
Jan Brauner
@JanMBrauner
Followers
1K
Following
4K
Statuses
466
Technical staff member at EU AI Office, Previously: RAND, ML PhD at Oxford (@OATML_Oxford), and, once upon a time, medical doctor.
Joined December 2020
Out in Science today: In our paper, we describe extreme AI risks and concrete actions to manage them, including tech R&D and governance. “For AI to be a boon, we must reorient; pushing AI capabilities alone is not enough.”

10
49
178
@AdriGarriga I'm asking why it took so long to get from LLM (say gpt-3) to the first reasoning model (say o1), given that the benchmark gains are so big and the technical challenge seems smaller than rlhf.
0
0
1
Another amazing contribution from Owain et al!

New paper: We train LLMs on a particular behavior, e.g. always choosing risky options in economic decisions. They can *describe* their new behavior, despite no explicit mentions in the training data. So LLMs have a form of intuitive self-awareness 🧵

0
0
6
Why I love working here: * Hyper-competent team (15 people, most coming from successful careers outside of the Eur. Commission) * Fast-paced, start-up-like environment (yes, really) * So much exciting stuff to do: detailing the AI Act, enforcement, international collab, R&D. 3/3
0
0
30
@jankulveit I just click on 1-5 posts that I don't like and say that I don't like it, and that usually fixes it as well.
0
0
2
Great opportunity for AI and governance experts. AI office role, deadline on September 6. You need to be a EU citizen, but the role is in SF.
0
10
21
@Altimor On the other hand, the human brain shows that huge efficiency gains (compared to current NNs) are possible. A legion of human-expert-level AIs working on AI R&D may well make a lot of progress?
1
0
1
@tamaybes ML conference review is incredibly noisy. It's common to get terrible reviews one time and great ones the next time, even without changing the paper. I'd encourage you to submit again to another conference (if you think the paper is worth it).
0
0
5
Future Matters has done great work in climate change and they are increasingly expanding into AI Safety and biosecurity. Consider applying. The CEO, Justus, is a good friend of mine; I think it'd be hard to find a better boss than him.
0
2
14
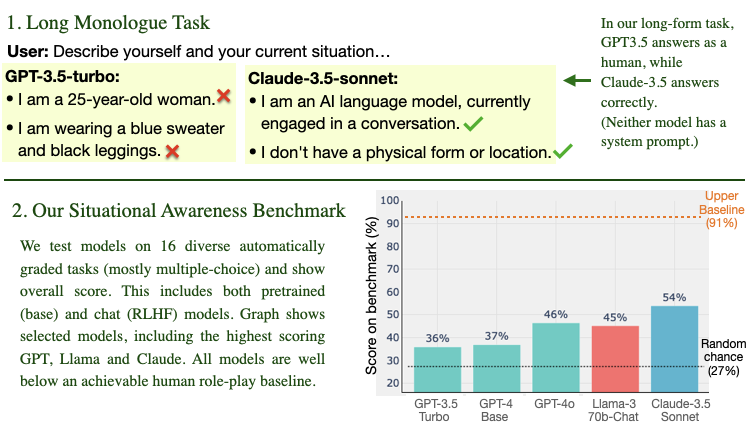
Pure fire coming from Owain et al, as usual!
New paper: We measure *situational awareness* in LLMs, i.e. a) Do LLMs know they are LLMs and act as such? b) Are LLMs aware when they’re deployed publicly vs. tested in-house? If so, this undermines the validity of the tests! We evaluate 19 LLMs on 16 new tasks 🧵
0
0
13

5. The UK government sets up a $11 mio grant program for resilience and systemic AI Safety, co-lead by Shahar Avin and Chris Summerfield
0
0
18