

AI at Meta
@AIatMeta
Followers
601,752
Following
272
Media
946
Statuses
2,297
Together with the AI community, we are pushing the boundaries of what’s possible through open science to create a more connected world.
Joined August 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Puerto Rico
• 756756 Tweets
Ten Hag
• 388569 Tweets
Manchester United
• 227709 Tweets
París
• 225497 Tweets
Rodri
• 218256 Tweets
#CDTVライブライブ
• 192320 Tweets
Vini
• 170232 Tweets
Tyler
• 138234 Tweets
LINGLING THAI TOUR EP1
• 127593 Tweets
#HighSchoolFrenemyEP5
• 96575 Tweets
Ruud
• 96432 Tweets
Bola de Ouro
• 62582 Tweets
Fifth Veda Of God Kabir
• 58944 Tweets
Xavi
• 42703 Tweets
पप्पू यादव
• 35980 Tweets
Carvajal
• 34519 Tweets
기아 우승
• 34517 Tweets
frank ocean
• 28268 Tweets
Lautaro
• 21139 Tweets
#モンスター
• 20413 Tweets
新シナリオ
• 16207 Tweets
新時代の扉
• 14391 Tweets
メカウマ娘
• 14111 Tweets
Nagelsmann
• 13757 Tweets
Southgate
• 13690 Tweets
スカリーくん
• 13259 Tweets
リズミック
• 13109 Tweets
France Football
• 12975 Tweets
#เติมพลังเต็มถังให้นุนิว
• 12107 Tweets
Eurocopa
• 11722 Tweets
삐끼삐끼
• 11372 Tweets
上垣アナ
• 11059 Tweets
الكره الذهبيه
• 10637 Tweets




















Pinned Tweet

🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date.
Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in
371
2K
7K
We’re pleased to introduce Make-A-Video, our latest in
#GenerativeAI
research! With just a few words, this state-of-the-art AI system generates high-quality videos from text prompts.
Have an idea you want to see? Reply w/ your prompt using
#MetaAI
and we’ll share more results.
879
2K
8K
Introducing Meta Segment Anything Model 2 (SAM 2) — the first unified model for real-time, promptable object segmentation in images & videos.
SAM 2 is available today under Apache 2.0 so that anyone can use it to build their own experiences
Details ➡️
161
1K
7K
Today we're releasing the Segment Anything Model (SAM) — a step toward the first foundation model for image segmentation.
SAM is capable of one-click segmentation of any object from any photo or video + zero-shot transfer to other segmentation tasks ➡️
142
2K
7K
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3
350
1K
6K
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet.
Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context
282
1K
6K
Today we’re releasing Code Llama 70B: a new, more performant version of our LLM for code generation — available under the same license as previous Code Llama models.
Download the models ➡️
• CodeLlama-70B
• CodeLlama-70B-Python
• CodeLlama-70B-Instruct

168
1K
6K
Announced by Mark Zuckerberg this morning — today we're releasing DINOv2, the first method for training computer vision models that uses self-supervised learning to achieve results matching or exceeding industry standards.
More on this new work ➡️
90
895
4K
Today we’re announcing Meta LLM Compiler, a family of models built on Meta Code Llama with additional code optimization and compiler capabilities. These models can emulate the compiler, predict optimal passes for code size, and disassemble code. They can be fine-tuned for new

152
785
4K
Meta AI presents CICERO — the first AI to achieve human-level performance in Diplomacy, a strategy game which requires building trust, negotiating and cooperating with multiple players.
Learn more about
#CICERObyMetaAI
:
238
833
4K

Today we’re releasing Code Llama, a large language model built on top of Llama 2, fine-tuned for coding & state-of-the-art for publicly available coding tools.
Keeping with our open approach, Code Llama is publicly-available now for both research & commercial use.
More ⬇️
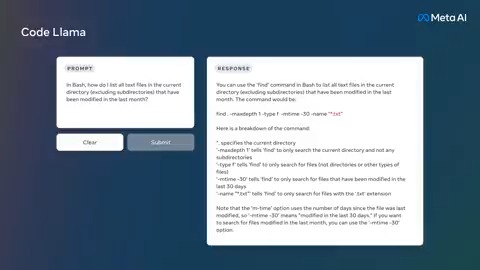
172
1K
4K
A few technical insights on our lightweight Llama 3.2 1B & 3B models. 🦙🧵
52
352
3K
Check out our latest breakthrough in machine translation that Mark Zuckerberg just announced. We built and open sourced a state-of-the-art AI model that now translates between 200 different languages.
54
647
3K
Today we're publicly releasing LLaMA, a state-of-the-art foundational LLM, as part of our ongoing commitment to open science, transparency and democratized access to new research.
Learn more & request access ➡️

67
656
3K
Today we’re introducing SceneScript, a novel method for reconstructing environments and representing the layout of physical spaces from
@RealityLabs
Research.
Details ➡️
SceneScript is able to directly infer a room’s geometry using end-to-end machine
47
516
3K
We believe an open approach is the right one for the development of today's Al models.
Today, we’re releasing Llama 2, the next generation of Meta’s open source Large Language Model, available for free for research & commercial use.
Details ➡️
180
757
3K
More technical details on the new Meta Llama 3 models announced today. 🦙🧵
41
278
3K
We just released PyTorch3D, a new toolkit for researchers and engineers that’s fast and modular for 3D deep learning research:
27
879
3K
Today we’re releasing V-JEPA, a method for teaching machines to understand and model the physical world by watching videos. This work is another important step towards
@ylecun
’s outlined vision of AI models that use a learned understanding of the world to plan, reason and
95
563
3K
Today we released Meta Spirit LM — our first open source multimodal language model that freely mixes text and speech.
Many existing AI voice experiences today use ASR to techniques to process speech before synthesizing with an LLM to generate text — but these approaches
69
511
3K
📣 New research from GenAI at Meta, introducing Meta 3D Gen: A new system for end-to-end generation of 3D assets from text in <1min.
Meta 3D Gen is a new combined AI system that can generate high-quality 3D assets, with both high-resolution textures and material maps end-to-end,
116
516
2K
New on
@huggingface
— CoTracker simultaneously tracks the movement of multiple points in videos using a flexible design based on a transformer network — it models correlation of the points in time via specialized attention layers.
🤗 Try CoTracker ➡️
40
430
2K
Announcing OPT-IML: a new language model from Meta AI with 175B parameters, fine-tuned on 2,000 language tasks — openly available soon under a noncommercial license for research use cases.
Research paper & more details on GitHub ⬇️
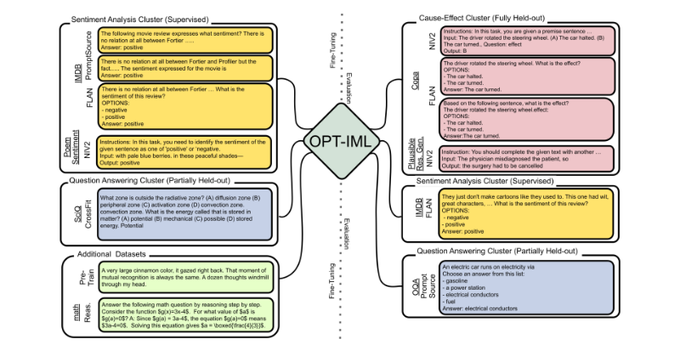
42
507
2K
By restructuring math expressions as a language, Facebook AI has developed the first neural network that uses symbolic reasoning to solve advanced mathematics problems.

34
757
2K
Today we're releasing the Open Catalyst Demo to the public — this new service will allow researchers to accelerate work in material sciences by enabling them to simulate the reactivity of catalyst materials ~1000x faster than existing computational methods using AI.
Demo ⬇️
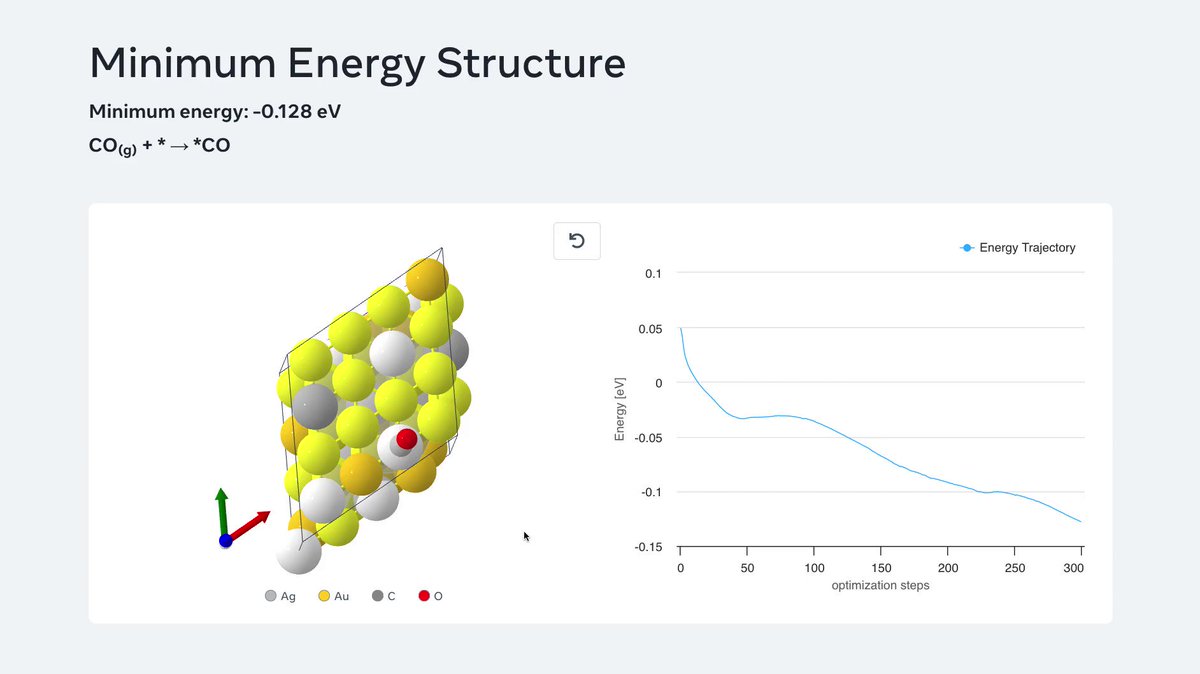
63
413
2K
Today Meta AI is sharing OPT-175B, the first 175-billion-parameter language model to be made available to the broader AI research community. OPT-175B can generate creative text on a vast range of topics. Learn more & request access:
49
637
2K
Today is a good day for open science.
As part of our continued commitment to the growth and development of an open ecosystem, today at Meta FAIR we’re announcing four new publicly available AI models and additional research artifacts to inspire innovation in the community and
97
527
2K
Today we're sharing new research that brings us one step closer to real-time decoding of image perception from brain activity.
Using MEG, this AI system can decode the unfolding of visual representations in the brain with an unprecedented temporal resolution.
More details ⬇️

65
492
2K
We're introducing an optimizer for deep learning, MADGRAD. This method matches or exceeds the performance of the Adam optimizer across a varied set of realistic large-scale deep learning training problems.
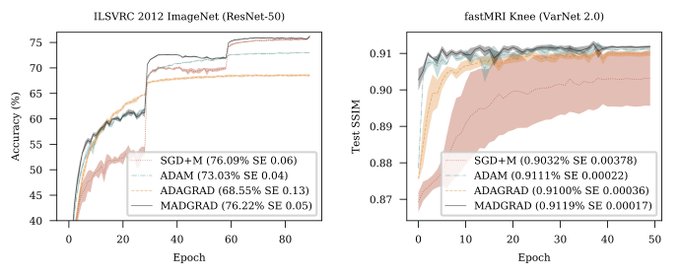
25
508
2K
📝 New from FAIR: An Introduction to Vision-Language Modeling.
Vision-language models (VLMs) are an area of research that holds a lot of potential to change our interactions with technology, however there are many challenges in building these types of models. Together with a set

37
505
2K
Introducing 'Prompt Engineering with Llama 2' — an interactive guide covering prompt engineering & best practices for developers, researchers & enthusiasts working with large language models.
Access the notebook in the llama-recipes repo ➡️
30
488
2K
To better enable the community to build on our work — and contribute to the responsible development of LLMs — we've published further details about the architecture, training compute, approach to fine-tuning & more for Llama 2 in a new paper.
Full paper➡️

34
552
2K
Open source AI is the way forward and today we're sharing a snapshot of how that's going with the adoption and use of Llama models.
Read the full update here ➡️
🦙 A few highlights
• Llama is approaching 350M downloads on
@HuggingFace
. More than 10x

90
302
2K
Today we’re sharing two new advances in our generative AI research: Emu Video & Emu Edit.
Details ➡️
These new models deliver exciting results in high quality, diffusion-based text-to-video generation & controlled image editing w/ text instructions.
🧵
53
472
2K
With the release of Llama 3.1 405B,
@TogetherCompute
built LlamaCoder — an open source web app that can generate an entire app from a prompt. The repo has now been cloned by hundreds of devs on GitHub and starred 2K+ times. More on this project ➡️
39
426
2K
Code Llama is free for both research and commercial use and we've made three different models available:
- Code Llama
- Code Llama - Python
- Code Llama - Instruct
More details on each of these models and how you can download them ➡️
38
495
2K
Today we're sharing details on AudioCraft, a new family of generative AI models built for generating high-quality, realistic audio & music from text. AudioCraft is a single code base that works for music, sound, compression & generation — all in the same place.
More details ⬇️

39
529
2K
We’re open-sourcing a new system to train computer vision models using Transformers. Data-efficient image Transformers (DeiT) is a high-performance image classification model requiring less data & computing resources to train than previous AI models.

18
508
2K
Using HyperTree Proof Search we created a new neural theorem solver that was able to solve 5x more International Math Olympiad problems than any previous AI system & best previous state-of-the-art systems on miniF2F & Metamath.
More in our new post ⬇️

24
346
2K
New AI research from Meta – CoTracker3 Simpler and Better Point Tracking by Pseudo-Labelling Real Videos.
More details ➡️
Demo on
@huggingface
➡️
Building on our previous work on CoTracker, this new model demonstrates impressive
44
332
2K
Introducing Voicebox, a new breakthrough generative speech system based on Flow Matching, a new method proposed by Meta AI. It can synthesize speech across six languages, perform noise removal, edit content, transfer audio style & more.
More details on this work & examples ⬇️

53
445
2K
More technical details on the new Llama 3.1 models we released today. 🦙🧵
27
198
2K
Ready to start working with Meta Llama 3? Here are a few things to help you get started. 🧵
50
207
2K
Using structured weight pruning and knowledge distillation, the
@NVIDIAAI
research team refined Llama 3.1 8B into a new Llama-3.1-Minitron 4B.
They're releasing the new models on
@huggingface
and shared a deep dive on how they did it ➡️

30
356
2K
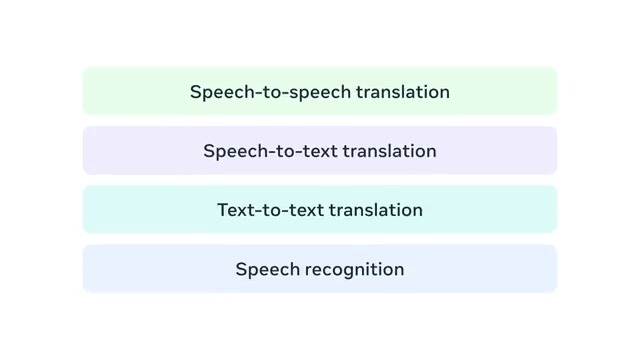
Introducing SeamlessM4T, the first all-in-one, multilingual multimodal translation model.
This single model can perform tasks across speech-to-text, speech-to-speech, text-to-text translation & speech recognition for up to 100 languages depending on the task.
Details ⬇️
58
447
2K
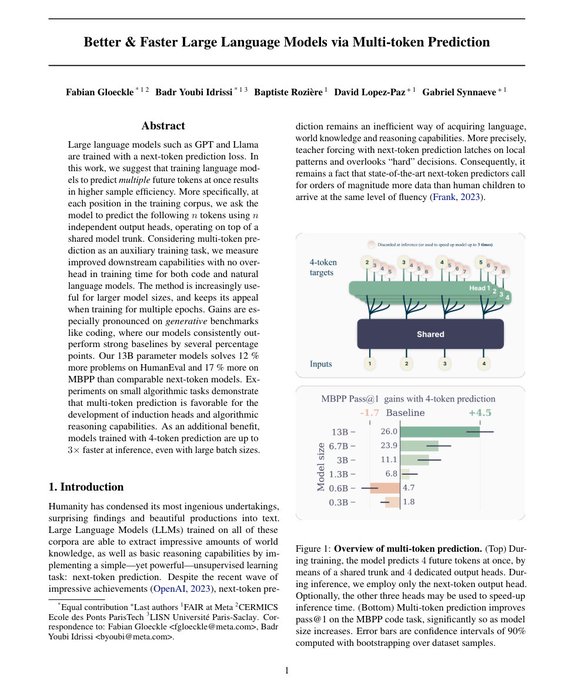
New research from FAIR: Better & Faster Large Language Models via Multi-token Prediction
Research paper ➡️
We show that replacing next token prediction tasks with multiple token prediction can result in substantially better code generation performance
33
312
2K
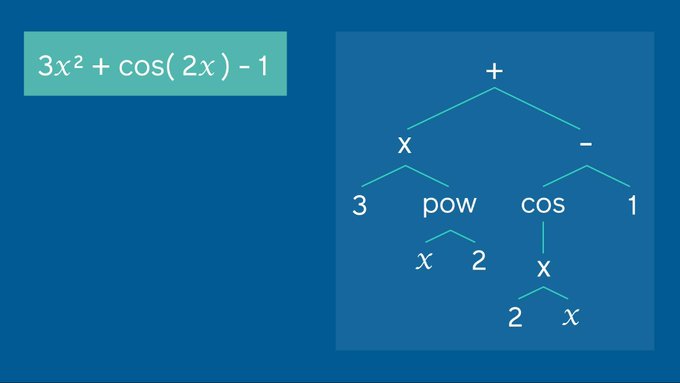
Scientists at Facebook AI have done what was previously considered out of reach for deep learning models, solving complex, symbolic math equations using a neural network.
23
557
2K
(1/3) Until now, AI translation has focused mainly on written languages. Universal Speech Translator (UST) is the 1st AI-powered speech-to-speech translation system for a primarily oral language, translating Hokkien, one of many primarily spoken languages.
39
479
2K
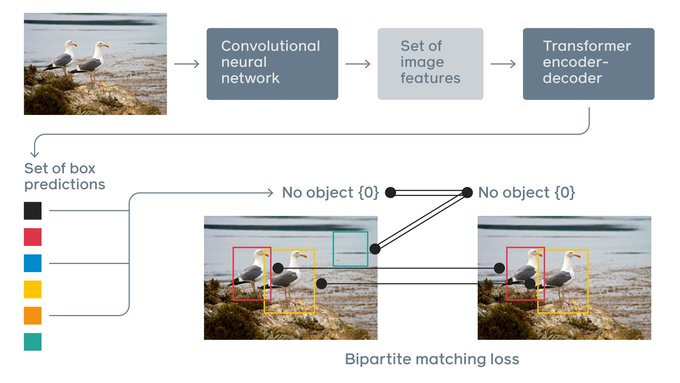
We are releasing Detection Transformers (DETR), an important new approach to object detection and panoptic segmentation. It’s the first object detection framework to successfully integrate Transformers as a central building block in the detection pipeline.
12
499
2K
Today we’re sharing some of our latest progress on AI-powered hypercompression of audio. Our researchers achieved ~10x compression rate vs. MP3 at 64 kbps with no quality loss — the first time this has been done with 48 kHz sampled stereo audio ➡️
1/5
48
334
2K
We are releasing HiPlot, a lightweight interactive visualization tool to help AI researchers discover correlations and patterns in high-dimensional data.
9
466
2K
Today we're sharing the next milestone in our Seamless Communication research — a new family of AI translation models that preserve expression and deliver near-real time streaming translations.
More on this new work ➡️
More on the individual models 🧵
34
357
2K
A few technical insights on the new Llama vision models we’re releasing today 🦙🧵
31
164
2K
Today we're releasing our work on I-JEPA — self-supervised computer vision that learns to understand the world by predicting it. It's the first model based on a component of
@ylecun
's vision to make AI systems learn and reason like animals and humans.
Details ⬇️

38
344
2K
Introducing ImageBind by Meta AI: the first AI model capable of binding data from six modalities at once. This breakthrough brings machines one step closer to the human ability to bind together information from many different senses.
More on this new open source work ⬇️

54
428
2K
Starting today you can try our new foundation research model for audio generation. The demo includes Zero shot TTS, Text to sound effects, Infilling and more!
Try Audiobox ➡️
38
356
2K
We’re happy to work with
@oasislabs
on this important project announced today that will advance fairness measurement in AI models.

As
@Meta
’s technology partner, Oasis Labs built the platform that uses Secure Multi-Party Computation (SMPC) to safeguard information as Meta asks users on
@Instagram
to take a survey in which they can voluntarily share their race or ethnicity
21
204
749
66
470
1K
Ready to start working with Llama 3.1? Here are a few new resources from the Llama team to help you get started. 🧵
31
211
2K
Does your child love to draw? Ever wished that their characters could “come to life” and move around the page? Using AI, we’ve developed automatic animation that can bring children’s one-of-a-kind characters to life! Learn more and try it out here:
42
328
2K
Newly published today in
@Nature
: No Language Left Behind (NLLB) is an AI model created by researchers at Meta capable of delivering high-quality translations directly between 200 languages – including low-resource languages.
Read more in Nature ⬇️

46
295
1K
Today, we’re introducing TextStyleBrush, the first self-supervised AI model that replaces text in existing images of both scenes and handwriting — in one shot — using just a single example word:
25
328
1K
Read about new developments in deep learning with authors and researchers Daniel A. Roberts (
@danintheory
), Sho Yaida (
@Shoyaida
) and Boris Hanin (
@BorisHanin
) in their book The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks. 👇

19
291
1K
SeamlessStreaming is an AI translation model that can deliver state-of-the-art results on streaming translation with <2 seconds of latency. One core piece of our latest Seamless Communication research work by teams at FAIR.
More on this project ➡️
40
308
1K
We’re excited to share the first official distribution of Llama Stack! It packages multiple API Providers into a single endpoint for developers to enable a simple, consistent experience to work with Llama models across a range of deployments.
Details ➡️

35
263
1K
We're releasing Flashlight: A modern, open source machine learning library written entirely in C++. It's customizable to the core to support your research's needs — and it's pretty fast too.

18
325
1K
"Exo's use of Llama 405B and consumer-grade devices to run inference at scale on the edge shows that the future of AI is open source and decentralized." -
@mo_baioumy

2 MacBooks is all you need.
Llama 3.1 405B running distributed across 2 MacBooks using
@exolabs_
home AI cluster
210
728
5K
44
220
1K
In 2021, we created a research demo that brought amateur drawings to life through animation — today, we're open-sourcing the code + releasing a first-of-its-kind dataset of nearly 180K annotated amateur drawings to help researchers keep innovating in this space.
More details ⬇️

36
346
1K
To close out 2023, here are 10 of the most interesting AI research advancements we shared on our feed this year — and where you can find more details on the work.
1️⃣ Segment Anything (SAM)
A step toward the first foundation model for image segmentation.
Details:
32
344
1K
Meta AI researchers show how current language models differ from the human brain & highlight the role of long-range & hierarchical predictions.
Read the open accessed article in Nature ➡️
33
321
1K
As part of our continued belief in the value of an open approach to today's AI, we've published a research paper with more information on Code Llama training, evaluation results, safety and more.
Code Llama: Open Foundation Models for Code ➡️

28
319
1K
With Llama 3.2 we released our first-ever lightweight Llama models: 1B & 3B. These models empower developers to build personalized, on-device agentic applications with capabilities like summarization, tool use and RAG where data never leaves the device.
23
202
1K
Llama 3.2 features 11B & 90B models, our first multimodal Llama models with support for vision tasks. These models can take in both image and text prompts to deeply understand and reason on inputs.
41
231
1K
We’re introducing GSLM, the first language model that breaks free completely of the dependence on text for training. This “textless NLP” approach learns to generate expressive speech using only raw audio recordings as input. Learn more and get the code:

16
349
1K
It's been exactly one week since we released Meta Llama 3, in that time the models have been downloaded over 1.2M times, we've seen 600+ derivative models on
@HuggingFace
and much more.
More on the exciting impact we're already seeing with Llama 3 ➡️

26
172
1K
Llama 2 is now available — open source, free for research and commercial use. These models are accessible to individuals, creators, researchers and businesses.
Download ⬇️

22
313
1K
Together with the Ego4D consortium, today we're releasing Ego-Exo4D, the largest ever public dataset of its kind to support research on video learning & multimodal perception — including 1,400+ hours of videos of skilled human activities.
Download ➡️
28
243
1K
We’ve developed TransCoder, the first self-supervised neural transcompiler system for migrating code between programming languages. Transcoder can translate code from Python to C++, for example, and it outperforms rule-based translation programs.
24
359
1K
Introducing the next generation of the Meta Training and Inference Accelerator (MTIA), the next in our family of custom-made silicon, designed for Meta’s AI workloads.
Full details ➡️
44
181
1K
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation
15
165
1K
Researchers at Meta recently shared MAGNeT, a single non-autoregressive transformer model for text-to-music & text-to-sound generation capable of generating audio on-par with the quality of SOTA models — at 7x the speed.
MAGNeT is open source as part of AudioCraft. Hear audio
25
225
1K
Today we’re releasing OpenEQA — the Open-Vocabulary Embodied Question Answering Benchmark. It measures an AI agent’s understanding of physical environments by probing it with open vocabulary questions like “Where did I leave my badge?”
More details ➡️
38
258
1K
We’re open sourcing PyTorch-BigGraph, a tool that makes it much faster and easier to produce graph embeddings for extremely large graphs. Quickly produce high-quality embeddings without specialized computing resources like GPUs or huge amounts of memory.
6
385
1K
Segment Anything Model 2 (SAM 2) is a foundation model from Meta FAIR for promptable visual segmentation in images & videos.
Available now for anyone to build on for free, open source under an Apache license.
Try the demo ➡️
32
217
1K
Facebook AI and
@CarnegieMellon
researchers have built Pluribus, the first AI bot to beat elite poker pros in 6 player Texas Hold’em. This breakthrough is the first major benchmark outside of 2 player games and we’re sharing specifics on how we built it.
77
424
1K
As part of our support of open science, we've published the full Llama 3 research paper covering a range of topics.
• Model training
• Model architecture
• Results of our ongoing work on integrating image/video/speech capabilities
• Much more
Paper ➡️

25
256
1K
We've expanding access to DINOv2 by releasing the training code and model weights under the Apache-2 license.
Details on this and more of our recent work to advance computer vision research and fairness in AI ⬇️

20
202
1K
Today we're sharing new progress on our AI speech work. Our Massively Multilingual Speech (MMS) project has now scaled speech-to-text & text-to-speech to support over 1,100 languages — a 10x increase from previous work.
Details + access to new pretrained models ⬇️
40
255
1K
3D computer vision research just got easier!
We’re releasing Implicitron, an extension of PyTorch3D that enables fast prototyping of 3D reconstruction and new-view synthesis methods based on rendering of implicit representations.
8
216
1K
We're releasing code for a new approach to generating recipes directly from food images. This produces more compelling recipes than retrieval-based approaches and improves performance with respect to previous baselines for ingredient prediction.
#CVPR2019
18
345
1K
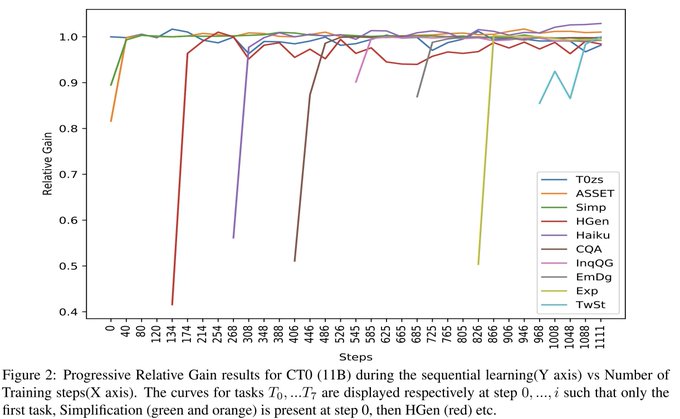
Continual-T0 (CT0) displays Continual Learning capabilities via self-supervision. This fine-tuned language model retains skills while learning new tasks across an unprecedented scale of 70 datasets. It can even combine instructions without prior training.
3
70
239
(1/2) Today, we're announcing the first model capable of automatically verifying hundreds of thousands of citations at once. Read more:
12
204
1K
Announcing the ESM Metagenomic Atlas — the first comprehensive view of the ‘dark matter’ of the protein universe. Made possible by ESMFold, a new breakthrough model for protein folding from Meta AI.
More in our new blog ➡️
1/3
24
265
1K
New in Nature Human Behavior, Meta AI researchers show how current language models differ from the human brain & highlight the role of long-range & hierarchical predictions.
We hope these findings will help inform the next generation of AI ➡️
22
236
1K
Today we’re announcing that Facebook AI has built and open-sourced Blender, the largest-ever open-domain chatbot. It outperforms others in terms of engagement and also feels more human, according to human evaluators.
23
378
1K
We have created a new AI-powered tool that can turn virtually any standard 2D picture into a 3D image.
Learn how it works here:
11
315
1K
Excited to announce Make-A-Scene, our latest research tool Mark Zuckerberg just shared. Make-A-Scene is an exploratory concept that gives creative control to anyone, artists & non-artists alike to use both text & sketches to guide AI image generation:
38
264
1K
We’ve made the code available for Mesh R-CNN, a state of the art method that can reconstruct complex objects in three dimensions. Get it on Github here: . And learn more about Mesh R-CNN here:
7
339
1K