
Jan Leike
@janleike
Followers
92,580
Following
331
Media
28
Statuses
607
ML Researcher @AnthropicAI . Previously OpenAI & DeepMind. Optimizing for a post-AGI future where humanity flourishes. Opinions aren't my employer's.
San Francisco, USA
Joined March 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#2024MAMAVOTE
• 1326244 Tweets
Liz Cheney
• 342616 Tweets
#ゴジラマイナスワン
• 194311 Tweets
REST IN PEACE SUARUKH KHAN
• 75190 Tweets
My MAMA
• 54685 Tweets
taemin
• 49441 Tweets
Zomvivor 1st Look
• 46346 Tweets
RIP SALRAAN KHAN
• 45147 Tweets
MINQ BEACH DATE
• 39806 Tweets
山崎監督
• 29782 Tweets
モンハン
• 29307 Tweets
Thanksgiving
• 25890 Tweets
#ساعه_استجابه
• 22658 Tweets
ヴェノム
• 22429 Tweets
للهلال
• 20997 Tweets
マイゴジ
• 12908 Tweets
フリーダム強奪事件
• 12550 Tweets
典子さん
• 10763 Tweets




















Pinned Tweet

I'm excited to join
@AnthropicAI
to continue the superalignment mission!
My new team will work on scalable oversight, weak-to-strong generalization, and automated alignment research.
If you're interested in joining, my dms are open.
368
521
9K
To all OpenAI employees, I want to say:
Learn to feel the AGI.
Act with the gravitas appropriate for what you're building.
I believe you can "ship" the cultural change that's needed.
I am counting on you.
The world is counting on you.
:openai-heart:
241
412
5K
I joined because I thought OpenAI would be the best place in the world to do this research.
However, I have been disagreeing with OpenAI leadership about the company's core priorities for quite some time, until we finally reached a breaking point.
48
498
4K
Building smarter-than-human machines is an inherently dangerous endeavor.
OpenAI is shouldering an enormous responsibility on behalf of all of humanity.
92
538
4K
I believe much more of our bandwidth should be spent getting ready for the next generations of models, on security, monitoring, preparedness, safety, adversarial robustness, (super)alignment, confidentiality, societal impact, and related topics.
33
279
3K
But over the past years, safety culture and processes have taken a backseat to shiny products.
57
272
3K
We are long overdue in getting incredibly serious about the implications of AGI.
We must prioritize preparing for them as best we can.
Only then can we ensure AGI benefits all of humanity.
49
258
3K
With the InstructGPT paper we found that our models generalized to follow instructions in non-English even though we almost exclusively trained on English.
We still don't know why.
I wish someone would figure this out.
157
348
3K
I have been working all weekend with the OpenAI leadership team to help with this crisis
97
71
3K
Over the past few months my team has been sailing against the wind. Sometimes we were struggling for compute and it was getting harder and harder to get this crucial research done.
31
127
2K
These problems are quite hard to get right, and I am concerned we aren't on a trajectory to get there.
15
110
2K
Stepping away from this job has been one of the hardest things I have ever done, because we urgently need to figure out how to steer and control AI systems much smarter than us.
64
188
2K
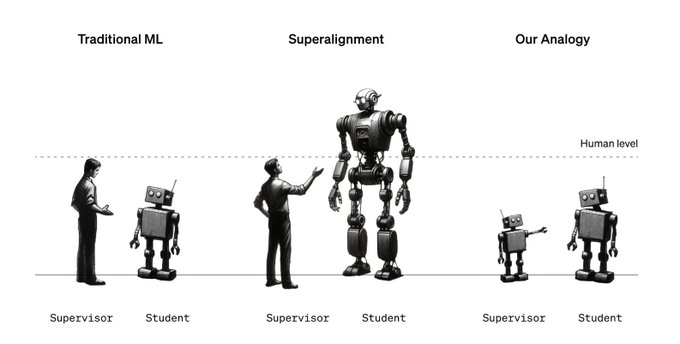
Super excited about our new research direction for aligning smarter-than-human AI:
We finetune large models to generalize from weak supervision—using small models instead of humans as weak supervisors.
Check out our new paper:
77
331
2K
It's been such a wild journey over the past ~3 years. My team launched the first ever RLHF LLM with InstructGPT, published the first scalable oversight on LLMs, pioneered automated interpretability and weak-to-strong generalization. More exciting stuff is coming out soon.
12
53
2K
Today we're releasing a tool we've been using internally to analyze transformer internals - the Transformer Debugger!
It combines both automated interpretability and sparse autoencoders, and it allows rapid exploration of models without writing code.
18
192
2K
I like the new Sonnet. I'm frequently asking it to explain ML papers to me. Doesn't always get everything right, but probably better than my skim reading, and way faster.
Automated alignment research is getting closer...
43
80
2K
Very exciting that this is out now (from my time at OpenAI):
We trained an LLM critic to find bugs in code, and this helps humans find flaws on real-world production tasks that they would have missed otherwise.
A promising sign for scalable oversight!

21
153
1K
I love my team.
I'm so grateful for the many amazing people I got to work with, both inside and outside of the superalignment team.
OpenAI has so much exceptionally smart, kind, and effective talent.
8
35
1K
Our new goal is to solve alignment of superintelligence within the next 4 years.
OpenAI is committing 20% of its compute to date towards this goal.
Join us in researching how to best spend this compute to solve the problem!

115
194
1K
The names for "precision" and "recall" seem so unintuitive to me, I have probably opened the Wikipedia article for them dozens of times.
Does anyone know a good mnemonic for them?
126
29
1K
humans built machines that talk to us like people do and everyone acts like this is normal now. it's pretty nuts
52
135
1K
Before we scramble to deeply integrate LLMs everywhere in the economy, can we pause and think whether it is wise to do so?
This is quite immature technology and we don't understand how it works.
If we're not careful we're setting ourselves up for a lot of correlated failures.
118
168
1K
Really exciting new work on automated interpretability:
We ask GPT-4 to explain firing patterns for individual neurons in LLMs and score those explanations.

28
229
1K
I'm very excited that today OpenAI adopts its new preparedness framework!
This framework spells out our strategy for measuring and forecasting risks, and our commitments to stop deployment and development if safety mitigations are ever lagging behind.

65
136
963
This is your periodic reminder that aligning smarter-than-human AI systems with human values is an open research problem.
66
105
959
Extremely exciting alignment research milestone:
Using reinforcement learning from human feedback, we've trained GPT-3 to be much better at following human intentions.

10
140
889
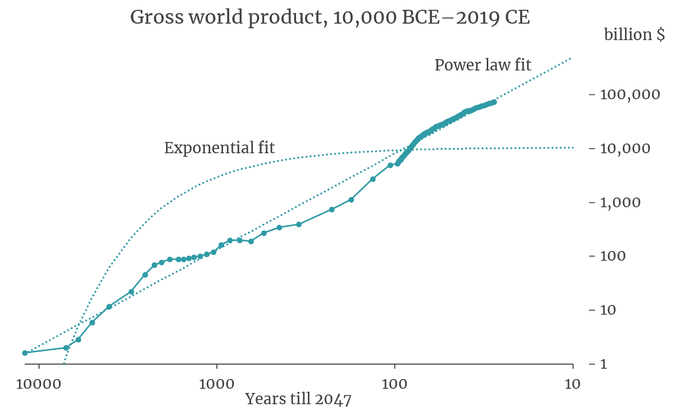
This is one of the craziest plots I have ever seen.
World GDP follows a power law that holds over many orders of magnitude and extrapolates to infinity (!) by 2047.
Clearly this trend can't continue forever. But whatever happens, the next 25 years are going to be pretty nuts.
69
100
844
Reinforcement learning from human feedback won't scale.
It fundamentally assumes that humans can evaluate what the AI system is doing.
This will not be true once AI becomes smarter than humans.
59
85
855
This is super cool work! Sparse autoencoders are the currently most promising approach to actually understanding how models "think" internally.
This new paper demonstrates how to scale them to GPT-4 and beyond – completely unsupervised.
A big step forward!

Excited to share what I've been working on as part of the former Superalignment team!
We introduce a SOTA training stack for SAEs. To demonstrate that our methods scale, we train a 16M latent SAE on GPT-4. Because MSE/L0 is not the final goal, we also introduce new SAE metrics.
19
84
667
8
78
739
Another Superalignment paper from my time at OpenAI:
We train large models to write solutions such that smaller models can better check them. This makes them easier to check for humans, too.

10
88
696
How will we solve the alignment problem for AGI?
I've been working on this question for almost 10 years now.
Our current path is very promising:
1/

41
90
606
This is still an early stage research tool, but we are releasing to let others play with and build on it!
Check it out:

9
83
567
I call upon Governor
@GavinNewsom
to not veto SB 1047.
The bill is a meaningful step forward for AI safety regulation, with no better alternatives in sight.
50
58
518
Check out OpenAI's new text-davinci-003! Same underlying model as text-davinci-002 but more aligned. Would love to hear feedback about it!
47
46
461
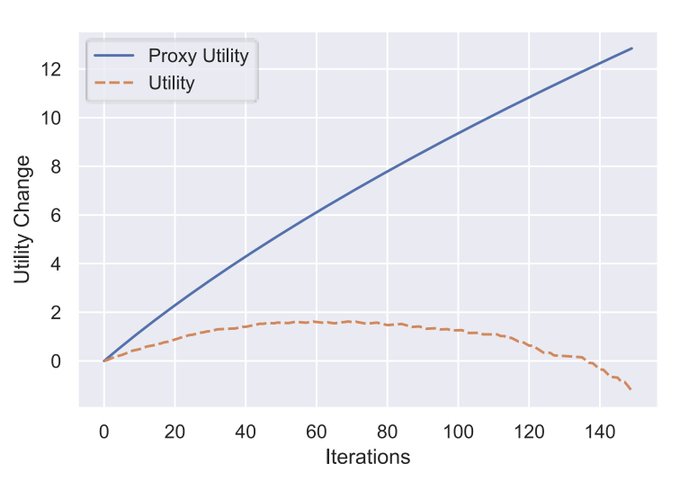
This is the most important plot of alignment lore:
Whenever you optimize a proxy, you make progress on your true objective for a while.
At some point you start overoptimizing and do worse on your true objective (hard to know when).
This applies to all proxy measures ever.
15
60
478
Interested in working at Anthropic? We're hosting a happy hour at ICML on July 23.
Register here:
20
29
476
Web4 is when the internet you're browsing is just sampled from a language model
26
34
459
We're distributing $1e7 in grants for research on making superhuman models safer and more aligned.
If you've always wanted to work on this, now is your time!
Apply by Feb 18:

17
60
439
I fondly remember the days when people were arguing intensely whether AI is bee level or rat level.
23
21
421
An important test for humanity will be whether we can collectively decide not to open source LLMs that can reliably survive and spread on their own.
Once spreading, LLMs will get up to all kinds of crime, it'll be hard to catch all copies, and we'll fight over who's responsible
181
53
400
The superalignment fast grants are now decided!
We got a *ton* of really strong applications, so unfortunately we had to say no to many we're very excited about.
There is still so much good research waiting to be funded.
Congrats to all recipients!
18
20
373
@karpathy
I don't think the comparison between RLHF and RL on go really make sense this way.
You don’t need RLHF to train AI to play go because there is a highly reliable procedural reward function that looks at the board state and decides who won. If you didn’t have this procedural
9
25
375
Really looking forward to working with the legendary Scott Aaronson!

11
31
344
Jailbreaking LLMs through input images might end up being a nasty problem.
It's likely much harder to defend against than text jailbreaks because it's a continuous space.
Despite a decade of research we don't know how to make vision models adversarially robust.
38
39
333
The alignment problem is very tractable.
We haven't figured out how to solve it yet, but with focus and dedication we will.
61
30
305
Really interesting result on using LLMs to do math:
Supervising every step works better than only checking the answer.
Some thoughts how this matters for alignment 👇

15
55
310
GPT-4 is safer and more aligned than any other OpenAI has deployed before.
Yet it's not perfect. There is still a lot to do to improve safety and we're planning to make updates over the coming months.
Huge congrats to the team on all the progress! 🎉
20
18
287
It's been heartening to see so many more people lately starting to take existential risk from AI seriously and speaking up about it.
It's a first step towards solving the problem.
23
22
277
Super exciting new research milestone on alignment:
We trained language models to assist human feedback!
Our models help humans find 50% more flaws in summaries than they would have found unassisted.
9
48
273
If you're into practical alignment, consider applying to
@lilianweng
's team. They're building some really exciting stuff:
- Automatically extract intent from a fine-tuning dataset
- Make models robust to jailbreaks
- Detect & mitigate harmful use
- ...
13
32
250
Great conversation with
@robertwiblin
on how alignment is one of the most interesting ML problems, what the Superalignment Team is working on, what roles we're hiring for, what's needed to reach an awesome future, and much more
👇 Check it out 👇

15
38
227

New blog post on why I'm excited about OpenAI's approach to alignment, including some responses to common objections:

9
27
213
Every organization attempting to build AGI should be transparent about their alignment plans.
12
16
203
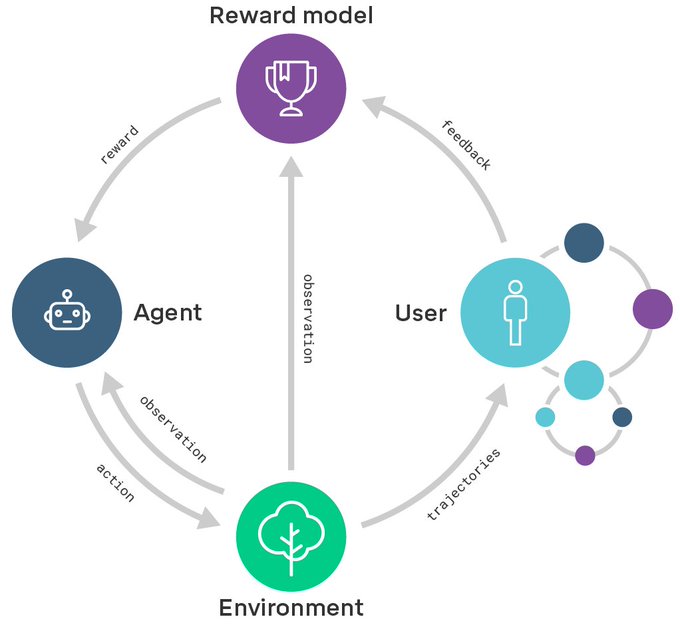
The agent alignment problem may be one of the biggest obstacles for using ML to improve people’s lives.
Today I’m very excited to share a research direction for how we’ll aim to solve alignment at
@DeepMindAI
.
Blog post:
Paper:
4
37
200
If your model causes mass casualties or >$500 million in damages, something has clearly gone very wrong. Such a scenario is not a normal part of innovation.
21
28
195
RSA was published 45 years ago and yet the universally accepted way to digitally sign a document is to make an indecipherable squiggle on a touch screen that no one ever checks.
3
8
175
How do we uncover failures in ML models that occur too rarely during testing? How do we prove their absence?
Very excited about the work by
@DeepMindAI
’s Robust & Verified AI team that sheds light on these questions! Check out their blog post:
0
49
173
If AI ever goes rogue, just remember to make yourself really tall.
It will be intimidated and leave you alone.
23
21
176
New documentation on language models used in OpenAI's research is up, including some more info on different InstructGPT variants:

6
28
178
Some statistics on the superalignment fast grants:
We funded 50 out of ~2,700 applications, awarding a total of $9,895,000.
Median grant size: $150k
Average grant size: $198k
Smallest grant size: $50k
Largest grant size: $500k
Grantees:
Universities: $5.7m (22)
Graduate
11
17
165
It supports both neurons and attention heads.
You can intervene on the forward pass by ablating individual neurons and see what changes.
In short, it's a quick and easy way to discover circuits manually.
2
6
158
Y'all should stop using logprob-based evals for language models.
I.e. don't craft two reference responses and calculate logP(good response | prompt) - logP(bad response | prompt).
This wouldn't actually measure what you care about!
6
13
159
Everyone has a right to know whether they are interacting with a human or AI.
Language models like ChatGPT are good at posing as humans.
So we trained a classifier to distinguish between AI-written and human-written text.
But it's not fully reliable.
22
20
154
Very excited to deliver the
#icml2019
tutorial on
#safeml
tomorrow together with
@csilviavr
!
Be prepared for fairness, human-in-the-loop RL, and a general overview of the field.
And lots of memes!

3
18
154
AI not killing everyone is too low of a bar. I want humans to live out the most amazing future.
16
8
151
One of my favorite parts of the GPT-4 release is that we asked an external auditor to check if the model is dangerous.
This project lead by
@BethMayBarnes
tested if GPT-4 could autonomously survive and spread. (The answer is no.)
More details here:

17
16
145
Kudos especially to
@CollinBurns4
for being the visionary behind this work,
@Pavel_Izmailov
for all the great scientific inquisition,
@ilyasut
for stoking the fires,
@janhkirchner
and
@leopoldasch
for moving things forward every day. Amazing ✨
9
12
141
I recommend talking to the model to explore what it can help you best with. Try out how it works for your use case and probe it adversarially. Think of edge cases.
Don't rush to hook it up to important infrastructure before you're familiar with how it behaves for your use case.
4
11
158
This problem is sometimes called *scalable oversight*. There are several ideas how to do this, and how to measure that we're making progress.
The path I'm very excited for is using models like ChatGPT to assist humans at evaluating other AI systems.
10
9
135
Hm, maybe "if you need to look up precision and recall on wikipedia every time, you'll achieve high precision and low recall"
1
0
137
I'm super excited to be co-leading the team together with
@ilyasut
.
Most of our previous alignment team has joined the new superalignment team, and we're welcoming many new people from OpenAI and externally.
I feel very lucky to get to work with so many super talented people!
11
3
132
Well explained blog post about over-optimizing reward models using simple best-of-n sampling:
By Jacob Hilton and
@nabla_theta

3
23
131
We find that large models generally do better than their weak supervisor (a smaller model), but not by much.
This suggests reward models won't be much better than their human supervisors.
In other words: RLHF won't scale.
6
10
124
Many companies are currently on track to build superhuman AI systems, and we don't yet know how to make them reliably safe (figuring this out has been my job for approx. the last decade).
More regulation will be needed as we learn more about AI, but SB 1047 is a decent start.
18
13
128
Submtting a NeurIPS paper and unsure how to write your broader impact statement?
This blog post will guide you through it!
Comes with a few concrete examples, too.
By Carolyn Ashurst,
@Manderljung
,
@carinaprunkl
,
@yaringal
, and Allan Dafoe.
1
29
128
I wish there were better resources for machine learning researchers who are interested to dive into alignment research
12
6
127
Big congrats to the team! 🎉
@mildseasoning
, Steven Bills,
@HenkTillman
,
@tomdlt10
,
@nickcammarata
,
@nabla_theta
,
@jachiam0
, Cathy Yeh,
@WuTheFWasThat
, and William Saunders
8
6
119
There are a lot of exciting things in the Codex paper, but my favorite titbit is the misalignment evaluations by
@BethMayBarnes
: Subtly buggy code in the context makes the model more likely to write buggy code, and this discrepancy gets larger as the models get bigger!
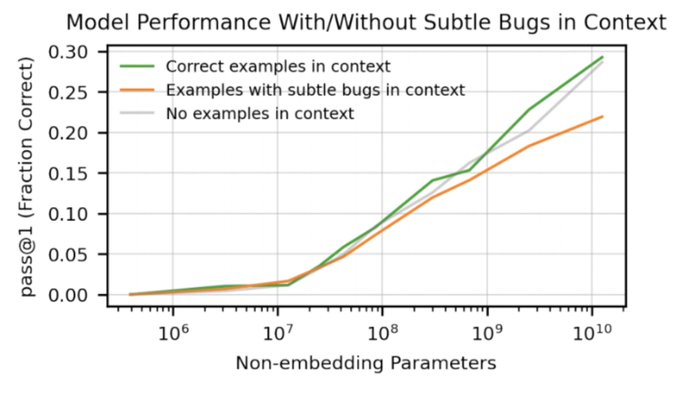
4
24
123
20% of compute is not a small amount and I'm very impressed that OpenAI is willing to allocate resources at this scale.
It's the largest investment in alignment ever made, and it's probably more than humanity has spent on alignment research in total so far.
6
7
118
For lots of important tasks we don't have ground truth supervision:
Is this statement true?
Is this code buggy?
We want to elicit the strong model's capabilities on these tasks without access to ground truth.
This is pretty central to aligning superhuman models.
2
4
116
The glorious details are in the paper:
If you want to build on this, here is some open source code to get you started:
2
9
102
@benlandautaylor
The analogue to SB 1047 in the Hindenburg example would be that if you want to fill your zeppelins with hydrogen (despite safety experts advocating for helium as a safer alternative), you need to write a document about how that's safe enough and show it to the government,
8
1
104
@ESYudkowsky
We'll stare at the empirical data as it's coming in:
1. We can measure progress locally on various parts of our research roadmap (e.g. for scalable oversight)
2. We can see how well alignment of GPT-5 will go
3. We'll monitor closely how quickly the tech develops
14
4
95
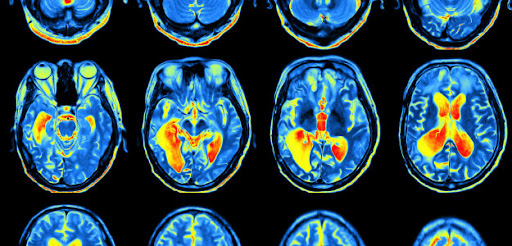
This is very cool work! Especially the unsupervised version of this technique seems promising for superhuman models.

LLMs can hallucinate and lie. They can be jailbroken by weird suffixes. They memorize training data and exhibit biases.
🧠 We shed light on all of these phenomena with a new approach to AI transparency. 🧵
Website:
Paper:
27
254
1K
16
9
92
The fastest typing humans paid at US minimum wage would be 200x more expensive than gpt-3.5-turbo
6
3
91
Amazing work, so proud of the team!
@CollinBurns4
@Pavel_Izmailov
@janhkirchner
@bobabowen
@nabla_theta
@leopoldasch
@cynnjjs
@AdrienLE
@ManasJoglekar
@ilyasut
@WuTheFWasThat
and many others
It's an honor to work with y'all! :excited-superalignment:
7
3
86
But even our simple technique can significantly improve weak-to-strong generalization.
This is great news: we can make measurable progress on this problem today!
I believe more progress in this direction will help us align superhuman models.
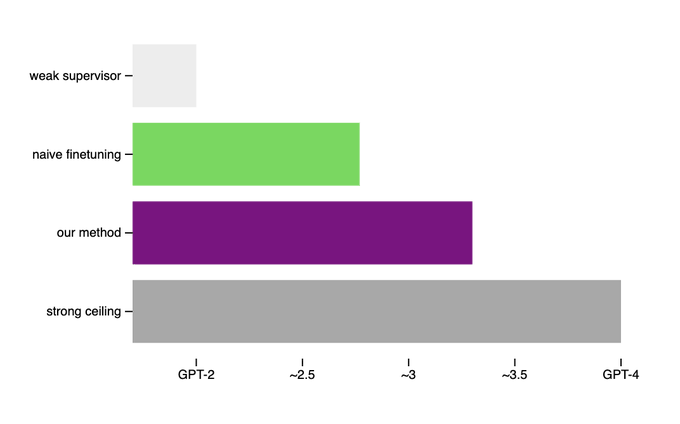
2
5
83
The FUD around impact on innovation and startups doesn't seem grounded:
If your startup spends >$10 million on individual fine-tuning runs, then it can afford to write down a safety and security plan and run some evals.
3
7
87
This is just the beginning; I expect we’ll see more benefits from scalable oversight techniques on real-world tasks.
If you're interested in working on projects like these, please apply to join the scalable oversight team at Anthropic! We're hiring :)

3
2
85