
Dhanvin Sriram
@DhaniSriram
Followers
898
Following
11K
Statuses
340
Currently building and scaling multiple AI products
Joined June 2023
1
0
0
0
0
3
0
0
0
@theo @FireworksAI_HQ NVIDIA is hosting it

NVIDIA just brought DeepSeek-R1 671-bn param model to NVIDIA NIM microservice on build.nvidia .com - The DeepSeek-R1 NIM microservice can deliver up to 3,872 tokens per second on a single NVIDIA HGX H200 system. - Using NVIDIA Hopper architecture, DeepSeek-R1 can deliver high-speed inference by leveraging FP8 Transformer Engines and 900 GB/s NVLink bandwidth for expert communication. - As usual with NVIDIA's NIM, its a enterprise-scale setu to securely experiment, and deploy AI agents with industry-standard APIs. @NVIDIAAIDev
0
0
0
“Is deep seeker a good name” lmao
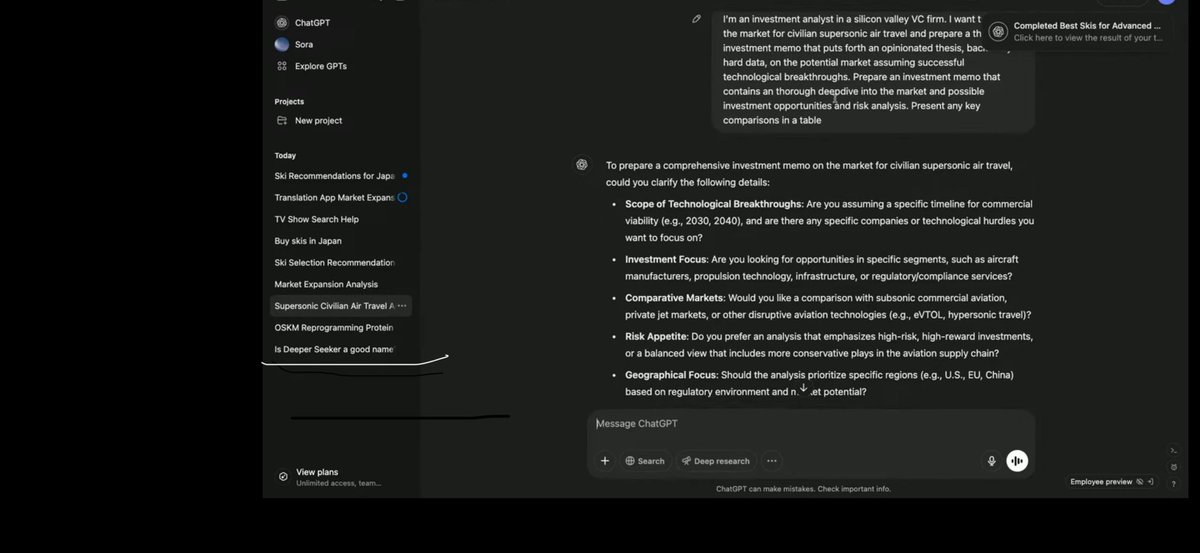

Today we are launching our next agent capable of doing work for you independently—deep research. Give it a prompt and ChatGPT will find, analyze & synthesize hundreds of online sources to create a comprehensive report in tens of minutes vs what would take a human many hours.
0
0
0
@EMostaque This is just a bug. I got it too but nothing happened after. I was still able to use o3
0
0
0
@ludwigABAP NVIDIA is hosting it
NVIDIA just brought DeepSeek-R1 671-bn param model to NVIDIA NIM microservice on build.nvidia .com - The DeepSeek-R1 NIM microservice can deliver up to 3,872 tokens per second on a single NVIDIA HGX H200 system. - Using NVIDIA Hopper architecture, DeepSeek-R1 can deliver high-speed inference by leveraging FP8 Transformer Engines and 900 GB/s NVLink bandwidth for expert communication. - As usual with NVIDIA's NIM, its a enterprise-scale setu to securely experiment, and deploy AI agents with industry-standard APIs. @NVIDIAAIDev
0
0
4

@timlihk Never said that. Hopper. Some my clients executives misinterpreted that as H100, but includes H20 and H800.
0
0
2