

Alex Carlier
@alexcarliera
Followers
8,898
Following
1,589
Media
448
Statuses
1,969
Building $9.4K & while full-time freelancing #buildinpublic Prev , AI research at @MetaAI , @ETH Zurich
Paris
Joined March 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
jeonghan
• 120462 Tweets
WONWOO
• 119911 Tweets
#FayeYouAreMine
• 93139 Tweets
Hispanidad
• 54019 Tweets
FINAL SEASON
• 46045 Tweets
W●RK
• 41545 Tweets
6TH MILKLOVE FANSIGN
• 40690 Tweets
GLAY
• 36636 Tweets
SVT RIGHT HERE IN GOYANG D1
• 29711 Tweets
Viva España
• 21083 Tweets
#キングオブコント
• 18148 Tweets
#12DeOctubre
• 16727 Tweets
ESTCOLA X PUNPREEDEE
• 16397 Tweets
ESTCOLA X KAO
• 13233 Tweets
オースティン
• 11775 Tweets
OUR DAWN IS HOTTER THAN DAY
• 11512 Tweets
ベイスターズ
• 11490 Tweets
ESTCOLA X MIKEY
• 10468 Tweets
エンティーム
• 10151 Tweets




















Pinned Tweet

I'm super excited to launch
@ReshotAI
! It's an AI face editor, and it works so well! 🤯🔥
Starting off with Face expressions: 🤪
👀 Edit eye movement & winking
🔄 Change the head rotation & tilt
😃 Adjust the smile, mouth opening
Here are more examples to see it in action ⬇️⬇️
99
299
2K
Upscale-A-Video was just released and it's so good! 🤯
It's a temporal-consistent Diffusion Model for video Super-Resolution, and has some of the best results I've ever seen, look at how sharp those lines become!
More details below ⬇️⬇️
43
275
2K
Google just revealed an ABSOLUTE depth estimation model 🤯
As opposed to recent depth models (Marigold, PatchFusion) which aim for maximum details, DMD aims to estimate the ABSOLUTE depth (in meters) within the image
More details below ⬇️⬇️
27
269
2K
Meta AI strikes again, with Relightable Gaussian Codec Avatars
This is an update to the Meta Codec Avatars 2.0, building on 3D Gaussian Splatting.
As a result, we get fully relightable real-time avatars, accurate at the hair strand level 🤯
More details below ⬇️⬇️
45
361
2K
Gaussian Painters imported into
#b3d
as ellipsoids
(3D Gaussian Splatting plugin for Blender - work in progress)
41
220
2K
Another experiment with Gaussian Painters ✨🎨
By optimizing 3D Gaussian Splattings over separate images at several viewpoints, it is possible to get a Steganography effect! Three paintings are hidden in those gaussian splats
I optimized 3D Gaussian Splattings over a single picture on a 2D plane. I'm calling this "Gaussian Painters" 🎨✨
Watch the gaussian splats work to paint the Girl with a Pearl Earring!
Here's how I did it (code below) ⬇️⬇️
13
75
640
22
227
1K
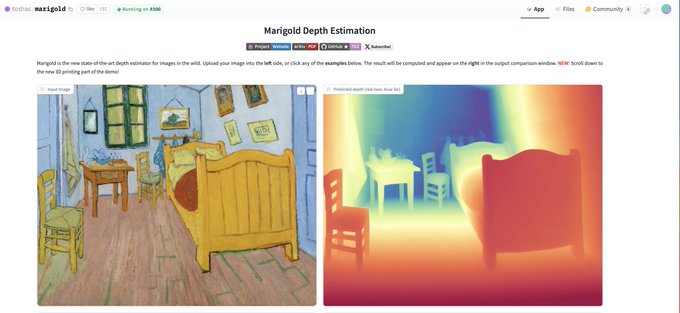
Wow Marigold 🌼 depth estimation works extremely well! 🤯
And the best thing is that the checkpoints and code are fully available for commercial use!
Try it out yourself! ⬇️⬇️
17
177
1K
This is literally magic 🤯
FMA-Net is a new AI method for video deblurring! It uses complex motion representation learning for spatio-temporally-variant restoration with kernels that are aware of motion trajectories.
More info below ⬇️⬇️
57
150
1K
Wow I made some big speed improvements for
@ReshotAI
🔥
The face editor now runs INSTANTLY, even for large images! 🤯
(not sped up)
30
121
954
PatchFusion was just released. Compared to ZoeDepth, it predicts depth maps with much finer details, just look at the comparison below! 🤯
Its main contribution is a new Global-to-Local module and Consistency-Aware Training.
More examples below (with code) ⬇️⬇️
22
134
889
LooseControl was just released and it's so good! 🔥
It enables depth-map conditioned image generation, but unlike ControlNet, the 3D boxes enable less strict control with simple bounding boxes. And look at how stable it is across frames!
More examples (with code) below ⬇️⬇️
22
117
796
This scene was scanned using only 3 pictures 🤯
In my opinion, this was the biggest flaw of NeRFs & 3D Gaussian splats: they are trained from scratch every time with no knowledge of the world. With ReconFusion, we now acquire it from diffusion models
More examples below ⬇️⬇️
18
117
752
Having accurate keypoints is extremely important for many tasks in AI and 3D. Here I trained a reenactment network with
@reshotAI
keypoints!
16
137
740
New 3D Gaussian Splatting recording! Those metallic reflections and leather were captured REALLY well!
When looking closer, you can also see how the watch hands are modeled with just a couple of elongated gaussians.
#GaussianSplatting
19
70
741
This scene was scanned using only 3 pictures 🤯
In my opinion, this was the biggest flaw of NeRFs & 3D Gaussian splats: they are trained from scratch every time with no knowledge of the world. With ReconFusion, we now acquire it from diffusion models
More examples below ⬇️⬇️
26
86
705
SUPIR: Scaling Up to Excellence. Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild 🔥
Links below ⬇️⬇️
22
78
671
Made a little visualisation for my latest project on free-view one-shot image generation 🤩
Just pick a photo, and generate images with full control of rotation and facial expressions. Or choose a driving video and let the magic happen✨
@ylecun
Try it for free using
@litso_app
!
18
111
646
I have written a tutorial on how to train your own "3D Gaussian Splatting" models!
#GaussianSplatting
Write me here if you're facing any issues.
⬇️⬇️
25
98
649
I optimized 3D Gaussian Splattings over a single picture on a 2D plane. I'm calling this "Gaussian Painters" 🎨✨
Watch the gaussian splats work to paint the Girl with a Pearl Earring!
Here's how I did it (code below) ⬇️⬇️
13
75
640
OpenVoice was just released! 🤯
Given a short audio clip, it clones the reference voice and can generate speech in multiple languages, while having control over emotion, accent, rhythm, pauses, and intonation!
Code & details below ⬇️⬇️
13
123
621
A new highly accurate OCR was just released and it's open-source!
Surya is accurate to the line-level, and multilingual. Well, in this example, only the newspaper name was not detected 😅
Link below ⬇️⬇️

12
75
511
EfficientSAM was just released and it's fast! 💨
With 20x fewer params, it is now 20x faster than the original SAM segmentation model, while staying in the same accuracy range.
See below for the project page and an interactive
@huggingface
space to try it out! ⬇️⬇️
14
110
493
Mediapipe vs my in-house keypoint detector for Reshot AI!
13
49
450
New 3D Gaussian Splatting capture at the Vintage Cars association in Versailles, from a 30 seconds recording.
Some floaters were cleaned with my b3d plugin. Original output below ⬇️⬇️
#GaussianSplatting
12
40
449
Imagine this on the
@Nike
website.
This is a 3D capture of the Nike ZoomX Vaporfly Next%, and visualizing this feels as real as touching the real shoe.
3D Gaussian Splattings are SO good at modeling fine structures, like in this case the transparent fabric.
#GaussianSplatting
14
38
438
Copy-paste any object into an image with AI! 🤯
Here's one application of using AnyDoor for virtual try-on, but it's much more general and is designed to maintain texture details yet allow versatile local variations!
Links below (with code!) ⬇️⬇️
9
87
426
Get crisp 3D Gaussian splats from blurry inputs 🤯
Capturing sharp videos is often impossible because of lens defocusing, object motion or camera shake. And 3DGS learns to fit this.
"Deblurring 3DGS" optimizes a small MLP to model the scene blurriness!
More details below ⬇️⬇️
8
75
427
An open-source version of AnimateAnyone was just released! (Moore-AnimateAnyone)
I just tried it, the quality is not there just yet, but it has great potential!
Links below ⬇️⬇️
3
67
425
3.8 mb 🤯
I tried the 3D Gaussian Splatting add-on for Unity by
@aras_p
on my Nike shoe capture, and when using the “Very low” quality, the file size becomes 3.8mb with minimal visual loss.
That’s the lowest file size I’ve seen for a 3DGS yet!
#GaussianSplatting
17
44
419
Wow, generate infinite videos from a single image 🤯
WonderJourney creates coherently connected 3D scenes along a controllable camera trajectory. Look how running the code three times results in completely different videos!
More examples below ⬇️⬇️
14
59
394
While everyone is waiting for AnimateAnyone, MagicAnimate was just released and it's really impressive! 🤯
It needs a single image and a motion video, and it produces an animated video!
See below for more examples ⬇️⬇️
8
75
376
A new video generation paper just dropped 🤯
DreaMoving creates human dance videos given a target identity and posture sequences.
But unlike AnimateAnyone and MagicAnimate, a full body picture is not required as input (only face + optional prompt).
More details below ⬇️⬇️
19
87
370
So Impressive 🤯
StreamDiffusion, built on sd-turbo, can generate up to 150 images per second.
Hardware configuration below ⬇️⬇️
14
45
370
How do 3D Gaussian Splatting models handle view-dependency? Using Spherical Harmonics
Here's how it works ⬇️⬇️
#GaussianSplatting
11
54
360
Using Gaussian Painters, you can also create a psychedelic illusion using two orthogonal images!
I optimized 3D Gaussian Splattings over a single picture on a 2D plane. I'm calling this "Gaussian Painters" 🎨✨
Watch the gaussian splats work to paint the Girl with a Pearl Earring!
Here's how I did it (code below) ⬇️⬇️
13
75
640
8
40
355
A new real-time Radiance Field paper beating 3DGS was just released! 🔥
Similarly to 3D Gaussian Splatting, TRIPS optimizes a point-cloud with color, position & size that gets splatted to the screen. But it does so using a single trilinear write in an image pyramid
More info ⬇️
10
60
354
Adaptive Shells was just awarded best paper at SIGGRAPH Asia! 🙌
It's a new hybrid method between a NeRF and mesh, and achieves up to 300 FPS at HD resolution!
More details below ⬇️⬇️
5
44
332
DreamBooth from a SINGLE image with perfect accuracy 🤯
Unlike specialized models like AnimateAnyone, DreamTuner is a general method for subject-driven generation, controllable via text or pose
But it works so well, it can create temporally consistent animations!
More below ⬇️
10
55
331
Gaussian Head Avatars look amazing! 🤯
Capture a dynamic 3D Gaussian splat of a face, then animate it in 3D using another actor. Imagine the potential for the film industry!
More examples below ⬇️⬇️
8
50
332
Meta AI's new real-time translation model is so impressive! 🤯
It streams the translation BEFORE waiting for the end of a sentence, with <2 seconds of latency. See how fast the translation appears after the speaker starts talking 💨
More details below (with code!) ⬇️⬇️
11
60
320
Google just announces VideoPoet: a multimodal video generation model!
It's massively multimodal and can take as input: text, image, depth & optical flow or a masked video and is one of the first models that generates video + audio!
More info below ⬇️⬇️
9
67
319
Wow this is cool! 🤯
PixelLLM generates image captions with pixel coordinates
Just a few years ago, the field of Explainable AI was amazed by simple heatmaps in the image classification task (single label prediction) This brings it to a whole new level!
Project links below ⬇️
9
74
310
Wow! 🤯🔥
Beyond First-Order Tweedie: Solving Inverse Problems using Latent Diffusion
Links below ⬇️⬇️
7
46
304
3D Gaussian Splatting is INSANELY good at fur rendering. Look at the fuzzy details here!
Makes sense since it literally optimizes over small ellipsoid particles, as opposed to NeRF or photogrammetry.
#GaussianSplatting
9
40
297
Deblurring 3D Gaussian Splatting is seriously amazing! 🔥
Can't wait to try it out on my captures!
Get crisp 3D Gaussian splats from blurry inputs 🤯
Capturing sharp videos is often impossible because of lens defocusing, object motion or camera shake. And 3DGS learns to fit this.
"Deblurring 3DGS" optimizes a small MLP to model the scene blurriness!
More details below ⬇️⬇️
8
75
427
3
28
297
Segment Anything Model (SAM) now runs at 30 FPS on an iPhone! 🤯
EdgeSAM is the first SAM variant that can run at over 30 FPS on an iPhone 14 with good quality. Low how accurately it segments tiny vegetables!
Code and
@HuggingFace
demo below! ⬇️⬇️
3
56
272
Extremely honored to have my artwork selected at the
@CVPR
AI Art Gallery among incredible artists! 🔥🤩


10
34
259
3D Gaussian Splattings from a single image 🤯
Compared to recent novel-view synthesis approaches (like Stable Zero123) which generate novel views as images (causing inconsistencies) this work generates 3D Gaussians directly (via a pointcloud and triplane features)
More below ⬇️
7
42
253
The first Consistency Model for Video was just released! 🤯
It enables video generation with as little as 4 sampling steps: generating 16 frames (at 256x256 resolution) takes 10 seconds only! So not real-time yet (as for images), but close!
More details below! ⬇️⬇️

7
39
250
Wow this is cool!
SMERF is a streamable NeRF that runs in real-time on any device with the quality of Zip-NeRF!
Try it yourself! ⬇️⬇️
9
18
241
The code for DreamTalk was just released!
Given any audio (text or song) and a single image frame, it generates a lip-synced animated video, copying the "expression" of a style reference.
Links below ⬇️⬇️
5
49
241
A comparison between 3D Gaussian Splatting and the new TRIPS radiance field rendering method ⬇️
Can't wait to try this out on some of my scenes! 🔥
A new real-time Radiance Field paper beating 3DGS was just released! 🔥
Similarly to 3D Gaussian Splatting, TRIPS optimizes a point-cloud with color, position & size that gets splatted to the screen. But it does so using a single trilinear write in an image pyramid
More info ⬇️
10
60
354
6
24
235
This new video upscaling & deblurring method (FMA-Net) works insanely well! ⬇️
This is literally magic 🤯
FMA-Net is a new AI method for video deblurring! It uses complex motion representation learning for spatio-temporally-variant restoration with kernels that are aware of motion trajectories.
More info below ⬇️⬇️
57
150
1K
2
43
233
Temporally stable 3D body MoCap with a SINGLE camera & occlusions!🔥
Obtaining globally coherent & plausible motions through occlusions is an incredibly difficult problem, but RoHM (by Meta and ETH Zurich) seems to have just solved this!
More info below ⬇️⬇️
9
36
226
ControlNet with higher fidelity, faster training & lower GPU memory 🔥
SCEdit introduces a lightweight tuning module called SC-Tuner
Project links below ⬇️⬇️
4
39
224
Photopea just announced their new Background Removal tool
It's available for FREE and works imo better than "Remove bg"! Wow 🤯
More examples below ⬇️⬇️
9
24
214
Wow the loading of
#GaussianSplatting
in
@LumaLabsAI
is so smart and satisfying! 😍
Only show the point cloud till fully loaded + progressive streaming from center to background
2
22
213
This is insane!
@antimatter15
has implemented a WebGL viewer for 3D Gaussian Splattings.
Unlike other implementations, this uses vanilla WebGL, and runs on any device in the browser (60+ FPS on my desktop, 30 FPS on mobile but no touch controls yet).
Link to try it below ⬇️⬇️
Imagine this on the
@Nike
website.
This is a 3D capture of the Nike ZoomX Vaporfly Next%, and visualizing this feels as real as touching the real shoe.
3D Gaussian Splattings are SO good at modeling fine structures, like in this case the transparent fabric.
#GaussianSplatting
14
38
438
2
36
213
Just tried
@LumaLabsAI
's Text-to-3D
(low-poly) 3D generation is now as fast as image generation, which you can then upscale for higher resolution 3D models.
Looks promising! 🔥

🔥 Introducing Genie 1.0, our first step towards building multimodal AI. Genie is a text-to-3d model capable of creating any 3d object you can dream of in under 10 seconds with materials, quad mesh retopology, variable polycount, and in all standard formats! Try it on web and in
106
494
3K
2
34
208
I created an upside-down optical illusion using Stable Diffusion XL ✨✨
Here's how I did it ⬇️⬇️
#SDXL
11
38
208
High quality real-time NeRFs on your phone🤯
MERF is a new streamable memory-efficient approach that achieves real-time performance while equaling the quality of Zip-NeRF (and outperforming 3DGS)
Try it out yourself below ⬇️⬇️
5
28
205
Try furniture in your living room before buying 🔥
Amazon just announced "Diffuse to Choose", a new diffusion-based image-conditioned inpainting model. It is fast and accurately copies fine details of the reference to the target image.
More examples below ⬇️⬇️
8
38
204
We made a small promo video for our upcoming
#LEGO
AR app! What do you think? ❤️
Join the waitlist ⬇️⬇️
21
20
204
This is so perfect 🔥✨
SDXL Auto FaceSwap by
@fffiloni
enables to create new images using the face of a source image.
Try it out in this
@huggingface
space ⬇️⬇️

5
31
200
Reminds of LooseControl, but for video!
Controlling 3d cubes in a video would be 🔥!
Fully control AI videos with simple boxes 🤯
Recent approaches enable control with human pose or depth maps, but creating these maps is challenging. TrailBlazer (built on top of ZeroScope) enables control with boxes through spatial & temporal attention map editing
More below ⬇️
1
7
79
1
20
181
#GaussianSplatting
from just two images in a single forward pass 🤯
PixelSplat predicts a dense probability distribution and samples Gaussians through a differentiable operation allowing to back-propagate gradients to the 3DGS representation
Completely insane results! More ⬇️⬇️
3
28
182
Tested Meta AI's new Audio2Photoreal: photorealistic animated 3D Codec Avatars from audio alone, sound on 🔊
Needs better face expressions, but very promising multi-view results!
Code links below ⬇️⬇️
9
32
184
New 3D Gaussian Splatting capture of a park near Versailles. The hardest part in shooting outdoors is to find the perfect timing when no people are seen 😅
#GaussianSplatting
7
17
180
Neural radiance field methods like Zip-NeRF perform very poorly when given only a few images. This is because they learn the scene from scratch with no prior information about the world.
ReconFusion fixes that! 🔥⬇️⬇️
This scene was scanned using only 3 pictures 🤯
In my opinion, this was the biggest flaw of NeRFs & 3D Gaussian splats: they are trained from scratch every time with no knowledge of the world. With ReconFusion, we now acquire it from diffusion models
More examples below ⬇️⬇️
18
117
752
2
25
174
DepthAnything was just released! 🔥
TLDR: it was trained on labeled + 62M unlabeled images
The encoder is initialized with DINOv2, a segmentation models helps to detect the sky (and set depth to ∞), the unlabeled images are strongly distorted (color, blur, CutMix).
More ⬇️⬇️
2
17
157
Get in-context descriptions of any object in an image 🤯
Osprey is a new Pixel Understanding model that can be integrated with Segment Anything Model (SAM) to obtain multi-granularity semantics of any region in an image!
More info below ⬇️⬇️
4
30
152
Lmao Procreate CEO’s last name is literally CUDA

We’re never going there. Creativity is made, not generated.
You can read more at ✨
#procreate
#noaiart
2K
23K
92K
5
5
143
Generate high-resolution UV textures from just a mesh 🤯
Compared to other approaches, Paint3D achieves to create UV textures without embedded illumination information. It does so using a novel coarse-to-fine approach.
More info below ⬇️⬇️
2
26
142
I optimized the Spherical Harmonic coefficients of a grid of 100x100 gaussian spheres to fit pictures at different viewpoints, creating a lenticular card effect! ✨🌈
Once trained, the images are stored in the SH coefficients of SHARED spheres
Here's how it works (w. code) ⬇️⬇️
3
17
139
Generate a 3D object from a few pictures only! 🤯
UpFusion also works taking a single picture as input, but providing a few UNPOSED images improves the fidelity to the input object!
More details below ⬇️⬇️
3
21
129
Another video showing Relightable Gaussian Codec Avatars in more details
2
13
126
Font resolution test on a 3D Gaussian Splatting capture. High frequency areas use more splats, while uniform ones are covered by just a handful of gaussians.
Still mind blown that this uses only 3D ellipsoids.
#GaussianSplatting
5
14
125
Ok this is cool! 🤯
Testing the
@krea_ai
AI Enhancer on one of our BricksAR
#LEGO
buildings to turn it into a realistic Parisian café 😍
Check below for more ⬇️⬇️
@Scobleizer
10
20
118
And here you go! A 3D Gaussian Splatting running in real-time in the browser on a 3-year old iPhone
Try it out here ⬇️⬇️

11
13
118
Tested 3D Gaussian Splatting on a capture from the Comics Art Museum, Brussels. 🇧🇪
Super impressive training convergence and real-time rendering!
#GaussianSplatting
5
15
117
Excited to announce that "DeepSVG: A Hierarchical Generative Network for Vector Graphics Animation" has been accepted to
#NeurIPS
!
If you're interested in vector graphics & sketch generation, feel free to check it out
Code:
Paper:


DeepSVG: A Hierarchical Generative Network for Vector Graphics Animation
Exciting work from
@alxandrecarlier
et al. Transformer-based hierarchical generative models learn latent representations of vector graphics, with nice applications in SVG animation.

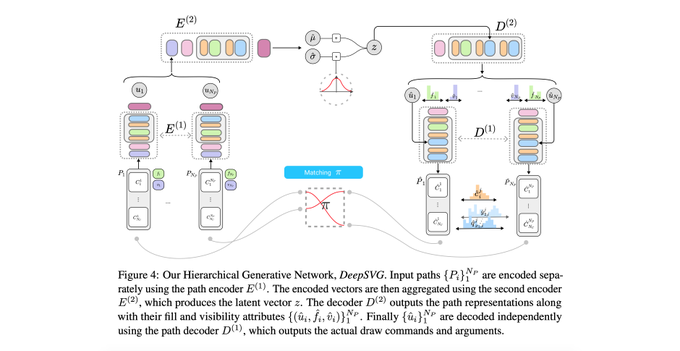
7
64
290
1
34
117
Neural Haircut: Prior-Guided Strand-Based Hair Reconstruction
Paper page:
Generating realistic human 3D reconstructions using image or video data is essential for various communication and entertainment applications. While existing methods achieved
3
18
118
Ok this is wild for 3D artists.
What if you could just get a ready-to-use material by simply clicking on a material in an IMAGE? This is what MaterialPalette solves.
Especially useful when modeling from a reference image, just pick the correct material!
Project page below ⬇️⬇️
5
16
113
There's something beautiful about visualizing impressionist artworks from Claude Monet using new technology.
Peaceful scenes from the past that become 3d dreams, and which would be fun to play with in VR.
Created using GaussianPainters.
#GaussianSplatting
4
16
109
For reference, here is the ground truth depth maps for the previous images. DMD improves the relative depth error by up to 25% over ZoeDepth!
One finding is that conditioning on the FOV is essential for disambiguating depth-scale.
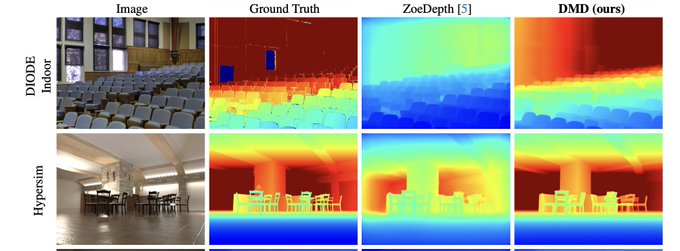
4
8
108
Replace a person from a video with any character using a single picture 🤯
This new paper from Alibaba is called MIMO: Controllable Character Video Synthesis withSpatial Decomposed Modeling
More below ⬇️⬇️
7
24
107
3D Gaussian Splatting vs TRIPS (new radiance field method running at 60 FPS 🔥) ⬇️⬇️
A new real-time Radiance Field paper beating 3DGS was just released! 🔥
Similarly to 3D Gaussian Splatting, TRIPS optimizes a point-cloud with color, position & size that gets splatted to the screen. But it does so using a single trilinear write in an image pyramid
More info ⬇️
10
60
354
1
12
102
I tested the ControlNet for video (MagicAnimate) and here are is my opinion: it works great but has some flaws.
- the identity of the motion video leaks to the resulting video (and deforms body shape)
- bad hands and face (unsurprisingly!)
But a great first step for consistent
While everyone is waiting for AnimateAnyone, MagicAnimate was just released and it's really impressive! 🤯
It needs a single image and a motion video, and it produces an animated video!
See below for more examples ⬇️⬇️
8
75
376
7
16
92
New 3D Gaussian Splatting capture of an amethyst. Look at those reflections 😍
#GaussianSplatting
6
6
91




Those fonts do not exist 🤯
@AdobeResearch
strikes again with VecFusion, a new diffusion approach for Vector Image generation. Here it generates missing glyphs from just a few examples!
If you follow me from my DeepSVG paper you know how excited I'm about this!
More below ⬇️⬇️
3
9
88
I'm building the best YouTube Thumbnails editor with my app
@ThumbnailsPro
With ✨AI foreground segmentation so that you can place content behind the main subject
What other features should it include?
6
10
87
Create your own upside-down optical illusions with Stable Diffusion XL! 🎨✨
I have created a colab notebook with the modified diffusion process for you to try!
Link in the comments ⬇️⬇️
10
19
84



Fully control AI videos with simple boxes 🤯
Recent approaches enable control with human pose or depth maps, but creating these maps is challenging. TrailBlazer (built on top of ZeroScope) enables control with boxes through spatial & temporal attention map editing
More below ⬇️
1
7
79