

Haohe Liu
@LiuHaohe
Followers
2K
Following
1K
Statuses
234
PhD student at @cvssp_research, @UniOfSurrey, UK, working with @markplumbley. Ex-intern at @Meta @MicrosoftASIA & @BytedanceTalk. https://t.co/qmZe2lvGHX
Joined October 2021
AudioLDM (ICML 2023) has officially joined the 🧨 Diffusers library! With up to 5x faster speeds and 3 different model sizes. Huge thanks to @sanchitgandhi99 for making it happen! 🥳 HF space has also gotten a significant speed boost! Get started now!
7
36
237
RT @ArxivSound: ``Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis,'' Zhen Ye, Xinfa Zhu, Chi-Min Chan…
0
8
0

One-step diffusion-based audio super-resolution! FlashSR would make scaling up much easier. Excited to see this as a great follow-up to AudioSR.

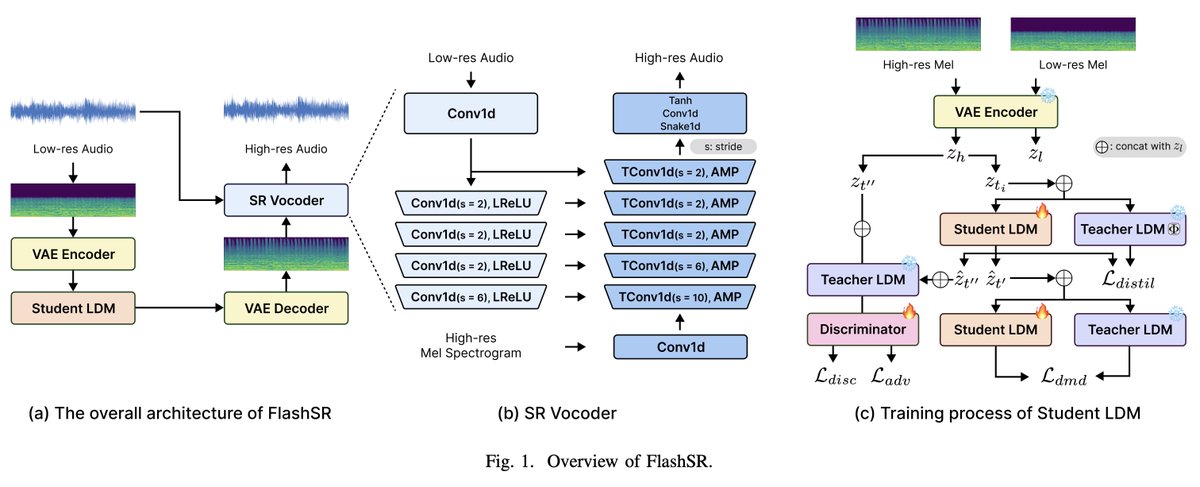
🌟 Excited to announce the release of the code and model weights for FlashSR: One-step Versatile Audio Super-resolution via Diffusion Distillation, accepted at ICASSP 2025! 🎉 🔗 Check out the demo, code, and paper here:
0
2
9
New 6M Audio-Caption Paired Dataset! Great work lead by @JishengBai

Excited to share our latest work: AudioSetCaps — the largest audio-caption dataset to date, with 6 million audio-caption pairs (fully open-sourced)! 🔗 ArXiv Paper: 🔗 GitHub: 🔗 HF:

0
0
3
RT @JishengBai: Excited to share our latest work: AudioSetCaps — the largest audio-caption dataset to date, with 6 million audio-caption pa…
0
2
0
RT @JishengBai: This paper is an extension of our NeurIPS 2024 Audio Imagination Workshop paper (, where we discuss…
0
2
0
The SemantiCodec paper has been accepted by the IEEE Journal of Selected Topics in Signal Processing Huge thanks to all the contributors and reviewers!
Excited to introduce SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound 🎉 SemantiCodec (50 tokens/second or 0.71kbps) ≈ Previous methods (200 tokens/second or 2.0kbps). 🎉Our study also reveals that SemantiCodec tokens hold richer semantic information.


0
1
21
Had an awesome day at Télécom Paris @tp_adasp! Great discussions with many amazing researchers!

Great talk today by @LiuHaohe at the @tp_adasp group on Latent Diffusion Models (LDMs) as versatile audio decoder! Walked us through diffusion basics, AudioLDM for text-to-audio, audio quality enhancement, and neural codecs!

2
1
30
It's nice to see SemantiCodec taking the lead in audio codec semantic information benchmarking, even at a much lower bitrate. Paper result cross-validated! Great work! @realHaibinWu et al.

``Codec-SUPERB @ SLT 2024: A lightweight benchmark for neural audio codec models,'' Haibin Wu, Xuanjun Chen, Yi-Cheng Lin, Kaiwei Chang, Jiawei Du, Ke-Han Lu, Alexander H. Liu, Ho-Lam Chung, Yuan-Kuei Wu, Dongchao Yang, Songxiang Liu, Yi-Chiao Wu, Xu Tan…
0
3
18