

Richard Riley (R²)
@Richard_D_Riley
Followers
12,765
Following
1,267
Media
236
Statuses
6,738
Prof of Biostats • BMJ Stats Editor • Books: "Prognosis Research in Healthcare" & "IPD Meta-Analysis: A Handbook ..." • • Doctor Who ❤️❤️
Joined August 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Dodgers
• 227658 Tweets
ドジャース
• 106897 Tweets
#HappyDussehra
• 73690 Tweets
JENO FIRST PITCH
• 56869 Tweets
#Perfect10Liners
• 45604 Tweets
राष्ट्रीय स्वयंसेवक संघ
• 38518 Tweets
Pilar
• 36330 Tweets
#lovefighters
• 33276 Tweets
#chibalotte
• 33175 Tweets
Hispanidad
• 26632 Tweets
ホームラン
• 24718 Tweets
플레이오프
• 17759 Tweets
#お笑いの日
• 14996 Tweets
JAMESSU WITH ADDA
• 11816 Tweets
キングオブコント
• 11482 Tweets
Viva España
• 10772 Tweets


















Pinned Tweet

Five years pregnant with this … finally popped out today 🥳
Many thanks
@LesleyCRD
& Jayne Tierney for embarking on the journey with me - wonderful people to work with & learn from.
And to our amazing co-authors for guiding, correcting & challenging us - thank you 🙏

23
41
371
Here are 10 of the 'best' reviewer comments I have received over the years (all real, sadly!):
1. Richard Riley is quite good as far as he goes
2. The style of presenting the main ideas is so long winded that I wanted to die several times over whilst reading it
31
86
966
Just had a reviewer criticize my work (ok, happens regularly) but then refers me to a paper on how to do things better ... written by me! At least now someone (me) will actually utilise the method proposed (by me) 🤣
20
41
806
A reviewer just criticised our report because:
"The choice of font is rather old fashioned."
So ignorant. We used Times *NEW* Roman.
12
27
522
Personal news👇
In November, I will move to the University of Birmingham (
@unibirmingham
) as Chair of Biostatistics
Excited to work with a leading Biostats team in
@UoB_IAHR
@unibirm_MDS
& to continue our applied & methods work & courses in prognosis, prediction & meta-analysis

67
15
511
Recent reviewer nonsense:
"Add p-values, as this is for a clinical audience"
"Non-linearity is confusing; re-do analyses at clinically meaningful cut-points"
"Something's wrong if complex stats methods are needed"
"Reduce methods section - it's distracting for clinical readers"
28
61
505
When reviewing, so often I see 'multivariate' used when 'multivariable' is the correct word. Multivariate = multiple outcomes. Multivariable = multiple variables (covariates). In particular, multivariate regression should usually be multivariable regression.
23
186
489
"Please move the details of the statistical analysis to the supplementary material - having it in the main paper is distracting & unnecessary for clinical readers"
Such comments are ignorant & harmful.
Methodology is the bedrock of medical research & should never be an aside.
15
48
484
Students watch Distinguished Stats Professor write an R loop for first time since 2009
8
49
474
In 2022, why not involve statisticians at the start of your research projects?
20
58
448
Monthly reminder for meta-analysis folk:
I-squared estimates between-study heterogeneity❌
I-squared is a test for between-study heterogeneity❌
I-squared > 50% means large heterogeneity❌
I-squared measures proportion of total variability due to between-study heterogeneity✅
8
93
401
All statisticians & data scientists training for healthcare research would benefit from dedicated time observing clinicians, GPs & health professionals make decisions & seeing the pathway involved
Should be part of any MSc in med stats/health data science, & training fellowships
20
55
401
MS Word is killing me with now needing to 'post' the comment box before it is saved
I must forget 1 in 2 times - and it won't let you write another comment until the previous one is posted...

25
10
373
Maybe I’m old fashioned, but I don’t think it’s appropriate to be releasing press releases when submitting a pre-print. Dangerous even. Surely a paper needs to go through peer review first? Once a message is in the media and public domain, it’s very hard to turn back.
21
45
369
Just launched!
• for healthcare researchers doing prognosis research
• disseminates good practice & latest methods
• introductory videos
• links to key papers, textbooks & software
• training courses & conferences
Feedback & suggestions welcome

12
157
370
Reviewing a paper that apparently presents
"95% confidential intervals"
(🤫,🙊)
20
10
355
Using software modules or packages (within R, Stata etc) in your research?
Novel idea: reference them in your publications too!
These packages often take years of hard work.
Their creators deserve to be acknowledged
(indeed, their career progression depends on it)
#academia
13
67
329
Madness!
Some Elsevier journals now requesting "a short (maximum 100 words) biography of each author, along with a passport-type photograph" for new article submissions
- submissions are exhausting enough without adding this to the mix.
35
17
324
📽️NEW VIDEO 📽️
"How to get your article rejected by the BMJ:
12 common statistical issues"
I discuss common stats issues we encounter at
@bmj_latest
Please check before you submit next article 🫣
Santa would check the list twice 🎅
Hope helpful 🙏

10
116
321
Sneak preview of our new sample size paper coming out soon in Statistics in Medicine ...

9
51
318
Statisticians:
Please stop categorising continuous variables, it loses valuable information - we've told you about this countless times already!
Also statisticians:
Please classify a study's risk of bias as either 'low', 'high' or 'some concerns'
7
18
284
Seeing a few comments suggesting peer review should be abandoned as it is takes too long or still misses things. It is not perfect BUT I can’t think of a single example where my work was not improved after peer review. We need it more than ever.
13
40
255
🎄NEW
@bmj_latest
Christmas article🎄
"On the 12th Day of Christmas, a Statistician Sent to Me..."
Fun & light-hearted, flags common issues the BMJ Stats Editors encounter during peer review
Hoping for a positive educational impact, so please share 🙏

4
120
252
Recent feedback on my work:
"The style of presenting the main ideas is so long winded that I wanted to die several times over whilst reading it”
Well, at least it's having an impact.
14
3
253
One thing I've consistently noticed in my career is how statisticians & methodologists often have to fight to have their input fully recognised
e.g. in terms of % time allocated, author position, & being listed as a co-applicant or co-supervisor rather than a collaborator
10
30
254
Important message below but infuriating
#AI
field has to 'discover' this rather than being guided by long-standing stats literature
eg,
by
@GSCollins
says:
'Categorising continuous predictors is ... inefficient & should not be used in model development'


AI models perform better when trained on underlying measurements rather than the associated diagnoses, because dichotomizing data loses information that is useful in training AI models. Read the Case Study by
@amey_vrudhula
, BS, et al.:
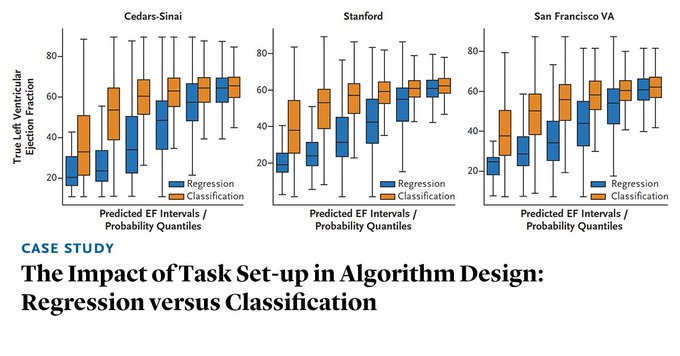
5
37
102
13
64
246
In case you missed it: our
@bmj_latest
paper on how to calculate the sample size required for developing a clinical prediction model (aimed at a broad audience)
8
77
249
"All co-authors read and approved the final manuscript"
4
38
237
Now formally published in Statistics in Medicine:
Minimum sample size for external validation of a clinical prediction model with a binary outcome
5
55
231
I keep being asked to review 'urgent'
#COVID19
articles that identify optimal cut-points (e.g. for d-dimer levels). Time to repeat again: dichotomisation of continuous variables is biologically implausible, statistically inefficient, & against ethos of individualised prediction

…and here is a screen shot of two slides from a talk I gave a couple of years ago on the topic - I think says it all (full slides available from here ).

9
104
340
9
58
219
Regular reminder for meta-analysis folk:
I-squared estimates between-study heterogeneity❌
I-squared is a test for between-study heterogeneity❌
I-squared > 50% means large heterogeneity❌
I-squared measures proportion of total variability due to between-study heterogeneity✅
5
44
224
Didn't think rejection letters could get more bizarre, but today I received this beauty:
"I enjoyed reading the paper and thought it was well-written... I want every fellow I train to read your paper ... but due to publication priorities, it cannot be accepted for publication"
16
12
218
Methodology research is an intense process mentally & emotionally - this rarely gets mentioned so thought I would share that it’s something I struggle with personally
It’s all consuming as your brain keeps trying to solve problems & generate solutions
Exciting & exhausting
1/n
6
40
216
Universities 'finalising' a data sharing agreement ...
3
31
219
Just completed my 350th open peer review for the BMJ.
I've probably annoyed 350^2 authors on the way & certainly don't always get it right.
But I'm hoping most of these 350 articles were improved as a result, even if ultimately not published in BMJ.
7
5
215
I first really *got* stats when taught a Bayesian module by Tony O’Hagan
He made Bayesian approach & probabilistic thinking compelling & natural. Forced me to re-learn frequentist approach & stop viewing stats as recipe book
All stats teaching should start with Bayes inference
12
19
207
August reminder for meta-analysis folk:
I-squared estimates between-study heterogeneity❌
I-squared is a test for between-study heterogeneity❌
I-squared > 50% means large heterogeneity❌
I-squared measures proportion of total variability due to between-study heterogeneity✅
3
38
206
Is dichotomisation a good idea?
Always
298
Never
805
24
35
203
Reviewed 6 cohort studies for the BMJ this week
- 5 of 6 did not mention missing data or how it was handled
- 5 of 6 dichotomised continuous variables or outcomes
Also differences between subgroups not quantified, non-constant HRs not considered, etc
Frustrating
12
24
203
Developing a prediction model? Before starting, calculate the sample size required to do your modelling reliably (no. participants, events, predictor parameters). Small sizes will likely fail. Penalisation & machine learning methods NOT exempt from this

4
58
201
So important for researchers to have quality reading time.
Being on top of the literature is an academic super power. Yet i fear most of us rarely get chance to prioritise this. I increasingly don’t.
How do we find time during our working hours to read?
#AcademicTwitter
14
18
194
Concerned you are collaborating with a data scientist rather than a statistician? My new diagnostic test is just for you. Simply ask what they mainly use the "ML" abbreviation for. A response of "Machine Learning" = data scientist, whilst "Maximum Likelihood" = statistician.
11
34
190
End of days
We should not be promoting this technology with words such as ‘biggest update’ or ‘simply’ or ‘analyse it for you’
Statistics & data science is a profession requiring substantial training at degree level(s) - there is rarely anything simple or automated about it

ChatGPT's BIGGEST UPDATE — Code Interpreter.
Simply upload a large dataset and it will analyze it for you.
It will also create charts and graphs.
In seconds.
Here's how to use it.
Code Interpreter 101: A Video Tutorial
82
433
2K
16
24
190
Reminder: when writing up research, always cite the software packages and methods papers that contributed to your research
Methodologists need to demonstrate impact too ...
3
28
190
A large proportion of papers I review dichotomise continuous variables. Today's treat: "Age was of interest as a potential subgroup effect, and so we dichotomised age at 70 (as this was the median)". Please stop this madness.
10
38
188
📢Just launched!
• for researchers undertaking IPD meta-analysis projects
• guidance & good practice
• introductory videos & latest seminars
• key references & articles
• training courses & resources
• companion to new textbook
Hope useful 🙏

1
75
185
Observation: We are losing talented researchers from academia (UK and non-UK), typically bright, young, mid-level career. Most worn out by pressures to deliver teaching, grant income, high impact papers, & enterprise. It's a tough environment. More nurturing needed in the system.
7
32
186
** Writing an academic text book - a thread **
I've written/edited a couple of textbooks in the last 5 years, & gained experience about the process & what worked well.
So 👇 I share 10 learning points to help others considering their own book project.
#AcademicTwitter
3
50
183
My July reminder for meta-analysis folk:
I-squared estimates between-study heterogeneity❌
I-squared is a test for between-study heterogeneity❌
I-squared > 50% means large heterogeneity❌
I-squared measures proportion of total variability due to between-study heterogeneity✅
3
33
180
Developing a prognostic model?
Don't neglect standard variables like age & stage of disease - these are routinely measured & often have strong prognostic information
'Novel' factors (eg, biomarkers) are often expensive & (despite the hype) typically add little prognostic value
10
29
176
Fun story
Gave my inaugural lecture at Keele in 2015 - big occasion with colleagues & friends. Thought it went well.
Afterwards got back in car with my wife & children. As we drove off, my daughter (4) sighed loudly & said ‘Never mind Dad, you tried your best’
Gorgeous memory
3
4
177
** Introduction to risk prediction & prognostic models **
New 30 minute video:
- a gentle introduction to the field
- motivating examples
- basic statistical format
- phases of research
- current problems
- signposts to better standards & training

4
48
171
The
#academia
career bootstrap:
1) Get existing data (call it 'big', ignore quality)
2) Form Qs based on variables recorded
3) Analyse until 'novel' findings
4) "Sensitivity analyses did not change results"
5) Publish
6) Inform comms team & media
7) Repeat 1-6 until tenure/chair
3
30
174
So many "regression versus machine learning" comparisons are not fair, as they don't allow non-linear trends for predictors in the regression model (eg using splines or polynomials).
As such, they only serve to reveal a lack of understanding of good statistical practice
5
20
170
Research statistician (tortoise) responding to new requests from the principal investigator (puppy)
0
25
165
May I introduce my YouTube channel?
My central place to share videos on prognosis, prediction and meta-analysis topics, including
- intros to prognosis research, risk prediction & IPD meta-analysis
- advanced topics (eg sample size, interactions)

5
40
166
Had a grant rejected - ok, happens alot - but main reason given was inappropriate 'power calculation' - yet the proposal was a prediction model development, so power is not relevant (no hypothesis test) & panel ignored our adherence to latest guidance
24
21
163
Who’s ready for an exposé of statistical reviews over Christmas?
Sneak preview of our stocking filler coming out in a few days in BMJ …

3
13
165
Delighted to announce our new book,
*** Individual Participant Data Meta-Analysis: A Handbook for Healthcare Research ***
will be published by Wiley in May 2021.
Edited by myself,
@LesleyCRD
& Jayne Tierney.
More details below...
1/5
9
31
164
Reminder that funnel plot asymmetry in meta-analysis indicates small-study effects, & not publication bias per se.
Publication bias is a possible reason for small-study effects, but often it's due to other aspects, notably between-study heterogeneity.

0
45
160
2002: print out articles & place in work bag to read later
2012: download article PDFs to read later
2022: use Twitter 'Bookmarks' to save links to articles to read later
Always: never actually read later
#Academia
2
11
162
⭐️NEW paper
“Clinical prediction models and the multiverse of madness”
For any model created, a multiverse of other potential models exists & an individual’s prediction may vary greatly across this multiverse
Avengers endgame: examine this instability🙏

5
49
163
**NOW PUBLISHED - with
@GSCollins
**
"Stability of clinical prediction models developed using statistical or machine learning methods"
So you've developed a fancy new model ... but have you checked instability of individual predictions?
You should!
1/3

2
43
159
Many thanks to
@NIHRcommunity
@NIHRresearch
@nihr
for supporting methodologists on their career pathway - humbled to receive this, & at same time as
@DrLauraGray
&
@GSCollins
too
Will continue to champion the importance of methodology & high research standards in coming years

Today,
@NIHRresearch
announced the research leaders receiving the prestigious NIHR Senior Investigator Award🏅
We couldn't be more pleased to congratulate our very own Professors
@drmelcalvert
&
@Richard_D_Riley
on this important recognition!
Read more:

5
7
38
27
11
162
Nothing is certain except death, taxes and dichotomisation of continuous variables
8
18
158
Journal Editors note: IPD meta-analyses are a big undertaking, often taking 1-2 years to obtain, clean & harmonize the data alone. Simply rejecting them because they miss IPD from recent studies published in last 6-12 months shows dire appreciation of the process & pain involved.
7
40
155
Missing data
- what is it & why does it matter?
1/10
5
32
155
Periodic reminder for meta-analysis folk:
I-squared is as an estimate of between-study heterogeneity ❌
I-squared measures the proportion of total variability due to between-study heterogeneity ✅

4
42
155
All sample size calculations are wrong, but some are harmful.
3
18
153
Remember: Methodology over metrics. Every day.
"Since Altman's 1994 paper, the problem of poor research has persisted – and arguably deteriorated further... Rigorous methodology is critical, and this needs to be imposed top-down without compromise"
7
51
150
Prediction model ‘validation’ using a split sample

8
11
148
** NEW PAPER - now published **
"Minimum sample size calculations for external validation of a clinical prediction model with a time‐to‐event outcome"
Open access in Statistics in Medicine

2
44
150
3. Prof Riley's response made my concerns much worse
4. The committee concluded that Dr Riley's methods are not truly innovative
5. Equation (8) is a very clever reformation (I didn’t realise he was that clever)”
2
2
148
Academics do much 'hidden' work that takes HOURS!
eg
- grant reviews & panels
- steering committees
- promotion applications
- external examining (PhDs, MSc courses etc)
- article reviews
- editorial & advisory roles
- interviews & chairing
We need to acknowledge this far better
5
18
146
***NEW PAPER***
"Minimum sample size for developing a multivariable prediction model using multinomial logistic regression"
Extends our work for continuous, binary & survival models
Led by Alex Pate &
@glen_martin1

1
30
143
Academics a few weeks ago: “we may be forced to work at home? Great, I can finish those crucial papers the world has been waiting for!”
Academics working at home this week: “actually, those papers don’t seem so important anymore....”
2
7
142
TIP: when reviewing a prediction model study, start by searching for these words:
- sample size
- calibration
- missing data
- TRIPOD
Failure to mention these is heavily linked with a poor quality study.
Most studies fail to mention at least one of these, & many ignore all.
11
24
144
"Is Medicine Mesmerized by Machine Learning?" - spend 10 minutes reading this excellent blog by
@f2harrell
on why stats methods remain crucial for risk prediction in healthcare; the ML field is too focused on classification & rarely examines calibration
1
61
142
Just read a published protocol for a prediction model development study, which says:
"Random forest will be chosen because of its popularity"
We need to justify analysis methods on science, not on popularity. Can't believe this even needs saying.
7
13
141
📽️ NEW VIDEO 📽️
"Sample size calculations for external validation of a clinical prediction model"
- what sample size is required for a validation study aiming to precisely estimate model performance?
- 30 min broad overview 👇
#stats
#MachineLearning

4
50
141
ICYMI:
"On the 12th day of Christmas a statistician sent to me"
Our educational article in
@bmj_latest
Christmas 2022 issue
The recommendations are for life, not just for Christmas - so please share 🙏
Here's a one-page summary to pin to your wall

1
52
138
May reminder:
I² estimates between-study heterogeneity: NO❌
I² is a test for between-study heterogeneity: NO❌
I² > 50% means large heterogeneity: NO❌
I² measures percentage of total variability due to between-study heterogeneity: YES✅

4
45
140
NEW BMJ GUIDANCE PAPER: Calculating the sample size required for developing a clinical prediction model - with collaborators
@MaartenvSmeden
@GSCollins
@joie_ensor
@Kym_Snell
@CarlMoons
@f2harrell
@glen_martin1
@hans_reitsma
4
45
137
Well written introductory article: "Overview of clinical prediction models" Provocative, though, that it is aimed at clinicians doing prediction model research who don't have time to read the books of
@f2harrell
or
@ESteyerberg
... 1/3

4
50
136
When responding to a reviewer who has clearly spent many hours reading your work and making comments to help you improve it, the first thing to say in response is 'thank you'.
4
9
139
Remember, it's not about statistics versus machine learning
Rather, it's about the right method to answer the right research question
2
18
139
*NEW PAPER*
"Poor handling of continuous predictors in clinical prediction models using logistic regression: a systematic review"
@JClinEpi
thanks to Jie Ma,
@pauladhiman
&
@GSCollins
for leading this important paper showcasing current shortcomings
3
40
137
This reminds me of how machine learners react to my independent validation of their over-fitted model
5
29
133
Reviewed a paper examining age as a treatment effect modifier
Me: "What's rationale for dichotomizing age at 60?"
Authors: "It's a commonly used cut-off"
Me: "Please also consider non-linear interaction"
Authors: "No. Not in protocol. We need a different stats reviewer"
9
11
136
*** NEW PAPER ***
"Minimum sample size for external validation of a clinical prediction model with a binary outcome"
Many thanks to co-authors
@Kym_Snell
@GSCollins
@joie_ensor
@LucindaAArcher
@MaartenvSmeden
@TPA_Debray
Open-access⬇️
4
38
134
10. The choice of font is rather old fashioned
A reviewer just criticised our report because:
"The choice of font is rather old fashioned."
So ignorant. We used Times *NEW* Roman.
12
27
522
4
3
132
I think this may be the greatest video I've ever seen
- resonates very strongly! And I love the ending.

20
25
133
ICYMI
BMJ series: Evaluation of Clinical Prediction Models
part 1: from development to external validation
part 2: undertaking an external validation study
part 3: calculating the sample size for external validation (out Monday!)

2
45
135
Really pleased to share the cover for our new book on IPD meta-analysis - hope you like it!
Asked my young daughter for her verdict.
She laughed out loud & said:
"It says 'willy' in the corner!"
Not the response I expected.
Apologies
@wileyinresearch

4
15
130
Annotate your code. Always.
Love your future self, and they will love you too.
2
8
131
⭐️New 15-min video⭐️
"Sample size calculations for clinical prediction model research"
(aka 'goodbye rules of thumb')
For broad audience, I describe how to calculate the sample size required for developing or validating prediction models in healthcare👇

1
44
130
NEW: Minimum sample size for developing a multivariable prediction model PART II: binary & time‐to‐event outcomes. Big thanks to
@GSCollins
@f2harrell
@Kym_Snell
@CarlMoons
@DanielleBurke88
@joie_ensor
Calculate minimum EPV required based on three criteria

4
61
126