time and measuring the resulting change in model performance.
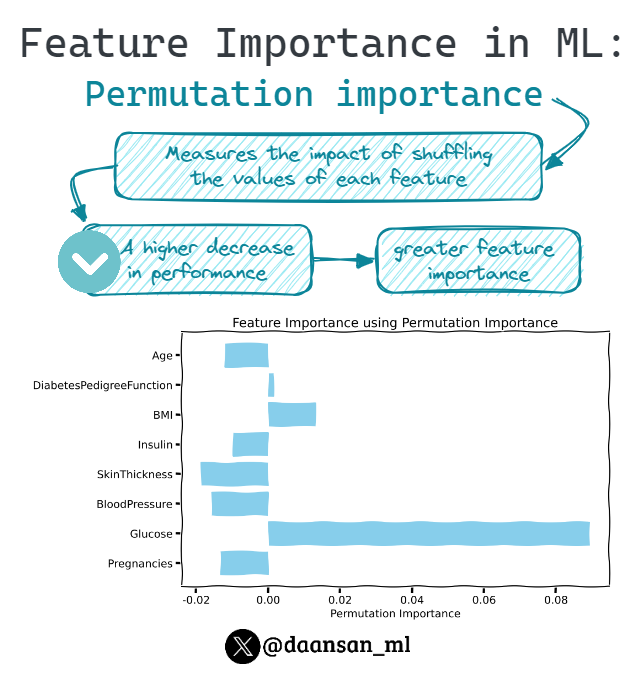
12
55
265
Today I'll introduce 𝗦𝘂𝗽𝗽𝗼𝗿𝘁 𝗩𝗲𝗰𝘁𝗼𝗿 𝗠𝗮𝗰𝗵𝗶𝗻𝗲𝘀 🤖
A useful Machine Learning algorithm that Data Scientists frequently use for both classification and regression problems.
Read more about it 🧵 👇

5
64
261
Cosine similarity is a handy method to find two items' similarities.
Widely used in NLP and in Recommendation Systems.
Let's explain it by using a simple example of a content-based recommender system of books 🧵 👇
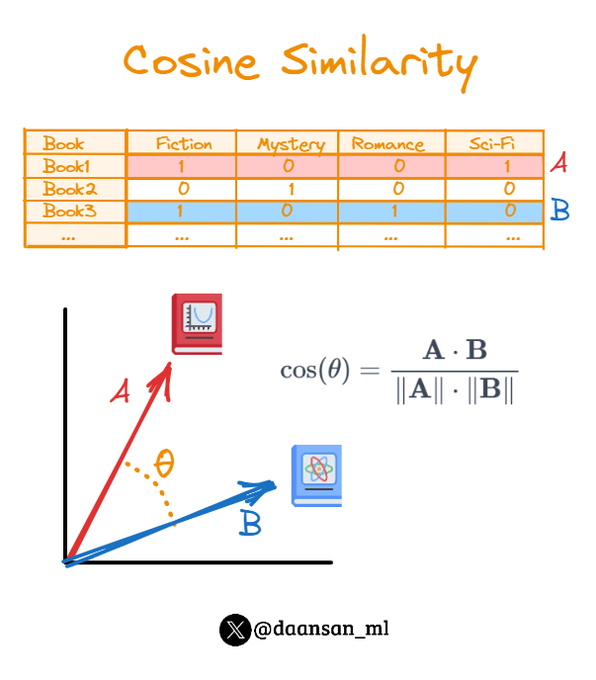
5
58
261
Decision Trees is a key model in Machine Learning for both classification and regression. 🌳
They use a tree structure for decision-making processes (hence the name).
Find out more about its components 🧵 👇
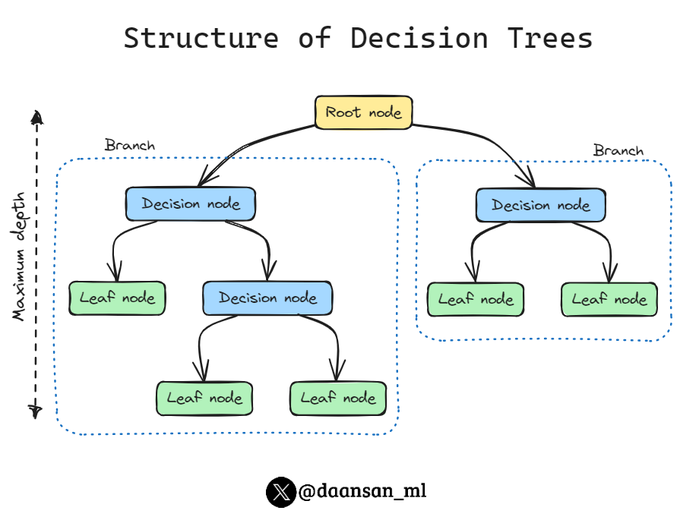
7
44
254
Your models may be impacted by outliers! 🚨
From where may these outliers be coming?
Let's find out the possible sources 🧵 👇
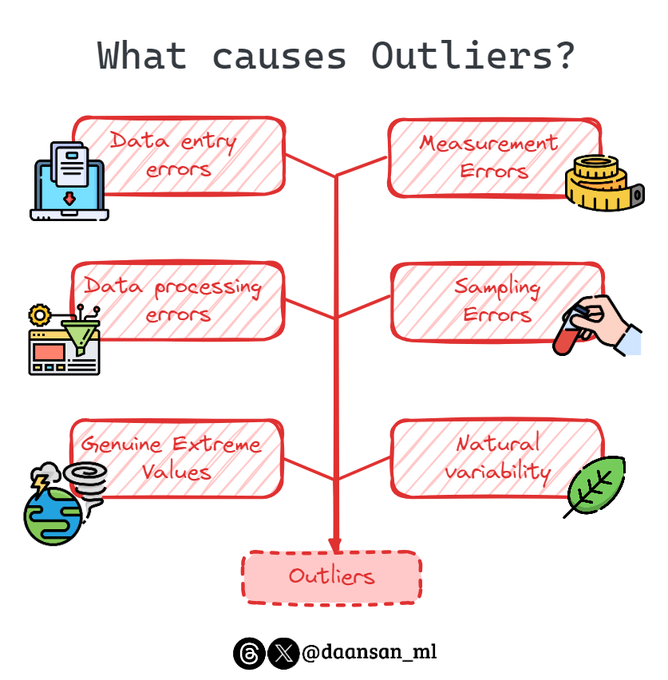
8
66
256
What are the steps of any Data Science project?
1️⃣ Define the problem or question to be answered: Clearly articulate the problem you aim to solve or the question you want to address.
2️⃣ Gather and understand the data: Collect relevant data and gain a thorough understanding of
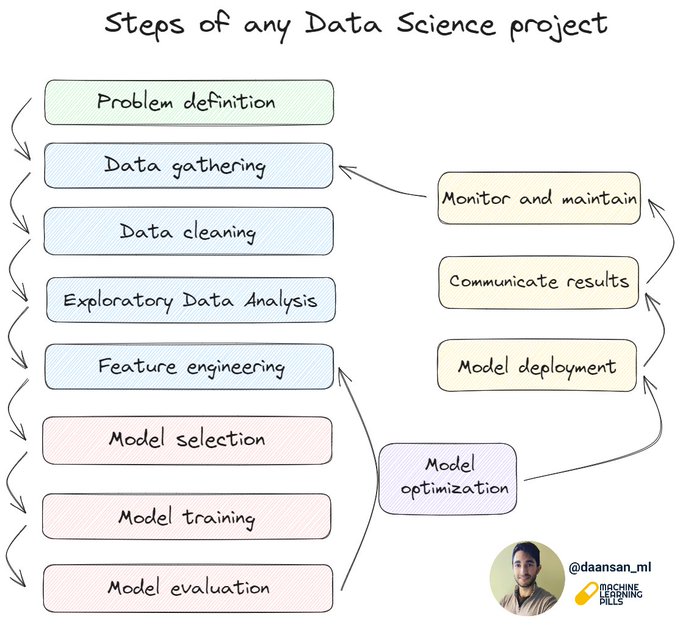
11
62
246
Looking to predict one Time Series variable based on another?
Will it be beneficial? ✅ Or not? ❌
You should first check Granger causality.
Check this out👇🧵
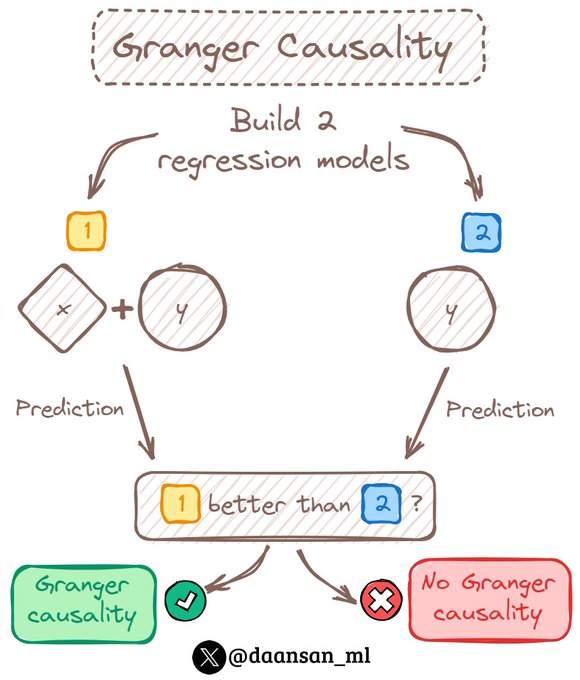
8
52
242
Would you like to create and train a neural network using TensorFlow and Keras?
You can find the main steps to achieve a simple version of this here 👇
1⃣ Begin by importing the necessary modules:
- Sequential to define a linear stack of network layers
- Dense for fully
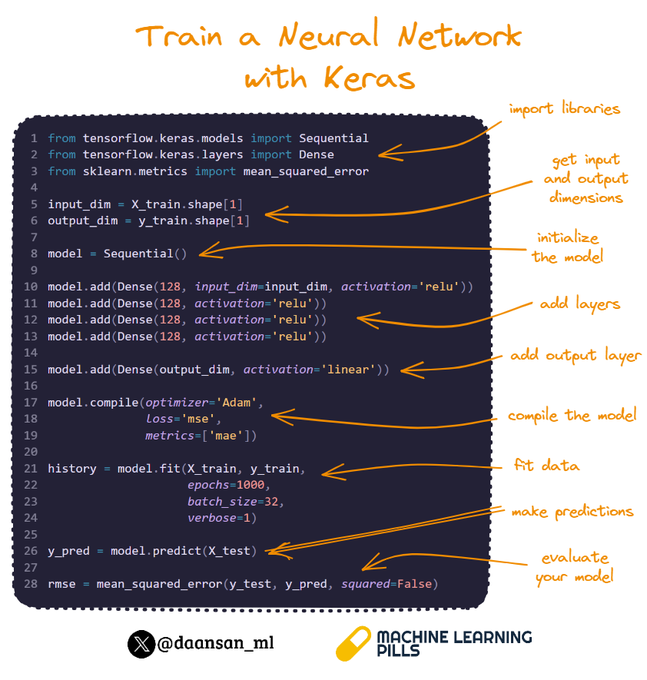
13
62
248
Time to introduce the ✨𝗥𝗼𝗼𝘁 𝗠𝗲𝗮𝗻 𝗦𝗾𝘂𝗮𝗿𝗲𝗱 𝗘𝗿𝗿𝗼𝗿✨, another really useful error metric for Time Series and Machine Learning!
Check this out if you are a Data Scientist! 🧑💻
🧵 👇
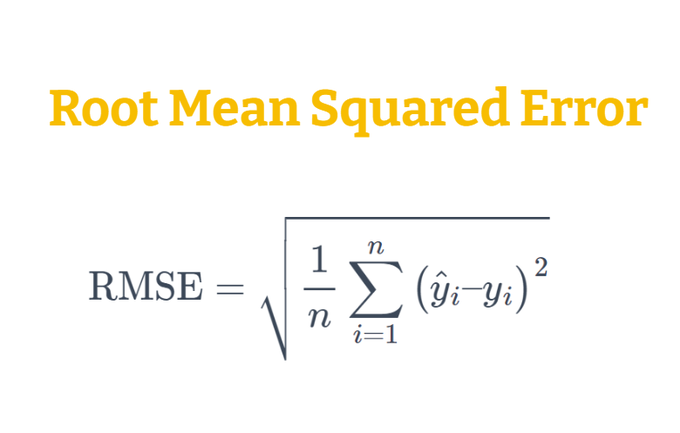
10
50
244
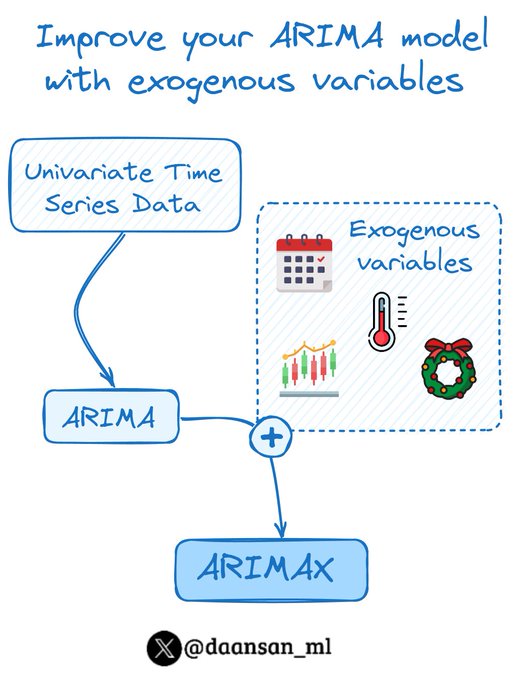
ARIMA models with more than 1 variable?
I introduce you to the ARIMAX models!
🧵 THREAD🧵 👇
4
53
241
Using an ML approach like an XGBoost model to forecast Time Series Data?
Extract the maximum information from the date 👇
Read more in the post below!

5
66
244
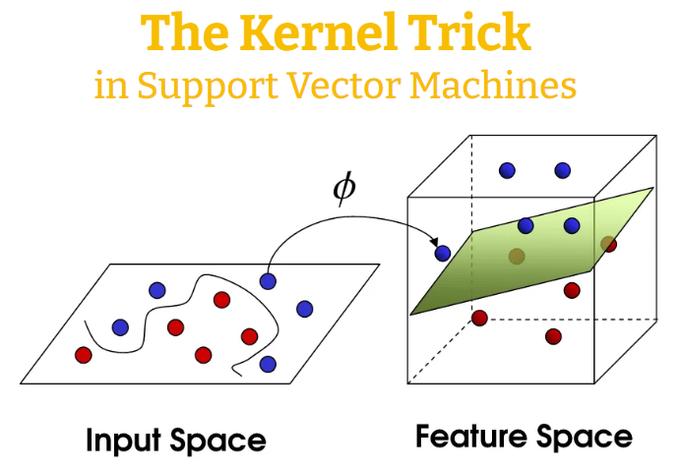
Have you ever wondered how 𝗦𝘂𝗽𝗽𝗼𝗿𝘁 𝗩𝗲𝗰𝘁𝗼𝗿 𝗠𝗮𝗰𝗵𝗶𝗻𝗲𝘀 (SVM) can handle non-linear data?
The "𝗞𝗲𝗿𝗻𝗲𝗹 𝗧𝗿𝗶𝗰𝗸" is a fascinating mathematical technique that allows efficient calculations and delivers powerful results!
Let's learn more about it 🧵 👇
5
61
241
Where can you find the most common data distributions? (2nd part)
Check this thread for real-world examples! 🧵 👇

4
63
238
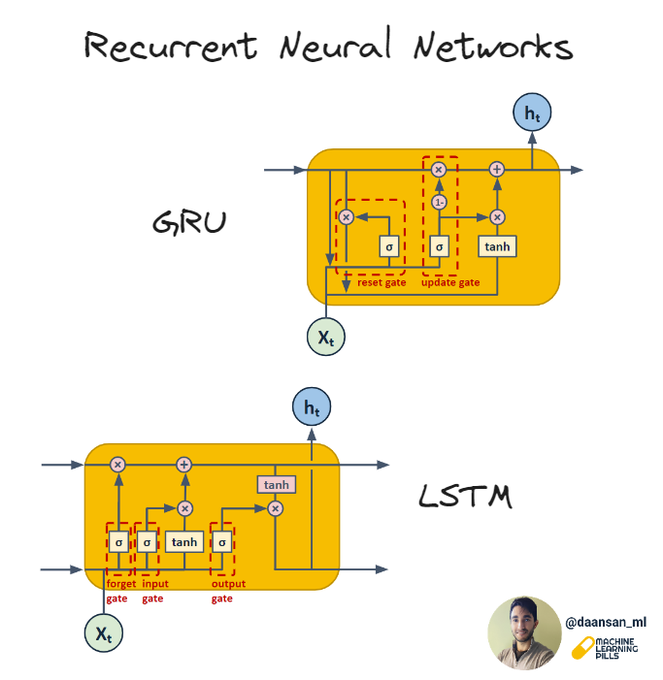
There is a kind of Neural Network that can be very useful to forecast Time Series data. These are called Recurrent Neural Networks or RNN.
This type of neural network are especially designed to process sequential data, where the order of the data points is crucial, like Time
8
71
235
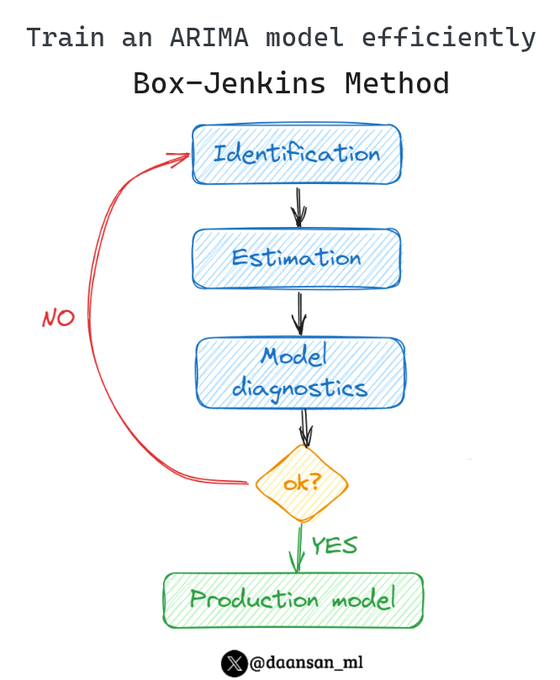
Build an optimal ARIMA model efficiently.
That's what you can achieve with the Box-Jenkins method.
From raw data to a production-ready model step-by-step 🧵👇
6
47
238