

Mu Cai @ Industry Job Market
@MuCai7
Followers
578
Following
515
Statuses
157
Ph.D. student @WisconsinCS, Multimodal Large Language Models Will graduate around 2025 May, looking for Research Scientist position around multimodal models.
Madison, WI
Joined May 2019
🚨 I’ll be at #NeurIPS2024! 🚨On the industry job market this year and eager to connect in person! 🔍 My research explores multimodal learning, with a focus on object-level understanding and video understanding. 📜 3 papers at NeurIPS 2024: Workshop on Video-Language Models 📅 Sat, Dec 14 | 10:20 a.m. MST 1️⃣ TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models (Oral) 🔗 2️⃣ Matryoshka Multimodal Models 🔗 Main Conference Poster Session 📅 Thu, Dec 12 | 12:00–3:00 p.m. MST 📍 East Exhibit Hall A-C, #3706 3️⃣ Yo’LLaVA: Your Personalized Language and Vision Assistant 🔗 Check out my work: 🌐 My webpage Let’s chat if you’re around! 🚀

5
22
138
Want to use the simplest manner to apply multimodal model (LLaVA) to robotics task? Checkout LLaRA ( accepted to #ICLR2025 ), which you get a vision-language-action (VLA) policy! Joint work with @XiangLi54505720, @ryoo_michael, et al from Stony Brook U, and @yong_jae_lee

(1/5) Excited to present our #ICLR2025 paper, LLaRA, at NYC CV Day! LLaRA efficiently transforms a pretrained Vision-Language Model (VLM) into a robot Vision-Language-Action (VLA) policy, even with a limited amount of training data. More details are in the thread. ⬇️



0
11
58
Two papers are accepted to @iclr_conf #iclr #ICLR2025 (1) Efficient Multimodal LLM — Matryoshka Multimodal Models (2) Multimodal for Robotics — LLaRA: Supercharging Robot Learning Data for Vision-Language Model Policy I’m graduating this spring and actively seeking an industry research scientist position focused on multimodal models. Please feel free to connect with me if you think my background aligns with your team’s needs. Here’s my homepage for more details:

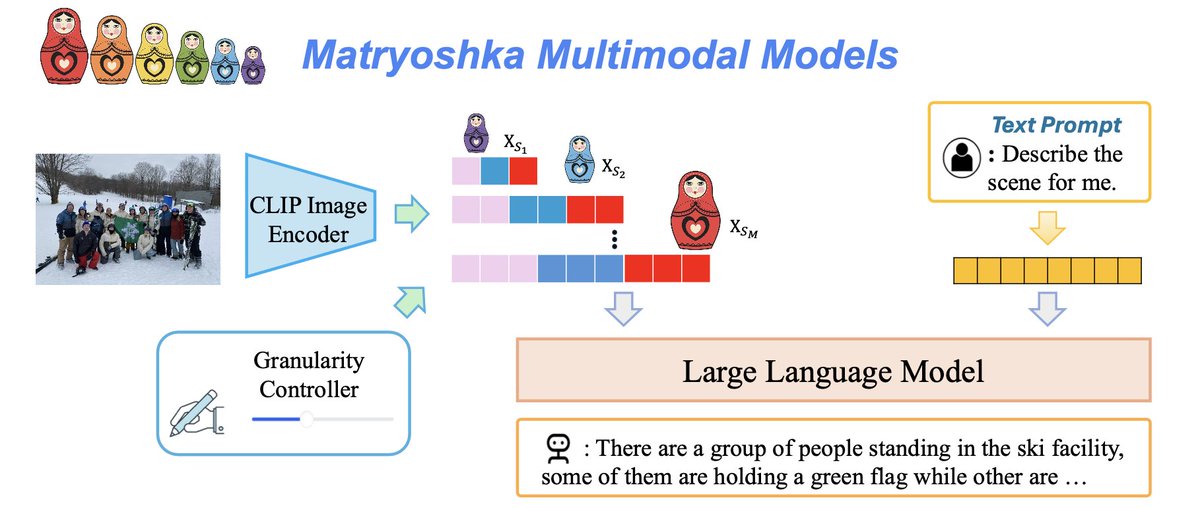
Thanks for @_akhaliq 's sharing! (1/N) We propose M3: Matryoshka Multimodal Models, which (1) reduces the number of visual tokens significantly while maintaining as good performance as vanilla LMM (2) organizes visual tokens in a coarse-to-fine nested way.
2
11
73
Thank you for organizing this event! I’m excited to give my talk on Friday. I’m graduating this spring and actively seeking an industry research scientist position focused on multimodal models. Please feel free to connect with me if you think my background aligns with your team’s needs. Here’s my homepage for more details:

~ New Webinar ~ In the 67th session of #MultimodalWeekly, we have three exciting presentations on multimodal benchmarks, video prediction, and multimodal video models.

0
0
7
RT @xyz2maureen: 🔥Poster: Fri 13 Dec 4:30 pm - 7:30 pm PST (West) It is the first time for me try to sell a new concept that I believe but…
0
14
0
I am not in #EMNLP2024 but @bochengzou is in Florida! Go checkout vector graphics, a promising format that is completely different from pixels for visual representation. Thanks to LLMs, vector graphics are more powerful now! Go chat with @bochengzou if you are interested!
VGBench is accepted to EMNLP main conference! Congratulations to the team @bochengzou @HyperStorm9682 @yong_jae_lee. The first work for "Evaluating Large Language Models on Vector Graphics Understanding and Generation" as a comprehensive benchmark!
0
1
9
@HaoningTimothy @ChunyuanLi @zhang_yuanhan Hi @HaoningTimothy, we actually have results on more frames. See the table here:
1
0
1
RT @jd92wang: Personal update: After 5.5 yrs at @MSFTResearch , I will join @williamandmary in 2025 to be an assistant professor. Welcome t…
0
23
0
RT @zhang_yuanhan: Fine-grained temporal understanding is fundamental for any video understanding model. Excited to see LLaVA-Video showing…
0
13
0
Great work on apply multi-granularity idea on image generation/manipulation! This share the same visual encoding design as our earlier work Matryoshka Multimodal Models (, where pooling is used to control visual granularity, leading to a multi visual-granularity LLaVA.

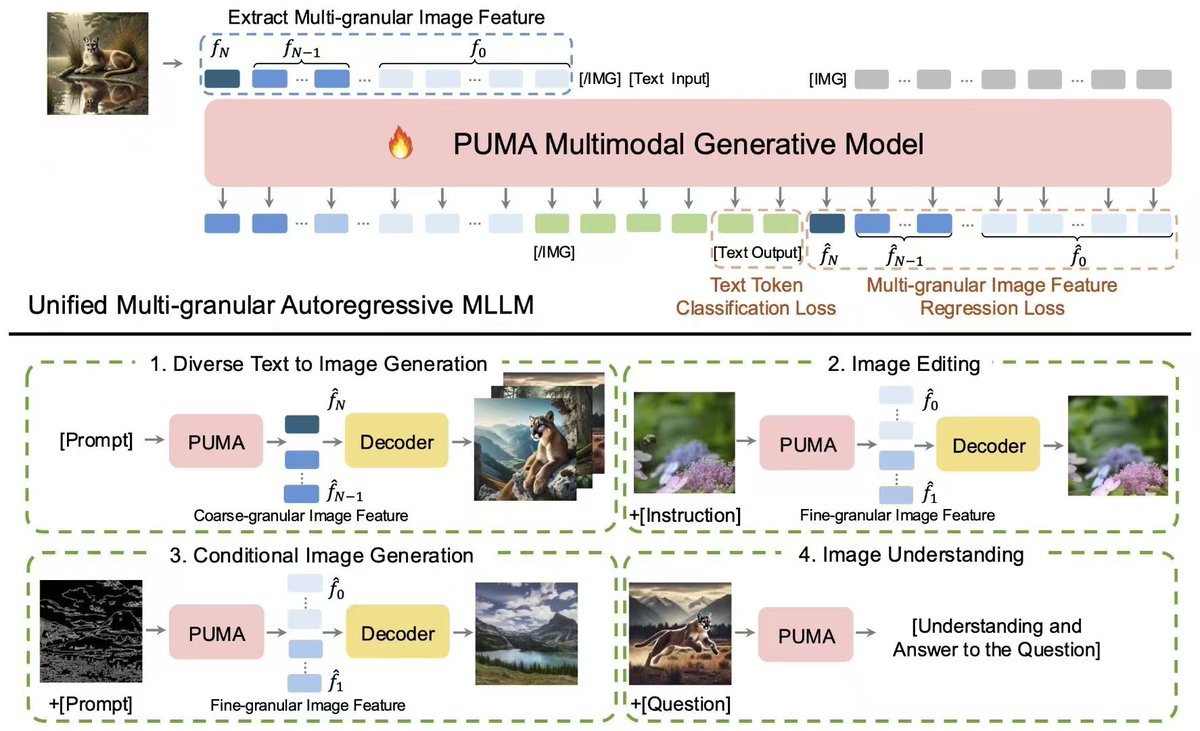
Introducing PUMA: a new MLLM for unified vision-language understanding and visual content generation at various granularities, from diverse text-to-image generation to precise image manipulation.

0
0
17