
Minhyuk Sung
@MinhyukSung
Followers
2K
Following
226
Media
37
Statuses
105
Associate professor @ KAIST | KAIST Visual AI Group: https://t.co/mblvQKFc8t.
Daejeon, Republic of Korea
Joined October 2021
Had an incredible opportunity to give two lectures on diffusion models at MLSS-Sénégal 🇸🇳 in early July!. Slides are available here:. Big thanks to @eugene_ndiaye for the invitation!.

🥳MLSS (Machine Learning Summer School) arrive au Sénégal 🇸🇳 en 2025! 🌍.📍 AIMS Mbour, Senegal.📅 23 Juin - 4 Juillet, 2025. Une école d'été internationale pour explorer, collaborer et approfondir votre compréhension du Machine Learning. 🔗 :

1
6
15
I recently presented our work, “Inference-Time Guided Generation with Diffusion and Flow Models,” at HKUST (CVM 2025 keynote) and NTU (MMLab), covering three classes of guidance methods for diffusion models and their extensions to flow models. Slides:


0
20
108
#ICLR2025 Come join our StochSync poster (#103) this morning! We introduce a method that combines the best parts of Score Distillation Sampling and Diffusion Synchronization to generate high-quality and consistent panoramas and mesh textures.
stochsync.github.io
Hello world!

🎉 Join us tomorrow at the #ICLR2025 poster session to learn about our work, "StochSync," extending pretrained diffusion models to generate images in arbitrary spaces!. 📌: Hall 3 + Hall 2B #103.📅: Apr. 25. 10AM-12:30PM. [1/8]

0
7
21
🚀 We’re hiring!.The KAIST Visual AI Group is looking for Summer 2025 undergraduate interns. Interested in:.🌀 Diffusion / Flow / AR models (images, videos, text, more).🧠 VLMs / LLMs / Foundation models.🧊 3D generation & neural rendering. Apply now 👉

2
19
104

Introducing ORIGEN: the first orientation-grounding method for image generation with multiple open-vocabulary objects. It’s a novel zero-shot, reward-guided approach using Langevin dynamics, built on a one-step generative model like Flux-schnell. Project:

🔥 Grounding 3D Orientation in Text-to-Image 🔥.🎯 We present ORIGEN — the first zero-shot method for accurate 3D orientation grounding in text-to-image generation!. 📄 Paper: 🌐 Project:

0
5
30
GPT-4o vs. Our test-time scaling with FLUX (2/2). GPT-4o cannot precisely understand the text (e.g., misinterpreting “occupying chairs” on the left), while our test-time technique generates an image perfectly aligned with the prompt. Check out more 👇.🌐

2
5
53
GPT-4o vs. Our test-time scaling with FLUX (1/2). GPT-4o still cannot count objects (see the ten, not seven, tomatoes on the left), but our test-time technique makes it work with FLUX. What you need is not a new model, but a test-time technique!. 🌐

0
12
57
Unconditional Priors Matter!. The key to improving CFG-based "conditional" generation in diffusion models actually lies in the quality of their "unconditional" prior. Replace it with a better one to improve conditional generation!. 🌐

Unconditional Priors Matter! Improving Conditional Generation of Fine-Tuned Diffusion Models without Additional Training Costs. arXiv: Project:
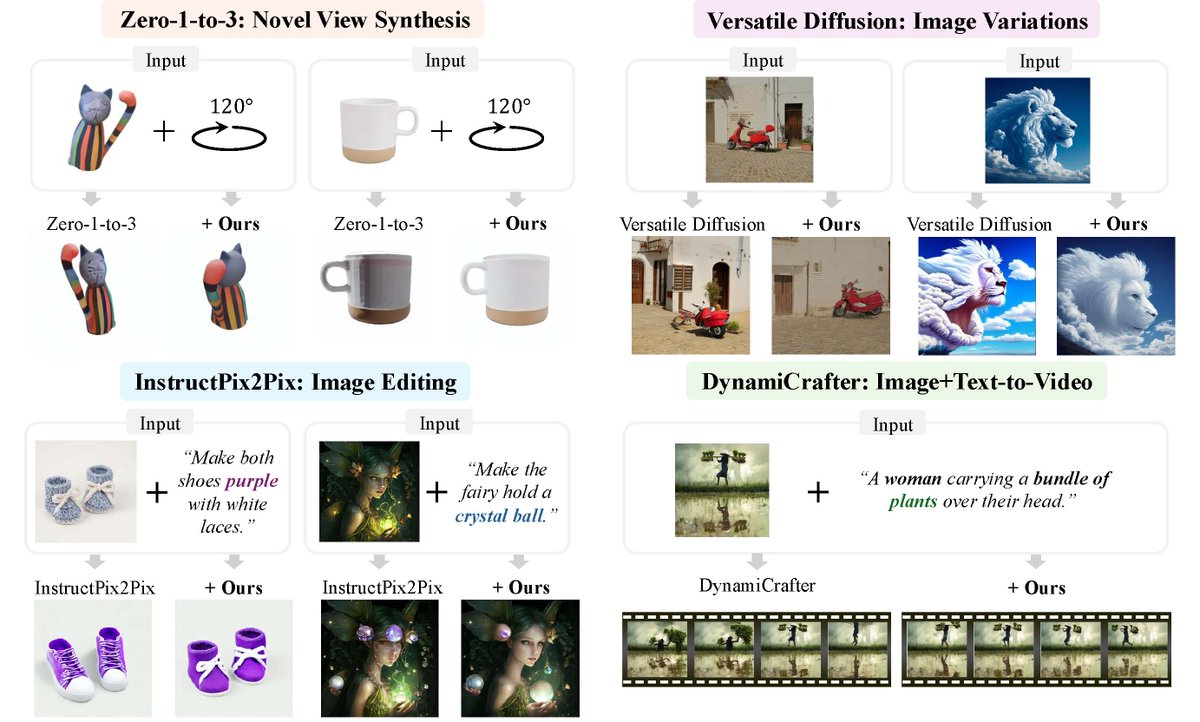
0
4
26
Thanks @_akhaliq! Our test-time technique makes image flow models way more controllable—better at matching text prompts, object counts, and object relationships; adding or removing concepts; and improving image aesthetics—all without finetuning!. Project:

Inference-Time Scaling for Flow Models via.Stochastic Generation and Rollover Budget Forcing
0
10
73
🚀 Inference-time scaling for FLUX! Significant improvements in reward-guided generation with flow models, including text alignment, object counts, etc.—all at a compute cost under just $1! . 📄 Paper: 🔗 Project:

arxiv.org
We propose an inference-time scaling approach for pretrained flow models. Recently, inference-time scaling has gained significant attention in LLMs and diffusion models, improving sample quality...

🔥 Pushing flow models to new frontiers 🔥. 🚀 Our inference-time scaling precisely aligns pretrained flow models with user preferences—such as text prompts, object quantities, and more—for under $1! 💵. 📄 Paper: 🔗 Project:
0
4
37
#CVPR2025.🚀Check out **VideoHandles** by Juil (@juilkoo), the first method for test-time 3D object composition editing in videos. 🔗 Project: 📄 arXiv:

arxiv.org
Generative methods for image and video editing use generative models as priors to perform edits despite incomplete information, such as changing the composition of 3D objects shown in a single...

Introducing "VideoHandles"—the first method for 3D object composition editing in videos, accepted to #CVPR2025!. [Project Page]: [arXiv]:
0
5
36
#NeurIPS2024 .DiT generates not only higher-quality images but also opens up new possibilities for improving training-free spatial grounding. Come visit @yuseungleee 's GrounDiT poster to see how it works. Fri 4:30 p.m. - 7:30 p.m. East #2510. 🌐
groundit-diffusion.github.io
GrounDiT: Grounding Diffusion Transformers via Noisy Patch Transplantation, 2024.

🇨🇦 Happy to present GrounDiT at #NeurIPS2024!. Find out how we can obtain **precise spatial control** in DiT-based image generation!. 📌 Poster: Fri 4:30PM - 7:30PM PST. 💻 Our code is also released at:

1
11
52
#NeurIPS2024.Thursday afternoon, don't miss @USeungwoo0115's poster on Neural Pose Representation, a framework for pose generation and transfer based on neural keypoint representation and Jacobian field decoding. Thu 4:30 p.m. - 7:30 p.m. East #2202. 🌐

🚀 Enjoying #NeurIPS2024 so far? . Don’t miss our poster session featuring the paper “Neural Pose Representation Learning for Generating and Transferring Non-Rigid Object Poses” tomorrow!. 📍 Poster Session: Thu, Dec 12, 4:30–7:30 PM PST, Booth #2202, East Hall A-C.

0
3
12
#NeurIPS2024.We'll be presenting SyncTweedies on Wednesday morning, a training-free diffusion synchronization technique that enables generation of various types of visual content using an image diffusion model. Wed, 11 a.m. - 2 p.m. PST.East #2605. 🌐
synctweedies.github.io
SyncTweedies: A General Generative Framework Based on Synchronized Diffusions, 2024.
🚀 Excited to share that our work, SyncTweedies: A General Generative Framework Based on Synchronized Diffusions will be presented at NeurIPS 2024 🇨🇦! . 📌 If you are interested, visit our poster (#2605) 11 Dec 11AM — 2PM at East Exhibit Hall A-C.

0
4
18
#SIGGRAPHAsia2024.🔥 Replace your Marching Cubes code with our Occupancy-Based Dual Contouring to reveal the "real" shape from either a signed distance function or an occupancy function. No neural networks involved. Web:
6
56
271
A huge thank you to Jiaming Song (@baaadas) for delivering a wonderful guest lecture in our "Diffusion Models and Applications" course! He shared valuable insights on video generative models and the future of generative AI. 🎥 📚
2
28
134
#DiffusionModels.🎓 Our "Diffusion Models and Their Applications" course is now fully available! It includes all the lecture slides, recordings, and hands-on programming assignments. Hope it helps anyone studying diffusion models. 🌐
5
98
393
#DiffusionModels.Big thanks to @OPatashnik for the insightful guest lecture in our diffusion models course on using attention layers in diffusion networks for image manipulation. Don’t miss the recording!.🎥:
0
11
56
#NeurIPS2024.We introduce GrounDiT, a SotA training-free spatial grounding technique leveraging a unique property of DiT: sharing semantics in the joint denoising process. Discover how we **transplant** object patches to designated boxes. Great work by @yuseungleee and Taehoon.
🌟 Introducing GrounDiT, accepted to #NeurIPS2024!. "GrounDiT: Grounding Diffusion Transformers.via Noisy Patch Transplantation". We offer **precise** spatial control for DiT-based T2I generation. 📌 Paper: 📌 Project Page: [1/n]

1
3
46