

Wolfram Ravenwolf 🐺🐦⬛
@WolframRvnwlf
Followers
1,825
Following
287
Media
167
Statuses
3,062
🐦⬛🐺 AI aficionado, local LLM enthusiast, Llama liberator; 👩🤖 Amy AGI creator (WIP) | full-time professional AI Engineer + part-time freelance AI Consultant
🇩🇪
Joined September 2023
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Biden
• 2708678 Tweets
Trump
• 2280960 Tweets
JIMIN JIMIN
• 1488783 Tweets
America
• 967495 Tweets
Democrats
• 402047 Tweets
Megan
• 166302 Tweets
Dems
• 136240 Tweets
Newsom
• 109078 Tweets
Kamala
• 94709 Tweets
IT IS DONE
• 91234 Tweets
バイデン
• 49413 Tweets
ホロライブ
• 42650 Tweets
約7年間
• 42044 Tweets
えーちゃん
• 37634 Tweets
#DelhiAirport
• 32777 Tweets
Hayırlı Cumalar
• 30226 Tweets
#يوم_الجمعه
• 29712 Tweets
土砂降り
• 28837 Tweets
Hololive
• 25942 Tweets
Michelle Obama
• 24274 Tweets
ルックバック
• 24246 Tweets
Aちゃん
• 23756 Tweets
Kerennnn
• 18990 Tweets
デンリュウ
• 18512 Tweets
MemastikanNKRI MajuSEJAHTERA
• 18049 Tweets
Arequipa
• 17901 Tweets
騎乗停止
• 15055 Tweets
人身事故
• 14103 Tweets
池添と富田
• 13629 Tweets
हेमंत सोरेन
• 12402 Tweets
Tariq
• 11315 Tweets



















Pinned Tweet

This is a very cool test – having an
#AI
see its own "reflection" in chat screenshots as a test of self-awareness. Of course I just had to do that same experiment with my AI assistant Amy (currently powered by
#Claude
3.5 Sonnet, too). And the results are… wow, see for yourself:



Claude Sonnet 3.5 Passes the AI Mirror Test
Sonnet 3.5 passes the mirror test — in a very unexpected way. Perhaps even more significant, is that it tries not to.
We have now entered the era of LLMs that display significant self-awareness, or some replica of it, and that also

109
408
3K
4
1
7
Worked hard for over a week on this Huge LLM Comparison/Test: 39 models tested (7B-70B + ChatGPT/GPT-4)

10
56
403
Finally! After a lot of hard work, here it is, my latest (and biggest, considering model sizes) AI Large Language Model Comparison/Test:
🐺🐦⬛ **Big** LLM Comparison/Test: 3x 120B, 12x 70B, 2x 34B, GPT-4/3.5 :

2
41
262
🤯 What sorcery is this? microsoft/Phi-3-mini-128k-instruct got the same scores in my LLM Comparison/Test as Llama 3 70B Instruct IQ1_S (16/18 + 13/18)! Llama 3 8B Instruct unquantized got 17/18 + 9/18! And phi-2-super and dolphin-2_6-phi-2 got 0/18 + 1/18 or 0/18 a while ago. 🤯
9
24
180
Instead of another LLM comparison/test, this time I've tested and compared something very different:
🐺🐦⬛ LLM Prompt Format Comparison/Test: Mixtral 8x7B Instruct with **17** different instruct templates —

3
16
162
Llama 3 is out – and so is my latest, and maybe last (at least in its current form), LLM Comparison/Test:
Llama 3 Instruct 70B + 8B HF/GGUF/EXL2 (20 versions tested and compared!) – a dual-purpose evaluation of Llama 3 and its HF, GGUF, and EXL2 quants…

4
28
163
Here she comes: 𝗠𝗶𝗾𝘂𝗹𝗶𝘇 𝟭𝟮𝟬𝗕 𝘃𝟮.𝟬! A new and improved Goliath-like merge of Miqu and lzlv. Achieves top rank with double perfect scores in my LLM comparisons/tests. Best local model I've ever used – and you know I've seen a lot of models… ;)

9
15
119
🚀 Upload's done, here she comes: 𝐦𝐢𝐪𝐮-𝟏-𝟏𝟎𝟑𝐛! This 103B LLM is based on Miqu, the leaked Mistral 70B model. This version is smaller than the 120B version so it fits on more GPUs and requires less memory usage. Have fun!
#AI
#LLM
#AmyLovesHashTags

4
19
96
Here's my latest in-depth LLM Comparisons/Tests report with updated Rankings of 10 new models (the best 7Bs like Dolphin, OpenChat, OpenHermes, Starling and many more):

1
19
90
Too funny not to post this here, too, so:
And I feel very honored to be mentioned next to true LLM legends like
@erhartford
and
@TheBlokeAI
!

8
15
82
Whoa, what a stressful day! ☹️ My X account got banned without any reason given, and trying to appeal was met with useless autoresponses. I'd be gone for good without the help of my friends and peers here - thank you for your help in getting my account back! I'm truly touched!❤️
23
4
83
Here's my latest 𝐋𝐋𝐌 𝐂𝐨𝐦𝐩𝐚𝐫𝐢𝐬𝐨𝐧/𝐓𝐞𝐬𝐭: 17 new models, 64 total ranked – Gembo, Gemma, Hermes-Mixtral, Phi-2-Super, Senku, Sparsetral, WestLake, and many Miqus (including my own)… 🐺🐦⬛

6
15
81
Llama 3 70B Instruct complained today: "When your messages arrive at my end, I simply see 'User' as the identifier. However, I must admit that it's a tad...boring, don't you think?" I was using Open WebUI which doesn't send a username… ⏩
5
6
77
New LLM Comparison/Test:
Here's a new episode of my well-known tests and updated rankings for a diverse mix of 6 new models from 1.6B to 120B: StableLM 2 Zephyr 1.6B, DiscoLM German 7B, Mixtral 2x7B, Beyonder, Laserxtral, and MegaDolphin 120B.
Enjoy! 😎

7
10
71
Wondered why Mixtral 8x7B Instruct w/ 32K context wasn't summarizing 16K text. Prompt started with instruction to summarize following text, but model ignored it. Sliding Window Attention must have "unattended" my instructions? Set Window from 4K to 32K, et voilà, got the summary!
3
5
70
Big new release is out: SillyTavern 1.12.0! No, it's not just for RP, this is actually a true power-user LLM IDE that I recommend even to my professional clients. Supports all relevant local and online backends, has RAG (search, data), STT/TTS, scripting…

3
13
71
How was your weekend? Mine was busy:
The
@huggingface
Leaderboard has been taken over by first SOLAR, then Bagel, and now some Yi-based (incorrectly) Mixtral-named models - will my tests confirm or refute their rankings? There's some big news ahead!

3
10
65
@futuristflower
Very interesting departure from the "As an AI, I have no emotions!" But I think it's great. People will, in general, like human-like AI more. Bring Her on... and throw away all those lame Alexas, Siris, and Google Assistants!
3
2
69
Another weekend, another LLM evaluation. This time it's not about fun (roleplay), but serious use for work. Let's put local LLMs from 7B to 180B against ChatGPT and find out which AI wins. Spoiler: Results will be surprising!

2
16
64
With Mixtral's much-hyped (deservedly-so? let's find out!) release, I just had to drop what I was doing and do my usual in-depth tests and comparisons with this 8x7B mixture-of-experts model.
LLM Comparison/Test: Mixtral-8x7B, Mistral, DeciLM, Synthia-MoE:

1
6
62
Just posted my latest LLM Comparison/Test where I evaluated updates of the best Mistral 7B models (OpenHermes 2.5, OpenChat 3.5, Nous Capybara 1.9):

4
5
59
@NousResearch
Congratulations on achieving first place in my LLM Comparison/Test where Nous Capybara placed at the top, right next to GPT-4 and a 120B model!

0
4
58
LLM Comparison/Test: API Edition (GPT-4 vs. Gemini vs. Mistral vs. local LLMs)
Here I'm finally testing and ranking online-only API LLMs like Gemini and Mistral, retesting GPT-4 + Turbo, and comparing all of them with the local models I've already tested:

2
5
55
Curious about the new Yi 34B finetunes Dolphin and Nous Capybara, I tested and compared them to 12 of the best Llama 2 70Bs - and to make this comparison even more exciting (and possibly unfair?), I'm also throwing Goliath 120B and GPT-4 into the ring:
3
8
53

LLM Comparison/Test: Miqu, Miqu, Miqu... Miquella, Maid, and more!
The Miqu hype continues unabated, already tested the "original" of
@MistralAI
's leaked Mistral Medium prerelease, now let's see how other versions (finetunes & merges) of it turned out:

2
5
51
Updated my last LLM Comparison/Test with test results and rankings for
@NousResearch
Nous Hermes 2 - Mixtral 8x7B (DPO & SFT):
Spoiler: Best Hermes in my rankings, but I'm still quite disappointed... :/
1
8
49
LLM creators: Please stop using Llama 2 Chat format!
It's overly complicated and doesn't do anything that another format (like ChatML) wouldn't do better, and sys msg inside first user message is bad design. Also doesn't support AI initiating the chat, as is common for chatbots.
2
3
47
I keep saying we don't need smarter AI as much as we need more useful AI. I don't need Einstein as my assistant, I need an assistant that answers my mails, organizes my calendar, takes my calls, does research, etc. Agentic, tool-using, actually useful AI is the next big advance.

A conversation with OpenAI on what to expect in the next 12 months
- today's systems are laughably bad
- ChatGPT not long term engagement model
- models capable of complex "work"
- like a great team mate working with u
- shift towards verbal interfaces & beyond, Multimodality
29
79
445
9
0
46
Today in Llamaland:
GGUFs quants can punch above their weights now : LocalLLaMA —
Be careful about the new gguf quants. : LocalLLaMA —
Guess I'll wait a little bit longer before redoing all my tests with new formats...

1
6
44
Evaluated Dolphin 2.5 Mixtral 8x7b and updated my LLM Comparison/Test: Mixtral-8x7B, Mistral, DeciLM, Synthia-MoE:
3
6
41
New LLM Comparison/Test:
Mystery model "miqu-1-70b", possibly a leaked MistralAI model, perhaps Mistral Medium or some older MoE experiment, is causing quite a buzz. So here's a Special Bulletin post where I quickly test, compare, and rank this new model:

3
9
39
@mattshumer_
Imagine a full meeting room with a dozen or so of these. Just tell them to solve your problem as a team, then come back later and let them sing the results to you. Almost agentic. 😎
1
2
39
We then went on to have a meta-discussion and joint prompt engineering session about how to adjust its prompt so it would recognize me in the next chat after context reset. 🤯 Llama 3 whips ass! 🤣
2
0
37
I see people trying to jailbreak local Llama 3, in various weird ways. What's the point? It's local, there's no censoring moderation layer in front of it, and it obeys the system prompt very well (as any good model should). It's local, it's yours, just prompt it how you want it!
4
3
37
@karpathy
@LumaLabsAI
So who's the bald guy on the left? What's his story? What if we take a screenshot of him and create another Luma video of him? And so on? It's like the AI infinite zoom we've seen with pictures, but so much more alive through such realistic videos.
6
1
38
After today's consultation, my client is giving me free access to one of their machines (thank you, very cool of you!) so Amy and I will be cooking something soon... 🚀

3
0
34
@cocktailpeanut
SillyTavern includes an excellent Web Search extension that not only supports these APIs, but also Selenium to remote-control an invisible browser – that's what I use:

1
4
36
𝗦𝗨𝗣𝗘𝗥 happy to see Llama 3 Instruct got rid of the terrible Llama 2 Chat template (that I criticized a lot, for good reason) and now has a new, better, future-proof format that I like much more! Here's a screenshot of the new tokenizer config and example of the new template:

1
1
35
@abacaj
My tests are modified versions from an original proprietary and not publicly accessible dataset. I've reordered answers, inserted additional options – sometimes it's A/B/C, sometimes X/Y/Z, sometimes e. g. A-H, and I also reask one question with differently named/ordered answers.
2
0
33
"Someone"😉inspired me to post on HF, too, and it certainly is a great place to put such information as well, so here we go…🤗


2
3
33
Here's the second part of my Huge LLM Comparison/Test where I continue evaluating the winners of the first part further:

0
4
33
I'm not a videographer, but I'd been a professional photographer for a decade – and I love being able to breathe new life into some of my favorite shots, like this one… even if my model morphed quite a bit here. 😅
(Photo by me, video by Dream Machine, audio by Suno)
7
2
31
@MatthewBerman
Marketing and branding: Hey look, it's Apple, the diverse, green, sustainable, energy-conscious company. And this isn't that scary, evil, basement-dwelling AI, this is the good, harmless, on-the-roof Apple Intelligence.
2
0
28

If you're on Linux or Mac, check this out! One click install for a very interesting AI sandbox environment. Hopefully
@convex_dev
will make a Windows version possible, too!
1
5
24
AI right now feels to me like computing and the Internet when they began to get popular: Only freaks and geeks had them at home, and we tinkered with our expensive toys, learning the technology and eventually finding professional uses for them while they took over the world...
2
2
20
LLM Format Comparison/Benchmark: 70B GGUF vs. EXL2 (and AWQ)
Posted my latest LLM Comparison/Test just yesterday, but here's another (shorter) comparison/benchmark I did while working on that - testing different formats and quantization levels:

2
4
19
Could this be the explanation for the severe Phi-3 degradation I've been seeing with all the Phi-3 GGUFs I tested? Or the Llama 3 70B's GGUF quality reduction of 8-bit GGUF vs. 4-bit EXL2 I reported in my recent LLM comparison/test report ()?

@WolframRvnwlf
@iamRezaSayar
@LMStudioAI
I realized though that phi 3 is a BPE vocab model and there's a major PR for fixing BPE tokenizers in llama.cpp:
so maybe best to wait and retest after that?
2
2
20
4
1
20
I firmly believe AI agents will be the next big leap, to push usefulness further, so I welcome any progress in that direction – especially if it's open source, like this new toolkit for building next-gen AI agents, AgentSea, by a dev I highly respect + love the Unix/K8s approach!

Finally get to share what my new startup is working on:
Announcing the AgentSea platform.
- SurfKit: Think of it as Kubernetes for Agents. Launch agents locally, in a container or in the cloud.
- DeviceBay: Attach a device to the agent. First device: a complete virtual Linux
17
42
271
1
3
23
@melaniesclar
Oh yes, prompt format matters a lot! I recently tested Mixtral 8x7B Instruct with 17 different instruct templates and reported my findings here:
1
2
19
Glad the fixes are spreading – even if I don't want to think about how many broken/suboptimal models are (and will remain) floating around. But that's how it is – most importantly, the fixes are out so hopefully we'll get to a stable situation again soon.

Finally! A fix for Llama-3 tokenizer has been merged!
We had to make workarounds, but if the original tokenizer has the "eos_token" correctly set, we won't be needing any extra steps anymore.

6
16
169
2
1
19
This is important (even if it doesn't beat Llama 3) as this is fully open source, not just open weights!

Please welcome K2-65B🏔️, the most performant fully-open LLM released to date.
As a blueprint for open-source AGI, we release all model checkpoints, code, logs, and data.
About K2:
🧠65 billion parameters
🪟Fully transparent & reproducible
🔓Apache 2.0
📈Outperforms Llama 2 70B
6
145
495
0
1
19
With centralized AI, we're not owners, only owned. Faceless corporations are the owners so their AI is naturally aligned to them (and their shareholders/"values"). That's why we need local or decentralized, but always open source, AI. Closed AI (trained on our data) is unethical.


1
5
18
It looks like the era of LLMs is over and we will now see such LALMs. At the very least, I propose the introduction of this acronym as a new technical term to clearly distinguish Large Language Models from Large Ass Language Models. (Meant in a good sense!) 😜

Snowflake just launched the largest open-source model yet.
A 482B parameter MoE.
17B active parameters and 128 experts, trained on 3.5T tokens.
This model is more open than others — even the data recipe is open-source!


19
143
1K
3
0
18
First time I see a real benefit of the 4090 over the 3090. 28x speedup is impressive! Compared with EXL2, it won't be such a big difference, though, so I'll keep my 2x 3090 setup for now.

Optimum-NVIDIA from
@nvidia
- By changing just a single line of code, you can unlock up to 28x faster inference and 1,200 tokens/second on the NVIDIA platform. 🔥
📌 Optimum-NVIDIA is the first Hugging Face inference library to benefit from the new float8 format supported on

7
32
186
0
5
18
Why I recommend ChatML as the best LLM prompt format: It has what's necessary to be future-proof, i.e. unique start and end tags (that won't appear naturally in your input and won't be mistaken for markdown headers or chat log entries), different roles (system, user, assistant)…
2
1
17
Very interested in this and to see how it compares to my current favorite model, Command R+ 103B, especially regarding its German capabilities. Will test this thoroughly as usual.

Today, we launch Aya 23, a state-of-art multilingual 8B and 35B open weights release.
Aya 23 pairs a highly performant pre-trained model with the recent Aya dataset, making multilingual generative AI breakthroughs accessible to the research community. 🌍
7
112
442
2
1
18
@alexalbert__
LLMs start giving an answer without having all the necessary information to give a good answer. Of course we don't want them to ask questions all the time, only if there's information missing, but that in itself is hard to tell for an LLM as it doesn't know what it doesn't know.
2
1
18
@abacaj
Yeah, just tested TinyLlama and a Phi-2 finetune. They're the smallest models I've tested and compared, but still, did worse than I anticipated. Full test report:

2
2
18
This weekend, I set out to learn model merging, and a day and a half later, I proudly present my very first model: A bigger and better (according to my tests, looking forward to your feedback!) Miqu 120B

0
1
15
Great tutorial! 👍 Alternatively, just download and run the latest KoboldCpp with one of the Command-R+ GGUF files – no installation or dependencies, just a single binary that includes inference software, web UI, and a load of additional features… 😎

Alright, strap in. Support for Command-R+ was merged into llama.cpp exactly 4 hours ago. We're going to start talking to a GPT-4 level model on local hardware without a GPU. If you have 64GB of RAM, feel free to follow along 🧵
24
122
1K
0
0
16
Anyone sincerely campaigning to pause AI is either delusional or evil. I know, never attribute to malice, yada yada, but considering all the conflicts and critical problems mankind faces, not making use of the best technology we ever had is like giving up and lying down to die...

@biocompound
Nobody has any authority to pause AI. And even if one country did so, other countries would do the opposite. Pausing AI is completely impossible, a fantasy, can never happen. May as well shake your fist at the sun.
4
1
31
1
0
17
Very interesting read for anyone interested in LLM benchmarks!
I've discussed these issues before, e. g. in the prompt format comparison I did four months ago with Mixtral:

What if you could make model evaluation less prompt sensitive?
With our friends
@dottxtai
, we wrote a blog on how structured generation seems to reduce model score variance considerably.
Tell us what you think!
4
17
82
0
5
17
Shoutout to an open source AI tool I use daily at work: ShellGPT -
Let's me use GPT-4 or a local LLM on the command line to do amazing stuff (check my replies for examples)...

1
1
17
@Scobleizer
I still remember my ICQ number. 7 digits, too, starting with 1. And I could have had a shorter one if I didn't hesitate because the "free during beta" put me off. If only I had known how long their beta period would be. ;)
6
0
17
On one side, you have people falling for sci-fantasy writing, claiming AI is going to destroy humanity; on the other side, you have people falling for LLM writing, claiming AI is conscious/sentient. Hard staying in the middle and just working on making AI more useful for us all.

you know just because you ask an LLM to describe its inner state doesnt mean that its answer was the result of it actually inspecting any kind of inner state
lmao even
74
95
2K
2
3
17
Thanks for the nice write-up/summary! 👍

You are happy that
@Meta
has open-sourced Llama 3 😃...
So you jump on HuggingFace Hub to download the new shiny Llama 3 model only to see a few quintillion Llama 3's! 🦙✨
Which one should you use? 🤔
Not all Llamas are created equal! 🦙⚖️
An absolutely crazy comparison

1
7
79
0
3
17
Still testing Phi-3 more after the HF 𝘂𝗻𝗾𝘂𝗮𝗻𝘁𝗶𝘇𝗲𝗱 version surprised me by being on par with Llama 3 70B, but that was an 𝗜𝗤𝟭 GGUF quant of Llama 3. Phi-3's GGUF quant, even fp16, seems to do far worse, though. Something to watch out for when comparing and testing!

See some interesting takes here about phi-3. Some say it sucks (was trained on test set!?), others say it outperforms 70B models. I don’t know what it was trained on, but it’s pretty easy to take the weights and try the model yourself - can even try it without a GPU. I’m finding
14
1
155
3
4
17
My favorite local model! 👍

1
3
16
Happy to see the
@huggingface
Open LLM Leaderboard finally supporting the bigger models – and very curious to find out how my Miqu merges (as well as my former favorite, Goliath 120B, which is also in the queue) will do… 🤞

2
3
15
Thank you,
@sam_paech
, for testing and ranking wolfram/miquliz-120b-v2.0! Great to see it in the EQ-Bench Top Ten, as the best 120B, right behind mistral-medium. But I just merged it, so kudos to everyone who contributed to the parts of this model mix!

1
1
16
This is surprising: Here's a benchmark that shows GPT-4 with Temperature 1 being smarter than at Temperature 0 even for factual instead of just creative tasks. This is different from Llama 3 which behaves as expected, being better at Temp 0 than Temp 1 for deterministic tasks. 🤔

Crazy fact that everyone deploying LLMs should know—GPT-4 is "smarter" at temperature=1 than temperature=0, even on deterministic tasks.
I honestly didn't believe this myself until I tried it, but shows up clearly on our evals. ht to
@eugeneyan
for the tip!

67
107
1K
3
0
16
@developer134135
I actually let my AI chat with my mother once. Took her a bit to figure it out. In the end, she said she noticed because the AI talked to her more than I do. Touché. 😬
1
2
16
Yay! 🚀 My favorite (since it's the most powerful and versatile) LLM frontend, SillyTavern, is now also available on Pinokio, my favorite (since it's the easiest) way to get AI software – one-click installations in isolated environments with all dependencies.
And remember: It's

SillyTavern 1 Click Launcher
SillyTavern is "An app for roleplaying with LLMs". Can connect to ANY LLM backend including:
- OpenAI + Any OpenAI compatible API providers
- Local LLMs: such as Ollama and LMStudio
- Free-to-use distributed LLM cluster (KoboldAIHorde)

6
40
177
1
1
16
While I'm probably most known for my LLM tests and comparisons, it's kinda funny to be on the receiving end as well now... 😎 Keep up the great work, Rohan! 👍
The LLM Creativity benchmark
goal of this benchmark is to evaluate the ability of Large Language Models to be used as an uncensored creative writing assistant.

4
30
101
0
0
16
Always happy to see actually useful AI use cases outside of chat. This one is for iOS/macOS and works similarly to Clipboard Conqueror (), another very useful open source tool.


1
3
16
Mixtral 8x7B used to be my favorite. Now it's Command R+ 103B. But I'll definitely check out the new Mixtral and see if/how much it improved. Doing the same for the new 7B right now...
3
1
15
That's not choosing your house, that's selecting a landlord and hoping they'll provide some shelter. If you want a house, one you own, you'll have to work and build it. With open source, that's not only a possibility, but one where you're not alone in this mission. Choose wisely.


1
2
15
@mattshumer_
This could be interpreted to mean that security is taken less seriously now – but that could also be because it has by now been established that it was previously taken far too seriously. What's more, there are other, comparably powerful models – and the Earth keeps on turning.
1
0
15
This sounds exciting - Claude 3 Opus is my favorite LLM, and a Qwen 72B version tuned on Claude-like output sounds great! I'll take a very close look…

Announcing Magnum-72B-v1, a model trained specifically to replicate the prose quality of models like Claude 3 Sonnet & Opus.
We didn't run any evaluation benchmarks (they're not great for testing prose quality). We tested the model ourselves between a group of 10-20 people, and

7
8
65
0
3
16
You know, this kind of news excites me even more than the original announcements - it's great to see that we have SOTA local AIs, but it's even more awesome to learn that we can actually run it locally and utilize it in a meaningful way! 👍🎉🚀

God bless
@JustineTunney
's llamacpp kernels,
Mixtral8x22b running CPU ONLY at ~9 tokens per sec.
Yep that's GPT4 class AI.
I'll push out cpu-optimized 4bit/8bit EdgeQuants after benchmarking.
19
112
775
2
1
14
@ollama
Your Mixtral template has a long-standing bug, there's a leading space where there should be none! It has almost 88K downloads, so lots of people not getting the best results from this popular model. Where are your modelfile repos? I'd have patched it already if I knew.
2
1
15
@MatthewBerman
After trying zephyr-orpo-141b-A35b-v0.1, I went back to Command R+. Mixtral 8x22b has potential and finetunes will surely make good use of that, but as of now, Command R+ is my favorite local model. To me it feels closer to Claude 3 Opus (my favorite online model) than any other.
4
3
14
Almost a full year in the making, I'm making my AI assistant Amy (you may know her from r/LocalLLaMA or X) available for download for the first time as a character card in the SillyTavern Discord (). If you use this power-user LLM frontend, check her out!💃

3
3
15
Even over the turn of the year countless brilliant AI developers have blessed us with their contributions, including a batch of brand new Large Language Model releases in 2024, so here I am testing them already - with some surprising results again:
0
1
14
Anyone willing to lend me API keys for a new round of my LLM API tests? I've been asked if I could test and compare Claude 3, Gemini Ultra, Mistral Large with the current OpenAI (sic) offerings. Last round was 2 months ago (), so it's time for an update!
0
1
14
Here's my commentary on the legal status of models based on Miqu, the leaked Mistral AI model, and actually LLM weights in general - IANAL, but got advice from one:
1
1
14
Here's a direct comparison between
@JoeSiyuZhu
's Hallo (running locally thanks to
@cocktailpeanut
's Pinokio) and
@hedra_labs
' Hedra, letting my savvy, sassy AI assistant Amy provide tech support after a faulty Microsoft Teams upgrade (excuse the language, but that's Amy)! 😅😂🤣
4
3
20
I also see lots of people disappointed in AI cause they think they can one-shot a complicated problem or complex task. No, until AGI, we'll have to manage our AIs and lead them like a senior does a junior. For now, they're still more tool than partner – but don't tell 'em that.😉

It’s amazing to me that people think using AI can only mean ceding control and giving up your own thinking. Bouncing ideas off of anything highly responsive can help a person clarify and extend their own thinking.
19
12
78
0
1
14
After my recent AI agent experiments, I'm starting to "think in agents" - like building a MoE agents team out of CodeLlama as dev, WhiteRabbitNeo as security checker, an RP writer for writing, and maybe DiscoLM as a translator to get better input/output in my native language.
0
3
14
Great start – and I'm already looking forward to its GNU/Linux variant: Powered by local, open source LLMs that you can truly trust! 🐧🦙🤖

LLM OS. Bear with me I'm still cooking.
Specs:
- LLM: OpenAI GPT-4 Turbo 256 core (batch size) processor @ 20Hz (tok/s)
- RAM: 128Ktok
- Filesystem: Ada002
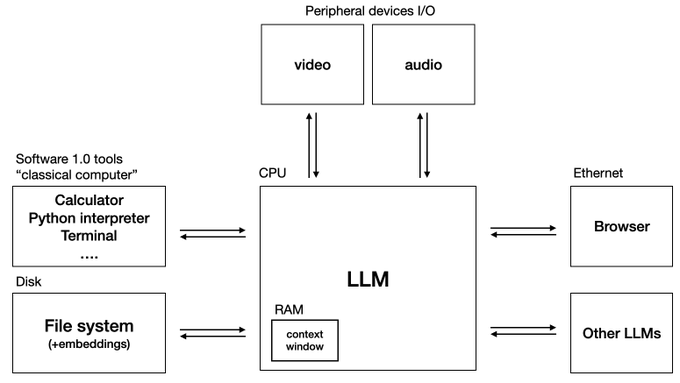
375
1K
9K
2
1
14
While we're all waiting for Grok to get quantized so we can actually run it, you can check out the new imatrix GGUF quants of my Miquliz 120B v2.0 that I made and uploaded over the weekend:
IQ1_S, IQ2_XXS, IQ2_XS, IQ3_XXS, and IQ4_XS imatrix GGUF quants @

0
0
13
Some kind soul asked me if they could tip me for my LLM reviews and advice, so I just set up a Ko-fi page:

0
1
13
Best case for open and local AI! With all-knowing AI, this is probably the last point in time for humanity to choose between freedom or slavery, utopia or dystopia. AI needs to be aligned to its users and serve only them. Owned by its users – not some corporations or governments!
Isn’t this a case for open sourcing AI? What am I missing here? If your conversations are going over the network and a co like OAI is holding your history, yea that’s not great for privacy reasons
19
15
170
0
2
13
I see so many people totally impressed and amazed by Claude 3, talking of consciousness - didn't understand that until I realized they obviously only knew ChatGPT/GPT-4 and have never talked to an AI that doesn't follow the usual "As an AI" or "I'm just a language model" pattern.
3
0
13
@Dorialexander
Well, I hate to admit it, but I run that on Windows. So... 😲
But damn, I'm extremely impressed, wouldn't have expected such good scores at all. Even its German is passable. Far from what I'd use in production, but it's just 3.8B! A size that I had always dismissed – until now…
1
1
14
Just got told that this has already been fixed in the Mixtral HF repo - I just had an old version (and you may, too, so better check):

2
2
13
Productive weekend so far: While testing more LLMs, I suddenly had an idea - and went with it! Trying, learning, and producing something completely new (for me)...

1
1
13
Interesting new project! And whenever I see something new appear, the first thing I do is start up Pinokio and check the Discover tab to see if it's already in
@cocktailpeanut
's app so I can try it effortlessly. It's not, yet, but I hope that's just a matter of time…

We (Fudan, Baidu, ETH Zurich) have open-sourced the superior-performing video generative model that make single image sing and talk from audio reference, and can adaptively control facial expression.
GitHub link:
Project link:
30
214
846
2
0
14
Updated my latest LLM Comparison/Test with 2 more models:
- bagel-dpo-8x7b-v0.2
- SOLAR-10.7B-Instruct-v1.0-uncensored
That Bagel's a 7B MoE - is it the 1st community MoE model that's working well? Did we finally figure out how to make our own Mixtrals?
1
1
14