
Bobby
@bobby_he
Followers
743
Following
1K
Statuses
66
Machine Learning postdoc @ETH. PhD from @UniofOxford and former research intern @DeepMind/@samsungresearch
Zürich
Joined January 2012
Outlier Features (OFs) aka “neurons with big features” emerge in standard transformer training & prevent benefits of quantisation🥲but why do OFs appear & which design choices minimise them? Our new work (+@lorenzo_noci @DanielePaliotta @ImanolSchlag T. Hofmann) takes a look👀🧵

4
38
183
RT @tpimentelms: BPE is a greedy method to find a tokeniser which maximises compression! Why don't we try to find properly optimal tokenise…
0
83
0
Come by poster #2402 East hall at NeurIPS from 11am-2pm Friday to chat about why outlier features emerge during training and how we can prevent them!

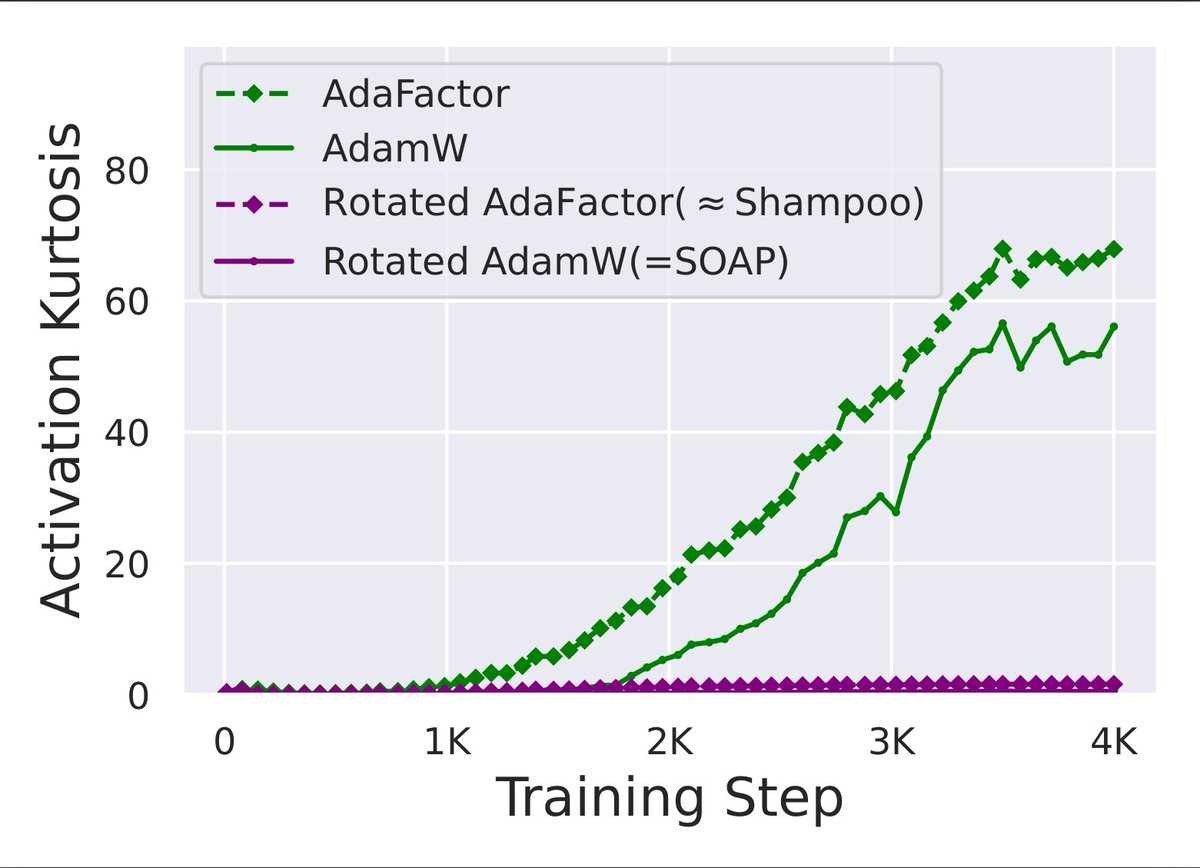
Updated camera ready New results include: - non-diagonal preconditioners (SOAP/Shampoo) minimise OFs compared to diagonal (Adam/AdaFactor) - Scaling to 7B params - showing our methods to reduce OFs translate to PTQ int8 quantisation ease. Check it out!



0
10
46
Updated camera ready New results include: - non-diagonal preconditioners (SOAP/Shampoo) minimise OFs compared to diagonal (Adam/AdaFactor) - Scaling to 7B params - showing our methods to reduce OFs translate to PTQ int8 quantisation ease. Check it out!
Outlier Features (OFs) aka “neurons with big features” emerge in standard transformer training & prevent benefits of quantisation🥲but why do OFs appear & which design choices minimise them? Our new work (+@lorenzo_noci @DanielePaliotta @ImanolSchlag T. Hofmann) takes a look👀🧵
1
30
157
RT @yuhui_ding: Tuesday 1:30pm-3pm, Hall C 4-9 #515. Drop by our poster if you are interested in SSMs for graphs👇! Code:
0
3
0
Heading to Vienna tomorrow for ICML! Broke up the train journey to catch a concert celebrating the 200th birth year of Bruckner, near the stunning Attersee 🏞 Looking forward to catching up with old friends and meeting new ones next week 😊




0
0
13
RT @unregularized: Ever wondered how the optimization trajectories are like when training neural nets & LLMs🤔? Do they contain a lot of twi…
0
9
0
@TimDarcet @iamrussianagent @lorenzo_noci @DanielePaliotta @ImanolSchlag Yep, altho imo token norm/act scale is not the best metric as you see OFs after the ln/rmsnorm/srmsnorm pre-norm layer (which are scale invariant). We discuss more in paper. Also thx 4 sharing, was aware of OF link to "massive activations" but not vit+reg: will add discussion :)
1
0
0
@TimDarcet @iamrussianagent @lorenzo_noci @DanielePaliotta @ImanolSchlag Thanks for q! Wanted to add OFs can arise through the mlp sub-block (indep of attn choices like registers). In pic we downweight the attention sub-block residual and change the slope of LeakyReLU mlp nonlin, which changes signal prop ( and also OF dynamics

1
0
1
@giffmana Update: have arxived and sharing in case of interest
Outlier Features (OFs) aka “neurons with big features” emerge in standard transformer training & prevent benefits of quantisation🥲but why do OFs appear & which design choices minimise them? Our new work (+@lorenzo_noci @DanielePaliotta @ImanolSchlag T. Hofmann) takes a look👀🧵
1
0
1
@lorenzo_noci @DanielePaliotta @ImanolSchlag Overall, we highlight key arch/opt choices to minimise OFs, shedding new light on this important facet of NN training dynamics. Many more results/exps in paper e.g. this ablation from standard Pre-Norm to OP one norm at a time. Check it out! 🙂 10/10

0
0
3