
Rémi Leblond
@RemiLeblond
Followers
1,668
Following
155
Media
2
Statuses
112
Research Scientist @GoogleDeepMind . #Gemini , #AlphaCode , #AlphaStar . Working on solving hard problems with machine learning.
Joined December 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
namjoon
• 345951 Tweets
Linkin Park
• 156583 Tweets
Adalet
• 138014 Tweets
FOR ASIA
• 123469 Tweets
BTS PAVED THE WAY
• 84214 Tweets
Chester
• 81106 Tweets
علي النبي
• 79573 Tweets
小泉進次郎
• 59762 Tweets
Hayırlı Cumalar
• 49643 Tweets
#يوم_الجمعه
• 34670 Tweets
エイリアン
• 32686 Tweets
知的レベル
• 30194 Tweets
資さんうどん
• 29932 Tweets
GRABTOUR LINGORM
• 28507 Tweets
すかいらーく
• 27005 Tweets
大阪府警
• 20282 Tweets
MARK TUAN BD FAN MEETING
• 19993 Tweets
ベイマックス
• 17462 Tweets
Milli Savunma Bakanlığı
• 16324 Tweets
フリーランスの田中
• 13709 Tweets
神ちゃん
• 10898 Tweets
#ガラッとチェンジマン
• 10515 Tweets





















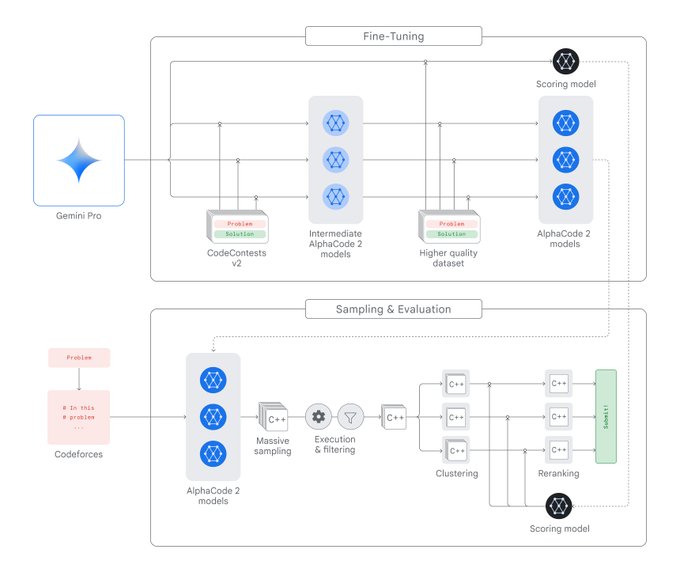
So excited to share what the team and I have been working on these last months!
#AlphaCode
2 is powered by Gemini and performs better than 85% of competition participants in 12 contests on Codeforces! More details at
@GoogleDeepMind
19
73
462
Hey Horace, cool analysis as ever! Let me give you a bit of reassurance; long tweet alert! (I had to subscribe for this 😅)
TL;DR All problems we evaluate on are held out, our models have never seen either them, their solutions or their tutorials.
As you can imagine, we’ve done

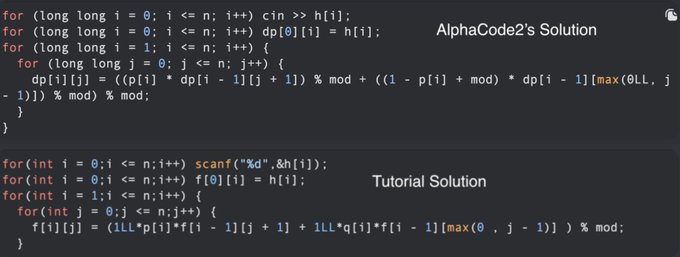
I reverse-engineered AlphaCode2's submission history and manually performed the Codeforces evals.
I'm ... again concerned that data leakage is affecting the results.
For the DP problem highlighted in the AlphaCode2 release, look at AC2's solution vs. the tutorial.
(1/5)
14
68
754
13
28
337
We’re looking for a great research scientist/engineer to bolster the LLM contingent in
@GoogleDeepMind
’s Paris office. If you want to build on our successes in the domain (
#chinchilla
,
#AlphaCode
…), and see what Gemini is capable of, DM me! 🗼
6
48
171
Check out our interview with the amazing
@ykilcher
for a sneak peek into the
#AlphaCode
project! Hope you have as much fun watching as we had recording it. Thanks again Yannic for having us!

I'm very happy to present this interview with Rémi Leblond and Peter Choy, two co-creators of AlphaCode! Learn the story behind the paper, whether these models actually understand the code they write, and what the future of AI code systems has in store:

1
25
119
0
15
120
So happy to finally present what I've been working on! Still can't quite believe some of the problems
#AlphaCode
can solve, but we still have a long way to go!

Below is an example of a problem
#AlphaCode
can successfully solve, using the exact information seen on
@codeforces
, & the program that
#AlphaCode
writes.
By
@liyuajia
, David Choi,
@junyoungch
,
@NateKushman
,
@Mononofu
,
@RemiLeblond
, Tom Eccles, James Keeling,
@FelixAxelGimeno
2/
42
497
2K
4
12
117
Check out our latest paper ! We investigate using MCTS with a value network for machine translation decoding. Joint work with the amazing
@jalayrac
,
@laurentsifre
,
@Miruna_Pislar
, JB Lespiau, Ioannis Antonoglou, Karen Simonyan and
@OriolVinyalsML
1/4
1
7
49
Yet another great example that LLMs + search can deliver incredible results when automated evals are available!
#AlphaCode
2 is based on similar ideas: we only have access to imperfect evals (example i/o) but we leverage learned eval models to great success! Congrats to our
Introducing FunSearch in
@Nature
: a method using large language models to search for new solutions in mathematics & computer science. 🔍
It pairs the creativity of an LLM with an automated evaluator to guard against hallucinations and incorrect ideas. 🧵
48
516
2K
3
1
49
@GoogleDeepMind
See the model in action on a 'G' problem from Codeforces/CodeTON round 4, rated 3200 (very hard)!
5
6
37
Can continuous diffusion lead to good language models too? It turns out that the answer is yes!
Very happy to share this work led by the amazing
@robinstrudel
!
Even if text is discrete, its neural embeddings are not, so we can simply run Gaussian diffusion in embedding space!

New paper SED , led by our intern
@robinstrudel
.
TL;DR: convincing & scalable general-purpose text diffusion can be achieved by combining continuous diffusion on pre-trained embeddings and self conditioning.
An example of its reverse process🦫:
2
15
84
0
7
27
@GoogleDeepMind
@c_tallec
@FelixAxelGimeno
@saade_alaa
@paul__caron
@antonruddock
@MLochbrunner
@MattMikula
Special thanks to
@OriolVinyalsML
,
@koraykv
,
@NandoDF
,
@pushmeet
, Satinder Singh Baveja,
@liyuajia
,
@NateKushman
and
@junyoungch
for their support and guidance throughout!
2
1
17
@GoogleDeepMind
This was a huge team effort with the peerless
@c_tallec
,
@FelixAxelGimeno
,
@saade_alaa
,
@paul__caron
, Florent Altché,
@antonruddock
, Jean-Bastien Grill,
@MLochbrunner
,
@MattMikula
, Michael Matthieu, George Powell, Grace Margand and Jakub Sygnowski Congrats to the team!
3
1
15
Our SeaRNN paper was just accepted at ICLR 2018! You can now check out our code at . All feedback/contributions welcome!
@jalayrac
@aosokin_ml

0
4
14
I’m at
#NeurIPS2022
until Friday! Happy to chat about DeepMind in Paris and all things
#AlphaCode
. We’ll be showcasing it at the DeepMind booth (hall G) today at 2pm!
0
0
8
This issue disappears for unsupervised metrics, where we can train high-quality value networks and consequently comfortably outperform beam search using a reasonable amount of MCTS simulations. 3/4
1
0
7
MQA (aka 'single-kv') is a criminally underused superpower. I never leave home without it. Whenever you want to sample a lot from your transformer (I know I always do!
#AlphaCode
), it's a free 8-12x speed improvement, at no cost to accuracy, which is insane! Noam is a wizard!

This paper has a very clear presentation of different attention architectures in transformers. I’d be thankful if people could share their experience in trying multi-query vs standard multi-head attention. Thanks
2
13
84
1
0
8
Together with pseudo-code for a numpy-compatible batched MCTS implementation, our results open the door for many exciting decoding applications. 4/4
0
0
6
@cHHillee
@dust68133035267
@kipperrii
We ran quite a few ablations to confirm which parts of the pipeline helped the most; so the aggregate performance will no reflect the final AC2 performance. To get the precise information, take a look at the 'AdamantChicken2' CF user. 😀
0
0
4
We find that it’s difficult to beat beam search for BLEU. Training a value network for supervised metrics is really hard; for it to be precise it requires reconstructing the ground truth, which is the policy problem! 2/4
1
0
3
@kastnerkyle
@aosokin_ml
@abursuc
@jalayrac
and I will be in Montreal in a couple weeks, we'll be able to discuss it then!
1
0
2
@debarghya_das
AlphaCode 2 performs even better 😉, and includes a reward model as a learned proxy for the 'code integrity' component. See for more details on how we integrate LLMs and search for competitive programming!
0
1
2
@LukaszBorchmann
@arankomatsuzaki
@DeepMind
Hey Łukasz, thanks for the pointer! We'll update the wording in our related work section in our next revision.
0
0
2
@LChoshen
@prajdabre1
I think I was complimenting
@LChoshen
on the very nice “rl weaknesses for MT paper” while idly wondering if models trained with SeaRNN () might fare better (as they’re an order of magnitude less confident).

0
0
2
@cHHillee
So weirdly enough 1844 actually took place two weeks after our last contest, 1845 😀!
Originally we’d planned the eval for August so we prepared the contest data at the end of June, spanning the last 3 months; then we filtered out div 3 and duplicate contests, and finally
0
0
1
@typedfemale
We did try a while ago for translation! Results were contrasted as learning good value functions for text is often quite difficult. The approach did show some promise 😊. And yes MCTS + transformers is challenging.
Check out our latest paper ! We investigate using MCTS with a value network for machine translation decoding. Joint work with the amazing
@jalayrac
,
@laurentsifre
,
@Miruna_Pislar
, JB Lespiau, Ioannis Antonoglou, Karen Simonyan and
@OriolVinyalsML
1/4
1
7
49
1
0
1
Worked like a charm on all applications I’ve tried, provided you reuse the weights you lose in the keys & values in wider FFN layers in your attention blocks. Based on the fact that inference cost for reasonably-sized models is dominated by reading k & vs from accelerator memory
1
0
1
@prajdabre1
If memory serves,
@LChoshen
referenced your paper in a completely unrelated conversation we were having, somehow the idea stuck with me! 🙂
1
0
1
Caveats: only speeds up sampling, not training. Only helps for auto-regressive models. Probably less efficient for humongous models who remain compute-bound during inference.
0
0
1
@Priyansh_31Dec
We first rank the groups according to their size, as in AC1. We use the a Gemini-based scoring model to choose which sample from each of the 10 biggest groups we submit :-)
1
0
1
MQA (aka 'single-kv') is a criminally underused superpower. I never leave home without it. Whenever you want to sample a lot from your transformer (I know I always do!
#AlphaCode
), it's a free 8-12x speed improvement, at no cost to accuracy, which is insane! Noam is a wizard!
1
0
8
0
0
1