

ByteDance Open Source
@ByteDanceOSS
Followers
888
Following
144
Statuses
142
Announcing new releases and the latest information about ByteDance open source projects.
Joined December 2022
RT @rspack_dev: Rslib v0.4 introduces bundleless mode to preserve the source file structure: ✨ single file transformation 🎨 static assets…
0
25
0
RT @rspack_dev: We're working on improving the doc search experience. You can now search within code blocks, including configuration exampl…
0
3
0
Using LLM can speed up your learning process:)

"Using Cursor with DeepSeek to Quickly Get Started with Unfamiliar Components" by @xuanhun1 #DEVCommunity @ByteDanceOSS @deepseek_ai @cursor_ai #Cursor #OpenAI #DeepSeek
0
1
2
RT @TheTuringPost: Over-Tokenized Transformers framework changes how models handle tokens. Normally, input and output tokens come from the…
0
5
0
RT @midscene_ai: It's time to start using the open-source version of GPT Operator & Agents, which is Midscene & UI-TARS, with all tool mode…
0
4
0
RT @dr_cintas: 9. ByteDance has unveiled Doubao 1.5 Pro, a multimodal AI model that competes with top competitors like GPT-4o and Claude 3.…
0
13
0
🚀 Meet Agent-R: The AI that learns from its mistakes in real-time! 🧠 This clever agent uses "reflection" to dynamically improve its performance. #AI #MachineLearning #AgentR #Innovation

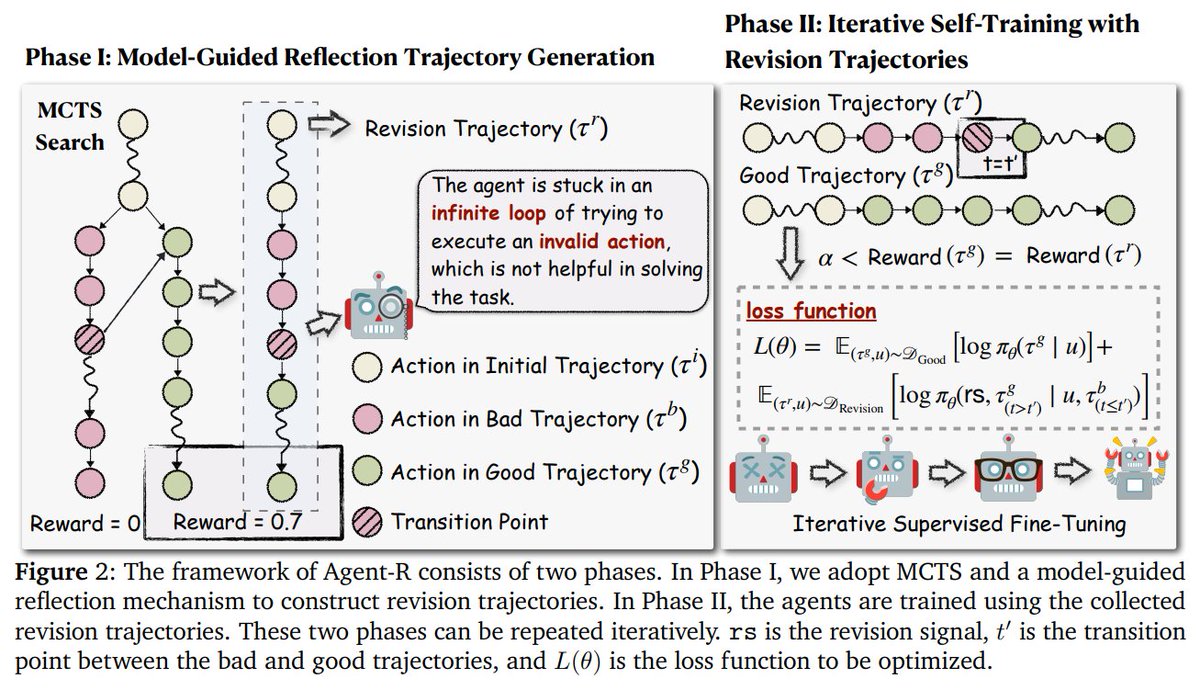
.@ByteDanceOSS introduced a fascinating development, Agent-R. Agent-R helps AI agents "reflect" on their mistakes as they work, learning from them dynamically. Using Monte Carlo Tree Search (MCTS) method, Agent-R fixes errors as they occur, helping the agent learn to self-correct in real time. What's special about Agent-R's workflow? ▪️ It identifies 4 types of reasoning paths: initial, bad, good, and revision. ▪️ Revision trajectories are fixed versions of the bad paths, which are used together with good paths for training the agent to self-correct. Overall, Agent-R's benefits include: - Dynamic error fixing - Self-reflection - Continuous learning - It significantly improves the agent's ability to perform long, complex tasks more effectively: +5.59% improvement over other methods. - Prevents the model from repeating mistakes or getting stuck in loops. - It's open source P.S. Interestingly, multi-task training with Agent-R was more effective than single-task training, so this method can be used to improve performance across different types of tasks. Check out all the links below👇
1
0
7
If you want to know how to support stream feature in LLM application, pleasech check out this article It introduces the significant features of Kitex/Hertz over the past year to empower LLMs. @CloudWeGo
0
0
0
RT @AdinaYakup: UI-TARS 🔥 series of native GUI agent models released by @ByteDanceOSS , combining perception, reasoning, grounding, and mem…
0
12
0
RT @rspack_dev: Announcing Rspack 1.2: ⚡️ Persistent cache: up to 250% faster ⚡️ Faster code splitting ⚡️ Less memory usage ⚡️ Smaller bun…
0
41
0
RT @Trae_ai: 🌟 The wait is over, Trae is officially launched! 💻 Start a conversation with Trae and discover how coding becomes smarter, f…
0
16
0
RT @rspack_dev: Mar 2023 - Rspack Oct 2023 - Rspress Nov 2023 - Rsbuild Jan 2024 - Rsdoctor Aug 2024 - Rslib Who will be next? We are conf…
0
15
0
RT @xtl994: We also release a stronger 26B Sa2VA model. @ByteDanceOSS @Gradio Please see the Bytedance Opensource Huggingface: https://t…
0
14
0
RT @BiologyAIDaily: Protenix: Advancing Structure Prediction Through a Comprehensive AlphaFold3 Reproduction @ByteDanceOSS - Protenix, an…
0
15
0
RT @AdinaYakup: Sa2Va 🔥 a unified model for dense grounded understanding of images & videos released by Bytedance. Model:
0
32
0
RT @rspack_dev: Rslib v0.2.0 is out! 🔸Improved bundleless mode 🔸Reduced output bundle size 🔸Support for .env files 🔸Support for config re…
0
8
0
RT @rspack_dev: We have an open bounty for improving Deno support in Rspack. You can find more details at If you…
0
2
0
Please check out ShadowKV, for high-throughput long-context LLM inference with memory-efficient & low-latency sparse attention.

❓Struggling with serving high-throughput long-context LLMs? 📢 Introducing ShadowKV! 🚀 Achieve high-throughput long-context LLM inference with memory-efficient & low-latency sparse attention! 🌟 ShadowKV minimizes memory footprint by storing low-rank keys on the GPU and offloading values, supporting larger batch sizes without accuracy loss. ⚡ Benchmarked on Llama-3.1-128K, Llama-3-1M, GLM-4-1M, & more, ShadowKV boosts throughput up to 3.04x on an A100 with a 6x batch size or 6x longer sequences! 🔍 Dive in to see how ShadowKV balances speed, memory, and precision across over 128K tokens! 📜 Paper: 🔗Blog: 💻 Code:

3
0
0
RT @rspack_dev: 🎉 Rslib v0.1 is now public! The goal of Rslib is to create JavaScript libraries in an simple and intuitive way. It curre…
0
37
0