

Vinoth Chandar
@byte_array
Followers
2K
Following
704
Statuses
1K
Founder @Onehousehq, Creator of @apachehudi, Built the World's first #DataLakehouse, Distributed/Data Systems, Linkedin, Uber, Confluent alum. (views are mine)
Joined April 2009
Beyond Basics: Smarter Elastic Scaling for Lakehouse Workloads 🚀💡 (Onehouse Compute Runtime #4) Auto-scaling is supposed to save costs and ensure smooth performance, but in reality, generic scaling mechanisms (like Spark dynamic allocation) struggle with real-world workload patterns. If you pause to ponder, this will very likely jump out as the most significant waste of your cloud data spend. 🔹 The Problem: 📉 Scale-down is too slow → Wasted compute costs during off-peak hours 📈 Scale-up is too slow → Missed SLAs during demand spikes For example, a ride-sharing service in the U.S. sees fewer trips early in the morning but massive demand leading up to long weekends/holidays/morning commutes. Traditional Spark auto-scaling isn’t built to understand these patterns, leading to either over-provisioned clusters (wasteful) or under-provisioned clusters (performance degradation). 🔹 The Solution: Real-Time Adaptive Auto-Scaling ✅ Historical + real-time workload learning → Predicts demand based on usage patterns ✅ Dynamic scaling within budget limits → Just set a max budget (OCU), and we handle the rest ✅ Graceful slowdowns with notifications → Never break workloads; intelligently adjust Whether you need to auto-scale down to cut costs or scale up instantly to hit SLAs, OCR strives to ensure your lakehouse runs at peak efficiency without waste. And we intend to make this continuously better with more data/usage. Full blog: 💡 How do you handle these patterns and scale efficiently? Drop your thoughts in the comments! #DataLakehouse #ApacheHudi #Onehouse #BigData #ETL #CloudComputing #DataEngineering #CostOptimization #Spark #AI #AutoScaling #StreamingData #AdaptiveExecution #OpenData

0
2
5
RT @raydistributed: 💙💙 Integrating Ray Data and @apachehudi enables users to run ML workflows with Ray Data using datasets directly from…
0
6
0
Write-Optimized vs. Read-Optimized? Why Not Both? 🚀⚖️ (Onehouse Compute Runtime #3) One of the hardest challenges in lakehouse engineering is finding the right balance between write performance and query speed. 🔹 The dilemma: 📌 Write frequently small, unsorted files → Fast writes, slow queries (until background optimizations run). 📌 Sort and optimize data as you write → Slow writes, fast queries (as long as queries fit the storage layout) There will always be a tradeoff. Shouldn’t we be able to choose a performance profile without manually tuning Spark or Hudi configs? Onehouse Compute Runtime (OCR) automatically optimizes this tradeoff on our incremental ingest/ETL pipelines: ✅ Fastest Writes Mode 📝💨 → Up to 5x faster writes - Prioritizes data freshness with near real-time availability - Queries get full acceleration once async maintenance runs (a few minutes later) ✅ Fastest Reads Mode 🔍⚡ → Up to 10x faster queries - Data is sorted and optimized as it’s written, adding a fixed overhead. - Queries run at peak speed immediately—no waiting for optimizations. And, the best part is that these kinds of workload optimizations are implemented once across all engines, with support for multiple catalogs/engines you may be bringing to your data. Full webinar 👉 : , if you are curious.

0
5
11
How to ensure your jobs meet your SLAs ⏳⚡️ (OCR #2) One of the biggest challenges in managing lakehouse workloads is ensuring that jobs finish within a predictable time frame. The problem is that you can’t simply specify a maximum tolerable execution time. Yet, for most data engineering teams, hitting strict latency SLAs is a primary goal. Instead of relying on static cluster configurations, Onehouse Compute Runtime (OCR) introduces lag-aware execution that dynamically adjusts task parallelism and auto-scaling behavior based on real-time job conditions. 🔹 How it works: ✅ Set a sync frequency and a latency goal—OCR uses these as guiding SLAs ✅ Continuously monitor data pending at source, previous execution history, and available resources ✅ Adapt parallelism and scaling in real-time to meet your target execution time 🔹 The impact? ⚡ Faster ingestion & ETL pipelines without over-provisioning clusters ⚡ More predictable job runtimes, reducing operational overhead ⚡ Lower compute costs by using just enough resources at the right time We needed these operational features to run planet-scale production data lakehouses for the companies I worked for before Onehouse. Onehouse automates this process, ensuring your data lands by the time you need it—without wasted resources. The full LinkedIn live event, if you are curious

0
1
2
Onehouse Compute Runtime #1: Job Scheduling Efficiency via Multiplexing One of the biggest challenges running data lakehouse workloads today is scheduling and running jobs across multiple tables without wasting resources. This is a dynamic problem where the load can increase/decrease, and static resource allocation approaches often lead to underutilized clusters, redundant compute cycles and runaway costs. Core lakehouse compute should be as efficient as lakehouse storage. That’s why we built Onehouse Compute Runtime (OCR) with a multiplexed job scheduler that virtualizes jobs across clusters—interleaving and distributing workloads efficiently at execution time. 🔹 The result? ✅ Production customers are running hundreds of jobs within a small compute footprint ✅ Minimal wasted resources—compute is dynamically shared and optimized within clusters ✅ Faster processing times without over-provisioning expensive clusters When we built @apachehudi , we focused on solving the problem of incremental, low-latency updates in the lakehouse. Now, with Onehouse Compute Runtime, we are tackling the next big challenge—scaling compute efficiently across workloads. If your team is managing complex streaming + batch pipelines and struggling with cluster over-provisioning, we hope the ideas from Onehouse Compute Runtime help you as well. Full webinar : 💡 What are your job scheduling challenges in the data lakehouse world? #DataLakehouse #ApacheHudi #Onehouse #CloudComputing #BigData #DataEngineering #Spark #AI #ETL #StreamingData #CostOptimization

0
3
8
Introducing Onehouse Compute Runtime 🚀 Today, we proudly announce the @Onehousehq Compute Runtime (OCR)— one of the final missing pieces of the open data architecture puzzle. 🔑 Why is that? 📂 Specialized runtime for lakehouse workloads: There are enough SQL engines in the market but no real platform for foundational tasks like ingestion, transformation and optimization. Things engineers still have to spend a lot of time and effort on to cater to different workload needs. 🔒 Time to recognize compute lock-in: Porting SQL is easier, but redoing these workloads on a new runtime is often a 12-18 month project. Aside from data lock-in, which we all care about, this compute lock-in can restrict freedom to have your data across engines and cloud providers. ⚙️ Performance Matters: These workloads involve “batch jobs” that run long and consume a lot of compute resources. So it's also essential to do this well, just once and in a highly-performant way. OCR delivers upto 30x faster queries and 10x write acceleration across these typical lakehouse workloads. (we don't kid around with numbers) ✨ Key Innovations in OCR: 1️⃣ Adaptive Workload Optimizer: Simplifies workload tuning, balancing speed and cost dynamically - to ensure each workload is run optimally. 2️⃣ Serverless Compute Manager: Eliminates the complexity of provisioning compute resources, enabling elastic scaling and budget control in a BYOC deployment model. 3️⃣ High-Performance Lakehouse I/O: Optimized storage, performant building blocks and parallel execution for lowered cloud spend. Companies have already leveraged OCR for real-time analytics in clickstreams, IoT, and marketing at the petabyte scale—redefining what’s possible in the lakehouse paradigm. Whether you’re chasing speed, scalability, or independence, we believe OCR will create a lasting impact. 👉 Dive deeper into OCR’s features and benefits here: 👉 Catch the lively VentureBeat article here: I'm eager to hear any feedback. So DM me, or comments are welcome.
0
2
11
0
0
1
🚀 Guide for data engineers to optimize your data lakehouse performance 🚀 Achieving peak performance remains critical to deploying a successful data lakehouse. We have compiled a crisp summary of techniques for accelerating lakehouse tables. Key Techniques for Boosting Performance: ⚡ Choose the Right Table Type •Copy-on-Write (CoW): Ideal for read-heavy workloads and batch jobs. •Merge-on-Read (MoR): Perfect for write-intensive or streaming scenarios. 🛠️ Optimize Partitioning •Align partitioning schemes with query patterns for efficient data skipping. •Use coarse-grained partitioning to avoid file listing bottlenecks. •Cluster data within each partition for finer-grained control over data locality. •Leverage features like expression indexes in Hudi for advanced flexibility. 🗒️ Leverage Indexing •Use secondary/unique indexes (e.g., Bloom Filters in Hudi) for accelerated read and write operations. •Employ secondary indexes for faster query execution and reduced I/O. 📈 File Size Management •Regularly compact small files to maintain optimal storage and query performance. •Follow best practices like maintaining partition sizes for large tables. Over-partitioning is the most common vice we see out there. •Activate metadata tables to eliminate costly file listing operations and support data skipping. •Efficient Query Pruning using column statistics for query optimization by skipping unnecessary file scans. Start integrating these practices into your workflows today! 💡 #dataengineering #data #bigdata #analytics #datalake #datalakehouse
0
1
8
ICYMI, it was a blast answering all of @ananthdurai 's direct questions yesterday about #apachehudi, the data lakehouse/open table format ecosystem, and the surrounding drama. Catch the recording: Key discussion points: 🏎 Performance is often one of many considerations. We discussed how, high performance is a necessity on data lakehouse since all we spend money on outside query engines is to run jobs that either ETL/Ingest/Optimize data. Hudi makes them all incremental and efficient while supporting standard batch workloads. ❤️ I brought receipts to showcase how the community thrives as a mainstream OSS project across the industry. We talked about how important and challenging it is to preserve this vibrant community. 🎇 We summarized the Hudi 1.0 features, which push the data lakehouse closer to database functionality across storage format, concurrency control, streaming data support and indexing. These changes bring several “never before” capabilities around the key cornerstone lakehouse feature set. We remain focused on solving complex computer science problems using open-source software. 🤼 I was thrilled to be asked tough questions on table format wars winners/losers. It gave me a rare opportunity to put events in perspective and explain the vendor chess moves that are unrelated to Hudi, its community or even Onehouse. My favorite part was encouraging Delta Lake users to carefully consider what they lose/gain from “standardization” before wasting time on a migration project as a third party (I guess many wouldn’t have hoped to see this day) ❓I also raised some questions. Why does every data warehouse default to a closed table format as the default? Are users going to stop using them now? Why the obsession with converging the three OSS data lakehouse projects alone? Overall, it's up to the market/users to decide slow standardization vs fast innovation. My view: it's healthy to have both and multiple choices in any ecosystem. 📈 Loved the discussion on the pains around easily be up & running with Data Lakehouse. Some low-hanging fruits around software packaging could help in the near term. We discussed the hierarchy of needs here: table format -> data lakehouse frameworks -> DBMS server/cluster software, which is all closed software ATM. There is a missing open-source software stack, and we are slowly crawling toward a database specialized in data lakehouse architecture/workloads. #apachehudi #data #database #datalakehouse #datawarehouse #opentableformat #dataengineering #apacheiceberg #deltalake
1
3
10
I wish everyone a happy 2025! January 2025 marks 8️⃣ years since I wrote the internal RFC (Uber speak for design documents) for @apachehudi. It's been a wild ride, going from skepticism about "why do we need this" on the 0.1 release to "this is how we do data platforms now on" on the 1.0 release. Our progress on open table formats is just the tip of the iceberg. We have much ground to cover to advance open-source software for data lakehouses. Like many, I have benefitted from @ananthdurai's in-depth technology breakdowns, curating "Data Engineering Weekly" to inform us every week. We recently struck up a deep conversation around the evolution of the data lakehouse space and thought it might make for an interesting fireside conversation. Join us next week as we discuss all things data lakehouses, #apachehudi and newly - databases!
0
0
9
RT @apachehudi: 🚀 Updates & deletes got even better with the New FileGroup Reader in Apache Hudi 1.0 📌 ✅Positional Merges: Skip pages base…
0
10
0
@iamRamavar @apachehudi All credit to the community. 🙏To your point, very valid and real feedback. We recognized it, liked how easy Delta had made it. and 0.14+ SQL/Spark Datasource is 1-1 match to how things are in Delta. Mostly boiled down to automatically generating keys.
0
0
1
@iamRamavar @apachehudi thats literally how Hudi works as well. Have you tried a recent Hudi release. Happy to help your team with it, and get your pipelines to be actually fast "after" you get started.
1
0
0
RT @apachehudi: 🚀 First-Ever Secondary Indexing for Lakehouses in Apache Hudi 1.0 🔑 Benefits: ✅Faster lookup on secondary keys ✅Efficient…
0
7
0
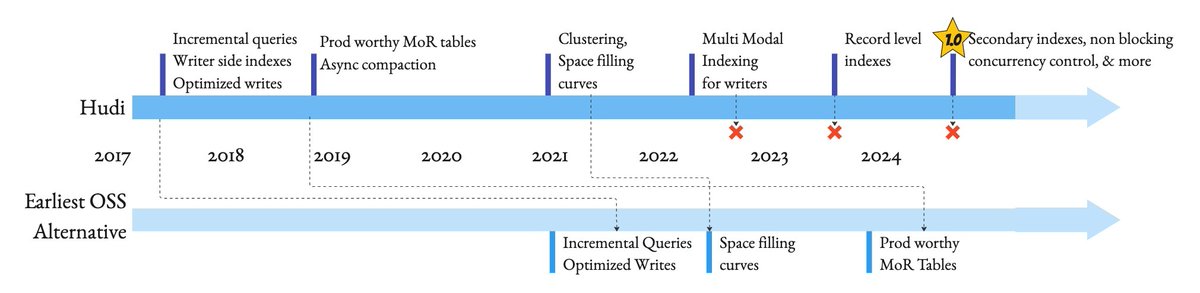
🎉 We’re proud to announce the @apachehudi 1.0 release! This release has been the result of a massive community effort, with tons of new code (re)written. I want to thank all 60+ contributors who worked on ~180K lines of change. 🗒️ Release blog: Hudi is still the OG of the data lakehouse when it comes to real technical innovation, as will become apparent below. 👇 🔥 Secondary Indexing - yes! you read it right. You can speed up queries using indexes, just like a #database. 95% decreased latency on 10TB tpc-ds for low-moderate selectivity queries. You can create/drop indexes asynchronously. ✨ Logical partitioning via Expression Indexes - #postgres style expression indexes to treat partitions like the coarse-grained indexes they are. It avoids the most common pitfall with users creating tons of small partitions. 🤯 Partial Updates - 2.6x performance and 85% reduction in byte written dropping write/query costs on update-heavy workloads. Lays the foundation for multimodal and unstructured data ⚡ Non-blocking Concurrency Control (NBCC) enables simultaneous writing from multiple writers and compaction of the same record without blocking any involved processes. This is an industry first! 🎉 Merge Modes - First-class support for both styles of stream data processing: commit_time_ordering, event_time_ordering, and custom record merger APIs. 🦾 LSM timeline—Hudi has a revamped timeline that stores all action history on a table as a scalable LSM tree, allowing users to retain a large amount of table history. ⌛ TrueTime - Hudi strengthens TrueTime semantics. The default implementation assures forward-moving clocks even with distributed processes, assuming a maximum tolerable clock skew similar to OLTP/NoSQL stores So, if you love open-source innovation as much as we do, check out the release and join our ~12000+ strong community across Slack & GitHub. We're a grassroots OSS community that has sustained innovation in a fiercely competitive commercial data ecosystem. #apachehudi #datalakehouse #opentableformat #dataengineering #apachespark #apacheflink #trinodb #awss3 #distributedsystems #analytics #bigdata #datalake
0
5
40
🚀 The way we build data platforms is changing fast. Traditional, monolithic data stacks cannot keep up with the velocity of data, the diversity of tools, or the growing demands of modern analytics and AI. I wrote down some of these thoughts in The New Stack article to highlight why modularity, adaptability, and simplicity are the future of data platforms. Here’s what stood out to me: 1️⃣ Embrace Open Data Proprietary lock-ins are a thing of the past. Open-source solutions like Apache Hudi, Delta Lake, and Iceberg give you flexibility and ensure you’re not boxed into a single vendor. 2️⃣ Build for Scalability & Resilience Your architecture needs to handle today’s and tomorrow’s data scale. It’s about investing in technologies that grow with you, such as cloud-native solutions, lakehouses, and incremental processing capabilities. 3️⃣ Shift from Pipelines to Products The article nailed it: Your data should be treated like a product, not just a pipeline. This mindset ensures continuous improvement, better collaboration, and higher ROI. What’s your take? Is the world ready for or needs a new data platform design? Or are we happy to dump data into a data warehouse and call it done? #DataEngineering #DataLakehouse #OpenSource #Data #BigData
0
2
4
RT @Onehousehq: 🚀 Just Launched: LakeView Insights + New Deployment Models! 🚀 Managing Apache Hudi tables just got a whole lot easier. Our…
0
3
0